

衡兰芷若成绝响,人间不见周海媚(4k修复基于PaddleGan) - 刘悦的技术博客
source link: https://www.cnblogs.com/v3ucn/p/17902788.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.


一代人有一代人的经典回忆,1994年由周海媚、马景涛、叶童主演的《神雕侠侣》曾经风靡一时,周海媚所诠释的周芷若凝聚了汉水之钟灵,峨嵋之毓秀,遇雪尤清,经霜更艳,俘获万千观众,成为了一代人的共同记忆。
如今美人仙去,回望经典,雪肤依然,花貌如昨,白璧微瑕之处是九十年代电视剧的分辨率有些低,本次我们利用百度自研框架PaddleGan的视频超分SOTA算法来对九十年代电视剧进行4K修复。
配置PaddlePaddle框架
PaddlePaddle框架需要本地环境支持CUDA和cudnn,具体请参照:声音好听,颜值能打,基于PaddleGAN给人工智能AI语音模型配上动态画面(Python3.10),囿于篇幅,这里不再赘述。
接着去PaddlePaddle官网查看本地cudnn对应的paddlepaddle版本:
https://www.paddlepaddle.org.cn/
输入命令查看本地cudnn版本:
nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Tue_Mar__8_18:36:24_Pacific_Standard_Time_2022
Cuda compilation tools, release 11.6, V11.6.124
Build cuda_11.6.r11.6/compiler.31057947_0
可以看到版本是11.6
随后安装对应11.6的最新paddle-gpu版本:
python -m pip install paddlepaddle-gpu==2.5.2.post116 -f https://www.paddlepaddle.org.cn/whl/windows/mkl/avx/stable.html
注意这里的最新版是paddlepaddle-gpu2.5.2.post116,而非之前的paddlepaddle-gpu2.4.2.post116
安装成功后,进行检测:
PS C:\Users\zcxey> python
Python 3.10.11 (tags/v3.10.11:7d4cc5a, Apr 5 2023, 00:38:17) [MSC v.1929 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import paddle
>>> paddle.utils.run_check()
Running verify PaddlePaddle program ...
I1214 14:38:08.825912 4800 interpretercore.cc:237] New Executor is Running.
W1214 14:38:08.827040 4800 gpu_resources.cc:119] Please NOTE: device: 0, GPU Compute Capability: 8.9, Driver API Version: 12.3, Runtime API Version: 11.6
W1214 14:38:08.829569 4800 gpu_resources.cc:149] device: 0, cuDNN Version: 8.4.
I1214 14:38:12.468061 4800 interpreter_util.cc:518] Standalone Executor is Used.
PaddlePaddle works well on 1 GPU.
PaddlePaddle is installed successfully! Let's start deep learning with PaddlePaddle now.
说明PaddlePaddle的配置没有问题。
随后克隆项目并且进行编译:
git clone https://gitee.com/PaddlePaddle/PaddleGAN
cd PaddleGAN
pip3 install -v -e .
视频修复超分模型
关于视频修复超分模型的选择,这里我们使用百度自研SOTA超分系列模型PP-MSVSR、业界领先的视频超分模型还包括EDVR、BasicVSR,IconVSR和BasicVSR++等等。
百度自研的PP-MSVSR是一种多阶段视频超分深度架构,具有局部融合模块、辅助损失和细化对齐模块,以逐步细化增强结果。具体来说,在第一阶段设计了局部融合模块,在特征传播之前进行局部特征融合, 以加强特征传播中跨帧特征的融合。在第二阶段中引入了一个辅助损失,使传播模块获得的特征保留了更多与HR空间相关的信息。在第三阶段中引入了一个细化的对齐模块,以充分利用前一阶段传播模块的特征信息。大量实验证实,PP-MSVSR在Vid4数据集性能优异,仅使用 1.45M 参数PSNR指标即可达到28.13dB。
PP-MSVSR提供两种体积模型,开发者可根据实际场景灵活选择:PP-MSVSR(参数量1.45M)与PP-MSVSR-L(参数量7.42)。
关于EDVR:
EDVR模型在NTIRE19视频恢复和增强挑战赛的四个赛道中都赢得了冠军,并以巨大的优势超过了第二名。视频超分的主要难点在于(1)如何在给定大运动的情况下对齐多个帧;(2)如何有效地融合具有不同运动和模糊的不同帧。首先,为了处理大的运动,EDVR模型设计了一个金字塔级联的可变形(PCD)对齐模块,在该模块中,从粗到精的可变形卷积被使用来进行特征级的帧对齐。其次,EDVR使用了时空注意力(TSA)融合模块,该模块在时间和空间上同时应用注意力机制,以强调后续恢复的重要特征。
关于BasicVSR:
BasicVSR在VSR的指导下重新考虑了四个基本模块(即传播、对齐、聚合和上采样)的一些最重要的组件。 通过添加一些小设计,重用一些现有组件,得到了简洁的 BasicVSR。与许多最先进的算法相比,BasicVSR在速度和恢复质量方面实现了有吸引力的改进。 同时,通过添加信息重新填充机制和耦合传播方案以促进信息聚合,BasicVSR 可以扩展为 IconVSR,IconVSR可以作为未来 VSR 方法的强大基线 .
关于BasicVSR++:
BasicVSR++通过提出二阶网格传播和导流可变形对齐来重新设计BasicVSR。通过增强传播和对齐来增强循环框架,BasicVSR++可以更有效地利用未对齐视频帧的时空信息。 在类似的计算约束下,新组件可提高性能。特别是,BasicVSR++ 以相似的参数数量在 PSNR 方面比 BasicVSR 高0.82dB。BasicVSR++ 在NTIRE2021的视频超分辨率和压缩视频增强挑战赛中获得三名冠军和一名亚军。
在当前参数量小于6M的轻量化视频超分模型在 UDM10 数据集上的PSNR指标对比上,PP-MSVSR可谓是“遥遥领先”:
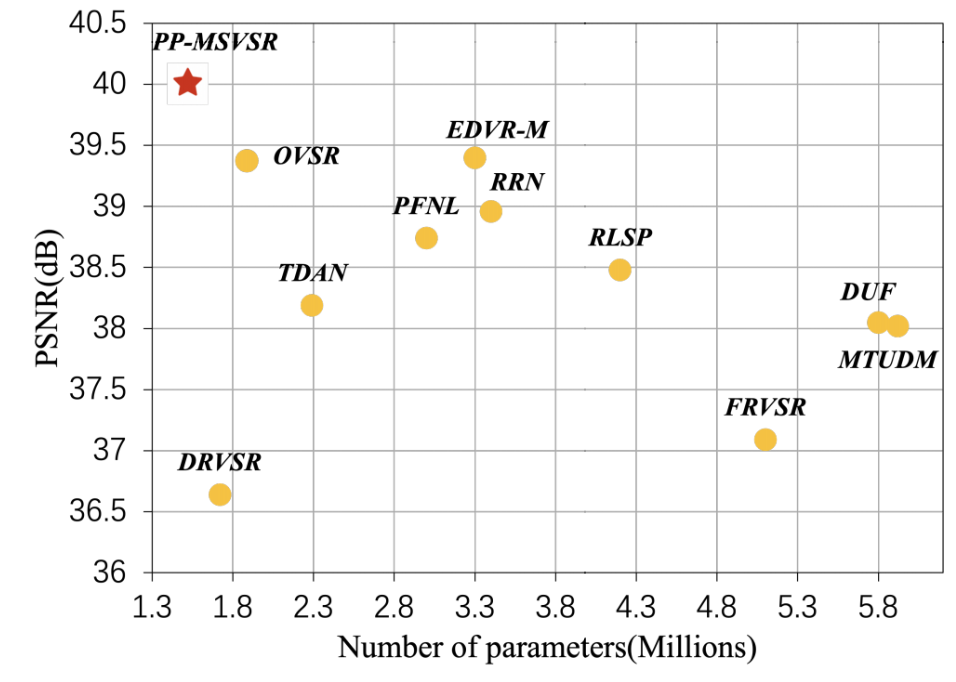
视频修复实践
PP-MSVSR提供两种体积模型,开发者可根据实际场景灵活选择:PP-MSVSR(参数量1.45M)与PP-MSVSR-L(参数量7.42)。这里推荐使用后者,因为该大模型的参数量更大,修复效果更好:
ppgan.apps.PPMSVSRLargePredictor(output='output', weight_path=None, num_frames)
参数说明:
output_path (str,可选的): 输出的文件夹路径,默认值:output.
weight_path (None,可选的): 载入的权重路径,如果没有设置,则从云端下载默认的权重到本地。默认值:None.
num_frames (int,可选的): 模型输入帧数,默认值:10.输入帧数越大,模型超分效果越好。
随后进入项目的根目录:
cd PaddleGAN
编写test.py来查看视频参数:
import cv2
import imageio
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from IPython.display import HTML
import warnings
warnings.filterwarnings("ignore")
def display(driving, fps, size=(8, 6)):
fig = plt.figure(figsize=size)
ims = []
for i in range(len(driving)):
cols = []
cols.append(driving[i])
im = plt.imshow(np.concatenate(cols, axis=1), animated=True)
plt.axis('off')
ims.append([im])
video = animation.ArtistAnimation(fig, ims, interval=1000.0/fps, repeat_delay=1000)
plt.close()
return video
video_path = 'd:/倚天屠龙记.mp4'
video_frames = imageio.mimread(video_path, memtest=False)
# 获得视频的原分辨率
cap = cv2.VideoCapture(video_path)
fps = cap.get(cv2.CAP_PROP_FPS)
HTML(display(video_frames, fps).to_html5_video())
如此,就可以获得视频的原分辨率。
随后,进入项目的根目录,执行修复命令:
python3 tools/video-enhance.py --input d:/倚天屠龙记.mp4 \
--process_order PPMSVSR \
--output d:/output_dir \
--num_frames 100
这里使用PPMSVSR模型对该视频进行修复,input参数表示输入的视频路径;output表示处理后的视频的存放文件夹;proccess_order 表示使用的模型和顺序;num_frames 表示模型输入帧数。
随后展示修复后的视频:
output_video_path = 'd:/倚天屠龙记_PPMSVSR_out.mp4'
video_frames = imageio.mimread(output_video_path, memtest=False)
# 获得视频的原分辨率
cap = cv2.VideoCapture(output_video_path)
fps = cap.get(cv2.CAP_PROP_FPS)
HTML(display(video_frames, fps, size=(16, 12)).to_html5_video())
修复效果:

除了视频超分外,PaddleGAN中还提供了视频上色与补帧的功能,配合上述的PP-MSVSR一起使用,即可实现视频清晰度提高、色彩丰富、播放更加行云流水。
补帧模型DAIN
DAIN 模型通过探索深度的信息来显式检测遮挡。并且开发了一个深度感知的流投影层来合成中间流。在视频补帧方面有较好的效果:
ppgan.apps.DAINPredictor(
output_path='output',
weight_path=None,
time_step=None,
use_gpu=True,
remove_duplicates=False)
output_path (str,可选的): 输出的文件夹路径,默认值:output.
weight_path (None,可选的): 载入的权重路径,如果没有设置,则从云端下载默认的权重到本地。默认值:None。
time_step (int): 补帧的时间系数,如果设置为0.5,则原先为每秒30帧的视频,补帧后变为每秒60帧。
remove_duplicates (bool,可选的): 是否删除重复帧,默认值:False.
上色模型DeOldifyPredictor
DeOldify 采用自注意力机制的生成对抗网络,生成器是一个U-NET结构的网络。在图像的上色方面有着较好的效果:
ppgan.apps.DeOldifyPredictor(output='output', weight_path=None, render_factor=32)
output_path (str,可选的): 输出的文件夹路径,默认值:output.
weight_path (None,可选的): 载入的权重路径,如果没有设置,则从云端下载默认的权重到本地。默认值:None。
render_factor (int): 会将该参数乘以16后作为输入帧的resize的值,如果该值设置为32, 则输入帧会resize到(32 * 16, 32 * 16)的尺寸再输入到网络中。
AI技术通过分析视频中的图像信息并应用图像处理和修复算法,自动修复视频中的缺陷、噪声、模糊等问题,以提高视频的观看质量和可用性,配合语音克隆等技术,从而让演员在某种程度上实现“数字永生”。
Recommend
-
49
好久不见,后台有收到朋友留言,问前端周刊是不是不做了?实际上不是,我在酝酿更好的内容提供形式!经过两个月的精心准备,很高兴跟大家宣布:我又回来了,并且给关注前端周刊的同学准备了礼物,前端周刊明天开始提供新的内容形式:定期推送 3 到 5 分钟主题聚焦...
-
72
360手机这一年:销量不见增长,周鸿祎的耐心还剩多少?-36氪360手机这一年:销量不见增长,周鸿祎的耐心还剩多少?36氪的朋友们·2017-12-14 00:1...
-
102
全新翻拍版《倚天屠龙记》今日正式开机,多位主演官方宣传照曝光,其中包括大陆演员曾舜晞扮演的张无忌、陈钰琪扮演的赵敏,而1994年版《倚天》中扮演周芷若的周海媚本次将变身灭绝师太。
-
59
全程不见一片雪,但这简直是我见过最酷炫的滑行短片!! 滑雪大神Candide Thovex的新作。。。
-
69
小米提前完成1亿部出货量小目标,华为今年有望卖出2亿部。智能手机厂商屡创新高之时,不知道有没有想过,某个阴暗的角落里,老牌PC厂商正默默抽泣。
-
57
PC一定程度上已经是“被抛弃”的传统产业。被用户“抛弃”,被PC厂商“抛弃”,被媒体和公众“抛弃”。大伙一同把PC抬上滑梯,又合力把它推进滑道。
-
10
山水画看腻了?PaddleGan带你灵魂转换! - 飞桨PaddlePaddle的个人空间 - OSCHINA - 中文开源技术交流社区 ...
-
6
石家庄-哈尔滨 1990年撰文:鲁雨涵,责编:石鸣,来源:
-
7
English | 简体中文 PaddleGAN PaddleGAN provides developers with high-performance implementation of classic and SOTA Generative Adversarial Netwo...
-
5
借助So-vits我们可以自己训练五花八门的音色模型,然后复刻想要欣赏的任意歌曲,实现点歌自由,但有时候却又总觉得少了点什么,没错,缺少了画面,只...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK