

酷家乐线下环境稳定性建设实践
source link: https://tech.kujiale.com/ku-jia-le-xian-xia-huan-jing-wen-ding-xing-jian-she-shi-jian/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

1 环境建设背景
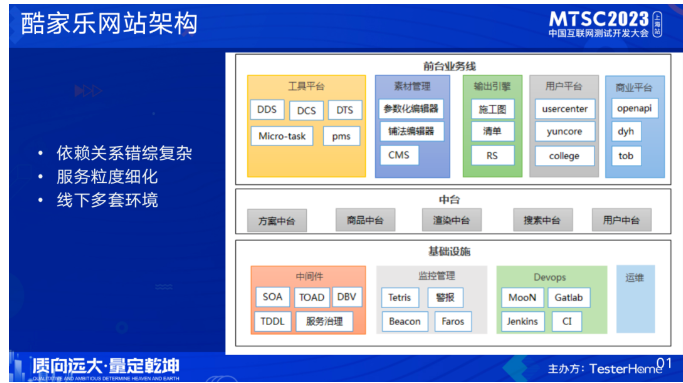
首先介绍下酷家乐的前后端架构,后端架构和大部分的互联网公司类似,分为前台、中台、基础设施,是一套微服务的架构体系,服务间依赖关系错综复杂,并且随着业务的发展服务粒度也逐渐细化,数量在增多,同时相对于线上环境,线下环境更加复杂,并且环境有多套,也加大了环境维护和治理的难度。
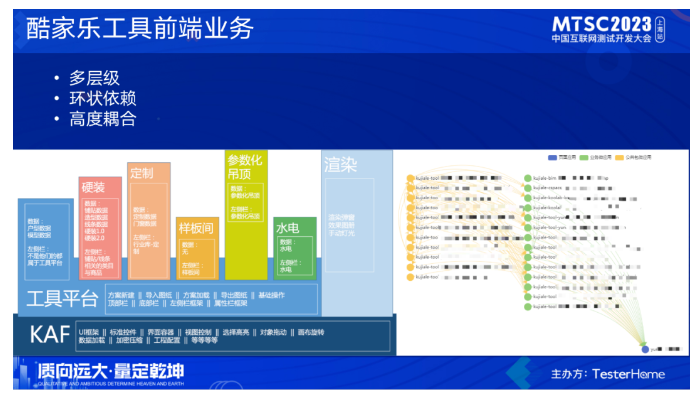
再来看下我们的工具前端架构,工具前端承载了大量的业务逻辑和算法,非常复杂,它有这么几部分组成
- kaf框架,它包含了公共组件和通用操作
- 业务微应用,各业务微应用间的依赖错综复杂
整体表现是层级多、依赖呈现环状、且高度耦合,这个复杂的依赖也加大了我们对环境治理的难度。
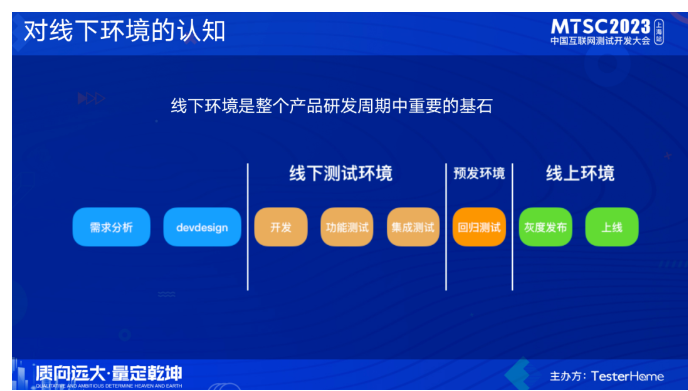
业界对线下环境的认知:整个产品研发周期中一个重要的基石。线下环境在整个研发迭代周期中有着非常重要作用,一般的研发周期可以从需求分析开始中间经历各种环节,最终上线发布,从代码开发阶段开始,各种活动就已经和线下环境紧密相关联,它直接关系到我们整个迭代周期是否顺畅。
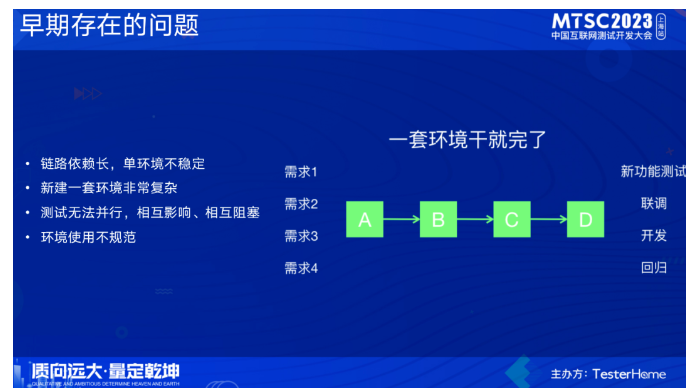
随着业务的发展,服务数量持续性增长, 线下测试环境的数量剧增,环境日常维护的难度也在上升, 同时我们对线下测试环境稳定性的要求也上升到新的高度。
2 线下环境标准化建设
在环境治理早期,容器化在酷家乐还没推开来,要构建一套环境非常复杂,各种配置、资源申请等等。同时存在链路依赖长且不稳定、没有统一的使用规范,大家都在一套环境上开发测试,导致并行问题,相互影响、相互阻塞。为什么会有这些问题?一个原因是受限于基础中间件和基础设施的能力,另一个原因是规范标准的不明确不统一 。
我们线下环境的建设和治理是随着基础设施、中间件的演进而逐步进行的。当我们具备soa路由的能力后,对线下环境做了标准化的定义。首先,我们定义了一套基线环境,基线(stable)环境的version是default,当其他版本进行请求的时候,没有找到对应的版本,会默认路由到default上。功能和项目测试环境也叫fe环境,是基于基线构建各自的测试服务,其余都是基于基线环境,包括服务、数据库等。集成测试环境(sit),也是有一套全量的服务,数据库、中间件和基线(stable)环境共用一套 。
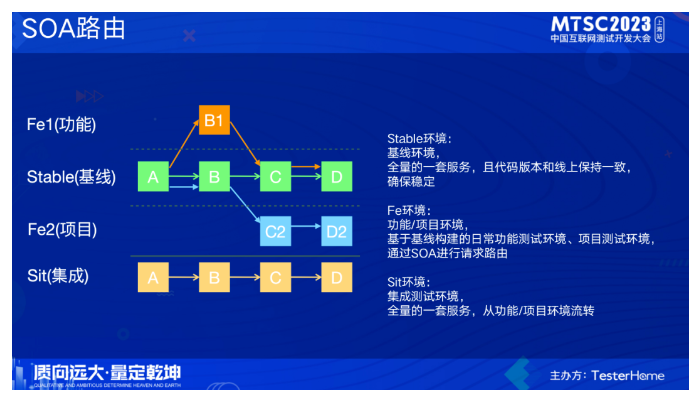
定义了各环境后,我们对各环境的流转也做了规范。其中fe作为功能测试环境,sit是集成测试环境。当完成功能测试后代码会流转到sit环境,完成集成测试后再流转到beta环境,prod是生产环境,代码部署到prod后会会自动流转到stable,这样从流程上保证了stable环境的代码稳定性。数据库和中间件线上线下分为两套,好处是维护方便,没有数据同步的问题。
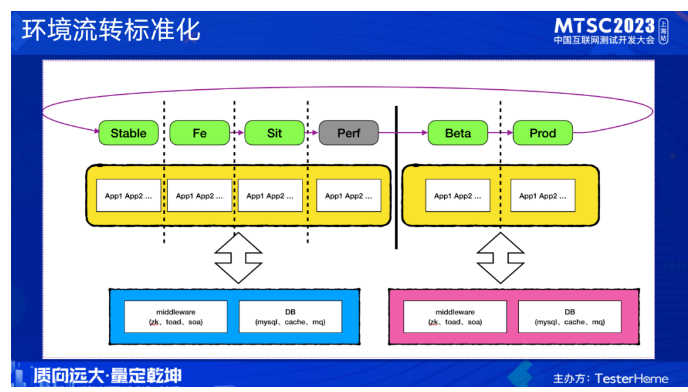
基于我们定义的环境流转标准化,在各环境阶段,配套定义了我们的研发活动,比如feature环境需要做什么事情、要达到什么程度才能进行流转,sit环境需要做哪些准备,bug如何修复流转等

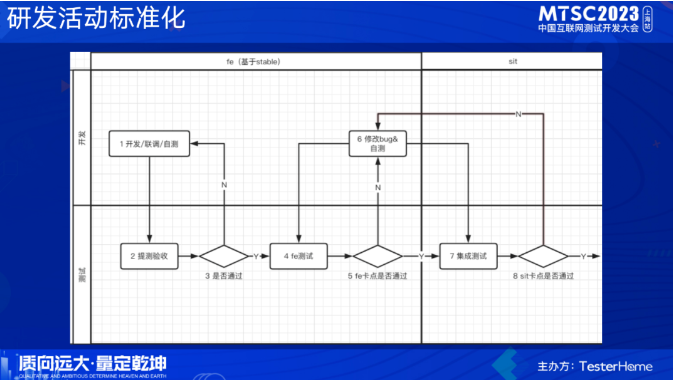
在这一套环境标准、对应的流程、卡点落地后,基本上解决了并行测试、相互影响、相互阻塞、以及一些环境使用的规范性问题。

3 线下环境稳定性建设
线下环境标准化建设完成后,按照这套标准,已经能较好的支持日常的研发测试活动。随着业务的发展和架构的变化,渐渐的暴露出一些新问题,线下环境前面也提到过复杂度高,比线上环境更加复杂,我们没有一个人或团队去做日常运维,出了问题去定位、解决效率比较低,基线环境由于是自动化部署的,关注度比较低,经常性会有服务挂了或缺失的情况。随着这些问题的积累,终于在21年底爆发了,一会网站挂了全崩、一会是工具进不去,近3个月的时间,测试环境挂了近30次,其中最严重的是我们的注册中心(zk)间歇性抖动,导致批量服务的掉注册的情况,要恢复得全量重启对应的问题服务,开发测试疲于本命,已经严重影响了日常开发测试的进度,也是借着这个契机我们展开了新一轮的线下环境稳定性治理工作。

那么我们该如何进行治理呢?上万的pod稳定性如何保障?首先我们先对问题进行分析,环境的组成可以大体上分为这几类:服务、基础中间件、硬件设施。他们出问题后影响面是依次提升的。硬件设施问题:基于成本问题考虑,我们线下环境是在自建机房搭建的,且自建机房的硬件设施稳定性不高,遍地都是过保的机器,机器经常会挂。基础中间件:出了问题难恢复、基本不能自愈、且数据库数据缺少备份,有数据丢失风险。业务服务:影响面小,但出问题的频繁高,比如代码问题导致的业务不可用、针对业务服务的线下监控也非常混乱,基于成本考虑,线下环境pod配置较低,也导致了经常性的性能问题。
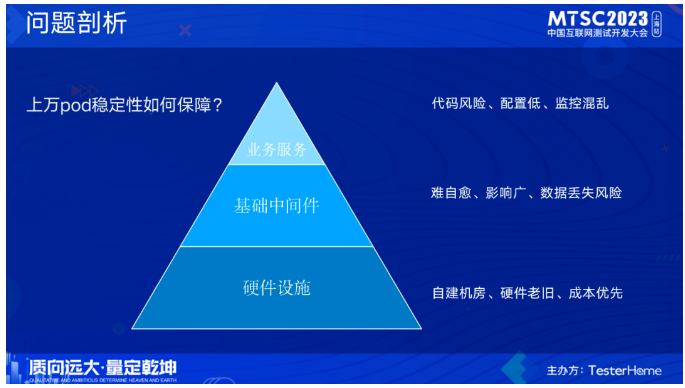
剖析完问题后,下一步就是进行治理,我们整体的治理思路是:从问题出发,不局限于问题本身,进行拓展和体系化的治理。线下环境特性就决定了:他肯定会出问题。那么我们要考虑的是如何降低出问题的频率,出了问题如何快速恢复,并且在做到这些的前提下如何形成一套长效机制。针对硬件设施、基础中间件、业务服务,我们分别从基础建设、事前预防、事发应急、日常运营这几个方面入手进行治理。比如事发应急,在出问题后,如何快速定位、快速恢复,解决问题三板斧重启、回滚、扩容?我们在这几方面做了一些能力的拓展。

3.1 基础建设
自愈和高可用:我们主要是利用了k8s提供的能力,我们把数据库也都统一迁移到了k8s上,实现数据库出问题也能分钟级恢复。启用Probe:Probe是用于检测和监控应用程序容器健康状态的一种机制,它可以通过定期执行预定义的检查来确定容器是否正常运行,并根据检查结果采取相应的操作。Kubernetes提供了三种类型的Probe:Readiness Probe(就绪探针)、Startup Probe(启动探针)、Liveness Probe(存活探针),应用了这三种probe后,服务存活能力大大提升。启用HPA:水平Pod自动伸缩器,通过检测应用cpu使用率判断是否进行动态扩缩容,这个很好的解决了因为服务性能问题导致的环境问题。关键节点防单点:核心服务和关键节点做到至少两个pod,防止单点的情况,这个点看着简单,但确实非常的有效。

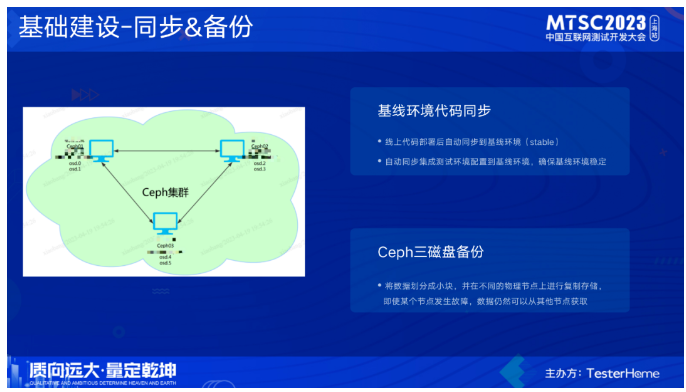
在同步方面,prod环境部署后会自动部署到stable环境,同时对stable环境部署做了限制,除了prod环境流转的代码外,只允许部署release分支。除了代码同步部署,相对应的配置也会进行同步,确保基线(stable环境的稳定)。在备份方面,我们利用了Ceph的能力,Ceph是一个开源的分布式存储系统,将数据复制到多个节点上,并提供故障检测和自动恢复机制,确保数据的可靠性和持久性。
3.2 事前预防
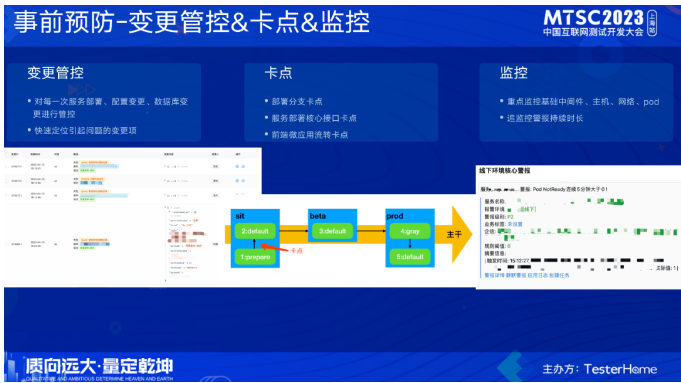
前面也提到了,线下环境肯定会出问题,那么如何进行事前预防,尽快、尽早的去发现问题或者扼杀在萌芽之中呢?我们对业务核心链路做了梳理定义,并针对每个环境(这里指sit、stable)做了自动化巡检,第一时间发现问题并处理。除了自动化巡检,还建设了中间件存活检查、业务服务的存活检查。

我们把线下环境相关的变更接入了变更管控系统,在发生问题的时候协助快速定位。卡点建设方面:结合我们的分支管控的规范,后端服务部署sit只允许部署release分支的代码,从一定程度上保证了sit环境的稳定性;这里重点讲一下前端的部署,前端微应用在集成后,会有一些运行时的错误,这类错误在构建的时候发现不了,在各自的测试环境也可能发现不了,只有当代码都集成到一个环境的时候会发现,当出现运行时报错后,前端页面也就挂了,为了避免这类问题,在sit的default版本前面新增了一个prepare版本,要流转sit的default版本只能从prepare进行流转,这样就可以提前把问题暴露在prepare,我们在prepare上会进行一些核心功能的巡检,巡检挂了就会在prepare流转default的时候进行卡点,只有解决了问题并通过巡检才能进行流转。
3.3 事发应急
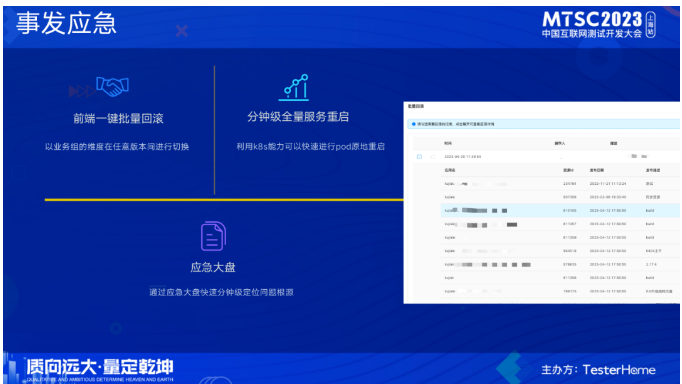
当出现问题时,时间是非常宝贵的,解决问题需要争分夺秒。但因为前端微应用间的高耦合,当出现前端问题时,单个微应用的回滚可能解决不了问题,且问题定位时间也比较久,基于这个原因,我们建设了前段批量回滚的能力,当前端出现问题时,可以一键批量回滚到指定的版本,做到分钟级恢复。
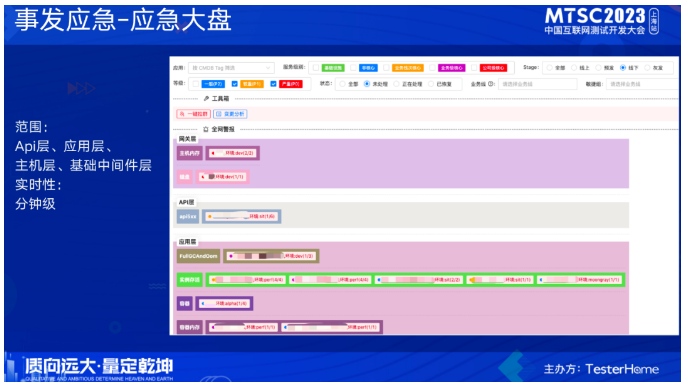
我们利用k8s的能力,实现不拉镜像的原地重启,可以选择性批量重启,分钟级就能重启完上千个pod。它可以很好的解决zk出现问题或抖动批量掉服务注册信息的问题,同时一些配置变更、数据库迁移需要批量重启时也能很好应对。解决问题首先要定位到问题,结合前面提到的变更管控我们可以快速知道是哪些变更引起的问题,但是还不能定位到具体的问题点,因此我们利用了应急大盘的能力,它对应的警报进行了分层,包括api层、应用层、主机层、基础中间件层,涵盖的范围非常广,通过这个大盘可以快速的知道当下我们的环境发生了什么,快速定位问题。
3.4 日常运营
前面我们做的主要是能力和工具的建设,完成这一系列建设后,日常我们还有一个专门的虚拟小组在利用这些能力和工具进行线下环境的日常运营。环境小组的日常运作机制如下图。
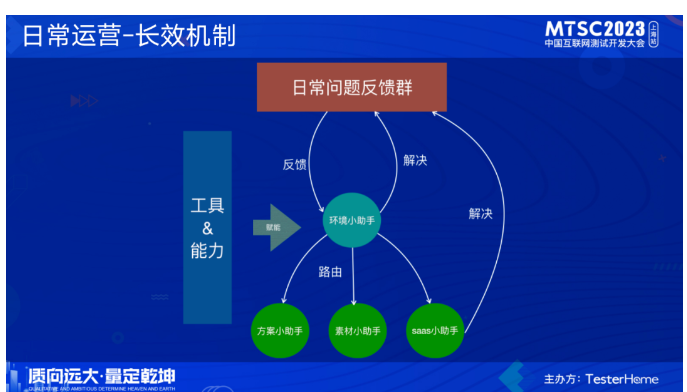
做了这么多事情,那么线下环境到底稳不稳,健不健康,我们需要拿具体的数据出来证明。这里是我们在用的一些指标,通过这些指标基本上就能衡量出环境的稳定性情况。
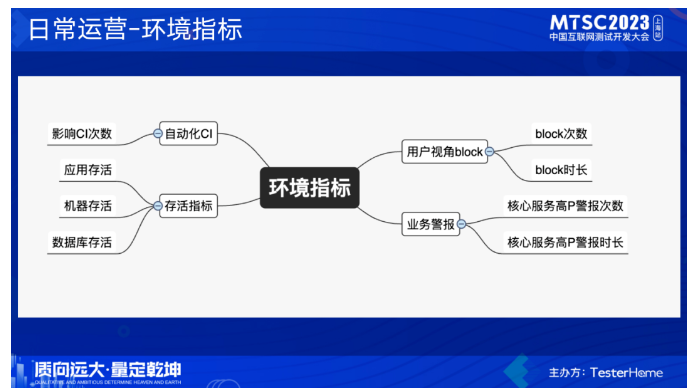
经过这一系列的治理后,目前整套机制已经运作的比较流畅了,环境block次数和时长都呈现下降趋势。

4 总结展望
在标准化建设方面,我们定义了线下基准环境,再辅助以规范、流程,这套落地后已经能较好的支持日常的研发测试活动。随着新的问题出现,我们又开展了新一轮的稳定性建设治理工作,主要从基础建设、事前预防、事发应急几个方面做了工具和能力的建设,再通过日常运营利用工具和能力形成完成的长效机制。

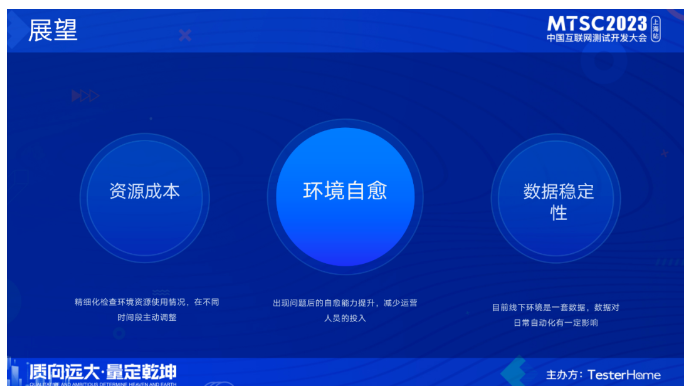
后续我们再资源成本、环境自愈、数据稳定性上还会做进一步探索。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK