

Bayes Theorem for Text Classification in NLP | Medium
source link: https://ujjwal-dalmia.medium.com/a-beginners-guide-to-bayes-theorem-53fb86839a20
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

A Beginner’s Guide To Bayes Theorem
Foundation For Text Classification (NLP)
Photo by Kelly Sikkema on Unsplash
This tutorial intends to explain the mathematical construct of the Bayes Theorem using an intuitive example.
Let’s get started.
The Story — Your annual appraisal ratings
Consider you are part of the innovation team in your organization. In the last ten years of your service, you were the top rater for six years. Given this year’s appraisals are around the corner, you are curious if you will be a top rater again or not.
While the excitement builds in, you know you have received the best innovation award that should work in your favor. But, given it is more of subjective thought, you want someone to help you prove this mathematically. You reach out to your friend in the data science team and seek his help.
He ensures you that he can help but asks for some additional information. His questions and your responses were as follows:
- Out of the six times, you were a top rater, how many times did you receive the innovation award? — You responded 5
- Out of the four times, you were not a top rater, how many times did you receive it? You responded 1
The moment he gets these answers, he does some calculations and confirms that you have an 83.3% chance of being a top rater again. Wow, but how?
Approaching Logically
Understanding Prior
As the first step, let’s ignore the information on our innovation award. The table below contains the details of the last ten years of your service and lists the years in which you were a top rater.

Top Rating (Image by Author)
If we go by historical data, out of ten years of our service, you received the top rating for six years. Keeping this information in mind, the probability of us getting the best rating is 60% (6/10). We call this probability Prior.
Prior — A prior is the probability of an outcome driven by our historical belief without considering any extra information (innovation award in this case).
Understanding Evidence
Without the information on the innovation award, our chances of being a top rater were 60%. We have modified our previous table to now include this information corresponding to every year. We call this additional information evidence.
Evidence — Evidence is the additional information that helps arrive at better estimates of having observed an outcome.

Evidence (Image by Author)
Understanding Posterior
Now that we have the additional information on your innovation award, the logical question which you will try and answer is:
What are the chances of getting the top rating, given I received the innovation award?
From the evidence table, there were six years (highlighted in green) when you received the award. Out of these, you were a top rater in 5. Therefore, given the evidence, the probability of you receiving the best rating is 83.3% (5/6). We call this probability posterior.
Posterior — A posterior probability is the revised estimate of having an outcome backed by the new evidence
Formal Definition — Going Mathematical
Bayes theorem provides the mathematical construct of the explanation given in the previous section. Let’s look at the notations and the formula for the same:
Notations
- Prior — P(A) — This notation indicates the probability of an event A. In our case, this is our original probability estimate of getting the top rating (60%).
- Prior Complement — P(A’) — This notation indicates the probability of event A not occurring. In our case, this is the original probability estimate of not getting the top rating (40%).
- Probability of evidence & event occurring together — P(A∩E)
- Probability of the evidence given the event has happened— P(E|A) —This notation indicates the chance of observing evidence E given that the event has occurred. We did not do this calculation in the previous section and will explain it in the next section.
- Probability of evidence given event complement— P(E|A’) — This notation indicates the chance of observing evidence E given that the event has not occurred. We did not do this calculation in the previous section and will explain it in the next section.
- Posterior— P(A|E) — This notation indicates the probability of an event A, given we have observed the evidence E. In our case, this was the revised probability of getting the top rating (83.3%).
Bayes Theorem Formula
The formula for Bayes Theorem is as follows:

Bayes Theorem — Simple Version (Image by Author)
The above formula is just a mathematical representation of our logical explanation:
- P(E) or probability of observing the evidence(irrespective of events and non-events) is the number of years you got the innovation award.
- P(A∩E) or probability of observing both: the evidence and the event(excluding the cases where the evidence occurred along with non-events) is the years you got the innovation award and the top rating.
For the sake of completion and, as you will find in most of the standard texts, we can break down this formula further.

Bayes Theorem — Broken Down Version (Image by Author)
Deriving Broken Down Version of Bayes Theorem
To understand how we arrived at the broken-down version of the Bayes Theorem, let’s look at the following diagram:

Deriving Broken Down Version (Image by Author)
- Breaking down P(A∩E) — Here, we are talking about events and evidence occurring together, P(A) and P(E). Since evidence should happen along with the event, we can’t take complete P(E). It will be the probability of evidence given event that is P(E|A)
- Breaking down P(E) — As we saw, the evidence can occur in both event and non-event scenarios. Therefore, P(E) is the sum of the probability of the event and evidence, P(A∩E), and event complement and evidence P(A’∩E).We can arrive at the calculation for P(A’∩E) in the same way as P(A∩E) in the previous point.
Re-calculating Results
Let’s re-calculate our results using the Bayes Formula. Our problem statement fits into simple Bayes formula looks as below:
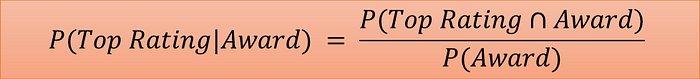
Bayes Theorem Fit to Example (Image by Author)
The broken-down calculation of our problem is as follows:

Calculation of Components (Image by Author)
It gives the same result as observed in the previous section.
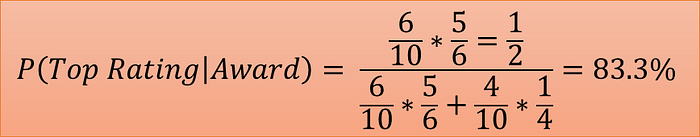
Final Calculation (Image by Author)
Closing note
On a lighter note, we all understand what goes behind an organization’s annual appraisal, but this was an attempt to use the scenario and understand a basic mathematical formulation that plays a critical role in one of the most common NLP Tasks.
Stay tuned for our next story, where we will explain the application of the Bayes Theorem in the most popular machine learning algorithms for text classification, The Naive Bayes. Till then:
- HAPPY LEARNING ! ! ! !
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK