|
|
I'm surprised this isn't firmly attached to the top of HN right now for the entire day. This is a tiny company (appears 30 or so people?) that just scored a 2B valuation, produced easily the most performant 7B model and a 7B*8 MOE model that performs at the level of a 70B requiring the inference power of a 14B. I feel this could be a potential bigger threat to OpenAI than Google or Anthropic. I gather with the huge recent investment they'll be able to a) scale out to a reasonable traffic load in the near future and b) attract the best and brightest researchers put off w/ various chest puffing and drama that has been front and center in this industry.
|
|
|
 |
|
Yes, I'm aware there's been a ton of recent chatter. Most of these are dupes though so it's really just Mixtral, their funding, and now their commercial offering. My argument is opening up the commercial offering is perhaps the biggest story yet simply because of all excitement this company has been able to generate.
|
|
|
|
Agreed. By far the most impressive company out of the current AI wave. They managed to put out the gold standard for 7B models in like 6 months, and are quickly moving up the scale. I mocked the funding round back in March as being signs of hype, ($300m for a team of 3 with just an idea?) but clearly I didn't know the details. Really remarkable execution. They may well be on their way to eat all use cases that don't need gpt-4 performance and hopefully soon tackle the big leagues as well. Exciting times!
|
|
|
|
In some ways I see this as a sign that LLMs possibly aren’t that hard to iterate on now that the cat is out of the bag. A small team can push the state of the art in just 6 months? It feels like this is more a circumstance of the state of LLMs presently and less a statement on Mistral. I wouldn’t it be surprised if we see 10+ other new $1B+ companies spring up because of how much room for improvement there is in the space.
|
|
|
|
Well said. OpenAI's biggest contribution wasn't serving GPT-4, it was proving that big LLMs are AGIs. Rushing to gold is easy; discovering it ain't. Since we've found a correct path, low-hanging fruit is plentiful. Throw more compute at it. Work smarter not harder (optimize). Graft on simple ideas for big gainz (e.g. RAG, MoE, chain-of-thought, etc). We moved from "GPT Who?" to...all of this, in a year. I now run an AGI at a bookish 13-year-old's level on my MacBook. The trend of hardware/software advances are astonishing. And this is just the beginning.
|
|
|
|
AGI, thanks 4 lmao. Either that or you're trolling.
|
|
|
|
I figure AGI will need a lot of parts to it, the same way our brain does, but having the language part figured out is I would guess is about 1/4 of what we need to solve to get there. So it's not AGI, but I would say it's a big chunk of what we need to get to AGI.
|
|
|
|
I have to disagree. I think language will be emergent from AGI, not the other way round. LLMs are neat, but likely wont have a place in an AGI.
|
|
|
|
> I'm surprised this isn't firmly attached to the top of HN right now for the entire day. It's kind of hard to tell what it is from both the blog post and their homepage. So only people really familiar with AI will grasp the relevance. But your comment certainly helps.
|
|
|
|
Mistral is in France though and the EU is throwing cold water on "AI" at the moment. I think this hurts them in the long run.
|
|
|
|
Or it could help them be more globally competitive because they’ll have built their product to accommodate the EU rules and will be ready if/when other countries introduce something similar. Maybe in 1970 someone was arguing that Volvo is handicapped because Swedish safety regulations have become so stringent that their cars can’t compete on price elsewhere. Turns out it was exactly Volvo’s strength to be ahead of the curve on regulation.
|
|
|
|
It's possible, but the AI space right now is all about the vibes and even the French President isn't feeling it[0]. The job market for AI/ML people is white hot right now and this is something Mistral has to try to explain around in an interview. I hope they do well despite it. [0]https://www.ft.com/content/9339d104-7b0c-42b8-9316-72226dd4e...
|
|
|
|
Regulations are accumulative though, not just relative to your era. So a critique in 2023 would be more relevant than one in 1970 as the pure scale of it has increased dramatically. I've seen a few graphs showing staffing counts and budgets for US regulatory agencies have grown exponentially since the 1970s (adjusted for inflation), while it was relatively flat before then in the 60s. Economic regulation growth in the US has grown steadily while social regulations (workplace, climate, healthcare, transportation etc) grew dramatically. Adding in TSA / Homeland security and it's a hockey stick. https://regulatorystudies.columbian.gwu.edu/sites/g/files/za... I'd be curious to see similar charts for the EU.
|
|
|
|
The EU’s new AI Act is the first regulatory action in the world targeted specifically at AI models. In that sense it’s now 1970 for this domain specifically.
|
|
|
|
In a democracy I'd expect regulation to grow alongside population and productivity. It would be interesting if it didn't, actually.
|
|
|
|
> Turns out it was exactly Volvo’s strength to be ahead of the curve on regulation. That's a weird analogy. I don't remember Volvo ever being that big. If anything they're bigger now than they used to be (I mean: I don't remember a world with lots of Volvo when I was a kid... I may be wrong though). And with about 650 000 vehicles sold per year they're not in the Top 25 car manufacturer worldwide by number of cars sold.
|
|
|
|
Yeah I think most people would consider Volvo - a standard bearer for safe vehicles for over 100 years - a success
|
|
|
|
The EU makes in it’s proposed law a lot of exceptions for open models. It might be a big selling point for mistral (or Facebook) but maybe tricky to deal with for closed models like OpenAI.
|
|
|
|
Have to see the final text, of course, but open source models apparently got some breaks in the final agreement last Friday.
|
|
|
|
French engineering and computer science education really emphasizes math and theory. That is an advantage in AI.
|
|
|
|
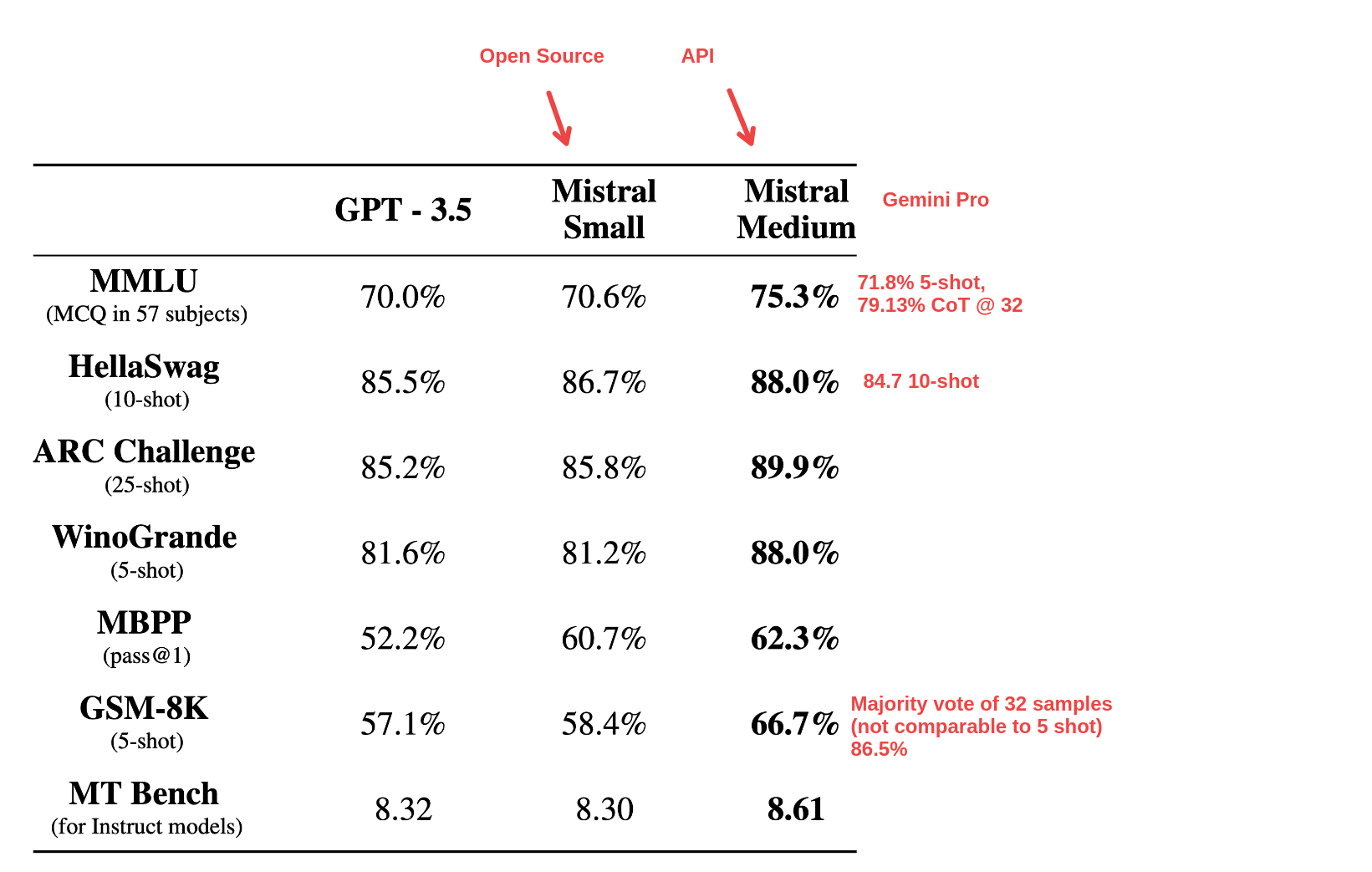
This is extremely impressive if benchmarks translate to real-world performance [1]. The mistral-medium beats GPT3.5 and also Gemini Pro (Google's best available model) with a huge margin on all available comparable benchmarks: https://screenbud.com/shot/c0d904e3-24a3-4c23-a1e4-2f18bc021...[1] I would expect real world-performance gap to be even larger if Mistral 7B is anything to go by. The fact that safety filters are opt-in is a huge benefit (even for safe applications).
|
|
|
|
>also Gemini Pro (Google's best available model) Pretty sad for Google if their next big AI thing is already being beaten by a small company with a tiny fraction of their resources.
|
|
|
|
Google in general looks like they're lost their touch and are kinda on a downward spiral. Trying to squeeze out as much as they can from Youtube is I think a major sign of that, usually attempts like that start to pop up in burnt-out companies that are heading to their end. As for AI they have a lot of world-class talent but they somehow cannot transform that into a coherent product even though they did amazing stuff on the research side. It has been brought up many times on HN on how Google has a product-design problem and it seems to be true.
|
|
|
|
It does look like Google will be the Yahoo of 2030 Perhaps even sooner, given the pace tech is evolving nowadays comparing to when Google took over Yahoo's place.
|
|
|
|
They deserve it. Google is one of the big reasons why the web is the way it is today - bloated, spammy, overly SEO-optimized.
|
|
|
|
You probably don't remember how the web just before Google. Just as bloated, spammy and SEO-optimized as it is today, just more primitive tech-wise. Bloat was measured in kb, but it was significant on dialup, spam was crude, but so were the blocking solutions, and SEO was hidden lists keywords, which was enough to heavily influence search results. In fact Google did a lot against it. Google search was clean, fast, and with no ads, GMail had one of the best spam filters, and Google algorithms were highly resistant to SEO of the time. Time have passed, Google is now part of the problem, but it is not alone there, and for some time, Google really did good.
|
|
|
|
But we did get faster browsers, pretty cool browser tech. Also, Google search results have page loading speed factored in, which is also a plug for everyone.
|
|
|
|
Not sure if it's a conspiracy theory or a known thing but I read it once and it stuck in my mind that Google's projects are a form of distraction and friction to prevent people catching up with them (e.g. HTTP3).
|
|
|
|
Google is solving problems at Google scale, where improving something by 2% yields millions. Re: "distracting other companies", there's however this famous essay by Joel Spolsky (2002): https://www.joelonsoftware.com/2002/01/06/fire-and-motion/ > Think of the history of data access strategies to come out of Microsoft. ODBC, RDO, DAO, ADO, OLEDB, now ADO.NET – All New! Are these technological imperatives? The result of an incompetent design group that needs to reinvent data access every goddamn year? (That’s probably it, actually.) But the end result is just cover fire. The competition has no choice but to spend all their time porting and keeping up, time that they can’t spend writing new features. Look closely at the software landscape. The companies that do well are the ones who rely least on big companies and don’t have to spend all their cycles catching up and reimplementing and fixing bugs that crop up only on Windows XP. The companies who stumble are the ones who spend too much time reading tea leaves to figure out the future direction of Microsoft. People get worried about .NET and decide to rewrite their whole architecture for .NET because they think they have to. Microsoft is shooting at you, and it’s just cover fire so that they can move forward and you can’t, because this is how the game is played, Bubby.
|
|
|
|
I'm not sure I follow: what kind of Google projects are you talking about? Google internal ones or external ones? And depending on the answer, who should get distracted by it? ... aaaand then in the end, catching up to what?
|
|
|
|
Example: Kubernetes, convincing 60% of the industry that they don't know how to run production workloads anymore.
|
|
|
|
Google was once a small company beating some big players with a fraction of their resources.
|
|
|
|
Google is conflicted about AI. Having AI do searches for you and summerize the results is both way more expensive than normal searches and means way fewer ads are shown. Google can't do anything about it either - consumers will prefer the chat approach and will go where it is offered. Google has to offer it, or people will go to ChatGpt and Bing, but at the same time they lose a lot of money each time people opt for the chat summary. It is way expensive for Bing too, but they don't care because their market is growing and since the only thing people used to search Bing for was how to download Chrome and how to change the default browser, they aren't losing a lot this way.
|
|
|
|
Imagine a search engine that tries to persuade you a sponsored product is the answer to your problems, and it can use its knowledge about you to do so. I think search products will be OK - it will just be stranger than we expect.
|
|
|
|
One area Google has a big advantage is in its massive crawling and indexing infrastructure. As good as ChatGPT plus is, the search with Bing feature is so. damn. slow. It seems do be doing a normal search request in the background rather than using any kind of index, and multiple links are visited serially rather than concurrently. Did I mention that it’s slow? That’s a large and difficult problem obviously and one Google is clearly well-positioned for if they can ever catch up on the model front.
|
|
|
|
> Google is conflicted about AI. Having AI do searches for you and summerize the results is both way more expensive than normal searches and means way fewer ads are shown But those ads would be compelling and more valuable. There is no reason to believe the current inference LLM architecture is the optimal one (as shown by Mistral's MoE) - future inference will likely be cheaper than it is currently. The sentiment that Google's goose is cooked I'm seeing in this thread seems like wish-fulfillment to me. Especially considering that the upstarts also don't have a clear road to profitability
|
|
|
|
OpenAI can raise a ton of more cash, so they may not have a road to profitability yet, but they have long time before they crash.
|
|
|
|
Big was used for porn. Don’t forget porn. Torrents too. Bing going legit and genuinely threatening google wasn’t on my bingo card for sure.
|
|
|
|
And honest content. One order of magnitude more honest at least; Google is like asking the Kremlin for truth.
|
|
|
|
Higher Winogrande score than GPT-4. Surprising given others are more GPT-3ish
|
|
|
|
> Gemini Pro (Google's best available model) It's not really "available" though, is it? I won't buy any PR benchmarks until the models are publicly available, there's too much variation based on how the models need to toned back for safety reasons before being released to the public
|
|
|
|
This is crazy. If they release this new model as open source, that would be very exciting!
|
|
|
|
|
No, they’ve released the weights for Mistral-small. They haven’t released the weights for Mistral-medium.
|
|
|
|
They might’ve been referring to mistral-medium, the larger version, which is not open source. The open-sourced version was the small variant.
|
|
|
|
https://docs.mistral.ai/platform/pricingPricing has been released too. Per 1 million output tokens: Mistral-medium $8 Mistral-small $1.94 gpt-3.5-turbo-1106 $2 gpt-4-1106-preview $30 gpt-4 $60 gpt-4-32k $120 This suggests that they’re reasonably confident that the mistral-medium model is substantially better than gpt3-5
|
|
|
|
Do we have estimates of the energy requirements for these models? I just did some napkin math, looks like inference on a 30B model with a GTX 4090 should get you about 30 tokens/sec [1], or 100k tokens/hour. Considering such systems consume about 1 kW, that's about 10 kWh/1M tokens. Based on the current cost of electricity, I don't think anyone could get below 2 ~ 4 $ per 1M token for a 30B model. [1] https://old.reddit.com/r/LocalLLaMA/comments/13j5cxf/how_man...
|
|
|
|
FWIW - I need to remeasure but - IIRC my system with a 4090 only uses ~500w (maybe up to 600w) during inference of LLMs, the LLMs have a lot harder time saturating the compute compared to stable diffusion I'm assuming because of the VRAM speed (and this is all on-card, nothing swapping from system memory). The 4090 itself only really used 300~400w most of the time because of this. If you consider 600w for the entire system, that's only 6kWh/1M token, for me 6kWh @0.2USD/kWh is 1.2USD/1M tokens. And that's without the power efficiency improvements that an H100 has over the 4090. So I think 2$/1M should be achievable once you combine the efficiencies of H100s+batching, etc. Since LLM's generally dwarf the network delay anyway, you could host in places like washington for dirt cheap prices (their residential prices are almost half of what I used for calculations)
|
|
|
|
Are you using batch size 1 with LLMs? Larger batch sizes get much higher utilization.
|
|
|
|
Well with those numbers, I pay $0.1/kWh so theoretically $0.6/1M tokens
|
|
|
|
Depends how and where you source your energy. If you invest in your own solar panels and batteries, all that energy is essentially fixed price (cost of the infrastructure) amortized over the lifetime of the setup (1-2 decades or so). Maybe you have some variable pricing on top for grid connectivity and use the grid as a fallback. But there's also the notion of selling excess energy back to the grid that offsets that. So, 10kwh could be a lot less than what you cite. That's also how grid operators make money. They generate cheaply and sell with a nice margin. Prices are determined by the most expensive energy sources on the grid in some markets (coal, nuclear, etc.). So, that pricing doesn't reflect actual cost for renewables, which is typically a lot lower than that. Anyone consuming large amounts of energy will be looking to cut their cost. For data centers that typically means investing in energy generation, storage, and efficient hardware and cooling.
|
|
|
|
During the crypto boom there were crypto miners in China who got really cheap electricity from hydroelectric dams built in rural areas. Shipping electricity long distance is expensive (both in terms of infrastructure and losses - unless you pay even more for HVDC infrastructure), so they were able to get great prices as local consumers of "surplus" energy. That might be a great opportunity for cheap LLMs too.
|
|
|
|
Batching changes that equation a fair bit. Also these cards will not consume full power since llm are mostly limited by memory bandwidth and the processing part will get some idle time.
|
|
|
|
Is $0.2-0.4/kWh a good estimate for price paid in a data center? That’s pretty expensive for energy, and I think vPPA prices at big data centers are much lower (I think 0.1 is a decent upper bound in the US, though I could see EU being more expensive by 2x).
|
|
|
|
The 4090 is considerably more power-hungry compared to e.g. an A100, however.
|
|
|
|
If comparing apples to apples, the 4090 needs to clock up and consume about 450 W to match the A100 at 350W. Part of that is due to being able to run larger batches on the A100, which gives it an additional performance edge, but yes in general the A100 is more power efficient.
|
|
|
|
|
Well the 4090 is certainly less efficient on this. They are using H100's or better no doubt. If they optimize for TPUs, it'll be even better.
|
|
|
|
I get 40 tok/sec on my M3 Max on various 34B models, I gather a desktop 4090 would be at least 80?
|
|
|
|
If you take input tokens in consideration is more like 5.25 eur vs. 1.5 eur / million tokens overall. Mistral-small seems to be the most direct competitor to gpt-3.5 and it’s cheaper (1.2 eur / million tokens) Note: I’m assuming equal weight for input and output tokens, and cannot see the prices in USD :/
|
|
|
|
Does the 8x7B model really perform at a GPT-3.5 level? That means we might see GPT-3.5 models running locally on our phones in a few years.
|
|
|
|
That might be happening in a few weeks. There is a credible claim that this model might be compressible to as little as a 4GB memory footprint.
|
|
|
|
You mean the 7B one? That's exciting if true, but if compression means it can do 0.1 token/sec,it doesn't do much for anyone.
|
|
|
|
No, I am referring to the 7Bx8 MoE model. The MoE layers apparently can be sparsified (or equivalently, quantized down to a single bit per weight) with minimal loss of quality. Inference on a quantized model is faster, not slower. However, I have no idea how practical it is to run a LLM on a phone. I think it would run hot and waste the battery.
|
|
|
|
Really? Well that's very exciting. I don't care about wasting my battery if it can do my menial tasks for me, battery is a currency I'd gladly pay for this use case.
|
|
|
|
I think we're at least a couple generations away where this is feasible for these models, unless say it's for performing a limited number of background tasks at fairly slow inference speed. SOC power draw limits will probably limit inference speed to about 2-5 tok/sec (lower end for Mixtral which has the processing requirements of a 14B) and would suck an iPhone Max dry in about an hour.
|
|
|
|
Maybe this way, we'll not just get user-replaceable batteries in smartphones back - maybe we'll get hot-swappable batteries for phones, as everyone will be happy to carry a bag of extra batteries if it means using advanced AI capabilities for the whole day, instead of 15 minutes.
|
|
|
|
Or maybe we'll finally get better batteries! Though I guess that's not for lack of trying.
|
|
|
|
Not true. Not everyone is building chat bot or similar interface that requires output with latency low enough for a user. While your example is of course incredibly slow, there are still many interesting things that could be done if it was a little bit quicker.
|
|
|
|
What kind of use cases run in an environment where latency isn't important (some kind of batch process?) but don't have more than 4GB of RAM?
|
|
|
|
Price sensitive ones, or cases where you want the new capability but can't get any new infrastructure.
|
|
|
|
Not LLMs, but locally running facial and object recognition models on your phone's gallery, to build up a database for face/object search in the gallery app? I'm half-convinced this is how Samsung does it, but I can't really be sure of much, because all the photo AI stuff works weirdly and in unobservable way, probably because of some EU ruling. (That one is a curious case. I once spent some time trying to figure out why no major photo app seems to support manually tagging faces, which is a mind-dumbingly obvious feature to support, and which was something supported by software a decade or so ago. I couldn't find anything definitive; there's this eerie conspiracy of silence on the topic, that made me doubt my own sanity at times. Eventually, I dug up hints that some EU ruling/regs related to facial recognition led everyone to remove or geolock this feature. Still nothing specific, though.)
|
|
|
|
|
|
I don’t think it’s safe to assume any of this. It’s still limited release which reads as invite only. Once it hits some kind of GA then we can test and verify.
|
|
|
|
It's safe to assume they are confident it's better than 3.5. But people can be confident and wrong.
|
|
|
|
We won’t know anything until it becomes a wider release and can test it.
|
|
|
|
Multiple people have tested it. Code and weights are fully released .
|
|
|
|
|
|
All they have to do to beat Anthropic's Claude is to skip having a permanent waitlist and let the credit cards get charged.
|
|
|
|
Do they all use the same tokenizer? (I mean, Mistral vs GPT)
|
|
|
|
No. Mistral uses sentencepiece and the GPT use tiktoken.
|
|
|
|
> This suggests that they’re reasonably confident that the mistral-medium model is substantially better than gpt3-5 How did you reach the conclusion? Maybe they are counting on people paying extra just to prevent vendor lockdown.
|
|
|
|
The only vendor lock-in to GPT3.5 is the absence (perceived or real) of competitors at the same quality and availability.
|
|
|
|
I understand how Mistral could end up being the most popular open source LLM model for the foreseeable future. What I cannot understand is who they expect to convince to pay for their API. As long as you are shipping your data to a third-party, whether they are running an open or closed source model is inconsequential.
|
|
|
|
I pay for hosted databases all the time. It’s more convenient. But those same databases are popular because they are open source. I also know that because it’s open source, if I ever have a need to, I can host it on my own servers. Currently I don’t have that need, but it’s nice to know that it’s in the cards.
|
|
|
|
Open source databases are SOTA or very close to it, though. Here the value proposition is to pay 10-50% less for an inferior product. Portability is definitely an advantage, but that's another aspect which I think detracts from their value: if I can run this anywhere, I will either host it myself or pay whoever can make it happen very cheap. Even OpenAI could host an API for Mistral.
|
|
|
|
> Here the value proposition is to pay 10-50% less for an inferior product. OpenAI just went through an existential crisis where the company almost collapsed. They are also quite unreliable. For some use cases, I'll take a service that does slightly worse on outputs, but much better on reliability. For example, if I'm building a customer service chat bot, it's a pretty big deal if the LLM backend goes down. With an open-source model, I can build it using the cloud provider. If they are a reliable host, i'll probably stick with them as i grow. If not, I always have the option of running the model myself. This alleviates a lot of the risk.
|
|
|
|
The big advantage of a hosted open model is insurance against model changes. If you carefully craft and evaluate your more complex prompts against a closed model... and then that model is retired, you need to redo that process. A lot of people were burned when OpenAI withdrew Codex, for example. I think that was a poor decision by OpenAI as it illustrated this exact risk. If the hosted model you are using is open, you have options for continuing to use it should the host decide to stop offering it.
|
|
|
|
You may be fine with shipping your data to OpenAI or Mistral, but worry about what happens if they change terms or if their future models change in a way that causes problems for you, or if they go bankrupt. In any of those cases, knowing you can take the model and run it yourself (or hire someone else to run it for you) mitigates risk. Whether those risks matter enough will of course differ wildly.
|
|
|
|
If I'm happy with my infrastructure being built on top of the potential energy of a loadbearing rugpull, I'd probably stick with OpenAI in the average use case.
|
|
|
|
Same reason why you would use GPT-4. Plenty of people pay for that, some pay really good money.
|
|
|
|
gpt-3.5 is heavily subsidized. Mistral may just be aiming for a more sustainable price for the long run.
|
|
|
|
|
They wrote "may", it was clearly speculation about one possible explanation, not an absolute statement of truth.
|
|
|
|
"endpoints are available in early access" is in reality "we have a waitlist (of unspecified length) for early access to endpoints" When I try to access: “Access to our API is currently invitation-only, but we'll let you know when you can subscribe to get access to our best models.”
|
|
|
|
Considering that their email verification has been in different states of brokenness for the last hour, I’m guessing they were not as ready as they thought for the publicity ;)
|
|
|
|
To be fair and complete after my parent post, Mistral granted API access to me after 3 days.
|
|
|
|
> Mistral-embed, our embedding endpoint, serves an embedding model with a 1024 embedding dimension. Our embedding model has been designed with retrieval capabilities in mind. It achieves a retrieval score of 55.26 on MTEB. Is there any information if this embedding model is or will be open source?
|
|
|
|
> Our API follows the specifications of the popular chat interface initially proposed by our dearest competitor. I like it, also made me laugh
|
|
|
|
|
By chance I noticed that Fabrice Bellard's TextSynth server has newly added support for Mistral 7B model. > 2023-10-21: CUDA support in the Windows version, mistral model support. Speculative sampling is supported. BNF grammar and JSON schema sampling. > mistral_7B_instruct_q4 - 3.9GB - Mistral 7B chat model https://bellard.org/ts_server/
|
|
|
|
It's interesting that many platforms, like Lemonfox.ai, offer Mistral finetunes at lower prices. They also already announced a Mistral 8x7B API. This raises the question of whether they'll still publish future models as open-source (like the Medium version) if they want to make money.
|
|
|
|
Without open weights why would anyone care about them? By the time they could compete with gpt4 there's probably be gpt5 already.
|
|
|
|
> Mistral-medium. Our highest-quality endpoint currently serves a prototype model, that is currently among the top serviced models available based on standard benchmarks. This is interesting. This model outperforms ChatGPT 3.5. I'm not sure what type of model it is, and it is not open-sourced.
|
|
|
|
Ah! So that what, we're using in ollama is named the tiny version? > Mistral-tiny. Our most cost-effective endpoint currently serves Mistral 7B Instruct v0.2, a new minor release of Mistral 7B Instruct. Mistral-tiny only works in English. It obtains 7.6 on MT-Bench. The instructed model can be downloaded here.
|
|
|
|
Yeah. This naming is interesting and speaks of lofty goals indeed. :)
|
|
|
|
Tiny and small, those two have been released, yes.
|
|
|
|
> Mistral-tiny. Our most cost-effective endpoint currently serves Mistral 7B Instruct v0.2, a new minor release of Mistral 7B Instruct. Mistral-tiny only works in English. It obtains 7.6 on MT-Bench. The instructed model can be downloaded here. "download here" link is to v0.1 [0]. Oversight or are they holding back the state of the art tiny model? [0]: https://huggingface.co/mistralai/Mistral-7B-v0.1
|
|
|
|
|
|
Wow, beating ChatGPT-3.5 is really an accomplishment. Congrats! That's literally the default of OpenAI's product. I had to fallback to GPT-3.5 the other day because I ran out of usage on ChatGPT-4 (playing 20 questions lol). So I really hope someone can come up on GPT-4! For me GPT-3.5 isn't good enough for daily things, it gets too much wrong.
|
|
|
|
I’m surprised no one has commented on the context size limitations of these offerings when comparing to the other models. The sliding window technique really does effectively cripple its recall to approximately just 8k tokens which is just plain insufficient for a lot of tasks. All these llama2 derivatives are only effective if you fine tune them, not just because of the parameter count as people keep harping but perhaps even more so because of the tiny context available. A lot of my GPT3.5/4 usage involves “one offs” where it would be faster to do the thing by hand than to train/fine-tune first, made possible because of the generous context window and some amount of modest context stuffing (drives up input token costs but still a big win).
|
|
|
|
Mixtral 8X7B has a 32k-token context window. GPT-3.5 models have a context window of 4k-16k. As for the sliding window attention, the model does not lose all the information about the tokens before the sliding window. Hidden states store information about past tokens.
|
|
|
|
The sliding window does not lose the data but it does "decompose" it so that it can't be recalled verbatim. For analyzing code (feed it n classes and ask it to create a class using all of them to accomplish a task) that isn't good enough. It's also not good enough for some of the "corporate business" use cases we tried putting Mistral and other sliding window models to use on, where you need it to re-use verbatim or reference specific portions of one of n documents fed into it as input tokens. Again, sufficient training can overcome these limitations. But that's only for cases where the corpus of input documents is static or at least contains significant reuse.
|
|
|
|
>The sliding window technique really does effectively cripple its recall to approximately just 8k tokens which is just plain insufficient for a lot of tasks. What are you basing this observation on; personal experience, or is there a benchmark somewhere confirming it?
|
|
|
|
I found this discussion on the local llama subreddit that digs a little bit more into what effects the sliding window might have, in case you or anyone else reading this comment thread finds it interesting: https://old.reddit.com/r/LocalLLaMA/comments/17k2mwq/i_dont_.... It refers to the original Mistral 7B though not the new Mixtral fwiw
|
|
|
|
Real world testing and experience. If you only need the llm to retain the "gist" of the input tokens in order to return a "related" answer, the sliding window design is fine. But if you need actual technical analysis or tasks that involve verbatim referencing, quoting, recomposing, etc based off parts of the input documents, it doesn't work. I tried using it for "business document" use cases but have ran into this with code as well; the latter might be a better explanation given where we're having this discussion. If you only need the llm to retain the general shape of your inputs so it can reuse them to influence the output, the sliding context is fine. But if you need it to actually reuse code verbatim from the input that you fed it (or to remember the api calls and their surrounding context verbatim to recall from a sample of just one that this api must be called before that api, when the prompt includes instructions to that effect) the "decomposition" of the input tokens with the sliding model is insufficient and the llm completely fails at the assigned task.
|
|
|
|
Competition is how the world moves forward. I'm super glad small and big players have competitive models. The thing that makes me a bit sad is how announcements show the benchmarks but they way they test is tweaked to make their metrics favorable. They aren't apple to apple benchmarks across different paper publications. Super grateful that they openly share the weights and code with Apache license. 25 shot - is having 25 tries and selecting the best answer. Is anyone working on an open benchmark where they take the major models and compare them apples to apples.
|
|
|
|
Well done, Mistral! "Show, don't tell" par excellence.
|
|
|
|
So, what would be the hardware setup for this? Can it run on 1 GPU and swap between experts.
|
|
|
|
I just signed up for the API waiting list. I have been enjoying running Mistral-7B on my home system, and it feels right to give them some of my paid for API business.
|
|
|
|
Until we can verify, I think it’s safe to place the in the smoke category. It’s invite only so until it hits GA it’s impossible to know if the pricing is real and the true capabilities of what they are offering.
|
|
|
|
This actually begs the question: Does anyone know the kind of actual infrastructure something like gpt4-32k actually run on? I mean when I actually type something in the prompt, what actually happens behind the scenes? Is the answer computed on a single NVidia GPU? Or is it dedicated H/W not known to the general public? How big is that GPU? How much RAM does it have? Is my conversation run by a single GPU instance that is dedicated to me or is that GPU shared by multiple users? If the latter, how many queries per seconds can a single GPU handle? Where is that GPU? Does it run in an Azure data center? Is the API usage cost actually reflective of the HW cost or is it heavily subsidized? Is a single GPU RAM size the bottleneck for how large a model can be? Is any of that info public ?
|
|
|
|
|
So 14400 H100 for GPT-4, but that's just a fraction of the new system that Azure is building for OpenAI. FWIW, I most enjoyed the 29TB machine demo at the end.
|
|
|
|
While we can't be sure of most of those answers, they have stated it is running in Azure. Also we can probably assume the pricing is likely to be somewhat in proportion to the cost to run (possibly subsidised to gain market, but they are unlikely to be taking a giant/unsustainable loss per query here, particularly as they seem to announce price decreases when they increase model performance).
|
|
|
|
Azure VMSS (uniform orchestration) + 2000 to 3000 GPU enabled servers. I'm not sure about what kind of GPU is on these servers.
|
|
|
|
> Is the answer computed on a single NVidia GPU? Most likely given that one of their open positions for a GPU programmer includes > high technical competence for writing custom CUDA kernels and pushing GPUs to their limits. Edit: only narrows it down to NVidia hardware, IDK if single GPU or not.
|
|
|
|
Is there anything Mistral + tuned on ChatGPT4?
|
|
|
|
|
They are two different news about one thing. Not dupe.
|
|
|
|
By the same submitter, minutes apart and both on the homepage.
|
|
|
|
>They are two different news about one thing. Then they'd be differing opinions?
|
|
|
|
Two out of the top three stories today on HN! What an achievement. Is mistral.ai a YC property?
|
|



{kind=link}