

eBPF应用程序开发:快人一步
source link: https://www.cnxct.com/ebpf-application-development-beyond-basics-zh_cn/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

eBPF应用程序开发:快人一步 – CFC4N的博客
这篇文章提供了关于eBPF应用程序开发的指南。正如标题所示,文章主要关注eBPF 201的概念,而不是提供另一篇关于eBPF技术是什么的入门级文章。我们提供了简短的介绍,但主要关注需要部署生产eBPF应用程序的开发团队的下一组概念和最佳实践。我们将探讨使BPF应用程序可以在多个内核版本和环境中部署和维护的编程语言和工具链。
eBPF 101: 简短回顾
BPF/eBPF是由轻量级的隔离虚拟机和一组辅助函数组成的操作系统内核技术。在本文中,我们关注Linux内核中的eBPF,尽管它也适用于其他操作系统平台,如Windows和FreeBSD。
这项技术使用户能够在内核中运行提供的程序,以扩展内核的功能。验证程序在加载到内核之前会检查BPF程序,以确保它们不会危及内核的可靠性。这些程序会被JIT(Just-In-Time)编译成本机指令,因此它们足够高效,可以在性能要求最高的情况下执行,例如网络数据包处理。
总体的好处是以一种安全、更灵活且开发速度更快的方式为操作系统内核提供可编程性和可扩展性,而不是开发内核模块或直接增强主要内核功能本身。
下图中的图表显示了Linux内核中的BPF虚拟机、BPF程序可以附加的挂钩点以及BPF程序可用的各种映射和辅助函数。
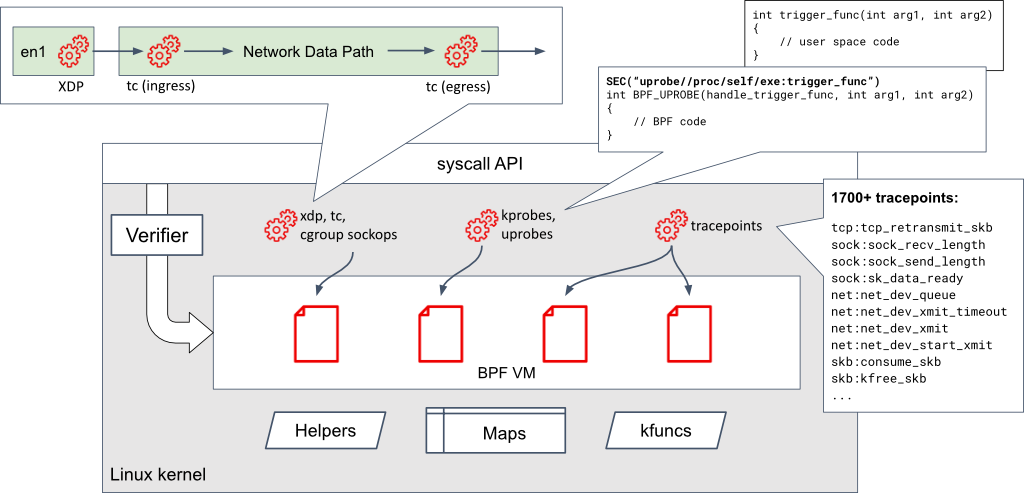
如果你对eBPF还不熟悉,eBPF详尽介绍将为你提供一个很好的基础,然后再阅读本文的其余部分。
技术成熟度
BPF已经从早期作为Linux内核的数据包过滤引擎(图2)的时代走来了很长的路。在过去的十年中,eBPF VM已经成为一种通用执行引擎,由Clang工具链支持,具有许多不同用途的程序类型和辅助函数。最近,重点放在了开发者和操作用户体验上,由BTF、CO-RE和libbpf支持。

BPF功能已经在从3.15到最新的6.x版本的许多内核中引入。在任何给定的内核版本中找出可用的功能集可能是困难的。BCC项目维护了一个有用的BPF功能按Linux内核版本排序的列表,它可以帮助你确定在给定的Linux内核中的功能可用性。
eBPF应用程序开发常见问题解答
以下是开发人员在学习eBPF应用程序开发时常遇到的一些常见问题。在本文中,我们试图提供这些问题的一些答案,同时注意到这个领域仍在不断发展,一些内容将在未来发生变化。
Q:用于eBPF应用程序的编程语言和开发工具有哪些选择,以及每种选择的利弊是什么?
A:这将在本文的选择您的eBPF应用程序栈部分中进行讨论。
Q:我们了解eBPF的概念,但迄今为止还没有进行任何内核开发。为了有效地开发eBPF应用程序,我们需要了解内核源代码的相关部分和开发环境吗?
A:开发内核经验不是开发基于eBPF的应用程序所必需的。然而,强烈建议对内核中相关的功能领域有很好的了解。例如,当开发网络应用程序时,您应该了解与网络套接字、内核数据包路径、netfilter功能等相关的一些内核内部内容。
Q:在跨目标方式开发eBPF应用程序时,其中开发涉及多个开发系统和内核版本,同时存在多个目标系统和平台,旨在实现跨所有这些平台的可移植性和可维护性,我们需要了解哪些内容?
A:这将在本文的eBPF应用程序跨开发、可移植性、CO-RE和内核API稳定性部分中进行讨论。
Q:有哪些实际的分发eBPF程序和在单个系统中并发安装来自多个供应商的程序的操作模型?
A:在撰写本文时,这是一个新兴的开发领域。目前,eBPF程序通常被打包为较大项目中的不可分割的子组件,例如Cilium或Pixie。结合和安装多个独立的基于eBPF的应用程序可能会导致不一致或错误的行为,特别是如果在使用的eBPF附加点中存在重叠(如在最近的案例中所示)。
新项目,如libxdp和bpfd,正在添加功能以解决此类操作问题。我们期望在未来的文章中更详细地介绍这些项目。
Q:上游核心eBPF开发模型是什么,我们如何跟踪仍在开发中的eBPF功能?
A:新的eBPF内核基础设施和功能是在Linux内核的“bpf-next” git存储库中开发的,最终合并到主要的Linux存储库中,作为正式的Linux内核发布的一部分。该过程在BPF开发FAQ中有更详细的描述。
此外,内核BPF函数越来越多地作为kfuncs(内核函数)添加。它们提供了eBPF应用程序可以调用的API,但相对于内核BPF辅助函数的稳定性较低,后者被认为是内核ABI的一部分。正在使用的kfunc API将得到支持和维护,但不属于内核ABI。
Q:在编写eBPF应用程序时,需要注意哪些软件许可要求?
A:Linux内核eBPF运行时的组件使用GPLv2许可证。这包括参考解释器、验证器、JIT编译器和BPF助手等组件。所有kfuncs和许多(但不是全部)BPF助手都是GPL许可的,这意味着BPF应用程序通常(尽管不总是)需要以GPL-v2兼容许可证发布。请注意,没有兼容许可归属的BPF验证器将不允许加载BPF应用程序。为了启用一些宽松的下游代码重用,应用程序可以考虑使用双重许可,此外将其BPF应用程序许可为诸如MIT、BSD-2-Clause等宽松许可证。有关更多详细信息,请参阅Linux内核文档的BPF许可指南。
Q:eBPF技术是否促进或与内核数据平面卸载技术交汇?
A:对于Linux内核功能,特别是网络功能的硬件卸载到智能网卡是一个广泛的话题,涵盖了许多超出本博客范围的技术。暂时简要说明一下,您确实可以利用eBPF技术来进行硬件卸载。例如,像ConnectX-6这样的某些智能网卡支持将基于XDP的eBPF程序从主机CPU卸载到网卡上的CPU。
选择您的eBPF应用程序栈
在启动新的eBPF项目时,开发团队需要决定使用哪种软件栈来开发计划中的应用程序。有多种编程语言和可用的库,具有不同的成熟度和与最新内核BPF功能的特性相匹配。
以下是eBPF应用程序的常见选择,也是新项目的不错选择:
这些应用程序开发栈如图3所示。
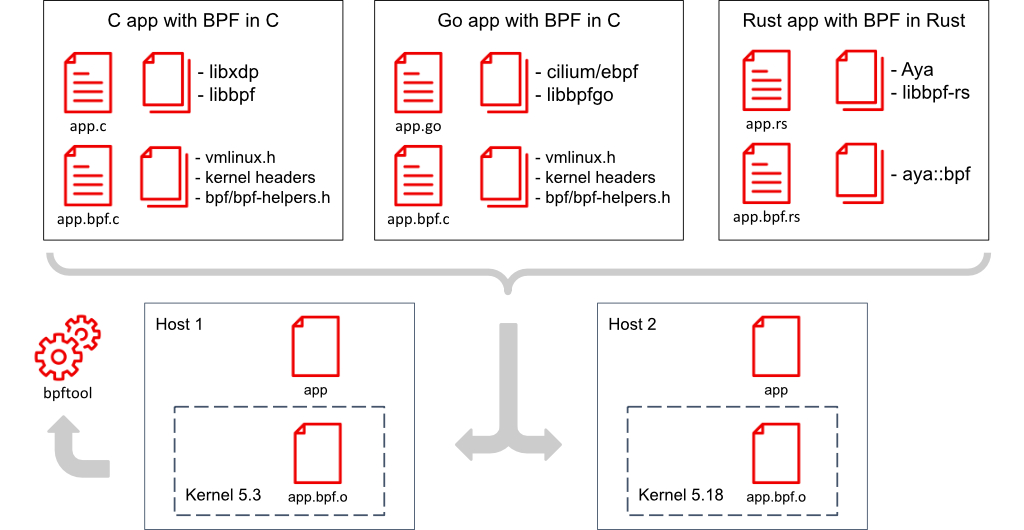
还有一种低代码选项,团队可以利用可用工具,如iproute2的tc、bpftool和bpftrace来处理计划中应用程序的用户空间和/或内核BPF程序。
需要注意的一个关键点是,以这种方式列出这些选项并不排除在这些选项以及其他选项之间混合和匹配的可能性。例如,您可以使用C编写内核空间eBPF程序,然后在用户空间使用Golang或Rust编写相应的程序,通常有很多理由这样做。还有更多的选项,包括通过直接调用内核ebpf系统调用或使用像BCC这样的框架编写自己的自定义eBPF加载程序。但通常情况下,本文列出的选项将更适合新项目,我们将讨论这些选项以阐明一些核心概念。
使用C和带libbpf(可选的libbpf-bootstrap)的C
这种软件栈选择通常是最全面的,支持最新的eBPF功能和工具。
关于libbpf
libbpf是一个C库,提供eBPF实用函数和定义,用户空间程序可以使用它来管理内核空间的eBPF程序。这个应用程序栈选项是最新的,是上游Linux源代码仓库的一部分,与最新的eBPF功能保持一致,并用于测试新的内核eBPF功能。这个库和内核BPF代码由内核开发人员共同编写、审查和测试,作为引入新的eBPF功能的一部分。libbpf还是CO-RE(Compile Once Run Everywhere)功能的官方实现,该功能在提供eBPF程序可移植性方面显著改进了开发人员的体验,后文将详细讨论。
在Linux源代码仓库中,libbpf位于tools/lib/bpf。API文档可在https://libbpf.readthedocs.io/en/latest/api.html 到。
与内核源代码分开维护的libbpf的镜像应该用于包含在应用程序中。该API包括一些关键的定义,如eBPF帮助函数的原型定义,用户空间类型定义以匹配相应的内核类型,并用于加载和附加程序以设置eBPF映射的函数。libbpf库于2022年中发布了1.0版本,并且正在积极开发,最近发布了1.2版本。
关于libbpf-bootstrap
libbpf-bootstrap是libbpf的伴随仓库之一,提供了使用libbpf功能的一组有用的模板和示例程序。这是一个快速编写用户空间程序的良好起点,该程序将与最新的eBPF功能一起使用。libbpf-bootstrap仓库还说明了使用bpftool实用程序准备eBPF骨架程序的方法。骨架是一组由用户空间程序使用的类型和函数的定义,以便轻松打开、加载、附加和销毁eBPF程序对象。
建议和要点
1. 这经常是编写eBPF应用程序时的一个不错的栈选择。
在我们看来,这种应用程序栈是开发团队采用的一个可靠选择,特别是如果需要使用C语言用户空间程序或者需要最新的eBPF功能,这些功能可能并不总是通过其他用户空间加载器和其他编程语言和工具的实用程序获得。
举例来说,在撰写本文时,这是作者用来管理、加载和附加使用新eBPF kfuncs(内核函数)的eBPF应用程序的几个可行选项之一。
2. 在应用程序仓库中将libbpf和bpftool作为git子模块包含。
我们还注意到,开发人员通常应通过将libbpf包含为其应用程序程序仓库中的Git子模块来使用libbpf。这可以确保他们始终使用libbpf的最新发布版本,而不是他们可能在开发系统上拥有的内核源代码版本,或者由Linux发行版捆绑的版本。
3. 考虑使用libbpf-bootstrap作为应用程序程序的参考仓库。
在作者看来,libbpf-bootstrap是用于新的eBPF项目或基于libbpf的应用程序的参考仓库。它作为使用libbpf的最佳实践示例进行维护(例如,使用libbpf和bpftool作为Git子模块)。
Go和C与Cilium ebpf、libbpfgo
当在Golang中编写eBPF应用程序的用户空间部分时,这是一个不错的选择。例如,当eBPF应用程序的用户空间部分是Kubernetes Operator或CRD控制器时,通常会使用Golang编写。
Cilium ebpf库是一个独立的纯Golang eBPF实用工具库,独立于Cilium项目的其他应用程序,比如Cilium Kubernetes CNI插件。libbpfgo是另一个此类eBPF实用函数库,用户空间Golang应用程序可以使用它来加载eBPF对象文件(从任何语言编译而来),附加到各种eBPF钩子点等等。
libbpfgo使用围绕我们在前一节中讨论的C语言libbpf库的Golang包装器调用,因此有可能支持更多最新的核心eBPF功能。Cilium eBPF库不是libbpf库的包装器,背后的社区略显多样化(相对于libbpfgo),包括供应商Isovalent和CloudFlare。
Rust and Rust with Aya
Aya是一个用于BPF应用程序开发的纯Rust库,旨在与libbpf具有功能相当。与上文描述的Cilium eBPF库类似,Aya不包含围绕C语言libbpf库的包装函数。正如前面提到的,用于eBPF内核程序的编程语言和工具链与应用程序的用户空间程序所使用的语言和工具无关。我们将在未来的一篇文章中详细描述这个选项,届时我们将介绍Aya和bpfd项目。
eBPF应用程序跨平台开发、可移植性、CO-RE和内核API稳定性
最佳实践的eBPF应用程序开发从一开始就考虑了跨平台开发、可移植性和可维护性。最近的eBPF内核增强功能,比如CO-RE(编译一次,随处运行)大大改进了这一领域的开发体验。
图4显示了一个支持不同开发环境和不同目标系统的开发模型。开发环境使用了前面讨论的C与libbpf。
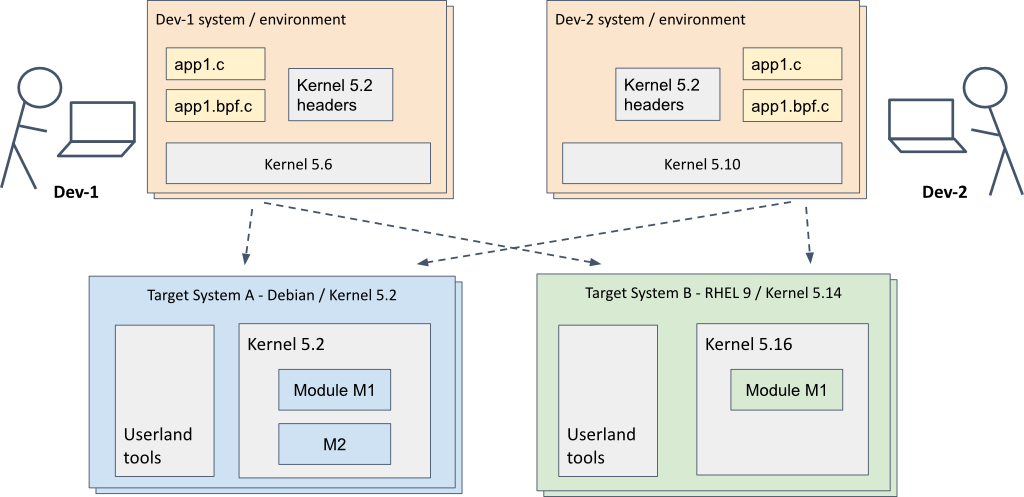
在图中,一个开发人员正在使用运行内核5.6的开发计算机,而另一位开发人员则使用内核5.10。这两位开发人员可以在两个不同的目标系统上进行测试,第一个目标系统运行带有内核5.2的Debian,而第二个目标系统运行Red Hat企业Linux,内核已升级到5.16版本。
直到最近,这种开发模型无法用于eBPF应用程序,特别是那些与在内核版本之间更改的原始内核数据类型和结构进行交互的应用程序。因此,eBPF应用程序必须在加载到目标系统时即时编译(使用其他加载功能,如BCC的内置CLANG/ LLVM)以获取实际目标系统内核的内核头文件和类型信息。
然而,被称为CO-RE(Compile Once Run Everywhere)的新eBPF基础架构使单个eBPF二进制对象能够在不同的内核版本上加载和运行,无需重新编译或复杂的解决方法。请参考本文及其附带的CO-RE指南,其中提供了有关CO-RE和开发人员最佳实践的出色详细信息。
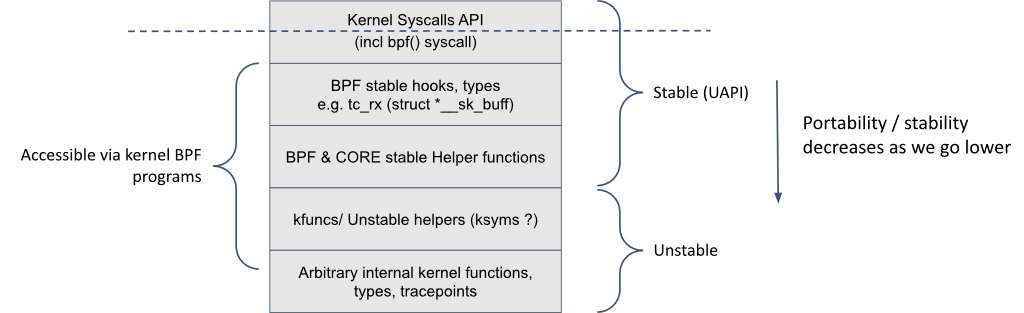
推荐和要点
1. 在可能的情况下,使用支持CO-RE的eBPF加载器,该加载器支持基于内核数据类型的重定位能力。
本文前一节中讨论的3种应用程序堆栈选项都支持CO-RE。其他eBPF加载器选项,如BCC框架,目前不支持CO-RE。
2. 遵循CO-RE最佳实践。
这包括使用编译器/Clang属性,例如__attribute__((preserve_access_index)),以确保eBPF程序使用的内核数据类型的可重定位性,使用诸如BPF_CORE_READ()宏之类的助手,以有效地访问内核数据,即使有多层指针间接引用,以及使用CO-RE功能来以编程方式检测内核版本和内核配置信息,以处理更复杂的内核数据类型更改,如CO-RE指南中所述。
3. 考虑使用 vmlinux.h 来简化包含头文件,而不是开发系统中打包的内核头文件。
vmlinux.h文件是可以通过bpftool工具生成的文件,用于包括内核映像中的所有数据类型。这是一个方便的单个头文件,供eBPF程序从中包括,而不是一组广泛而有些特殊的内核头文件,可能会因开发人员的系统而异。我们建议创建此文件的精简版本,只包括应用程序实际需要的内核定义。这可以确保:
- 与目标内核版本的数据类型保持一致
- 可以充分利用CO-RE重定位
- 具有适当大小的头文件,更容易维护
4. 针对所有目标内核版本和相关子系统配置测试eBPF应用程序。
即使遵循所有CO-RE最佳实践,也很重要测试任何eBPF应用程序,测试所有或一组宽泛的内核版本以及相关内核子系统和模块配置的变化,以确保在所有目标部署中具有完全的可移植性和正确性。
5. 确定应用程序所需的最低内核版本。
首先,阅读BPF功能文档,以确定包含所需功能的内核版本范围。例如:
- cgroup/connect4程序支持是在4.17中添加的。
- BPF有界循环是在5.3中添加的。
然后,您可以选择编写您的应用程序,仅使用内核版本中可用的eBPF函数,或者使用BPF功能探测来在运行时检测功能的可用性。
您的BPF程序可以检查内核版本:
#include <bpf/bpf_helpers.h>
extern int LINUX_KERNEL_VERSION __kconfig;
int probe_kernel()
{
if (LINUX_KERNEL_VERSION > KERNEL_VERSION(4, 18, 0)) {
/* 我们在支持的内核版本上 */
} else {
/* 记录错误并优雅退出 */
}
...
}您的BPF程序还可以探测单个内核功能或结构定义:
extern bool CONFIG_LWTUNNEL_BPF __kconfig __weak;
if (CONFIG_LWTUNNEL_BPF) {
/* 从BPF配置lwtunnel */
}
if (bpf_core_type_exists(struct bpf_ringbuf)) {
/* 使用ringbuf而不是perf缓冲区 */
}运行中的BPF程序的架构
下图显示了用户空间应用程序及其嵌入式BPF程序的视图。该应用程序链接到libbpf,libbpf代表应用程序创建BPF映射并加载程序。
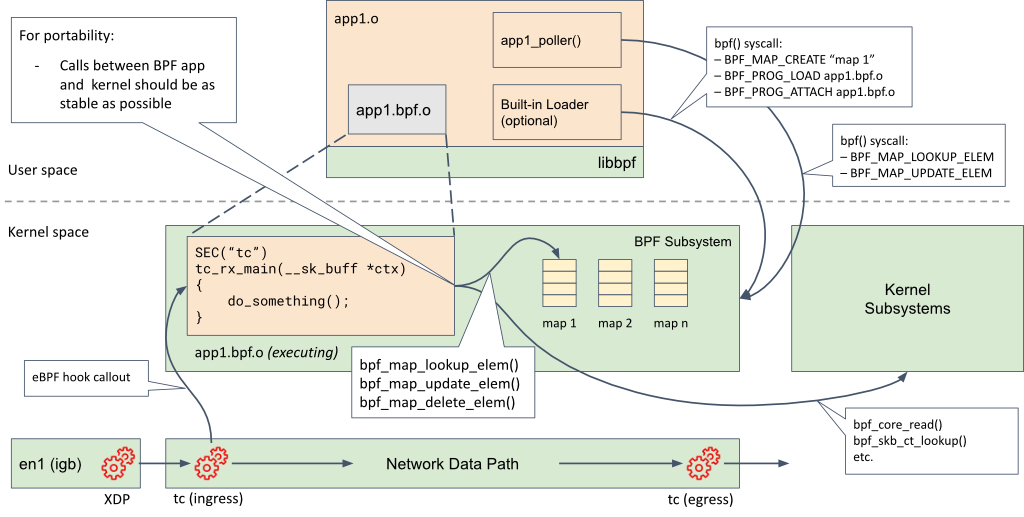
在此图中,我们可以看到BPF程序连接到网络数据路径中的tc钩子。用户空间应用程序和BPF程序共享访问由内核中的BPF子系统管理的映射。BPF程序还使用助手函数从其他内核子系统中访问数据。
使用libbpf的C应用程序示例
这里讨论的主题最好通过示例应用程序来演示。我们将使用DNS跟踪实用程序来突出显示主要要点。
libbpf-bootstrap为使用libbpf的C项目提供了一个很好的起点。在这里,我们通过复制libbpf-bootstrap的Makefile和项目布局,并根据自己的需求进行调整,创建了一个dns-trace实用程序项目:
.
├── Makefile
├── dns-trace.bpf.c # BPF代码
├── dns-trace.c # 用户空间代码
├── dns-trace.h # 共享定义
├── libbpf # libbpf git子模块
└── .output
├── dns-trace.skel.h # 骨架,由bpftool生成
└── vmlinux.h # 所有内核类型定义,由bpftool生成dns-trace实用程序有一个BPF部分,用于拦截DNS数据包,以及一个用户空间部分,用于解码DNS消息并报告各种指标。BPF程序捕获的数据以事件流的形式通过BPF环形缓冲区发送到用户空间程序。struct dns_event在BPF和用户空间程序中都被使用。请注意确保类型定义对两个编译单元都可以解析。
- 用户空间程序使用系统头文件,包括UAPI导出的内核类型,如
__u32和libbpf头文件。 - BPF程序也在包括生成的
<vmlinux.h>时具有访问UAPI导出的内核类型的能力,同时还包括了所有内核类型定义。
任何要包括在两个编译单元中的结构都需要使用UAPI导出的内核类型并避免内核的内部类型定义。
struct dns_event {
__u64 duration;
char ifname[IFNAMSIZ];
__u32 srcip;
__u32 dstip;
__u16 length;
unsigned char payload[MAXMSG];
__u16 id;
__u16 flags;
};访问内核数据结构
BPF程序连接到net_dev_queue内核跟踪点,以拦截主机上运行的任何程序发送或接收的所有数据包。跟踪点上下文包括一个指向保存数据包数据的struct sk_buff的指针。我们只对访问sk_buff->data和sk_buff->len字段感兴趣,因此我们可以使用CO-RE来访问它们。BPF程序定义了自己的struct sk_buff的私有版本,其中只包含我们需要的字段。该结构使用preserve_access_index属性进行注释,以便在加载BPF程序时进行CO-RE重定位。
struct sk_buff {
unsigned char *data;
unsigned int len;
} __attribute__((preserve_access_index));
struct trace_event_raw_net_dev_template {
struct sk_buff *skbaddr;
} __attribute__((preserve_access_index));此项目本地的struct sk_buff定义清晰地说明了我们实际需要的结构的子集。C代码使用BPF_CORE_READ()宏来访问struct sk_buff字段,再次在加载BPF程序时启用CO-RE重定位到运行的内核。
SEC("tracepoint/net/net_dev_queue")
int trace_net_packets(struct trace_event_raw_net_dev_template *ctx) {
unsigned char *data = BPF_CORE_READ(ctx, skbaddr, data);
unsigned int len = BPF_CORE_READ(ctx, skbaddr, len);
do_trace(data, len);
return BPF_OK;
}用户空间应用程序
用户空间应用程序通过生成的BPF程序骨架使用libbpf来加载BPF程序并访问BPF程序中定义的映射。骨架由项目Makefile中的bpftool gen skeleton生成。骨架派生自BPF程序,因此所有映射应该在BPF C代码中定义,然后通过用户空间代码中的骨架访问器引用。
生成的骨架提供了加载BPF代码和附加BPF程序的函数:
/* Load and verify BPF object file */
skel = dns_trace_bpf__open();
if (!skel) {
fprintf(stderr, "Failed to open and load BPF skeleton\n");
return 1;
}
/* Load & verify BPF programs */
err = dns_trace_bpf__load(skel);
if (err) {
fprintf(stderr, "Failed to load and verify BPF skeleton\n");
goto cleanup;
}
/* Attach tracepoints */
err = dns_trace_bpf__attach(skel);
if (err) {
fprintf(stderr, "Failed to attach BPF skeleton\n");
goto cleanup;
}从用户空间程序中设置和轮询BPF环形缓冲区所需的代码非常少:
struct ring_buffer* ringbuf =
ring_buffer__new(bpf_map__fd(skel->maps.dns_events), process_event, NULL, NULL);
while (!exiting) {
ring_buffer__poll(ringbuf, 100);
}应用程序使用与BPF程序共享的struct dns_event定义从BPF程序的环形缓冲区接收事件。
eBPF文档体系
BPF子系统和支持库拥有大量文档资源,但它们分散在不同的位置。以下是一些有用的链接,可帮助您访问最相关的文档:
需要注意的是,BPF领域没有单一的权威指南,而且仍有很多未记录的知识。
-
eBPF术语
- BTF: BPF类型格式是一种用于存储有关Linux内核或BPF程序类型信息的紧凑编码。它用于通过BPF CO-RE实现BPF程序的可移植性。
- CO-RE: BPF CO-RE(编译一次,到处运行)使得编写可在多个内核版本上运行的可移植BPF应用程序成为可能,无需修改或重新编译目标机器。
- 内核用户空间API(UAPI): UAPI是内核和用户空间之间的接口,由系统调用、头文件、sysfs、procfs、BPF辅助函数等组成。
原文来自 RedHat的博客 BPF application development: Beyond the basics 本文为机翻+人工矫正。
笔者的eCapture项目,用户空间加载器使用ebpfmanager类库,包装了cilium/ebpf类库,也是纯Go的加载器。在这里也推荐给大家。
CFC4N的博客 由 CFC4N 创作,采用 知识共享 署名-非商业性使用-相同方式共享(3.0未本地化版本)许可协议进行许可。基于https://www.cnxct.com上的作品创作。转载请注明转自:eBPF应用程序开发:快人一步
Recommend
-
13
天生玩酷快人一步,机械师新品发布会圆满收官! 2021-05-12 12:53:57...
-
2
依云's Blog搜索,快人一步 本文来自依云's Blog,转载请注明。 在一...
-
6
一文理清快人一步的比特币期货ETF与现货ETF有何区别PANews2021-10-23热度: 15676“推出比特币期货ETF不大会损害现货ETF的应用”。...
-
5
快人一步掌握好这个能力,这将可能改变你未来5-10年职业生涯! | 运营派 直播+录播 一年免费回看,不断巩固知识 ...
-
2
升级HarmonyOS 2最新版本,出门亮健康码快人一步!-品玩 升级HarmonyOS 2最新版本,出门亮健康码快人一步! 2小时前 最近一段时间,在人口流动较大的大城市疫情反复,防疫形势紧张,商场、地铁站、公交、餐厅...
-
5
犀牛的博客 姑苏城外一茅屋,万树梅花月满天
-
5
编辑导语:快人一步才能抢占先机,这份八月营销日历推给七月的你!本文分享了八月热点如建军节、七夕节、中元节等可借势营销的方向和参考案例,希望对你有所帮助。
-
3
ASA 广告上线中国大陆区已满一年,这一年来为了让广告主们更好地投放广告, ASA 广告后台多次进行调整...
-
4
功能解析|如何快人一步找到TikTok爆品,巧用TiChoo发现多个选品途径 ...
-
4
12月是全年话题热度最多的月份 来看看小编为大家整理的 12月热点营销日历 时刻准备,抢占时机!
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK