

深度解析自然语言处理之篇章分析 - techlead_krischang
source link: https://www.cnblogs.com/xfuture/p/17818058.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

深度解析自然语言处理之篇章分析
在本文中,我们深入探讨了篇章分析的概念及其在自然语言处理(NLP)领域中的研究主题,以及两种先进的话语分割方法:基于词汇句法树的统计模型和基于BiLSTM-CRF的神经网络模型。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。

篇章分析在自然语言处理(NLP)领域是一个不可或缺的研究主题。与词语和句子分析不同,篇章分析涉及到文本的更高级别结构,如段落、节、章等,旨在捕捉这些结构之间的复杂关系。这些关系通常包括但不限于衔接、连贯性和结构等方面,它们不仅对理解单一文本有重要意义,还在多文本、跨文本甚至跨模态的分析中起到至关重要的作用。从推荐系统的个性化内容生成,到机器翻译的文本质量优化,再到对话系统的上下文理解,篇章分析的应用场景极为广泛。
篇章分析的整体理念
篇章分析的核心理念是“高层次的语义和语用分析”。在这个视角下,文本不仅仅是词和句子的简单集合,更是信息和观点的有机组合。每个篇章元素都在与其他元素交互,形成更大的语义和语用结构。因此,篇章分析的目标不仅是理解各个单元(如句子、段落)如何构成一个统一和连贯的文本,更是在多层次、多维度上理解文本传达的深层含义。
内容之间的关联关系
-
篇章的衔接、连贯与结构: 这三个方面是篇章分析的基石。衔接关注句子或段落之间的明确联系,如转折、因果等;连贯性关注文本整体的流畅度和可读性;结构则从宏观角度审视文本,探讨如何更有效地组织信息。这三者相互关联,相互促进,共同构成了高质量的文本。
-
话语分割: 在深入到基于词汇句法树和循环神经网络的话语分割之前,理解这三个核心方面是至关重要的。话语分割方法试图在更细粒度上划分和理解文本,为后续的任务提供基础。
二、篇章分析的基础概念
什么是篇章?
篇章是由两个或更多的句子构成的,用于表达一个或多个紧密相关的观点或信息的文本单元。与单个句子或词汇不同,篇章包括更复杂的结构和含义,通常需要通过多个句子甚至多个段落来传达。
比如,在一篇关于气候变化的文章中,一个篇章可能会专门讨论极端天气现象的增加,从统计数据到具体的事件案例,再到可能的影响,构成一个完整的讨论。
篇章分析的重要性
篇章分析是自然语言处理中非常重要的一部分,因为它能够帮助机器更好地理解人类语言的复杂性和多层次性。篇章分析能够从宏观的角度捕捉文本信息,提供比句法和语义分析更为全面的理解。
拿新闻摘要生成为例,单从句子级别出发,我们可能只能获取到表面的信息。但如果能够进行篇章分析,我们不仅可以抓住文章的主要观点,还能了解各个观点是如何逻辑排列和相互支持的。
篇章分析在NLP中的应用
篇章分析在NLP的多个应用场景中都有着广泛的用途。以下是几个典型的应用场景:
- 信息检索: 通过篇章分析,可以更准确地理解用户的查询意图,从而返回更相关的搜索结果。
- 机器翻译: 篇章层面的分析能够帮助机器翻译系统更准确地把握原文的语境,提高翻译的自然性和准确性。
- 文本摘要: 除了抓住文章的主要观点,篇章分析还能捕捉到观点之间的逻辑关系,生成更为精炼和高质量的摘要。
-
在信息检索中,如果用户查询“气候变化的影响”,仅从词汇或句子级别分析可能会返回关于“气候”和“影响”的广泛文章。但通过篇章分析,可以更精确地找到讨论“气候变化影响”的具体篇章或文章。
-
在机器翻译中,比如一个长句子由多个短句子构成,而这些短句子之间有因果、转折等复杂关系。篇章分析能帮助机器更准确地捕捉这些关系,从而生成更自然的译文。
-
在文本摘要中,通过篇章分析,系统可以识别文章的主要观点,以及这些观点是如何通过证据和论点串联起来的,从而生成一个全面而准确的摘要。
三、篇章的衔接
篇章分析中的一个重要概念是衔接(Cohesion)。衔接涉及文本中各个语言成分如何相互关联,以形成一个整体的、连贯的信息结构。
衔接主要是一种语义关系,它使篇章的各个组成部分在语义上紧密相连。这通常通过两种主要方式来实现:词汇衔接和语法衔接。
词汇衔接主要涉及使用特定的词汇手段,如重述(Reiteration)和搭配(Collocation)。
重述 (Reiteration)
重述通常是通过词汇的重复或使用同义词、近义词、反义词、上下位词等来建立篇章的衔接。
例子:
太阳是生命之源,无论是人类还是动植物,都离不开太阳的照射。因此,阳光是非常重要的。
在这个例子中,"太阳" 和 "阳光" 建立了一种重述关系,增加了篇章的衔接性。
搭配 (Collocation)
搭配关系通常是词与词之间的习惯性组合,不仅限于一个句子内,也可能是跨句或跨段。
例子:
他拿起手机,然后开始浏览社交媒体。不久后,他发现了一条有趣的推文。
在这里,"手机" 和 "社交媒体"、"推文" 形成了一种搭配关系,增强了文本的连贯性。
语法衔接主要包括照应(Reference)、替代(Substitution)、省略(Ellipsis)和连接(Conjunction)。
照应 (Reference)
照应是指一个词或短语与前文或后文中的词或短语有明确的指代关系。
例子:
小明是个好学生。他总是第一个到校,最后一个离开。
在这里,“他”明确地指代了“小明”,形成了照应关系。
替代 (Substitution)
替代是用其他词或短语来代替前文中出现的词或短语。
例子:
有些人喜欢苹果,有些人则更偏向于橙子。
在这里,“更偏向于”替代了“喜欢”,形成了替代关系。
省略 (Ellipsis)
省略是在句子中去除某个不必要的成分,以使表达更简洁。
例子:
他想吃巧克力,但我不(想吃)。
这里,“想吃”被省略,但意思仍然清晰。
连接 (Conjunction)
连接是通过使用特定的连接词来建立逻辑关系,可以分为详述、延伸和增强三大类。
详述例子:
她很善良,例如,总是愿意帮助别人。
延伸例子:
他是个勤奋的学生。然而,他在数学方面却总是遭遇困难。
增强例子:
除了是一个优秀的程序员,他还是个热爱音乐的人。
在这些例子中,例如、然而和除了都作为连接词,增加了句子和段落之间的逻辑关系。
通过以上各种衔接手段,篇章可以形成一个结构严谨、语义连贯的整体,从而更有效地传达信息和观点。
四、篇章的连贯
篇章分析是一个复杂且有深度的领域,涉及到语义、语法、修辞和认知等多个层面。特别是在涉及到篇章连贯(Coherence)时,这一复杂性更为明显。
连贯(Coherence)与连贯性(Coherent)
连贯(Coherence)是指篇章在语义、功能和心理上构成一个整体,围绕同一个主题或意图展开。连贯性(Coherent)则是一个衡量篇章质量的指标。
考虑下列两个句子:
- 张三参加了马拉松比赛。
- 他完成了全程42.195公里。
这两个句子形成了一个连贯的篇章,因为它们都围绕着“张三参加马拉松比赛”这一主题展开。
局部连贯性(Local Coherence)
局部连贯性涉及篇章中前后相连的命题在语义上的联系。这通常需要考虑词汇、句法和语义等因素。
考虑以下的句子序列:
- 小明喜欢数学。
- 他经常参加数学竞赛。
这两个句子在局部层面上是连贯的,因为“小明”和“数学竞赛”都与“数学”有直接的语义联系。
整体连贯性(Global Coherence)
整体连贯性则更注重篇章中的所有命题与篇章主题之间的联系,这一点在长篇文章或论文中尤为重要。
考虑以下的句子:
- 小红去了图书馆。
- 她借了几本关于量子物理的书。
- 她的目标是成为一名物理学家。
这些句子围绕着“小红对物理学的兴趣和目标”这一主题,展示了整体连贯性。
认知模式与连贯
篇章的语义结构受到人们普遍认知规律的制约,例如从一般到特殊、从整体到局部。
考虑以下句子:
- 北京是中国的首都。
- 故宫是北京的一大旅游景点。
- 故宫的午门是最受游客欢迎的地方。
这一系列句子符合从整体到局部的认知模式,先描述北京,再到具体的故宫,最后到更具体的午门。
理论与方法
篇章连贯性的研究有多种方法,包括关联理论、修辞结构理论(Rhetorical Structure Theory)、图式理论(Schema Theory)和基于语篇策略(Discourse Strategy)的研究等。
在微观层面上,关联理论(Relevance Theory)提供了一种用于理解篇章中信息如何相互关联的框架。
修辞结构理论(Rhetorical Structure Theory)
这一理论尝试通过分析篇章中不同元素之间的修辞性关系,来理解篇章的连贯性。
图式理论(Schema Theory)
图式理论主要用于解释读者如何使用先前的知识来理解新信息,从而提供篇章连贯性的一种认知基础。
基于语篇策略(Discourse Strategy)的研究
这一方向主要研究篇章如何通过不同的语篇策略,如主题句、过渡句等,来增强其连贯性。
五、篇章的结构
篇章不仅是一组简单地排列在一起的句子,而是一个精心设计的结构,旨在传达特定的信息或达到特定的目的。
线性结构与等级结构
首先,篇章有线性结构和等级结构两种基本形式。线性结构是指句子按照某种逻辑顺序或时间顺序排列。例如:
“今天早上我起床,刷牙洗脸后吃了早餐。然后我走到公交站,搭乘公交车到达学校。”
这个例子中,句子按照事件发生的时间顺序排列,构成了线性结构。
等级结构则意味着句子和段落的组合可以构成更高级别的信息单元。以学术文章为例,它通常包括引言、主体和结论等部分,这些部分又由多个段落组成,形成了一个等级结构。
篇章超级结构(Superstructure)
篇章超级结构是用于描述篇章如何组织的一种高级结构。例如,在学术论文中,常见的超级结构包括“引言-方法-结果-讨论(IMRD)”。这种结构只涉及内容的组织方式,与内容本身无关。
修辞结构理论(Rhetorical Structure Theory, RST)
RST 是一种用于分析篇章结构的理论,它定义了不同文本单元(Text Span)之间的修辞关系。主要分为两种类型:
- 核心(Nucleus):篇章中最重要的部分,例如:“吸烟有害健康。”
- 辅助(Satellite):用于解释或支持核心信息的部分,例如:“据世界卫生组织统计,每年有 800 万人因吸烟导致的疾病而死亡。”
语篇模式(Textual Pattern)
语篇模式是长期形成的,通常带有文化背景的篇章组织方式。例如,在西方文化中,“问题-解决(Problem-Solution)”模式非常普遍。
例子:语篇模式在新闻报道中的应用
考虑以下新闻报道:
[1]“新的研究发现,青少年使用社交媒体的时间越长,出现抑郁症状的几率越高。”(核心)
[2]“这一发现是基于对 1000 名青少年进行为期一年的跟踪研究的结果。”(辅助)
这个报道用了“问题-解决”模式。[1]提出了一个问题(青少年使用社交媒体与抑郁),而[2]给出了该问题的一个解决方案(基于研究的证据)。
通过了解这些不同的结构和模式,作者可以更有效地组织篇章,读者也能更容易地理解和接收信息。这也是为什么篇章的结构是写作和阅读中不可或缺的一个方面。
六、基于词汇句法树的统计话语分割
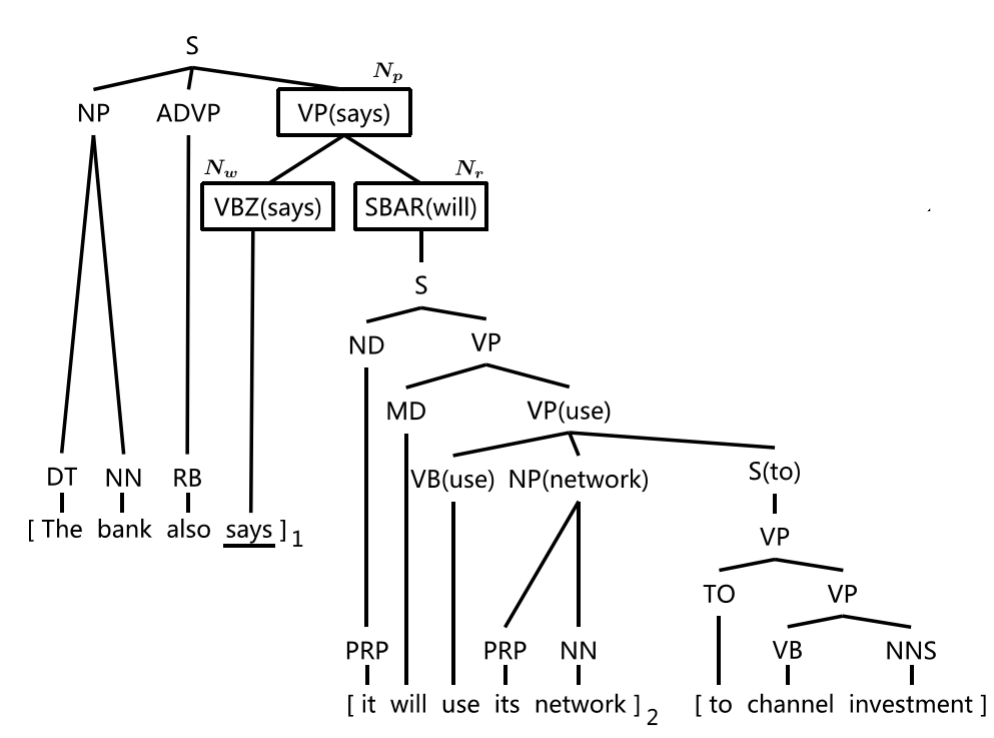
话语分割(Discourse Segmentation)是自然语言处理中的一个关键任务,它旨在识别篇章中的基本篇章单元(Elementary Discourse Units, EDU)。这是后续进行高级篇章分析的基础。
话语分割与修辞结构理论
根据修辞结构理论(Rhetorical Structure Theory, RST),篇章的修辞关系是定义在两个或多个EDU之间的。话语分割的主要目标就是识别这些EDU。
考虑以下句子:
"苹果很好吃,但是很贵。"
在这里,"苹果很好吃" 和 "但是很贵" 可以被认为是两个不同的EDU。
SynDS 算法概述
SynDS 算法基于词汇句法树来估算一个单词是否应作为一个EDU的边界。它使用词汇中心(Lexical Head)映射规则来提取更多特征。
最大似然估计
给定句子 (s = w_1, w_2, ..., w_n) 和它的句法树 (t),该算法使用最大似然估计来学习每个词 (w_i) 作为边界的概率 ( P(b_i | w_i) ),其中 (b_i \in {0, 1})。0表示非边界,1表示边界。
词汇中心映射
对于每个词 (w),该算法注意到其右侧兄弟节点的最高父节点,并使用这个信息来决定当前词是否应作为边界词。
PyTorch 实现
下面的 PyTorch 代码片段展示了这一算法的基础实现。
import torch
import torch.nn as nn
import torch.optim as optim
# 假设我们已经得到了句法树和词汇向量
# feature_dim 是特征维度
class SynDS(nn.Module):
def __init__(self, feature_dim):
super(SynDS, self).__init__()
self.fc = nn.Linear(feature_dim, 2) # 二分类:0表示非边界,1表示边界
def forward(self, x):
return self.fc(x)
# 初始化
feature_dim = 128
model = SynDS(feature_dim)
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
# 假设 x_train 是输入特征,y_train 是标签(0或1)
# x_train 的形状为 (batch_size, feature_dim)
# y_train 的形状为 (batch_size)
x_train = torch.rand((32, feature_dim))
y_train = torch.randint(0, 2, (32,))
# 训练模型
optimizer.zero_grad()
outputs = model(x_train)
loss = criterion(outputs, y_train)
loss.backward()
optimizer.step()
# 输出预测
with torch.no_grad():
test_input = torch.rand((1, feature_dim))
test_output = model(test_input)
prediction = torch.argmax(test_output, dim=1)
print("预测边界为:", prediction.item())
输入与输出
- 输入:特征维度为
feature_dim的词向量。 - 输出:预测结果,0 或 1,代表是否为EDU边界。
- 使用最大似然估计计算概率。
- 用交叉熵损失函数进行训练。
- 使用优化器进行权重更新。
七、基于循环神经网络的话语分割
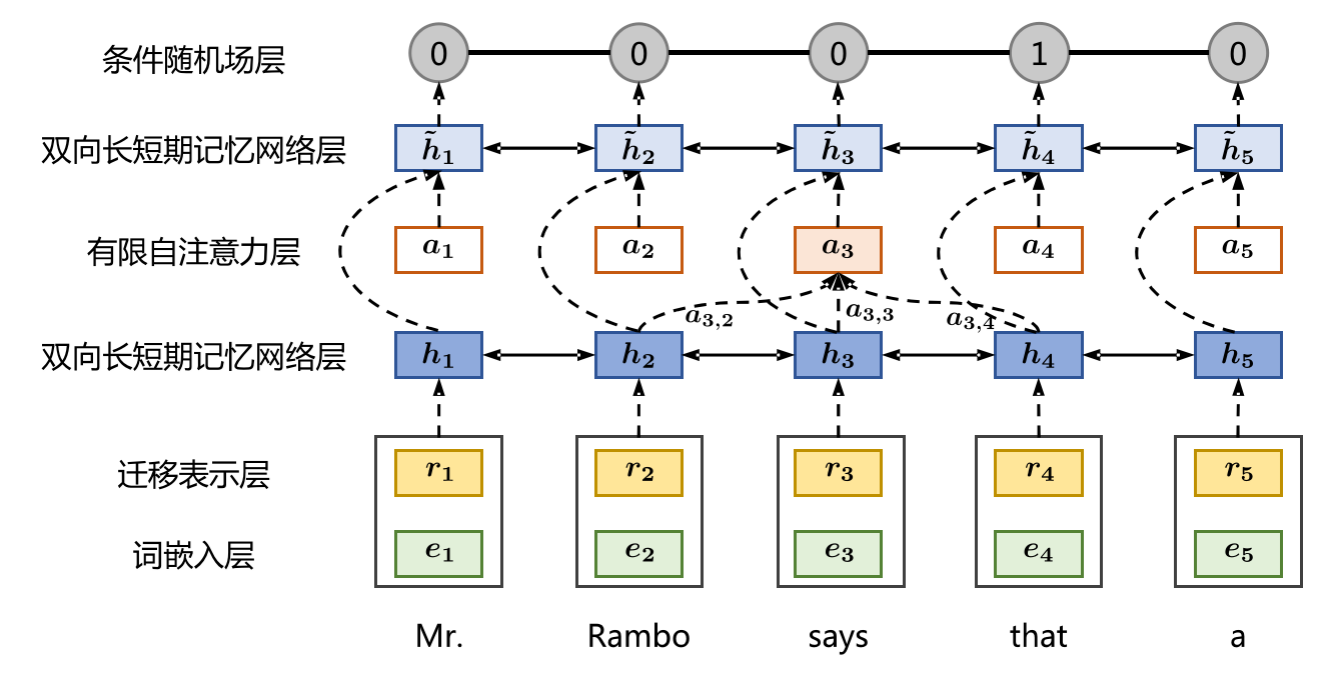
话语分割是识别篇章中基本篇章单元(Elementary Discourse Units,简称EDU)的过程,为后续的分析打下基础。在这一篇章中,我们将专注于使用双向长短时记忆网络(BiLSTM)和条件随机场(CRF)进行话语分割的实现。
从序列标注到话语分割
在基于RNN的模型中,话语分割任务可以被重新定义为一个序列标注问题。对于输入的每一个词 (x_t),模型输出一个标签 (y_t),表示该词是否是一个EDU的起始边界。
输出标签的定义
- ( y_t = 1 ) 表示 ( x_t ) 是EDU的起始边界。
- ( y_t = 0 ) 表示 ( x_t ) 不是EDU的起始边界。
BiLSTM-CRF模型
BiLSTM-CRF结合了BiLSTM的能力来捕获句子中的长距离依赖关系和CRF的能力来捕获输出标签之间的关系。
BiLSTM层
BiLSTM可以从两个方向读取句子,因此它可以捕获前后文信息。
条件随机场(CRF)是用于序列标注的概率图模型,其目标是找到给定输入序列 ( X ) 下可能的最佳输出序列 ( Y )。
PyTorch 实现
下面是使用PyTorch实现BiLSTM-CRF模型进行话语分割的示例代码:
import torch
import torch.nn as nn
from torchcrf import CRF
class BiLSTM_CRF(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
super(BiLSTM_CRF, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim // 2, num_layers=1, bidirectional=True)
self.hidden2tag = nn.Linear(hidden_dim, 2) # 2表示两个标签:0和1
self.crf = CRF(2)
def forward(self, x):
embeds = self.embedding(x)
lstm_out, _ = self.lstm(embeds.view(len(x), 1, -1))
lstm_feats = self.hidden2tag(lstm_out.view(len(x), -1))
return lstm_feats
# 参数设置
vocab_size = 5000
embedding_dim = 300
hidden_dim = 256
# 初始化模型
model = BiLSTM_CRF(vocab_size, embedding_dim, hidden_dim)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, weight_decay=1e-4)
# 模拟输入数据
sentence = torch.tensor([1, 2, 3, 4], dtype=torch.long)
tags = torch.tensor([1, 0, 1, 0], dtype=torch.long)
# 前向传播
lstm_feats = model(sentence)
# 计算损失和梯度
loss_value = -model.crf(lstm_feats, tags)
loss_value.backward()
optimizer.step()
# 解码:得到预测标签序列
with torch.no_grad():
prediction = model.crf.decode(lstm_feats)
print("预测标签序列:", prediction)
输入与输出
- 输入:词的整数索引序列,长度为 ( T )。
- 输出:标签序列,长度也为 ( T ),其中每个元素都是0或1。
- 词嵌入层将整数索引转换为固定维度的向量。
- BiLSTM层捕获输入序列的前后文信息。
- 线性层将BiLSTM的输出转换为适用于CRF的特征。
- CRF层进行序列标注,输出每个词是否是EDU的开始。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。
如有帮助,请多关注
TeahLead KrisChang,10+年的互联网和人工智能从业经验,10年+技术和业务团队管理经验,同济软件工程本科,复旦工程管理硕士,阿里云认证云服务资深架构师,上亿营收AI产品业务负责人。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK