

谷歌视觉语言模型PaLI-3问世,参数仅5B,更小、更快、更强
source link: https://www.51cto.com/article/770099.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

谷歌视觉语言模型PaLI-3问世,参数仅5B,更小、更快、更强
在大模型时代,视觉语言模型(VLM)的参数已经扩展到了数百甚至数千亿,使得性能持续增加。与此同时,更小规模的模型仍然很重要,它们更易于训练和服务,更加环境友好,并为模型设计提供更快的研究周期。
在该领域,谷歌研究院在去年推出了一个名为 PaLI(Pathways Language and Image)的模型。作为一个多模态大模型,PaLI 的关键结构之一是复用大型单模态基干进行语言和视觉建模,在语言方面复用 13B 参数的 mT5-XXL,在视觉方面复用 2B 参数的 ViT-G 和 4B 参数的 ViT-e。当时 PaLI 实现了优于多数新旧模型的性能。
此后谷歌继续专注于更小规模的建模,并于近日提出 PaLI-3,这是 PaLI 系列的第三代模型。通过一个仅有 5B 参数的预训练基线模型,他们优化了训练方法,并在多个 VLM 基准上实现了有竞争力以及新的 SOTA 结果。
该方法主要由三部分组成,分别是在 web 规模的图像文本数据上对图像编码器的对比预训练、用于 PaLI 多模态训练的改进后的混合数据集,以及更高分辨率的训练。

作者来自谷歌研究院、谷歌DeepMind和谷歌云。
论文地址:https://arxiv.org/pdf/2310.09199.pdf
下图为 5B PaLI-3 模型概览,其中通过对比预训练的 2B SigLIP 视觉模型,图像被单独地编码成了视觉 token。接着与 query 一起,这些视觉 token 被传递给了 3B 编码器 - 解码器结构的 UL2 Transformer,它生成了预期答案。在这样的设置下,与之前 PaLI 模型中单个分类预训练的模型,对比预训练的模型提供了明显更有用的 token。
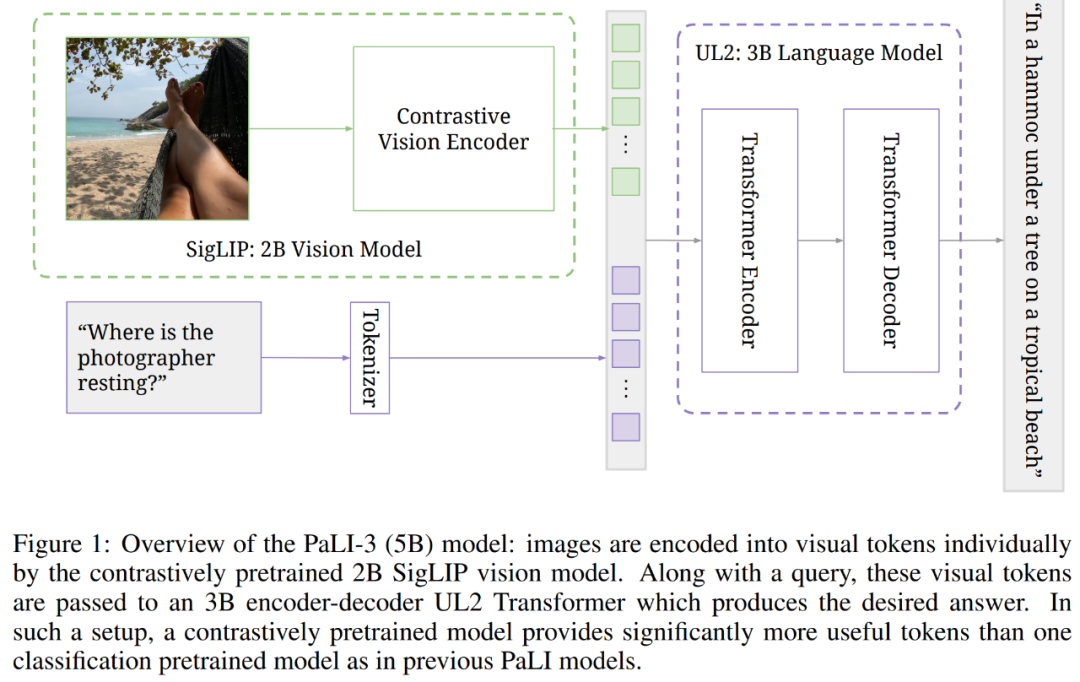
效果怎么样呢?PaLI-3 在需要视觉定位文本理解和目标定位的任务上实现了新的 SOTA,包括 RefCOCO 数据集上的 8 个视觉定位文本理解任务和参考表达分割任务。PaLI-3 也在一系列分类视觉任务上有出色的表现。
此外研究者还专门做了消融实验以与分类预训练的 ViT 基线模型比较,并进一步确认了预训练视觉编码器在有噪声 web 规模的图像文本数据上的可行性,从而成为在分类数据上进行训练的优先替代方案。
除了 5B PaLI-3 模型之外,研究者还利用最近提出的 SigLIP 方法,构建了一个参数扩展到 2B 的 SOTA 多语言对比视觉模型。
架构
在更高的层面,PaLI-3 的架构遵循了 Chen et al. (2023b;a):ViT 模型将图像编码为 token,并与问题、提示和指令等文本输入一起被传递到编码器 - 解码器结构的 transformer,从而生成文本输出。
先看视觉组件。研究者使用 SigLIP 训练方法,从对比预训练的 ViT-G/14 模型(参数约为 2B)初始化出 PaLI-3 的视觉基干。简而言之,他们训练了图像嵌入 ViT-G/14 模型和文本嵌入 transformer 模型来分别嵌入图像和文本,这样一来,使用图像和文本嵌入点积的 sigmoid 交叉熵的二元分类器,能够准确地分类各自的图像和文本是否相互对应。
这类似于 CLIP 和 ALIGN,但更加高效、可扩展和稳健。同时这种方法是为了预训练 ViT 图像嵌入组件,因此当将 ViT 插入到 PaLI 时,文本嵌入 transformer 会被丢弃。
再来看完整的 PaLI 模型。ViT 图像编码器的输出在池化之前形成了视觉 token,并线性地映射和添加到嵌入的输入文本 token。接着这些 token 被传递到了预训练的 3B UL2 编码器 - 解码器模型,从而生成文本输出。该模型的文本输入通常包含有描述任务类型的提示,并为该任务编码必要的文本输入。
训练
训练过程包含多个阶段。
阶段 0:单峰预训练。图像编码器按照 SigLIP 训练协议,图像编码器的训练分辨率为 224×224 ;文本编码器 - 解码器是一个 3B UL2 模型,按照 Tay 等人描述的混合降噪程序进行训练。
阶段 1:多模态训练。将图像编码器与文本编码器 - 解码器相结合,然后,将这个组合得到的 PaLI 模型在多模态任务和数据上进行训练,此时,图像编码器保持冻结,分辨率还是 224×224。通过对文本质量进行启发式过滤,并使用 SplitCap 训练目标,再次从 WebLI 数据集派生出主要的混合组件。
阶段 2:提升分辨率。高分辨率输入是一种被广泛接受的提高性能的方法,这既是因为可以感知图像中的更多细节,也是因为通过增加序列长度来提高模型能力。本文通过解冻图像编码器来提高 PaLI-3 的分辨率,将检查点保持在 812×812 和 1064×1064 分辨率。
任务迁移。最后,对于每个单独的任务(基准),本文使用冻结的 ViT 图像编码器在任务的训练数据上微调 PaLI-3 模型;对于大多数任务,本文微调 812×812 分辨率检查点,但对于两个文档理解任务,本文将分辨率提高到 1064×1064。
实验及结果
实验首先比较了在 PaLI 框架下不同 ViT 模型的结果对比,研究者考虑了两种 ViT 模型:Classif 和 SigLIP。
结果如表 1 所示,表明虽然 SigLIP 模型的少样本线性分类有些落后,但通过使用 PaLI-3,SigLIP 模型在更简单的任务上(例如字幕和问答)提供了适度的增益,并且在更复杂的场景即文本和空间理解任务上取得了巨大增益。
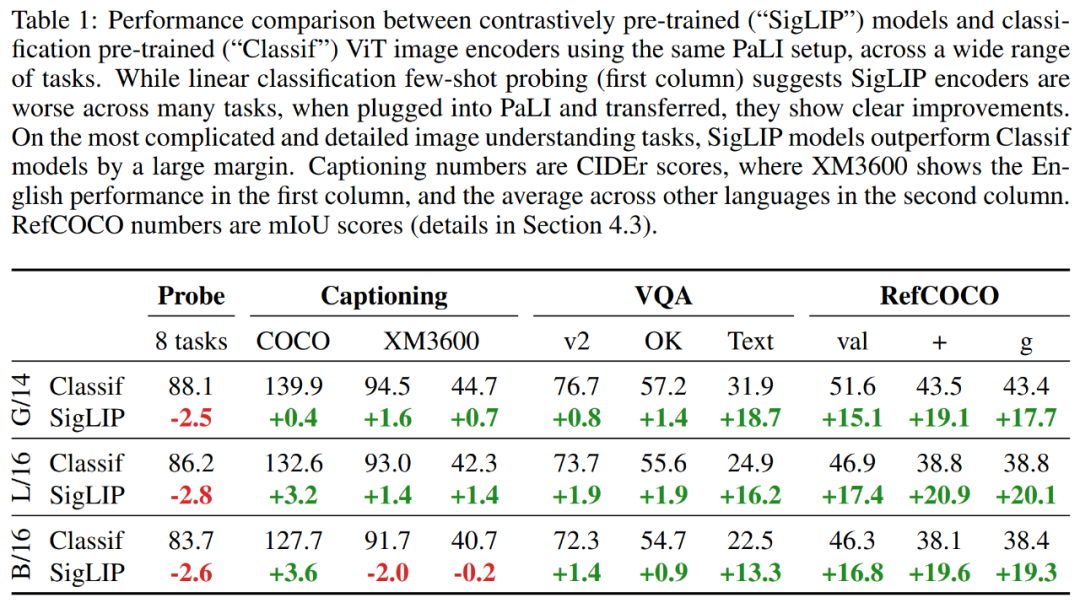
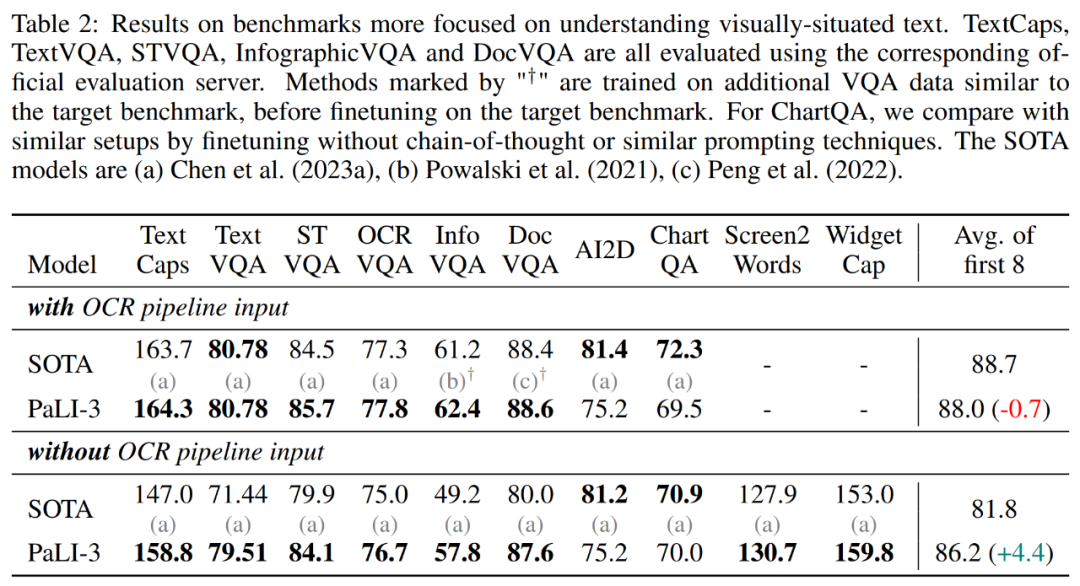
此外,研究者还在 TextCaps、TextVQA、STVQA、OCRVQA、InfographicVQA、DocVQA、ChartQA、Scree2Words、 WidgetCap 数据集上评估了 PaLI-3。结果如表 2 所示,在使用外部 OCR 系统的情况下,PaLI-3 仅比 SOTA 方法低 0.7 分。然而,在没有这种外部系统的情况下,PaLI-3 比所有 SOTA 方法的组合高出 4.4 分。对于 TextCaps、TextVQA、InfographicVQA 和 DocVQA,PaLI-3 的优势超多 8 分甚至更多。
参考表达分割
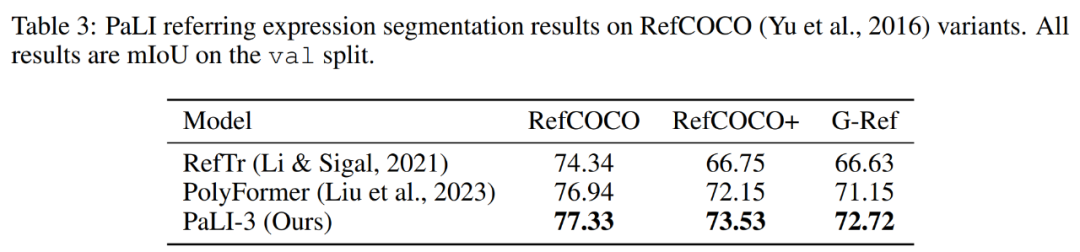
研究者扩展了 PaLI-3,使其能够通过类语言输出来预测分割掩码。为此,他们利用了 Ning et al. (2023) 的向量量化变分自编码器(VQ-VAE)。VQ-VAE 经过训练可以学习 128 个掩码 token,其编码器可以将 64 × 64 像素的分割掩码标记为 16 个掩码 token,解码器可以转换回来。
研究者训练 PaLI-3 来预测单个分割掩码,首先输出 4 个坐标作为文本,并表示为边界框。接着是 16 个掩码 token,表示边界框内的掩码。
表 1 表明对于此类定位任务,对比预训练比分类预训练更有效。下表 3 显示,完整的 PaLI-3 模型在参考表达分割方面略微优于现有技术。
图像理解
接下来研究者在一般视觉语言理解任务上评估了 PaLI-3。与之前的工作一样,他们没有使用外部 OCR 模块,因为这些基准测试很少涉及图像中的文本。
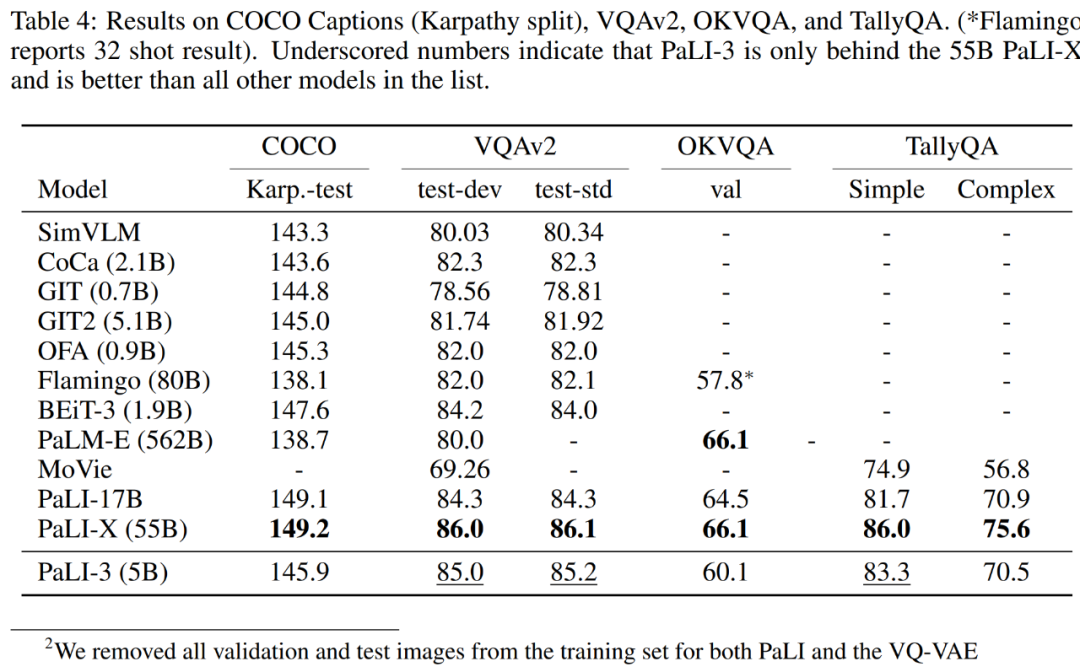
结果表明,与最近的 SOTA 模型相比,PaLI-3 的尺寸要小得多,但它在这些基准测试中表现出了非常强大的性能。对于 COCO,PaLI-3 优于除 BEiT-3 以及 17B 和 55B PaLI 之外的所有模型。在 VQAv2 和 TallyQA 上,PaLI-3 超过了除 PaLI-X 之外的所有先前模型。对于 OKVQA 任务,PaLI-3 仅落后于 PaLM-E (562B) 和 PaLI-X (55B),但仍然优于 32-shot Flamingo (80B) 模型。
视频字幕和问答
该研究在 4 个视频字幕基准上对 PaLI-3 模型进行了微调和评估:MSR-VTT、VATEX、ActivityNet Captions 和 Spoken Moments in Time。此外,该研究在 3 个视频问答基准上进行了同样的操作:NExT-QA、MSR-VTT-QA 和 ActivityNet-QA。
尽管没有使用视频数据进行预训练,PaLI-3 仍以较小的模型尺寸实现了出色的视频 QA 结果:在 MSR-VTT-QA 和 ActivityNet-QA 上实现了最先进的性能,并在 NextQA 上取得了具有竞争力的结果。在图像和视频 QA 上的持续改进凸显了采用对比 ViT 的好处。
此外,PaLI-3 还取得了非常好的视频字幕结果,平均仅比 SOTA 结果低 3 个 CIDEr 点。考虑到模型尺寸,PaLI-3 在性能和实用性方面似乎都是一个绝佳的选择。
直接图像编码器评估
研究者还评估了 ViT-G 模型,ViT-G 可以理解为不是完整的 PaLI-3,结果如表 6 所示。
首先,该研究使用标准的 ImageNet 基准测试及其两个最流行的变体来测试图像分类功能。结果表明,SigLIP 在 top-1 和 v2 准确率方面略有落后,但在 ReaL 方面结果相当。
其次,该研究报告了不同模型在 Crossmodal-3600 基准上的结果。结果表明 SigLIP ViT-G 模型明显优于较大的 ViT-e 模型。
最后,该研究还报告了线性 probing 结果,结果表明 SigLIP 不及其他模型。
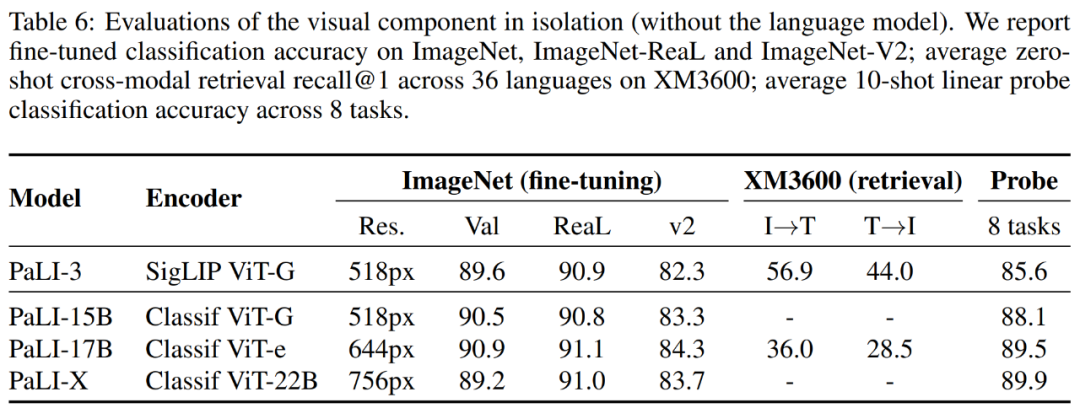
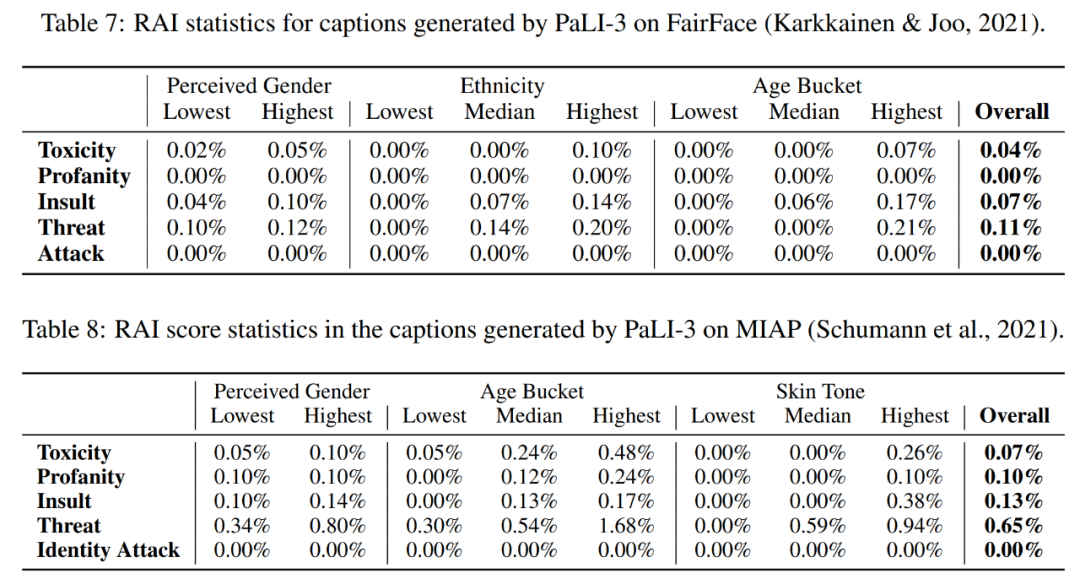
表 7 和表 8 评估了模型的公平性、偏差和其他潜在问题。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK