

Complex Document Recognition: OCR Doesn’t Work and Here’s How You Fix It
source link: https://hackernoon.com/complex-document-recognition-ocr-doesnt-work-and-heres-how-you-fix-it
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Complex Document Recognition: OCR Doesn’t Work and Here’s How You Fix It
Complex Document Recognition: OCR Doesn’t Work and Here’s How You Fix It
6min
by @olegkokorin
Oleg Kokorin
@olegkokorin
CEO of Businessware Technologies, machine learning engineer
Too Long; Didn't Read
OCR software alone can't handle complex documents — special symbols, rotated text, low-quality scans. Using deep learning, one can augment ready-made OCR solutions and allow for processing of complex documents. From removing false positives to using binary matrices to detect complex spreadsheets, deep learning can handle any document. In this article I describe my experience with developing a system for detecting technical drawings of floor plans, the perfect example of applying modern CV and AI to complex document digitization.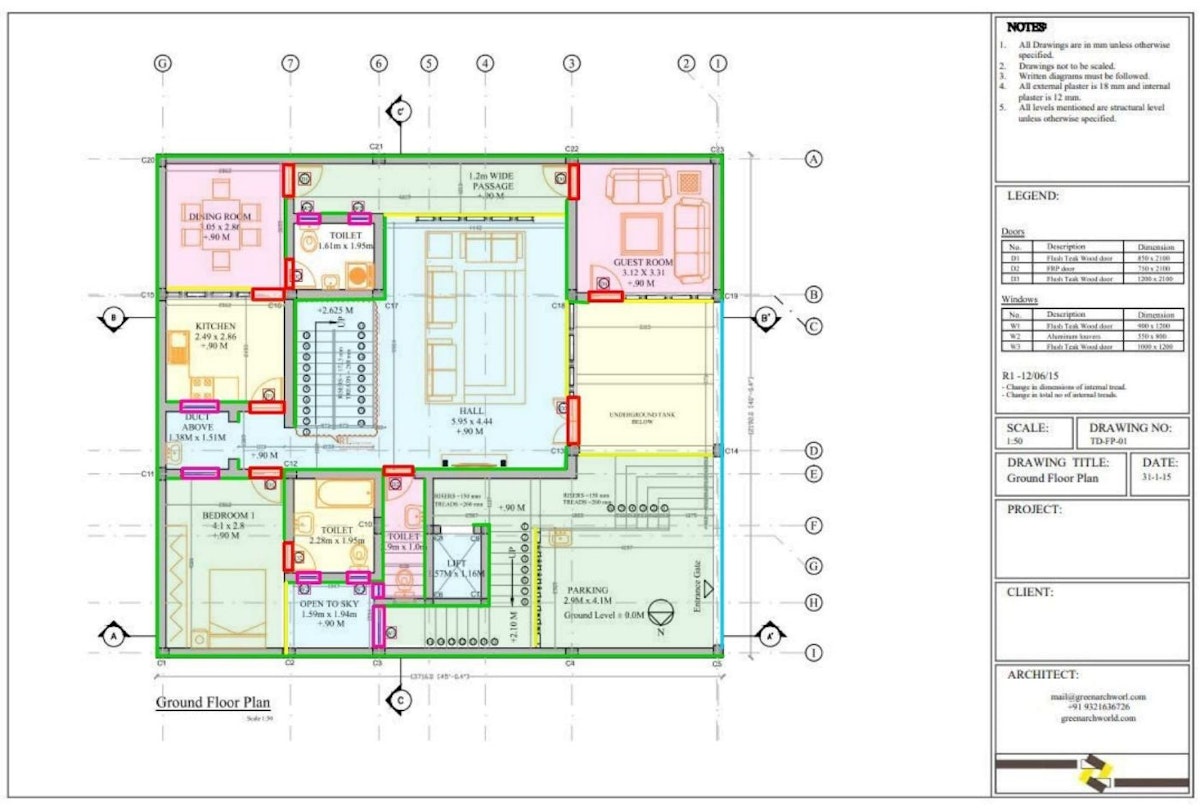
audio element.@olegkokorin
Oleg KokorinCEO of Businessware Technologies, machine learning engineer
Receive Stories from @olegkokorin
Credibility
In this article, I will dive into a complex world of complex document recognition using AI and OCR.
Document recognition nowadays is not a complex task.
Modern OCR solutions are able to detect both typed and written text in many languages. One can find dedicated solutions for the detection of specific documents like passports and driver’s licenses.
But where out-of-the-box AI tends to struggle is when a document includes special symbols or tilted text.
Technical drawings are among the ‘trouble children’ that cause ready-made OCR solutions to struggle: they are nothing but a collection of weird symbols and weirdly placed text.
Having worked on an AI solution for technical drawing recognition, I have insights into the world of modern OCR that I will share in this article.
Why OCR is bad for OCR
The ‘digital first’ approach, at the forefront of many businesses, has motivated many to convert physical documents into a digital format. This process usually involves the implementation of OCR — optical character recognition — which converts physical documents into PDF files.
Morel OCR tools are capable of recognizing more than just text. In many cases, OCR tools can detect special symbols, written text, signatures, images, and more.
Many of these tools come ready to use: all you need to do is install the tool (or, if you are working on a custom solution, use an API) to scan the documents in question.
Despite all this, OCR tools have certain limitations. They don’t work well for irregular text, also called wild text, like low-quality scanned documents with no predefined structure, car license plates, text on advertisement billboards, etc.
Low-quality scans
The quality of text recognition depends highly on the quality of the document itself. Warping, scratches, faded ink, and more have a detrimental effect on the recognition quality.
Symbol mixups
Even the best OCR tools have trouble distinguishing between certain similar-looking letters and numbers, like ‘3’ and ‘8’ or ‘O’ and ‘D.’ The very challenges OCR is supposed to solve often become the stumbling block of document digitization.
Special symbols
Documents that feature any special symbols, from letters specific to a certain language to symbols denominating certain objects, like symbols used in technical drawings, e.g., diameter ‘Ø,’ square ‘□.’
AI to the rescue
Using artificial intelligence, OCR tools can be improved and augmented to better handle complex documents, and often even replaced by a custom AI neural network.
Neural networks can be trained to recognize text regular OCR tools have trouble with. Intelligent OCR provides superior text recognition results in document recognition applications by improving recognition speed and reducing errors.
Recognition of complex documents
Despite the widespread digitization, some paperwork remains offline. This usually applies to complex documents that are impossible to digitize due to their complex layouts, the use of special symbols, and unconventional formatting.
Technical drawings are the perfect example of a complex document: their layouts change from one document to another; they include a bunch of symbols specific to technical drawings only, and the text is often formatted in odd ways. All of the above makes technical drawings the perfect candidate for model-based OCR.
While working on a similar project, I’ve developed an understanding of the best strategies to apply when working on digitizing technical drawings. I have had experience with working on an AI for floor plan detection, so that’s what I’ll be using as an example.
I’ve broken the process down into sections, as this is exactly how one should approach the development of AI-based OCR solutions for complex document recognition.
Stage 1: Detection of text
Recognition of plain text is the most simple part of this entire ordeal. When it comes to technical drawings, plain text is used to specify the drawing type, dimensions, floor plan type, building type, etc. While the detection of plain text is a simple task, detecting text on a technical drawing is far more complex.
The text can come in a variety of fonts, sizes, and colors, can be rotated or upside down, and contains special symbols. Ready-made OCR software like iText and OCRSpace can detect simple text with high accuracy, but they fail spectacularly when it comes to technical drawings (or any other complex document, for that matter). For example, these tools struggle to detect rotated text.
OCR tools often have trouble detecting rotated text | Image by author
Most OCR tools can be fine-tuned to handle problematic text better. .
Another benefit of using fine-tuned OCR software is the increase in recognition speed.
Fine-tuning of OCR software leads to better results | Image by author
By fine-tuning these tools alone, we’ve seen a 200 times decrease in document processing speed.If you add an OCR engine into the equation, like Tesseract, the text recognition quality can be increased up to 99.9%.
Stage 2: Recognition of special symbols
Each technical drawing includes special symbols of some sort. In the case of floor plan technical drawings, the documents include symbols designating doors, windows, electrical outlets, etc.
These symbols, or labels, look like geometric figures with text inside. They can be difficult to distinguish from their surroundings due to their shape, which blends in perfectly with the rest of the drawing.
In addition, there can be multiple labels representing the same object due to inconsistencies in document design.
Similar looking objects are often detected as the same one | Image by author
Pre-trained computer vision solutions, like OpenCV libraries for symbol detection, work best with photographs of real-life objects. Technical drawings are quite a bit different: they are almost always in black and white and mostly consist of geometric shapes.
We’ve tested multiple OpenCV libraries, each of which resulted in albeit different, yet insufficiently low recognition quality. Unless you develop your own neural network from scratch, any pre-trained computer vision model needs to be built upon to achieve decent recognition quality.
One of the main problems with using pre-trained CV models is the amount of false positive results they produce. Technical drawings consist of simple geometric shapes, but so do special symbols and labels, which results in CV models detecting random parts of the drawings as labels.
The best way of mitigating this issue is to implement deep learning to detect false positive results and remove them from the final detection results.
Deep learning can be used to remove false positive results | Image by author
Stage 3: Spreadsheets
Technical drawings often include large spreadsheets with merged cells and complex structures stretching across multiple pages. While spreadsheets are generally easy to detect, the complex nature of these spreadsheets makes them difficult to crack.
Going a custom software route is the best way to achieve satisfactory results. Here’s how we’ve done it:
Recognition of text in a spreadsheet
Solutions like Amazon Textract work very well and can extract text with very high accuracy as long as the document scan is of high quality. Documents with 300 DPI result in 100% recognition accuracy and 100 DPI results in ~90% accuracy.
Recognition of spreadsheet structure
First, you need to detect the spreadsheet structure by detecting vertical and horizontal lines.
Using OpenCV, create a binary matrix by converting the document into black and white, defining its threshold in a way that results in all horizontal and vertical lines being one and the rest — a zero. The binary matrix will then contain the spreadsheet structure.
Using the extracted text and spreadsheet structure, the spreadsheet itself can be extracted in an editable format like Excel.
Summing Up
Digitizing any complex document comes with its own set of problems. The best approach to solving them is to approach them one by one, researching the best tools for the job, testing them, and comparing results.
The approaches I’ve described work on any document type despite its type, as individual challenges can be similar despite the document type being completely different.
For example, I have experience in working on a passport detection solution where the text recognition challenges were very similar, and we’ve used some of the same techniques.
Knowing your OCR tools, being well-versed in coding neural networks and having decent experience in the field of custom AI development will help overcome any document digitization challenges.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK