

全抖音都在说家乡话,两项关键技术助你“听懂”各地方言
source link: https://www.51cto.com/article/769657.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

全抖音都在说家乡话,两项关键技术助你“听懂”各地方言
国庆期间,抖音上“一句方言证明你是地道家乡人”的活动在吸引了全国各地的网友热情参与,话题最高登上抖音挑战榜第一位,播放量已超过5000万。
这场“各地方言大赏”之所以能火出圈,抖音新上线的地方方言自动翻译功能功不可没。创作者们在用家乡话录制短视频时,使用“自动字幕”功能,选择“转为普通话字幕”,即可完成对视频内容方言语音的自动识别,并将视频里的方言内容转化为普通话字幕,让其他地区的网友也能无痛听懂各种“加密型国语”。有来自福建网友亲测表示,连“十里不同音”的闽南语也能翻译得分毫不差,大呼“闽南语在抖音上为所欲为的日子一去不复返了”。

众所周知,语音识别和机器翻译的模型训练需要大量的训练数据,但方言作为口语流传,可用于模型训练的方言语料数据很少,那么,为这项功能提供技术支持的火山引擎技术团队是如何突破的呢?
方言识别阶段
一直以来,火山语音团队都为时下风靡的视频平台提供基于语音识别技术的智能视频字幕解决方案,简单来说就是可以自动将视频中的语音和歌词转化成文字,来辅助视频创作的功能。
在这个过程中,技术团队发现,传统的有监督学习会对人工标注的有监督数据产生严重依赖,尤其在大语种的持续优化以及小语种的冷启动方面。以中文普通话和英语这样的大语种为例,尽管视频平台提供了充足的业务场景语音数据,但有监督数据达到一定规模之后,继续标注的ROI将非常低,必然需要技术人员考虑如何有效利用百万小时级别的无标注数据,来进一步改善大语种语音识别的效果。
相对小众的语言或者方言,由于资源、人力等原因,数据的标注成本高昂。在标注数据极少的情况下(10小时量级),有监督训练的效果非常差,甚至可能无法正常收敛;而采购的数据往往和目标场景不匹配,无法满足业务的需要。
对此,团队采用了以下方案:
- 低资源方言自监督
基于Wav2vec 2.0自监督学习技术,团队提出了Efficient Wav2vec,实现了极少量标注数据条件下的方言ASR能力。为解决Wav2vec2.0训练慢、效果不稳定的问题,一方面,用filterbank特征取代waveform降低计算量、缩短序列长度,同时降低帧率,实现训练效率翻倍;另一方面,通过等长数据流和自适应连续mask,大幅改善了训练的稳定性和效果。
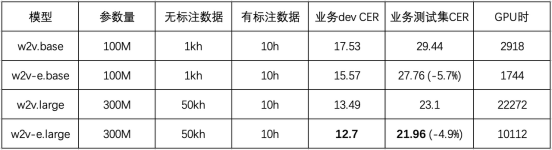
该实验在粤语上进行,使用了5万小时无标注语音和10小时标注语音。结果如下表所示,Efficient Wav2vec (w2v-e)在100M和300M参数量的模型下,相比Wav2vec 2.0,CER相对下降5%,训练开销减半。
进一步,团队以自监督预训练模型微调得到的CTC模型作为种子模型,对无标注数据打伪标签,然后提供给一个参数量较小的端到端LAS模型做训练,同步实现了模型结构的迁移和推理计算量的压缩,可以直接基于成熟的端到端推理引擎部署上线。该技术已成功应用于两个低资源方言,用10小时量级的标注数据实现了低于20%的字错误率。
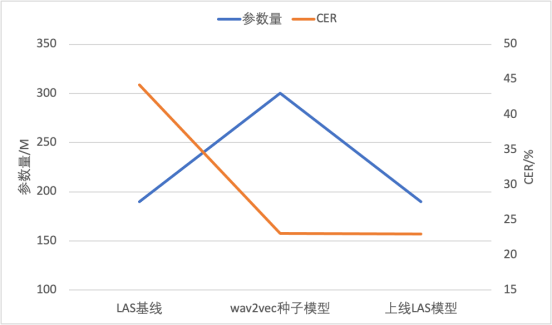
图说:模型参数量和CER对比
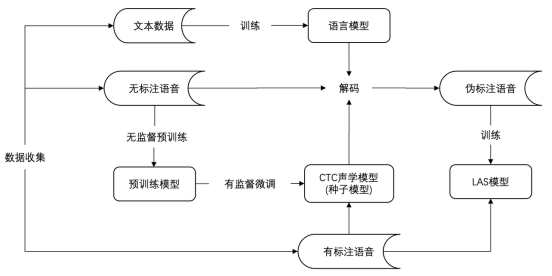
图说:基于无监督训练ASR的落地流程
- 方言大规模pretrain+finetune训练模式
当有监督数据标注结束后,ASR模型的持续优化是一个很重要的研究方向。过去很长一段时间,半/无监督学习一直很火热,无监督pretrain主要思想是,充分利用用未标记的数据集来扩充已标记的数据集,能够实现小数据量的平行语料取得比较好的识别效果。算法流程如下:
(1)首先,利用人工标注的有监督数据训练出种子模型,然后利用该模型对未标注的数据进行伪标签标记。
(2)在伪标签生成过程中,由于种子模型对未标记数据的所有预测都不可能都是准确的,因此需要利用一些策略过率训练价值低的数据。
(3)其次,将生成的伪标签与原始的标记数据相结合,并在合并后数据上进行联合训练。
(4)由于在训练过程加入了大量的无监督数据,即使无监督数据伪标签质量不及有监督数据,但是,往往能够得到比较通用的表征。我们基于大数据训练出的pretrain模型,用人工精标的方言数据进行finetune。这样可以保留pretrain带来的优秀的泛化性,同时提升模型对方言的识别效果。
5个方言的平均CER(字错误率)从35.3%优化到17.21%。
平均字错误率 | ||||||
100wh pretrain+方言混合finetune | 17.21 | 13.14 | 22.84 | 19.60 | 19.50 | 10.95 |
方言翻译阶段
通常情况下,机器翻译模型的训练离不开大量语料的支持,然而方言常以口语形式流传,现今方言使用者的数量也逐年减少,这些现象都提升了方言语料数据收集的难度,方言的机器翻译效果也难以提升。
为了解决方言语料不足的问题,火山翻译团队提出多语言翻译模型 mRASP (multilingual Random Aligned Substitution Pre-training)和 mRASP2,通过引入对比学习,辅以对齐增强方法,将单语语料和双语语料囊括在统一的训练框架之下,充分利用语料,来学习更好的语言无关表示,由此提升多语言翻译性能。

论文地址:https://arxiv.org/abs/2105.09501
加入对比学习任务的设计是基于一个经典的假设:不同语言中同义句的编码后的表示应当在高维空间的相邻位置。因为不同语言中的同义句对应的句意是相同的,也就是“编码”过程的输出是相同的。比如“早上好”和“Good morning”这两句话对于懂中文和英文的人来说,理解到的意思是一样的,这也就对应了“编码后的表示在高维空间的相邻位置”。
训练目标设计
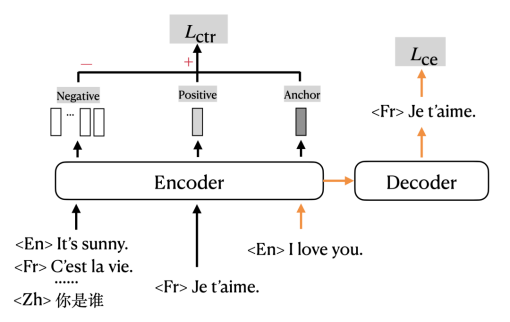
mRASP2在传统的交叉熵损失 (cross entropy loss) 的基础上,加入了对比损失 (contrastive loss) ,以多任务形式进行训练。图中橙色的箭头指示的是传统使用交叉熵损失 (Cross Entropy Loss, CE loss) 训练机器翻译的部分;黑色的部分指示的是对比损失 (Contrastive Loss, CTR loss) 对应的部分。
词对齐数据增强方法又称对齐增强(Aligned Augmentation, AA),是从mRASP的随机对齐变换(Random Aligned Substitution, RAS)方法发展而来的。
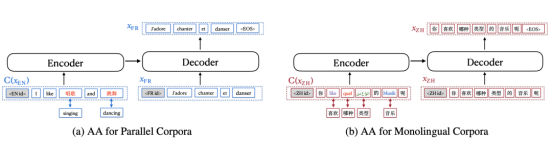
如图所示,图(a)表示了对平行语料的增强过程,图(b)表示了对单语语料的增强过程。其中,图(a)中原本的英语单词被替换成中文对应的单词;而图(b)中原本的中文单词被分别替换成英文、法语、阿拉伯语、德语。mRASP的RAS等价于第一种替换方式,它只要求提供双语的同义词词典;而第二种替换方式需要提供包含多种语言的同义词词典。值得提一句,最终使用对齐增强方法的时候,可以只采用(a)的做法或者只采用(b)的做法。
实验结果表明mRASP2在有监督、无监督、零资源的场景下均取得翻译效果的提升。其中有监督场景平均提升 1.98 BLEU,无监督场景平均提升 14.13 BLEU,零资源场景平均提升 10.26 BLEU。该方法在广泛场景下取得了明显的性能提升,可以大大缓解低资源语种训练数据不足的问题。
写在最后
方言与普通话相辅相成,都是中华传统文化的重要载体,以方言为载体的“乡音”更是中国人故乡的情感符号和情感纽带,借助短视频和方言翻译,有助于广大用户无障碍欣赏天南海北不同区域的文化。
当前,抖音「方言翻译」功能现已支持粤语、闽语、吴语(上海)、西南官话(四川)、中原官话(陕西、河南)等,据说未来还将支持更多方言,一起拭目以待吧。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK