

使用Python分析时序数据集中的缺失数据
source link: https://www.51cto.com/article/769090.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
使用Python分析时序数据集中的缺失数据
时间序列数据几乎每秒都会从多种来源收集,因此经常会出现一些数据质量问题,其中之一是缺失数据。
在序列数据的背景下,缺失信息可能由多种原因引起,包括采集系统的错误(例如传感器故障)、传输过程中的错误(例如网络连接的故障)或者数据收集过程中的错误(例如数据记录过程中的人为错误)。这些情况经常会在数据集中产生零散和明确的缺失值,对应于采集数据流中的小缺口。
此外,缺失信息也可能由于领域本身的特性而自然产生,从而在数据中形成较大的缺口。例如,某个特征在一段时间内停止采集,从而产生非显性的缺失数据。
无论底层原因如何,时间序列中存在缺失数据会对预测和预测模型产生严重的不利影响,并且可能对个人(例如误导的风险评估)和业务结果(例如偏差的业务决策、收入和机会的损失)造成严重后果。
因此,在为建模方法准备数据时,一个重要的步骤是能够识别这些未知信息的模式,因为它们将帮助我们决定处理数据的最佳方法,以提高数据的一致性和效率,可以通过某种形式的对齐校正、数据插值、数据填补,或者在某些情况下,进行逐案删除(即,在特定分析中对具有缺失值的特征省略案例)。
因此,进行全面的探索性数据分析和数据剖析是不可或缺的,这不仅有助于理解数据特征,还能就如何为分析准备最佳数据做出明智决策。
在这个实践教程中,我们将探索如何使用新版本ydata-profiling最近推出的功能来解决这些相关问题。本文将使用Kaggle上提供的美国污染数据集(许可证DbCL v1.0),该数据集详细记录了美国各州的NO2、O3、SO2和CO污染物的信息。
【ydata-profiling】:https://github.com/ydataai/ydata-profiling
【Kaggle上提供的美国污染数据集】:https://www.kaggle.com/datasets/sogun3/uspollution?resource=download
实践教程:对美国污染数据集进行剖析
为了开始我们的教程,首先需要安装最新版本的ydata-profiling:
pip install ydata-profiling==4.5.1然后就可以加载数据,删除不必要的特征,并专注于我们要研究的内容。为了本例的目的,我们将重点研究亚利桑那州马里科帕县斯科茨代尔站测量的空气污染物的特定行为:
import pandas as pd
data = pd.read_csv("data/pollution_us_2000_2016.csv")
data = data.drop('Unnamed: 0', axis = 1) # 删除不必要的索引
# 从亚利桑那州,马里科帕县,斯科茨代尔站(站点编号:3003)选择数据
data_scottsdale = data[data['Site Num'] == 3003].reset_index(drop=True)现在,准备开始对数据集进行剖析!请记住,在使用时间序列剖析时,我们需要传递参数tsmode=True,以便ydata-profiling可以识别与时间相关的特征:
# 将'Date Local'改为日期时间格式
data_scottsdale['Date Local'] = pd.to_datetime(data_scottsdale['Date Local'])
# 创建概述报告
profile_scottsdale = ProfileReport(data_scottsdale, tsmode=True, sortby="Date Local")
profile_scottsdale.to_file('profile_scottsdale.html')时间序列概述
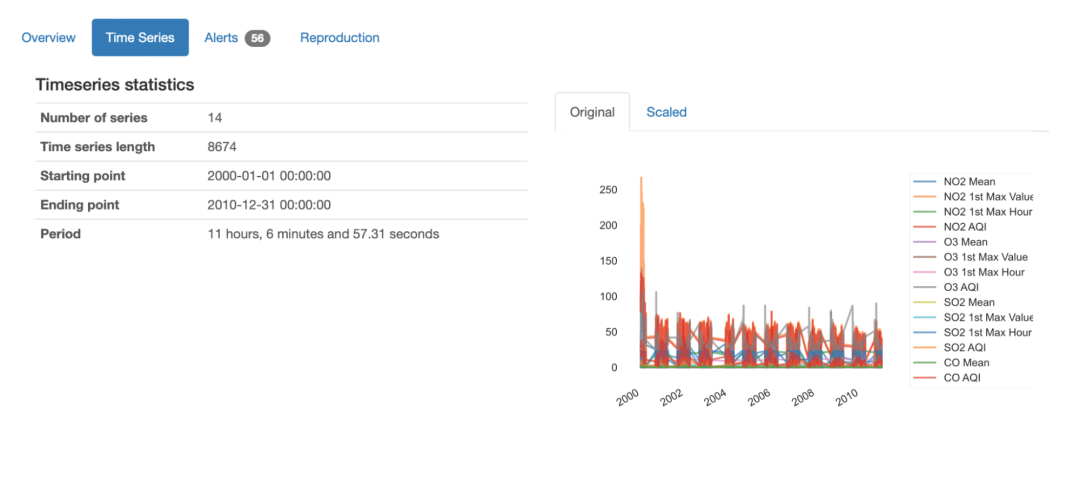
输出报告将与我们已经知道的内容一样熟悉,但在体验上有所改进,并新增了时间序列数据的汇总统计:
图片
从概述中可以通过查看所提供的汇总统计数据,从而对该数据集有一个整体的了解:
- 它包含14个不同的时间序列,每个时间序列有8674个记录值;
- 该数据集报告了2000年1月至2010年12月的10年数据;
- 时间序列的平均时间间隔为11小时零7分钟左右。这意味着平均而言每11小时就进行一次测量。
还可以获取数据中所有序列的概览图,可以选择以原始值或缩放值显示:可以很容易地把握序列的总体变化情况,以及正在测量的组分(二氧化氮、臭氧、二氧化硫、一氧化碳)和特征(平均值、第一最大值、第一最大小时、空气质量指数)。
检查缺失数据
在对数据有一个总体了解之后,我们可以关注每个时间序列的具体情况。
在最新版本的ydata-profiling中,分析报告在针对时间序列数据方面进行了大幅改进,即针对“时间序列”和“间隙分析”指标进行报告。这些新功能极大地方便了趋势和缺失模式的识别,现在还提供了具体的汇总统计数据和详细的可视化。
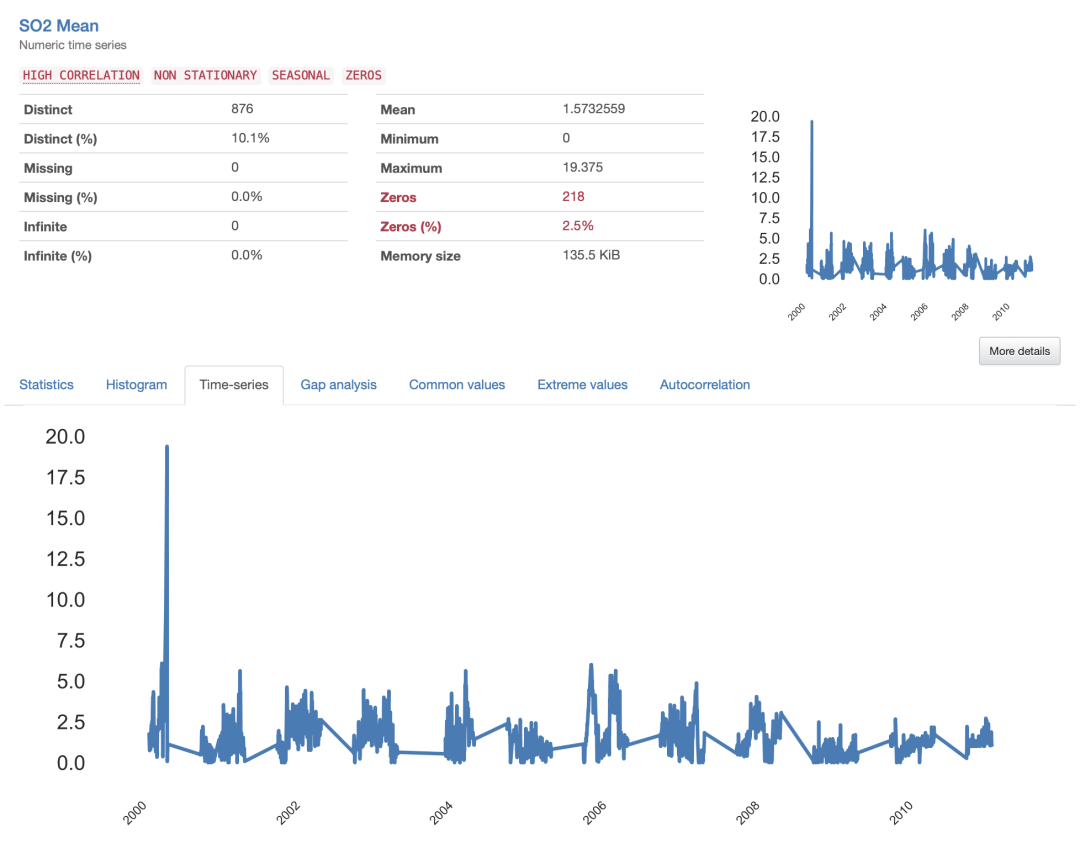
所有时间序列都会呈现不稳定模式,其中在连续测量之间似乎存在某种“跳跃”。这表明存在缺失数据(缺失信息的“间隙”),应该对其进行更仔细的研究。本文以S02 Mean为例来看一下。
图片
图片
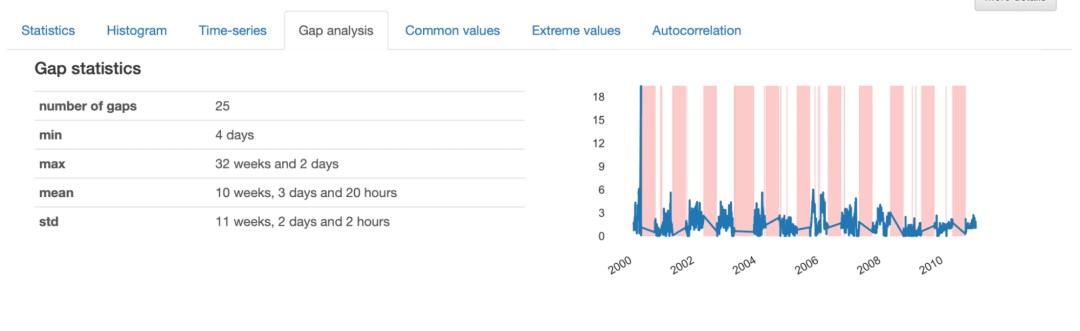
在研究间隙分析所提供的细节时,可以获得对于已识别间隙特征的信息描述。总体而言,时间序列中有25个间隙,最短间隔为4天,最长为32周,平均为10周。
从所呈现的可视化效果中,可以注意到较为“随机”的细条纹代表的是较小的间隙,而较大的间隙似乎遵循着一种重复的模式。这表明我们的数据集中存在两种不同的缺失数据模式。
较小的间隙对应于产生缺失数据的零星事件,很可能是由于采集过程中的错误而发生的,通常可以很容易地对数据进行插值或从数据集中删除。反之,较大的间隙则更为复杂,需要进行更详细的分析,因为它们可能揭示了需要更彻底解决的潜在模式。
在本文的例子中,如果我们调查较大的间隙,实际上会发现它们反映了一个季节性模式:
df = data_scottsdale.copy()
for year in df["Date Local"].dt.year.unique():
for month in range(1,13):
if ((df["Date Local"].dt.year == year) & (df["Date Local"].dt.month ==month)).sum() == 0:
print(f'Year {year} is missing month {month}.')# Year 2000 is missing month 4.
# Year 2000 is missing month 5.
# Year 2000 is missing month 6.
# Year 2000 is missing month 7.
# Year 2000 is missing month 8.
# (...)
# Year 2007 is missing month 5.
# Year 2007 is missing month 6.
# Year 2007 is missing month 7.
# Year 2007 is missing month 8.
# (...)
# Year 2010 is missing month 5.
# Year 2010 is missing month 6.
# Year 2010 is missing month 7.
# Year 2010 is missing month 8.正如我们所猜测的那样,时间序列中呈现出一些较大的信息间隙,它们似乎具有重复性,甚至是季节性的:在大多数年份中,从5月到8月(第5至8个月)之间未收集数据。出现这种情况可能是由于不可预测的原因,或者与业务决策有关,例如与削减成本有关的决定,或者仅仅是与天气模式、温度、湿度和大气条件相关的污染物的季节性变化有关。
根据这些发现,我们可以进一步调查为什么会发生这种情况,是否应该采取措施防止今后出现这种情况,以及如何处理我们目前拥有的数据。
最后的思考:填补、删除、重新对齐?
在本教程中,已经了解到理解时间序列中缺失数据模式的重要性,以及有效的分析方法如何揭示缺失信息的奥秘。无论是电信、医疗、能源还是金融等所有收集时间序列数据的行业,都会在某个时候面临缺失数据的问题,并需要决定处理和从中提取所有可能知识的最佳方法。
通过全面的数据分析,我们可以根据手里拥有的数据特征做出明智而高效的决策:
- 信息间隙可能是由于采集、传输和收集过程中的零星事件导致的。我们可以通过修复问题以防止其再次发生,并根据间隙的长度进行插值或填补缺失数据。
- 信息间隙也可能表示季节性或重复性模式。我们可以选择重构我们的流程,开始收集缺失的信息,或者用来自其他分布式系统的外部信息替代缺失的间隙。我们还可以确定检索过程是否失败(也许是在数据工程方面输入错误的查询)。
希望本教程能够帮助你正确识别和描述时间序列数据中的缺失数据,期待你在间隙分析中的发现!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK