

Presto 在阿里云实时日志分析中的实践和优化
source link: https://www.51cto.com/article/768879.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Presto 在阿里云实时日志分析中的实践和优化

一、业务背景
首先第一部分介绍一下我们的业务背景。阿里云 SLS 是一个云上一站式可观测日志服务平台。
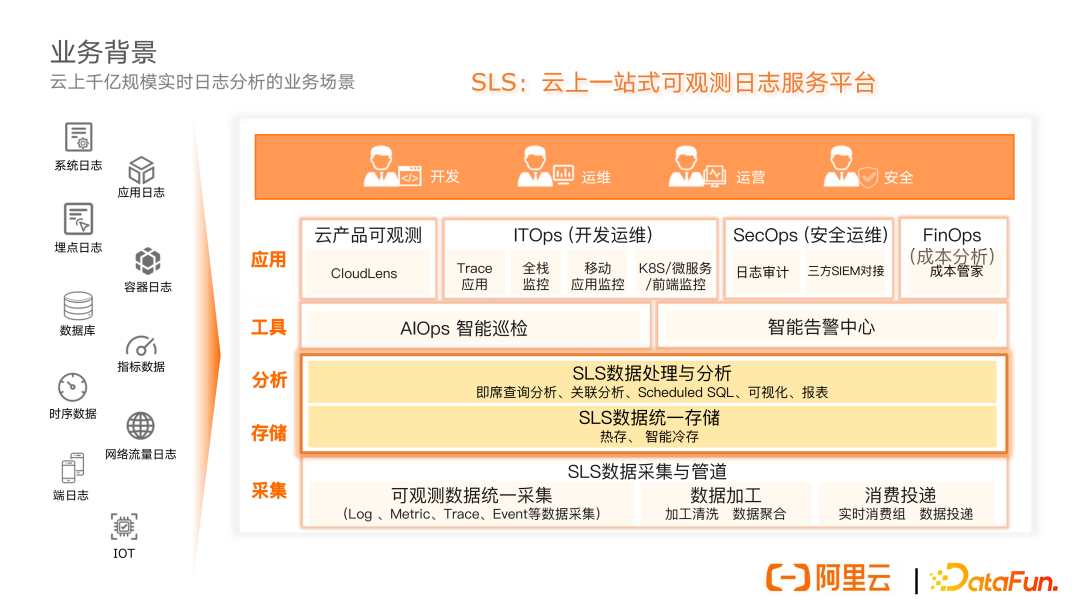
SLS 提供了强大的数据采集、数据加工、消费投递等能力,数据采集利器 ilogtail 目前也已经完全开源。数据采集上来后提供数据的统一存储,包括热存、智能冷存等,帮助用户尽可能节省成本。在存储之上,提供了数据处理与分析能力,包括即席查询分析、关联分析等。这两块构成了整个 SLS 产品的核心基础能力。在这个基础能力之上提供了丰富的工具和应用,最终服务于各种不同的角色和用户。
本文将聚焦在存储和分析基础能力上面的建设,重点分享日志分析系统,以及在面对核心问题时的一些架构设计思路和经验。

这是具体日志分析业务覆盖和服务的能力,主要是围绕日志场景去进行数据分析。日志数据的形态是多种多样的,包括无结构的、半结构的以及结构化的。我们在数据源层面统一收集、存储到存储引擎当中,再通过 SQL 的分析引擎向上层提供数据分析服务。
具体业务,包括比如实时监控、实时大屏这一类基于日志数据分析去做的一些业务,其刷新率非常高,所以用户的并发查询请求量非常大;还有一些比如像基于日志的数据去做实时的告警、链路分析、交互式分析、AI 异常检测等,这一类业务主要是对于数据的时效性要求非常高,要求查询和分析延时要能够做到秒级实时。
还有一类业务,比如像可视化工具、运营报表、schedule SQL 这一类的业务,数据量是非常大的,面临超大数据规模的问题。就整体业务覆盖而言,SLS 除了在阿里云上对外提供日志服务外,在集团内部也被众多的 BU 所使用,同时也经历了多年双十一的挑战。
分析引擎的整体能力方面,我们目前每天大概有数十亿次的查询,每天的行扫描规模大概在千万亿级别,吞吐大概在数十 PB 规模。而我们平均的查询延时小于 300ms,在业务高峰时刻的并发峰值能够达到 7.2 万,届时系统会面临数十万的 QPS 压力。以上就是整体业务的情况。
二、核心问题

面对上述业务场景和需求,我们面临的最核心问题主要包括四个方面。
首先,区别于传统的离线数仓,我们是一个在线的实时分析服务,所以对于查询的低延时要求非常高。我们要求秒级的查询,并且数据要可见即可得、可得即可算。
第二,我们面对的数据处理规模是非常大的,数据的行扫描规模可能从百万到千亿级别不等,并且规模是弹性多变的。
第三,会面临用户高并发的查询压力,像双十一这种业务高峰时刻能达到 7.2 万的并发峰值,同时单点会有上千的并发查询、数十万的计算任务,所以如何去解决系统在面临这种高并发查询下的负载压力,是我们面临的又一个核心问题。
最后还要去解决整个云服务的高可用以及租户间的隔离,由于云服务多、租户是共享云上资源的,所以不可避免会有各种各样的热点资源争用。怎样去解决服务的治理以及压力的防控,保障云服务的高可用,也是我们面临的核心问题之一。
三、关键设计

接下来主要围绕这四个核心的问题,分享在系统架构设计以及关键环节上面的思考和权衡。首先是 SLS 日志查询分析范式,主要是由三部分因素组成:第一部分是查询语句,类似于搜索引擎,可以根据相关的关键字或者是一些过滤查询条件,将特征数据检索出来。第二部分是分析语句,也就是标准的 SQL 语句,可以针对检索出来的一些特征数据,进行灵活的统计和分析。第三部分是时间范围,可以指定任意的时间范围,在这个范围内进行日志数据的分析。所以这三个要素构成了 SLS 整个日志查询分析的范式。

日志数据有它自己的一些特点。首先时间是日志数据的一个天然属性。其次日志分析 99% 的场景是面向特征的,比如像上图中的示例,服务访问日志中包含时间、日志级别、地域、访问域名、http status、延时等多个字段,我们可能就想分析来自 cn-shanghai 地域的访问情况,那我们可以通过关键词检索过滤出需要分析的数据。第三,分析的数据往往具有局部性,比如对于上面的服务日志,我们可能就想分析 status 字段,那对于每一条检索出来的日志,并不需要将整行日志的数据全部加载。这些日志数据的特点是实时、低延时查询分析的关键所在。
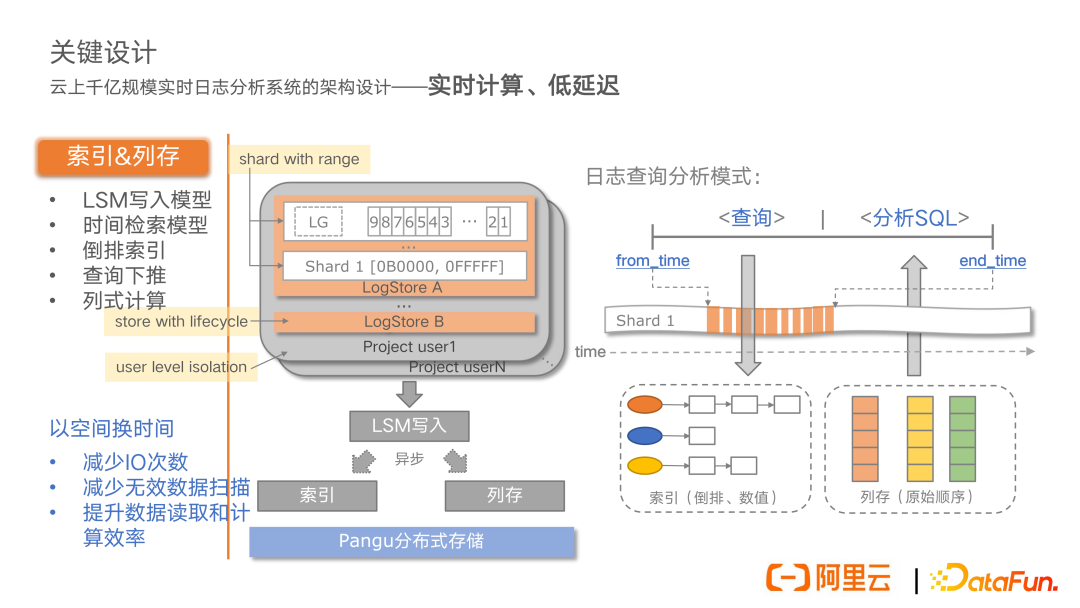
实时计算、低延迟的关键,我认为首先是快速定位数据,其次是高效加载数据,最后是如何执行高效计算。在这里索引和列存是关键。首先介绍一下我们的存储模型,这是一个三级结构,最外层是 project,实现了用户级别的隔离;在 project 内可以有多个 logstore,它是日志数据的存储单元,实现了生命周期 TTL 的管理;在一个 logstore 内部是由多个数据分片(我们叫它 Shard)组成。Shard 间是按照 Range 粒度进行切分,日志数据的写入,是类似于一个队列的形式进行追加,然后按照 hash 均衡负载到各个 Shard 分片上。最终是以 LSM-Tree(log structure merge Tree)的写入模型将数据存储下来。
前面我们刚刚提到了日志的一个天然属性是时间,这里我们基于 LSM 追加写入模型,其实日志数据在一个 Shard 内都是按照时间进行分布的。所以第一个关键点是基于时间检索模型,根据 From 和 To 的时间范围可以快速地定位到某一个 Shard 在某一段时间内的数据。同时根据查询分析范式,对于前面的查询条件,我们可以利用索引倒排技术,高效检索出来我们需要的特征数据。同时,刚刚还提到分析数据可能是局部的,用户可能只需要分析日志数据中的某些字段,所以我们实现了列存,对于索引字段进行列式存储,分析时将指定列的列存数据加载上来进行分析即可。
所以,最终在 LSM 写入之后,会进行异步的索引和列存构建过程,最终统一存储到我们的分布式存储。这就构成了我们整体的存储模型。总体来说,通过索引和列存,以空间来换时间,减少了 IO 次数和无效的数据扫描,提升了数据读取和计算效率。
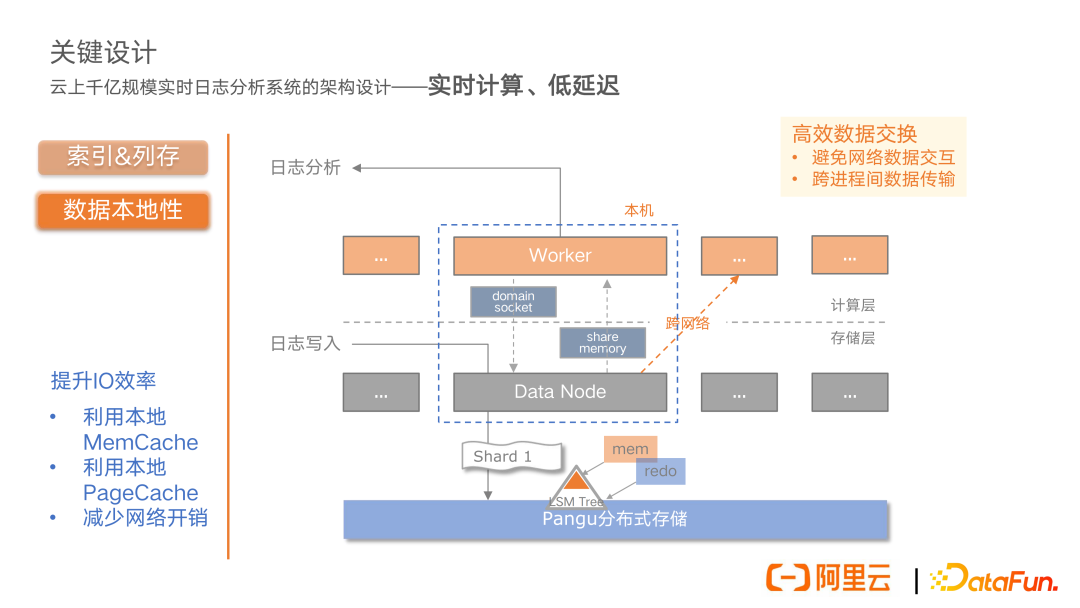
再来看计算和存储架构,首先无论是存储还是计算,都是分布式架构。日志数据的写入基于 LSM 模型,在写入节点上面,一部分热数据在 memory 里面,另一部分则已经 Dump 下去,最终写到分布式存储中,这部分是数据写入。而查询分析时需要加载数据,我们希望能高效利用 LSM 模型特性,尽可能地从 memory 中加载数据,减少不必要的网络和磁盘 IO,因此在存储和计算架构上,我们进行了数据本地性的设计,将计算节点和存储节点放在同一个机器上面,同时因为计算节点和存储节点是跨进程的,所以涉及到数据的交互,这里是通过 domain socket 进行控制面的通信,通过 share memory 完成数据交接。
通过数据本地性的设计,我们利用了 LSM 里面本地的 mem cache,同时利用分布式存储节点上面的 page cache,减少了不必要的磁盘 IO;同时也避免了节点间跨网络的 IO 开销,最终有效地提升了 IO 效率。

有了前面这两点,要实现实时低延迟计算,仍然存在不少挑战。这里引用计算机领域一个大佬的话“所有计算机领域的问题都可以通过另外一层抽象来解决”。我们其实也是借鉴了这一思想,在整个系统里面实现了一个分层缓存。
在数据层面,利用了分布式存储节点上面的 page cache,利用写入节点上面的 memory cache 这样的一些缓存能力。
在索引层面,缓存了倒排数值、字典等等一些索引块的信息,减少反复索引数据的加载以及解码开销。
在分析引擎层面,对元数据进行缓存,将索引字段信息、Shard 分片信息,还有数据分布等这些信息进行缓存,来加速 SQL 语义的解析以及物理执行计划的生成过程。同时,对于相同 SQL 的逻辑执行计划进行了缓存,来减少分析引擎核心节点 coordinator 上面的重复 SQL 解析的开销。
在调度层面,对数据的分片以及任务执行的调度历史进行缓存,这样做的好处是可能有一些节点上面已经加载过一部分的数据,它已经执行过一些历史任务,对这些调度历史进行缓存之后,可以基于亲和力的调度,下次再计算的时候,可以再调度到这个节点上,最大化的利用数据的本地性以及下层缓存的一些收益。
在计算缓存层面,实现了一个 partial agg operator 的算子。它主要是缓存相同数据在相同算子上的部分聚合计算结果,来避免相同数据反复加载和计算的开销。
最终在结果缓存层面,会缓存完全相同的查询的最终计算结果,来减少无效的查询开销。基本上通过这三个层面,在查询的实时性以及低延时上面,可以做到较好的表现。
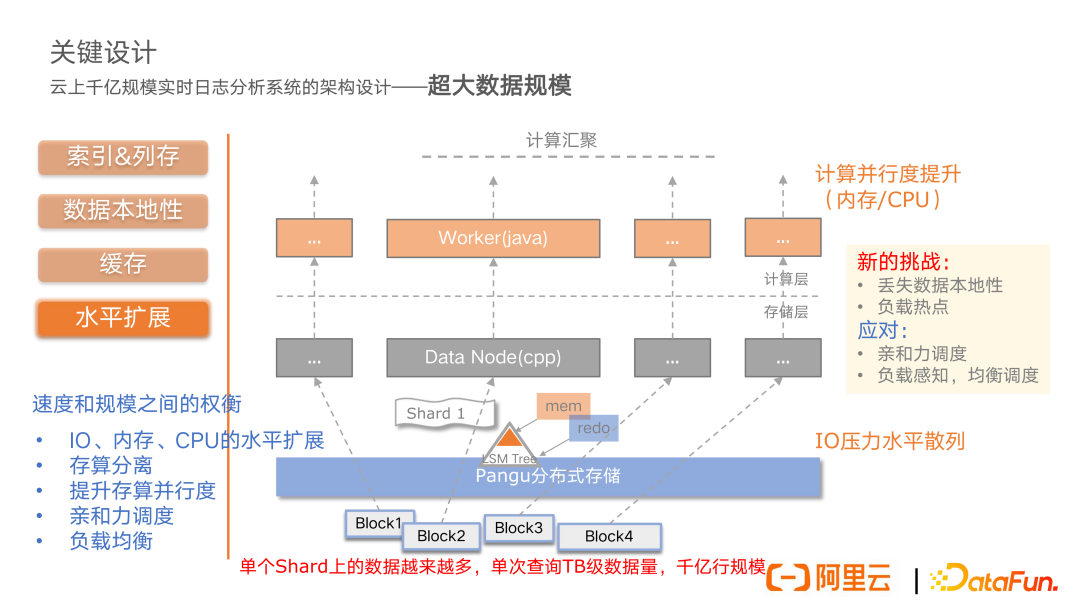
第二个核心问题就是超大数据规模的问题。我们刚刚所讲的存储模型,由于用户的日志数据越写越多,数据块可能越来越多。按照我们前面数据本地性这样的设计,所有的计算要在这样的一个存储节点上面去走,随着单 Shard 上数据规模越来越大,单节点的数据读取和计算能力可能是不够的。所以整体来说,我们会将 LSM 落到分布式存储里面的一些 block 的数据块,把它散列到更多的存储节点上面,分派给上层更多的计算节点,这样整体再交给上面的计算汇聚层,去做相关的计算的汇聚。这样一来,在存储层面我们的 IO 压力可以得到水平散列,在计算层面,我们的计算并行度能够得到大幅的提升,在计算节点上面的内存、CPU 这些资源也能够得到水平扩展。这个是我们在整体架构上面做的调整(即存储计算分离)。
但是我们会面临新的挑战。由于刚刚所说的数据本地性的设计,就是为了避免网络开销来高效地利用数据的本地的缓存,这种存算分离的模式,可能会丢失一部分数据的本地性,可能会导致延时的增高。另外,虽然我们去做了水平的扩展,但是由于数据的一些热点或者是一些倾斜,可能会造成一些局部的热点的负载压力。
针对数据本地性丢失问题,我们的应对方式是基于亲和力的调度,再去调度到这个节点上,利用这个节点上的数据的本地性,尽可能减少数据加载以及延时的开销。另外一个就是去对负载进行实时的感知,通过均衡调度的一些策略,尽量去减少系统的负载的一些热点。所以整体来说,我们是在速度和规模之间进行一个权衡。通过水平扩展,我们可以实现 IO、内存以及 CPU 等资源的横向扩展能力。同时通过存算分离的架构,可以提升存算的并行度,解决超大数据规模的问题。并通过亲和力的调度,以及负载均衡来应对新的挑战。
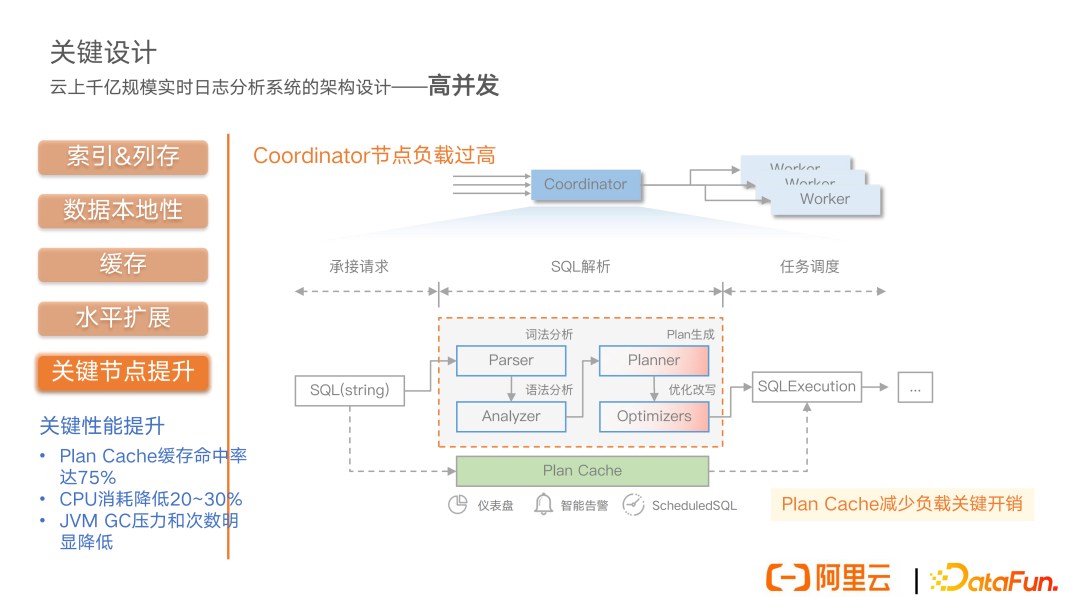
第三个核心问题,系统会面临一些高并发的查询压力。整体来说,分析引擎的架构是非常简单的,前面会有一个 coordinator,也就是一个协调节点。具体工作的 worker 节点,统一由 coordinator 节点来负责整体任务的调度。所以当用户的并发查询请求越来越高的时候,coordinator 上面的负载就会非常大,因为它既要承接前面用户的查询请求,同时还要负责 SQL 的整体的解析任务,同时还要负责整体的计算过程当中的任务调度。我们在实际线上也进行了采样分析,发现 SQL 解析部分,包括词法分析、语法分析,还有 planner 生成以及优化改写这些步骤,对于 CPU 的消耗开销是非常大的,尤其是 plan 生成和优化改写这两步。
另一方面,我们也分析了我们线上的一些业务,发现很多业务来自于仪表盘、智能告警,还有 schedule SQL 这样一些业务。这类业务查询是固定不变的,只变动一些时间。所以这样的查询所对应的逻辑执行计划是不变的,我们就在这个层面去做了查询 plan 这样的一个缓存,通过 plan 的 cache 来减少系统关键节点上面的关键负载的开销。最终的效果是缓存命中率能够达到 75%,同时关键节点上 CPU 的消耗能够降低 20% 到 30%,而且我们的 JVM 的 GC 压力和次数也有明显的降低。
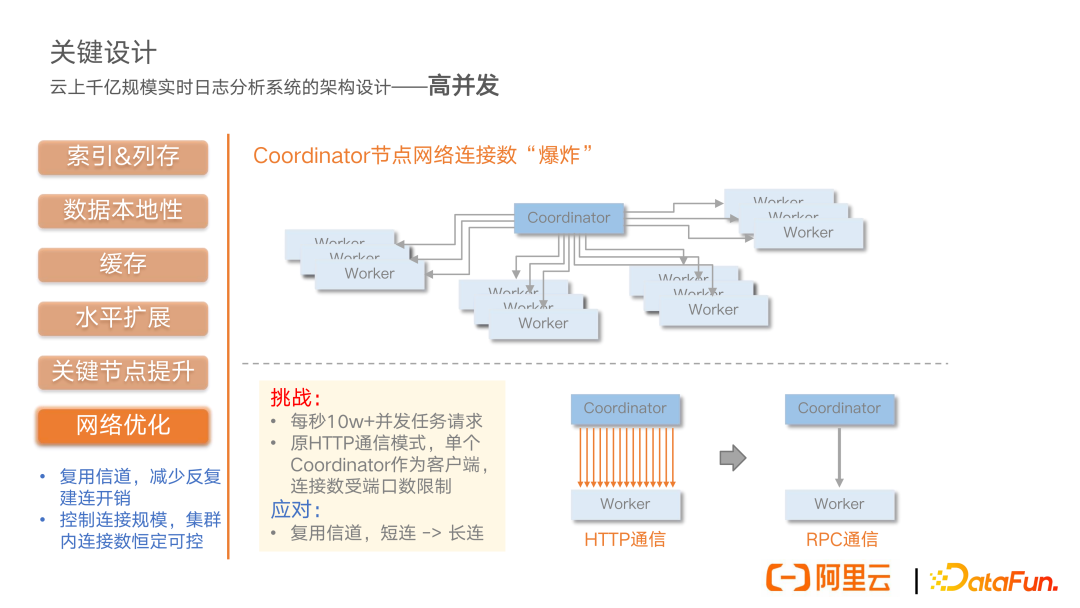
另外一个高并发的问题就是我们的 coordinator 节点上可能会存在这种网络连接数爆炸式的增长。因为 coordinator 在整个分析系统中,是核心协调节点,它要和集群里面所有的 worker 节点进行通信,任务上面进行节点上面的调度交互。所以当集群里面的节点规模越来越大,单个 coordinator 节点网络通信的量是非常大的。面临的挑战是单秒就可能达到 10 万以上的并发任务数。原来是 HTTP 短连接这种通信模式,单个 coordinator 作为一个客户端,要去和所有的 worker 节点进行通信。我们的应对方案就是复用信道,将 HTTP 短连接改造成 RPC 长连。通过复用信道来减少反复建连的开销。同时可以有效控制连接的规模,在集群内把连接数做到恒定可控。
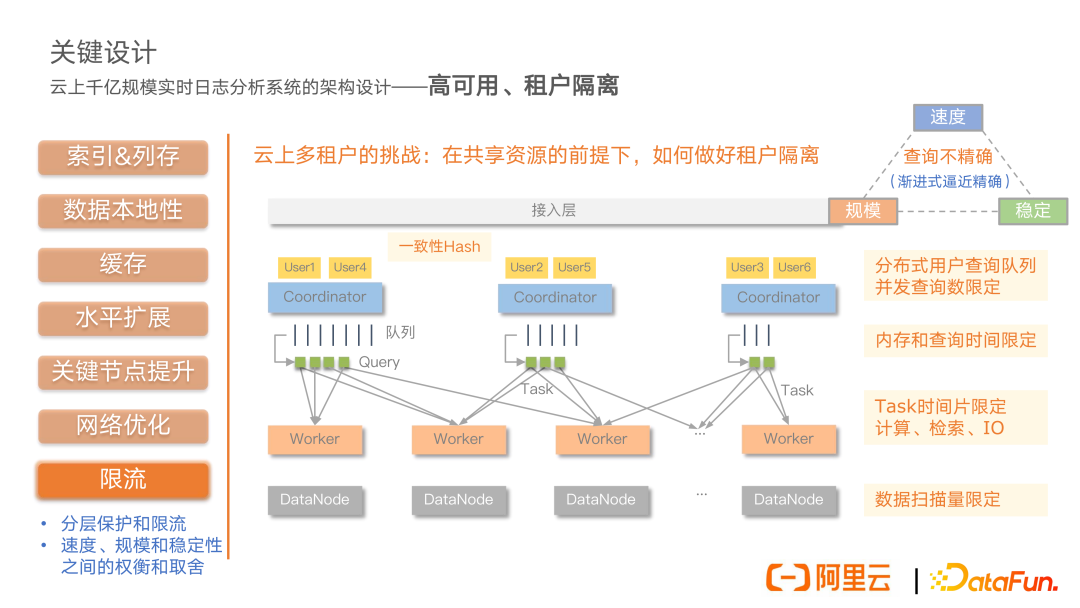
第四个核心问题是服务的高可用以及租户之间的隔离,这也是我们作为云服务不得不解决的一个核心问题。云上多租户的一个核心挑战在于如何在共享资源的前提下去做好租户之间的隔离,做好服务的可用性。我们的思路跟 Linux 的多租户分时复用的思路是相似的,分成若干的时间片去给用户使用相关的资源。重点在于我们怎么去做隔离,以及怎么保证系统的可用性,我们通过限流的方式来做自我的保护,限制用户的使用。首先我们实现了分布式的用户查询队列,基于一致性哈希可以将具体的用户落到具体的 coordinator 节点上,在 coordinator 节点上来统一管控用户的资源使用情况,控制用户的并发查询数。同时在执行过程当中,去监控用户的内存以及查询时间的情况来限定其使用。
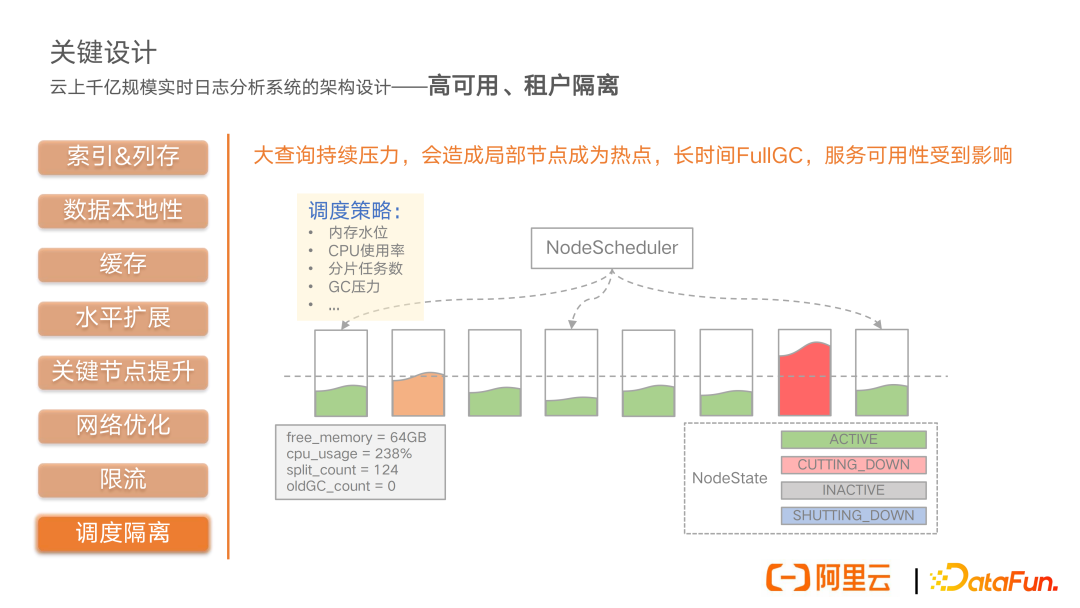
在具体的执行层面,我们会对 task 的时间片进行有效的限定,这里面包括计算层面的,还有查询检索层面的,以及 IO 层面的各种任务时间片。最后,在存储层面,我们会对整体的数据扫描量进行一个限定,避免一下打爆我们的网络带宽。整体来说,通过这样的一个分层的限流措施,我们可以比较好地做到在共享资源情况下的租户隔离,也做到一个比较好的系统的自我防护,保证服务的高可用。
这里还带来另外一个问题,由于我们做了各种限定,可能用户的数据在计算的过程当中没有加载完整,这就会导致查询不精确。针对这种情况,我们的解决思路是并没有直接去返回,查询失败了会把本次查询的一个已经计算出来的结果返回,并且会标记这个结果是不精确的。同时由于我们分层缓存的设计,通过让用户进一步地去查询,可以渐进式地去逼近一个精确的结果。整体来说,我们是通过分层的保护和限流,来实现租户资源之间的隔离和服务的稳定可用。同时我们要在速度、规模还有稳定性上面去做一些权衡和取舍。

总结一下前面所介绍的实践经验。
首先,通过索引列存、数据本地性,以及分级的缓存,解决了第一个核心问题——查询的实时性以及低延时问题;
第二,通过水平的扩展、存算分离等架构上的改造,解决了第二个核心问题;
第三,通过一些关键节点上面的性能提升,以及网络上的优化,解决了系统高并发上的压力。我们目前能够支持云上的海量用户的在线并发查询。同时我们经受住了多年双 11 大促业务高峰并发峰值的考验。
最后,通过分层的限流以及调度隔离,实现了整体的服务的高可用以及多租户的隔离,可以稳定支撑阿里集团数十个 BU,数千条业务线的日志分析需求。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK