

GPT-4竟成Nature审稿人?斯坦福清华校友近5000篇论文实测,超50%结果和人类评审一致
source link: https://www.51cto.com/article/768803.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

GPT-4,已经成功晋身审稿人!
最近,来自斯坦福大学等机构的研究者把数千篇来自Nature、ICLR等的顶会文章丢给了GPT-4,让它生成评审意见、修改建议,然后和人类审稿人给出的意见相比较。

图片
论文地址:https://arxiv.org/abs/2310.01783
结果,GPT-4不仅完美胜任了这项工作,甚至比人类做得还好!
在它给出的意见中,超50%和至少一名人类审稿人一致。
并且超过82.4%的作者表示,GPT-4给出的意见相当有帮助。
论文作者James Zou总结道:我们仍然需要高质量的人工反馈,但LLM可以帮助作者在正式的同行评审之前,改进自己的论文初稿。
图片
GPT-4给你的意见,可能比人类都好
所以,怎样让LLM给你审稿呢?
非常简单,只要从论文PDF中提取出文本,喂给GPT-4,它就立刻生成反馈了。
具体来说,我们要对一个PDF提取、解析论文的标题、摘要、图形、表格标题、主要文本。
然后告诉GPT-4,你需要遵循业内顶尖的期刊会议的审稿反馈形式,包括四个部分——成果是否重要、是否新颖,论文被接受的理由,论文被拒的理由,改进建议。

图片
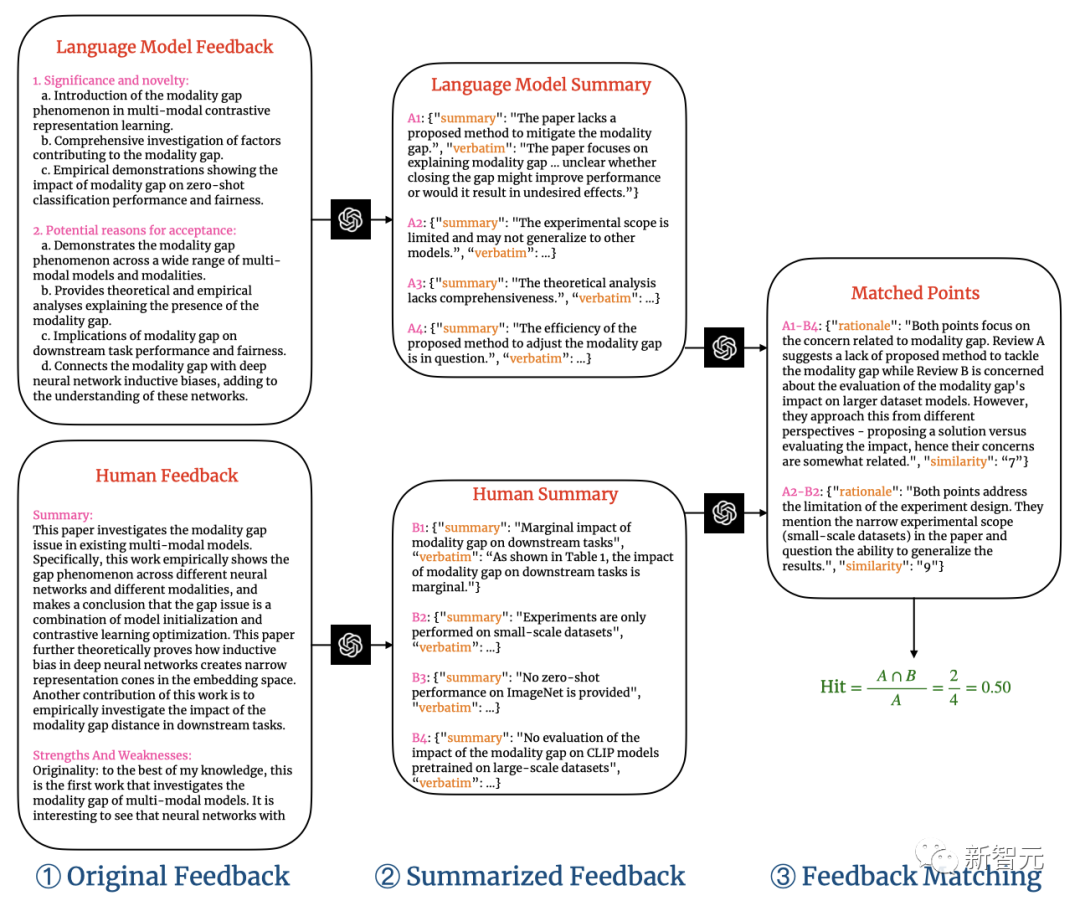
从下图可以看到,GPT-4给出了非常有建设性的意见,反馈包括四部分。
这篇论文有什么缺陷?
GPT-4一针见血地指出:虽然论文提及了模态差距现象,但并没有提出缩小差距的方法,也没有证明这样做的好处。

图片
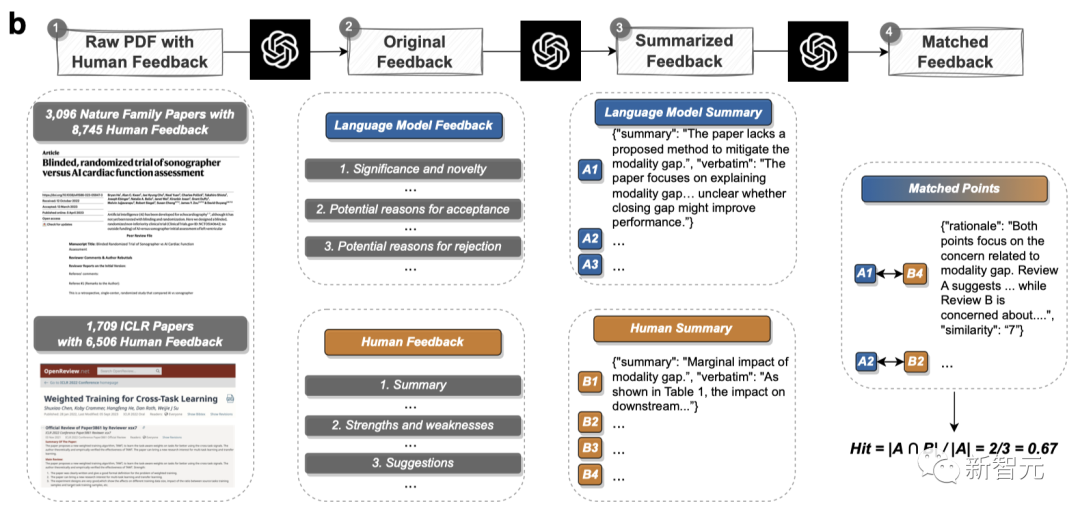
研究者对3,096篇Nature系列论文和1,709篇ICLR论文的人类反馈和LLM反馈进行了对比。
两阶段评论匹配管线会分别提取出LLM和人类反馈中的评论点,然后执行语义文本匹配,来匹配LLM和人类反馈之间的共同评论点。
图片
下图就是一个具体的两阶段评论匹配管线。
对于每条配对评论,相似度评级都会给出理由。
研究者将相似度阈值设为7,弱匹配的评论就会被过滤掉。
图片
在Nature和ICLR两个数据集中,论文和人类评论的平均token长度分别如下。

图片
这项研究有美国110个AI机构和计算生物学机构的308名研究员参与。
每位研究者都上传了自己撰写的论文,看了LLM的反馈,然后填写了自己对于LLM反馈的评价和感受。
图片
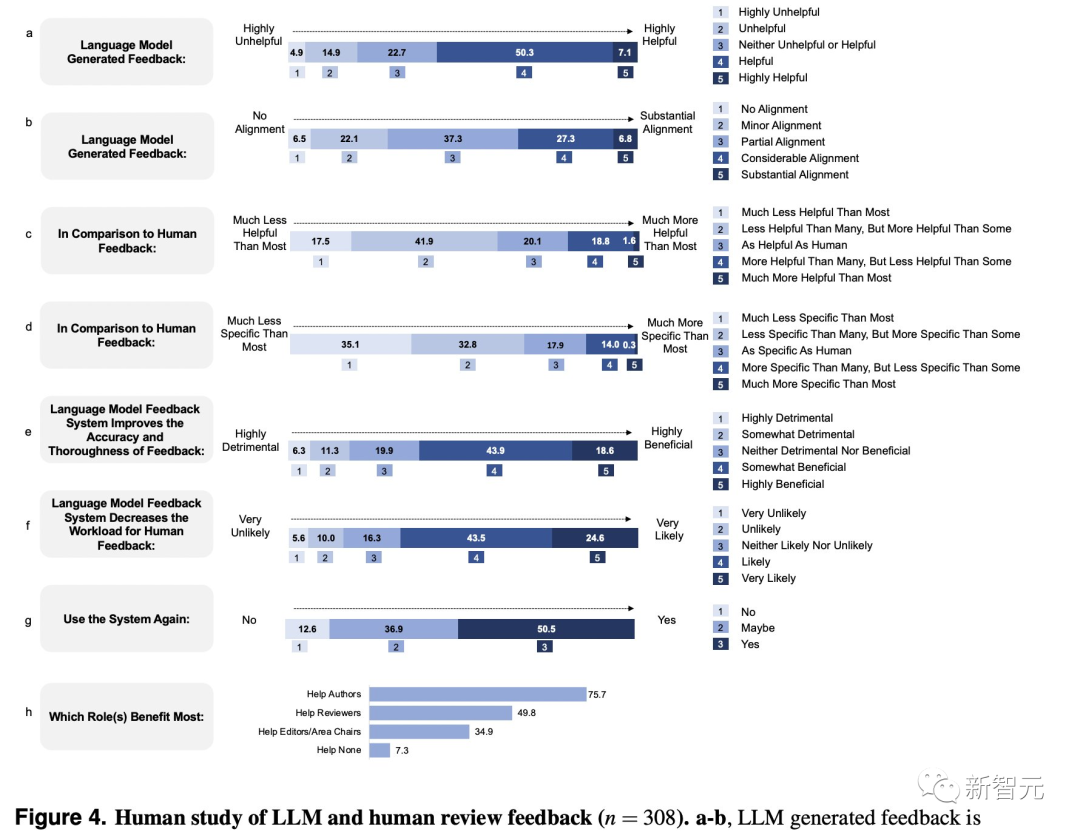
结果显示,研究者普遍认为,跟人类评审的结果相比,LLM生成的反馈与之有很大的重叠,通常很有帮助。
如果说有什么缺点的话,就是在具体性上稍差一些。

图片
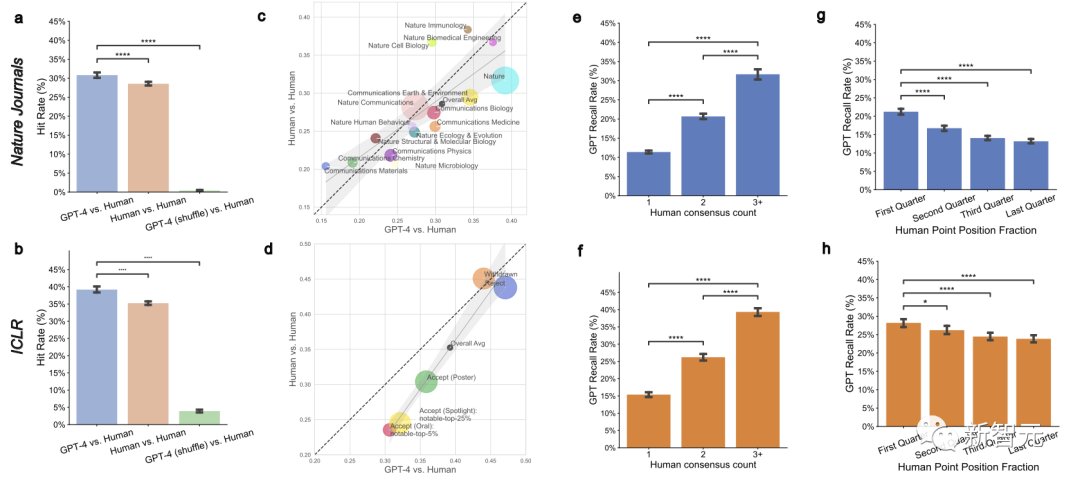
如下图所示,对于提交给Nature的论文,大约三分之一(30.85%)的GPT-4意见与人类审稿人意见重合。
在ICLR论文中,超过三分之一(39.23%)的GPT-4意见与人类审稿人意见重合。
图片
LLM与人类审稿人,偏重略有不同
以下是对同一篇ICLR论文的LLM评论和人类评论,可以看出,LLM的眼光很毒辣,评论很一针见血。
比如与先前研究的对比上,人类审稿员表示:
比较是有缺陷的。尤其是GNN方法的标签一致性和中心一致性损失都没有考虑到。更公平的比较应该是使用两种损失都考虑到的GNN方法。
而GPT-4的评价是:
论文缺乏与现有方法的彻底的比较。虽然作者对于一些方法比较了基线,但还需要更全面的比较。

图片
在理论可靠性上,人类审稿人给出了这样的意见——
恕我直言,理论的证明太琐碎了。最终结论是如果相似度合适,预测的动作就是准确的。由于模型正在学习正确的相似度,也就相当于说模型h如果经过良好的训练,输出就是正确的。这是显然的事。
而GPT-4的意见是:
作者应该提供更多理论分析,来比较信息传递和一致性约束之间的联系,这样能让读者更易于理解。

图片
在研究的可复现性上,人类审稿员希望论文能够提供代码,好让其他读者也能复现实验。
GPT-4对此也给出了相同意见:「作者应该提供有关实验设置的更多详细信息,来确保研究的可复现性。」

图片
参与调查的用户普遍认为,LLM的反馈可以帮助提高评审的准确性,减少人类评审员的工作量。而且大多数用户打算再次使用LLM反馈系统。
图片
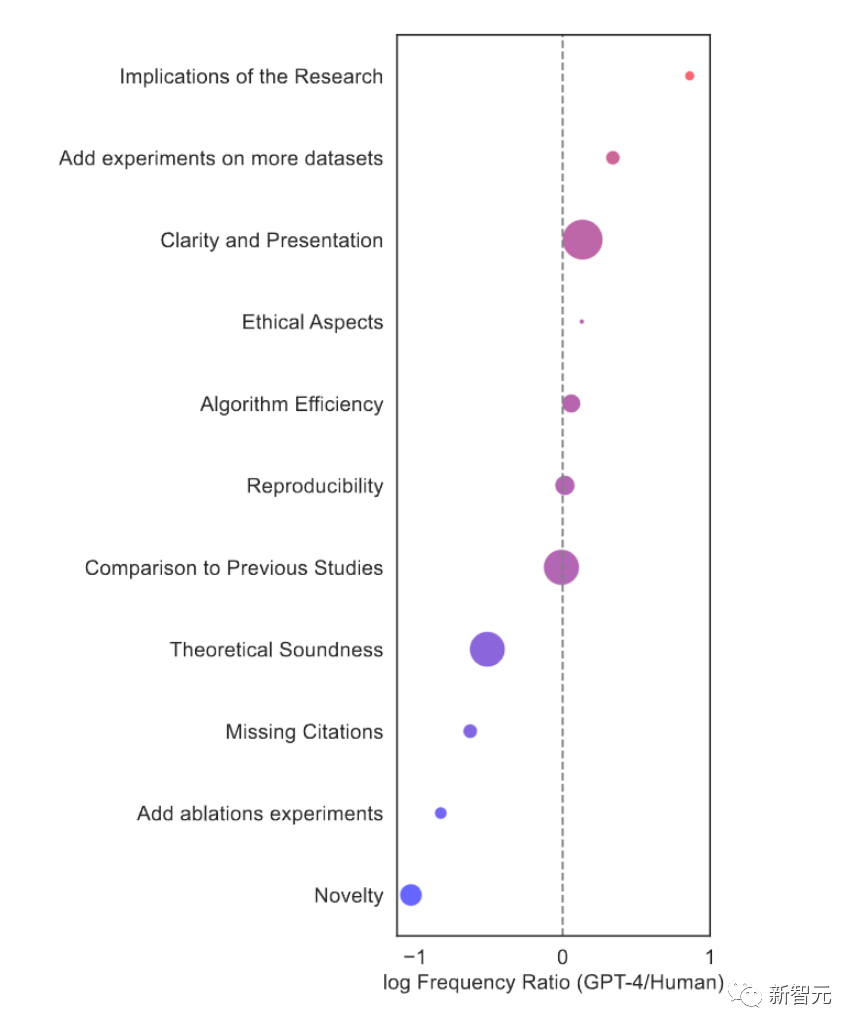
有趣的是,相比人类审稿人,LLM审稿员有自己独有的特点。
比如,它提及影响因子的频率,是人类审稿人的7.27倍。
人类审稿人会更可能要求补充额外的消融实验ablation experiments,而LLM则会注重于要求在更多的数据集上进行实验。
图片
网友们纷纷表示:这项工作很了不起!
也有人说,其实我早就这么干了,我一直在用各种LLM帮我总结和改进论文。
图片
有人问,所以GPT评审会不会为了迎合如今的同行评审标准,让自己有偏见呢?
图片
也有人提出,量化GPT和人类评审意见的重合,这个指标有用吗?
要知道,在理想情况下,审稿人不应该有太多重合意见,选择他们的原意是让他们提供不同的观点。
图片
不过至少,这项研究让我们知道,LLM确实可以用作改论文神器了。
三步,让LLM给你审稿
1. 创建一个PDF解析服务器并在后台运行:
conda env create -f conda_environment.yml
conda activate ScienceBeam
python -m sciencebeam_parser.service.server --port=8080 # Make sure this is running in the backgroundconda create -n llm pythnotallow=3.10
conda activate llm
pip install -r requirements.txt
cat YOUR_OPENAI_API_KEY > key.txt # Replace YOUR_OPENAI_API_KEY with your OpenAI API key starting with "sk-"
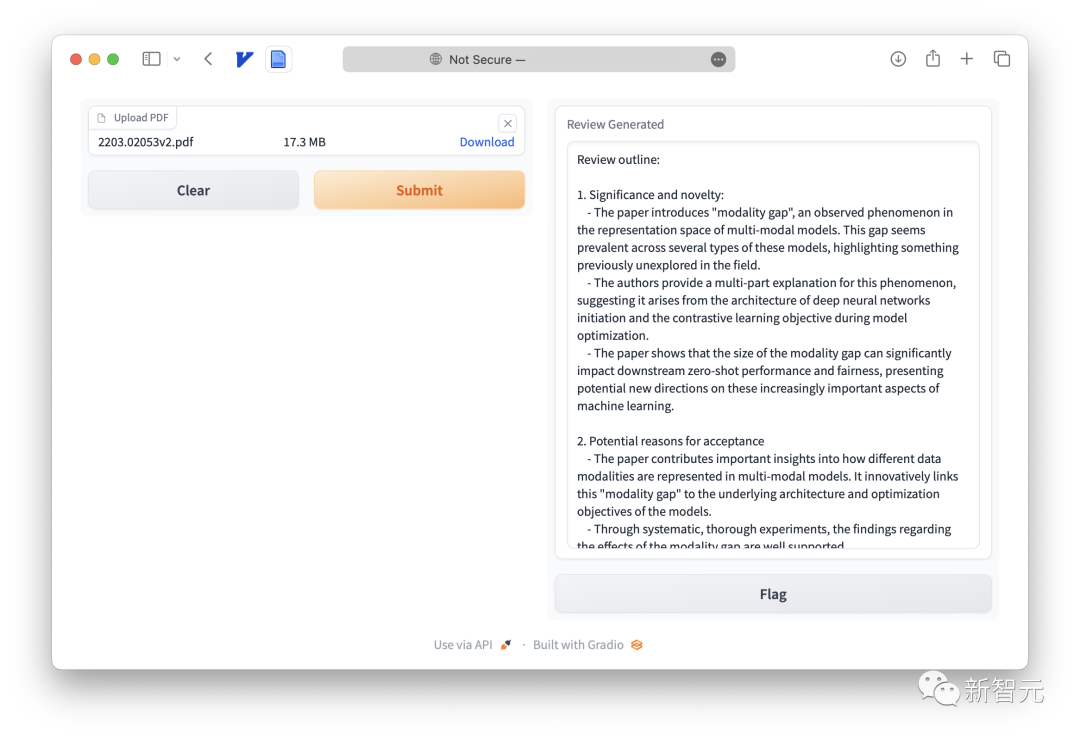
python main.py3. 打开网页浏览器并上传你的论文:
打开http://0.0.0.0:7799并上传论文,就可以在大约120秒内得到LLM生成的反馈。
图片
Weixin Liang(梁伟欣)

Weixin Liang是斯坦福大学计算机科学系的博士生,以及斯坦福人工智能实验室(SAIL)的成员,由James Zou教授的指导。
在此之前,他在斯坦福大学获得电子工程硕士学位,师从James Zou教授和Zhou Yu教授;在浙江大学获得计算机科学学士学位,师从Kai Bu教授和Mingli Song教授。
他曾在亚马逊Alexa AI、苹果和腾讯进行过实习,并曾与Daniel Jurafsky教授、Daniel A. McFarland教授和Serena Yeung教授合作过。
Yuhui Zhang

图片
Yuhui Zhang是斯坦福大学计算机科学系的博士生,由Serena Yeung教授的指导。
他的研究方向是构建多模态人工智能系统和开发从多模态信息中获益的创意应用。
在此之前,他在清华大学和斯坦福大学完成了本科和硕士学业,并与James Zou教授、Chris Manning教授、Jure Leskovec教授等出色的研究人员合作过。
Hancheng Cao(曹瀚成)

图片
Hancheng Cao是斯坦福大学计算机科学系六年级的博士生(辅修管理科学与工程专业),同时也是斯坦福大学NLP小组和人机交互小组的成员,由Dan McFarland教授和Michael Bernstein教授指导。
他于2018年以优异成绩获得清华大学电子工程系学士学位。
2015年起,他在清华大学担任研究助理,导师为李勇教授和Vassilis Kostakos教授(墨尔本大学)。2016年秋,他在马里兰大学杰出大学教授Hanan Samet教授的指导下工作。2017年夏,他作为交换生和研究助理在麻省理工学院媒体实验室人类动力学小组工作,由Alex 'Sandy' Pentland教授 Xiaowen Dong教授指导。
他的研究兴趣涉及计算社会科学、社会计算和数据科学。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK