
2

一日一技:从Pandas DataFrame两个小技巧
source link: https://www.kingname.info/2023/09/05/pandas-normal-columns/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

一日一技:从Pandas DataFrame两个小技巧
2023-09-05
94
296
1 分钟
今天我从网上下载了一批数据。这些数据是Excel格式,我需要把他们转移到MySQL中。这是一个非常简单的需求。
正常情况下,我们只需要5行代码就能解决问题:
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine('数据库链接URI', echo=False)
df = pd.read_excel('Excel文件路径')
df.to_sql(name='表名', con=engine)
但我发现,这个下载的文件有两个工作簿(Sheet),第一个Sheet叫做Overall,第二个Sheet叫做Result。我们需要的数据在Result这个工作簿中。那么,在使用Pandas读取时,需要这样写代码:
df = pd.read_excel('文件路径', 'Result')
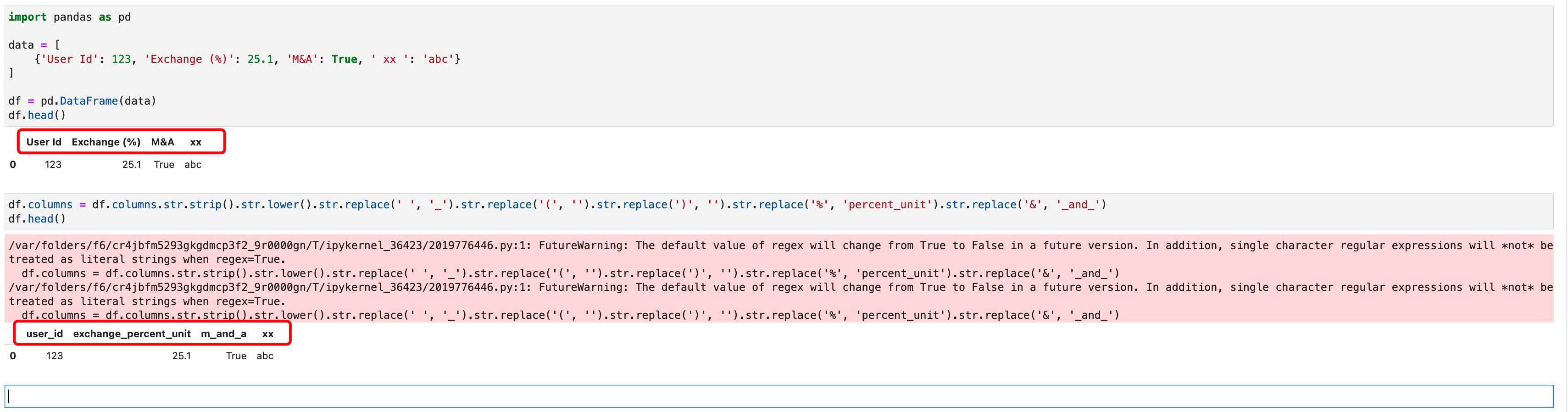
第二个问题,是这个Excel表格的列名,包含了一些不能作为MySQL字段名的值,如下图所示:

其中的空格、括号、百分号、&符号都不适合放到MySQL的字段名中。那么怎么快速批量把这些字符全部替换掉呢?可以使用如下的写法:
df.columns = df.columns.str.strip().str.lower().str.replace(' ', '_').str.replace('(', '').str.replace(')', '').str.replace('%', 'percent_unit').str.replace('&', '_and_')
这样可以批量把所有列名转换为小写字母,并移除特殊符号。效果如下图所示:
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK