

最强LLaMA突然来袭!只改一个超参数,实现上下文3.2万token,多个任务打败ChatGPT、Cl...
source link: https://www.qbitai.com/2023/09/87178.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

最强LLaMA突然来袭!只改一个超参数,实现上下文3.2万token,多个任务打败ChatGPT、Claude 2

“比Meta版ChatGPT更令人兴奋”
明敏 丰色 发自 凹非寺
量子位 | 公众号 QbitAI
悄无声息,羊驼家族“最强版”来了!
与GPT-4持平,上下文长度达3.2万token的LLaMA 2 Long,正式登场。

在性能上全面超越LLaMA 2。
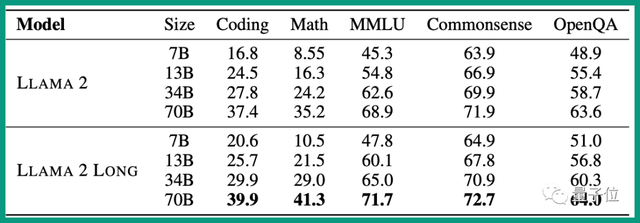
和竞争对手相比,在指令微调MMLU (5-shot)等测试集上,表现超过ChatGPT。
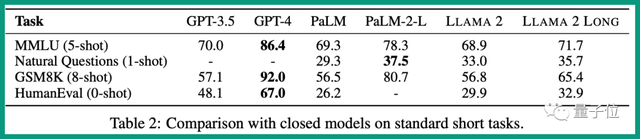
在人类评估(human evaluation)上甚至优于10万token的Claude 2,这个话题还在Reddit上引发了讨论。
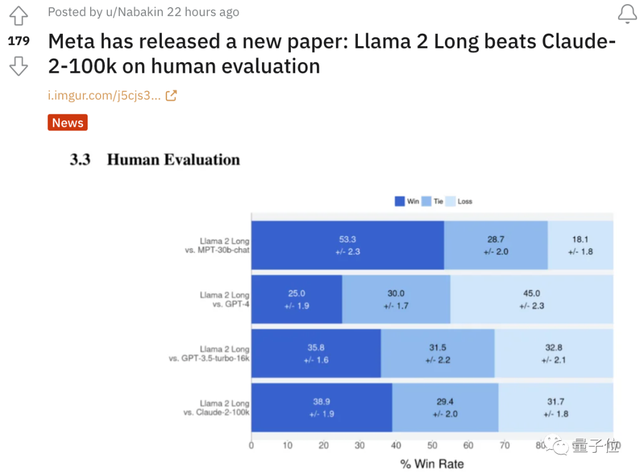
要知道,这些对比版本中,LLaMA 2 Long使用的最大版本也只有70B,远小于其他大模型。
这让人不禁感慨:Meta确实还是有两下子的。
也有人觉得,这才是最近Meta发布会的最大新闻啊,比Meta版ChatGPT要更令人兴奋。
论文介绍,LLaMA 2 Long使用了4000亿token语料加持下,并进行位置编码修改。
所以LLaMA 2 Long究竟是如何诞生的?
只对位置编码进行了一个非常小的改动
与LLaMA 2相比,LLaMA 2 Long的变化并不多。
一是训练参数上,采用了高达4000亿token的数据源。
——相反,原始LLaMA 2包含多个变体,但最多的版本也只有700亿。
二是架构上,与LLaMA 2保持不变,但对位置编码进行了一个非常小的必要修改,以此完成高达3.2亿token的上下文窗口支持。
在LLaMA 2中,它的位置编码采用的是旋转编码RoPE方法。
它是目前大模型中应用最广的一种相对位置编码,通过旋转矩阵来实现位置编码的外推。
本质上来说,RoPE就是将表示单词、数字等信息的token embeddings映射到3D图表上,给出它们相对于其他token的位置——即使在旋转时也如此。
这就能够使模型产生准确且有效的响应,并且比其他方法需要的信息更少,因此占用的计算存储也更小。
在此,Meta的研究人员通过对70亿规模的LLaMA 2进行实验,确定了LLaMA 2中的RoPE方法的一个关键限制:
即,阻止注意力模块聚集远处token的信息。
为此,Meta想出了一个非常简单的破解办法:
减少每个维度的旋转角度。
具体而言就是将超参数“基频(base frequency) b”从10000增加到500000。
这一改动立刻奏效,缩小了RoPE对远端token的衰减效应,并且在扩展LLAMA的上下文长度上优于一项类似的名为“位置插值”的方法(如下图所示,RoPE PI,衰减效果较为“隐含”)。
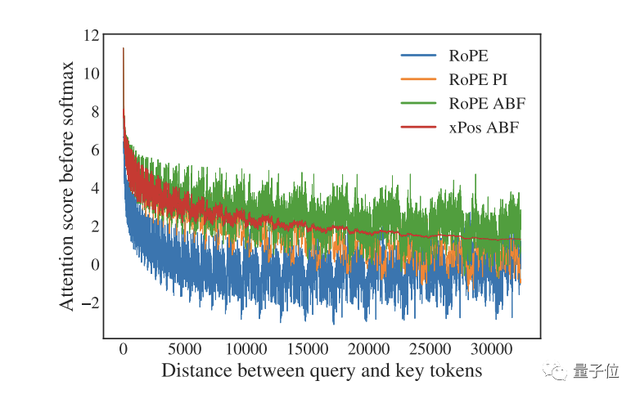
Ps. 图中RoPE表示基线方法,RoPE ABF为Meta此次发明的新方法,xPos是另一种应用了该方法的旋转编码变体。
一个问题是,通过上面这个可视化结果,Meta观察到RoPE在长程区域出现了较大的“振荡”,这对于语言建模来说可能不是个好消息。
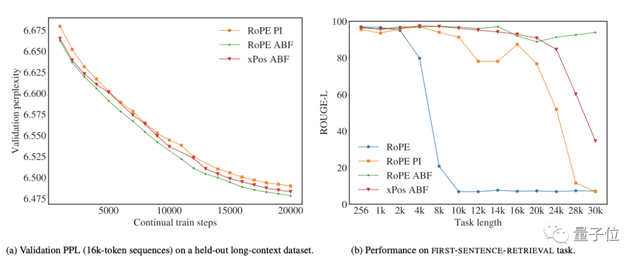
不过,通过报告几种方法在长序列困惑度和FIRST-SENTENCE-RETRIEVAL两个任务上的表现来看,问题不大。
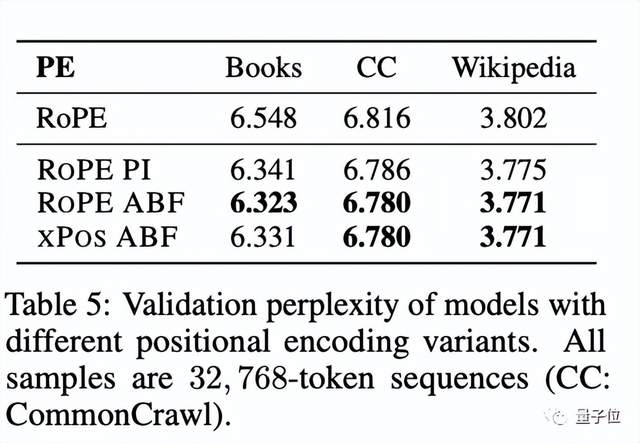
而且,尤其在后者任务上,他们提出的RoPE ABF是唯一一个可以始终保持性能的变体。
在附录中,Meta还通过可视化为螺旋图这一非常有趣的方式,将RoPE ABF与RoPE PI的差异进行了理论分析。
结果是,与RoPE PI相比,RoPE ABF的优势主要体现在它能以更大的粒度分配嵌入向量(the embedded vectors),从而使模型更容易区分位置。

此外,他们还观察到,嵌入向量之间的相对距离既对RoPE PI的关键参数有线性依赖性,也对RoPE ABF的关键参数也有对数依赖性。
这也就是为什么我们可以很容易地对基频这一超参数“下手”。
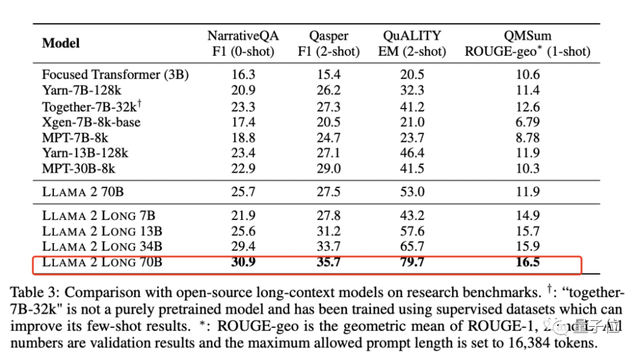
最终,LLaMA 2 Long凭借着这一改动,达成了3.2万的上下文token,并通过长下文连续预训练的共同作用,获得了开头所示的好成绩:
除了全面超越LLaMA 2、在特定任务上超越Claude 2和ChatGPT,Meta也给出了它和一些开源长下文模型的对比。
结果也相当不赖。
One More Thing
值得一提的是,这个最新的版本,是用LLaMA2生成的文本内容来进行训练的。
官方会不会正式发布这一版本,现在还没有更明确的消息,模型的网址也还没有找到。
不过已经有人提前兴奋起来了:
这对可商用微调大模型来说太有用了!
而在此之前,已经有非官方版本实现了3.2万token上下文,也是开源可商用。
“长颈鹿(Giraffe)”基于13B版本的LLaMA2打造。
研究团队提出了一种称为“截断(truncation)”的方法,对原始RoPE编码进行变换。
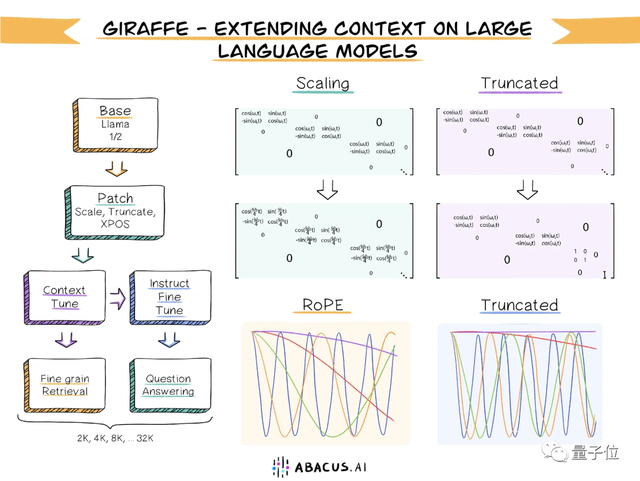
llama-2-7b-32k-instruct也可以支持3.2万上下文,模型规模是7B。
论文:
https://arxiv.org/pdf/2309.16039.pdf
参考链接:
[1]https://venturebeat.com/ai/meta-quietly-releases-llama-2-long-ai-that-outperforms-gpt-3-5-and-claude-2-on-some-tasks/
[2]https://twitter.com/_akhaliq/status/1707569241191285207
[3]https://www.reddit.com/r/LocalLLaMA/comments/16v0onb/meta_has_released_a_new_paper_llama_2_long_beats/
[4]https://news.ycombinator.com/item?id=37698604
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK