

将LLaMA2上下文扩展至100k,MIT、港中文有了LongLoRA方法
source link: https://www.51cto.com/article/768539.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

将LLaMA2上下文扩展至100k,MIT、港中文有了LongLoRA方法
一般来说,大模型预训练时文本长度是固定的,如果想要支持更长文本,就需要对模型进行微调。但是训练具有长上下文的 LLM 计算成本很高,需要大量的训练时间和 GPU 资源。
比如,训练一个具有 8192 长度上下文的模型,相比于 2048 长度上下文,需要 16 倍的计算资源。就算如此,上下文长度对模型性能至关重要,因为它代表了 LLM 回应时对整个上下文清晰理解的能力。
近日,MIT 与香港中文大学联合研究,提出了 LongLoRA。它是一种有效的微调方法,以有限的计算成本扩展了预训练大型语言模型上下文大小。

论文地址:https://arxiv.org/pdf/2309.12307.pdf
项目地址:https://github.com/dvlab-research/LongLoRA
本文从两个方面加快了 LLM 的上下文扩展。
一方面,尽管在推理过程中需要密集的全局注意力,但通过稀疏的局部注意力可以有效且高效地对模型进行微调。本文提出的 shift short attention 有效地实现了上下文扩展,节省了大量的计算,与使用 vanilla attention 进行微调的性能相似。
另一方面,用于上下文扩展的 LoRA 在可训练嵌入和归一化的前提下工作得很好。LongLoRA 在 LLaMA2 模型从 7B/13B 到 70B 的各种任务上都展现了很好的结果。在单台 8x A100 设备上,LongLoRA 将 LLaMA2 7B 从 4k 上下文扩展到 100k, LLaMA2 70B 扩展到 32k。LongLoRA 扩展了模型的上下文,同时保留了其原始架构,并与大多数现有技术兼容,如 FlashAttention-2。为使 LongLoRA 实用,研究者收集了一个数据集 LongQA,用于监督微调。该数据集包含超过 3k 个长上下文问题 - 答案对。
LongLoRA 的能够在注意力水平和权重水平上加速预训练大型语言模型的上下文扩展。亮点如下:
- Shift short attention 易于实现,与 Flash-Attention 兼容,且在推理过程中不需要使用。
- 发布了所有模型,包括从 7B 到 70B 的模型,上下文长度从 8k 到 100k,包括 LLaMA2-LongLoRA-7B-100k、LLaMA2-LongLoRA-13B-64k 和 LLaMA2-LongLoRA-70B-32k。
- 建立了一个长上下文 QA 数据集 LongQA,用于监督微调。研究者已经发布了 13B 和 70B 32k 型号的 SFT、Llama-2-13b-chat-longlora-32k-sft 和 Llama-2-70b-chat-longlora-32k-sft,并将在下个月发布数据集。
LongLoRA 技术细节
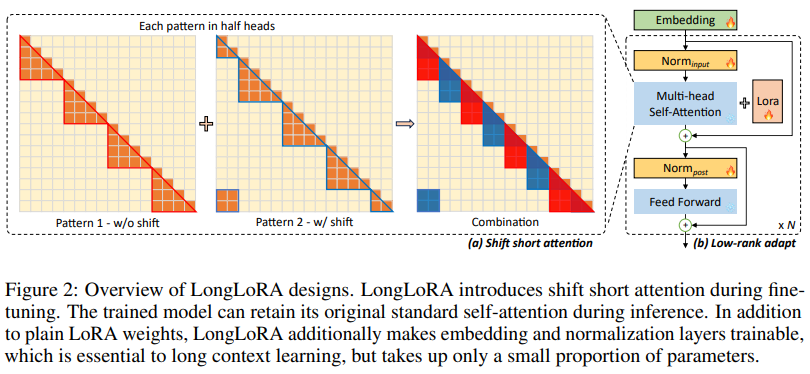
Shift short attention
标准自注意力模式的计算开销为 O (n^2 ),使得长序列上的 LLM 内存开销高且速度慢。为了在训练中避免这个问题,本文提出了 shift short attention(S^2 -Attn),如下图 2 所示。
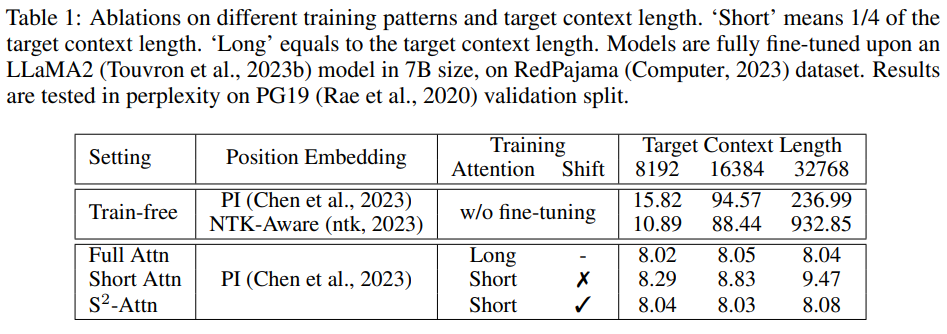
研究者验证了微调的重要性,如下表 1 所示。如果没有微调,随着上下文长度的增长,即使配备了适当的位置嵌入,模型的表现也会变差。
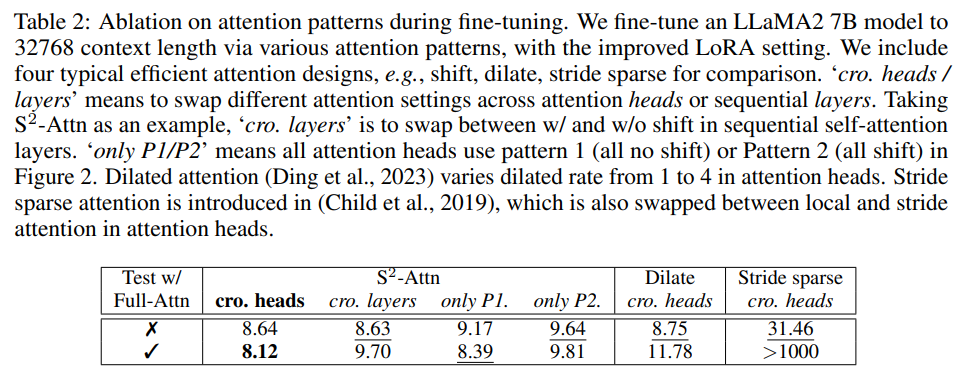
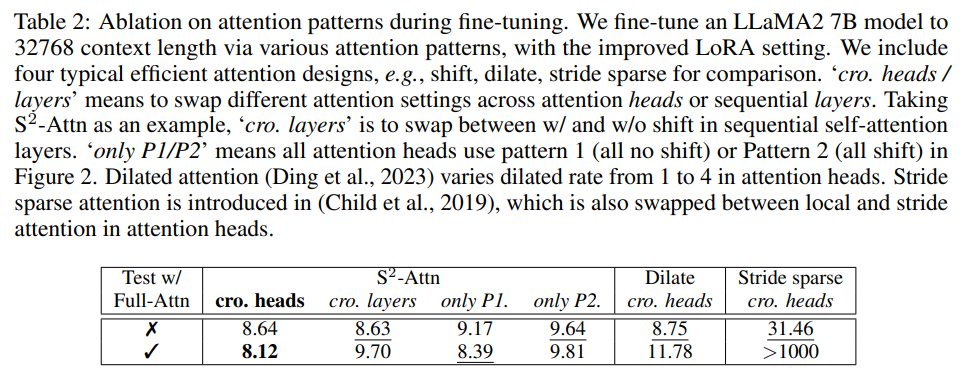
现有的 efficient attention 设计也可以提高长上下文语言模型的效率。在下表 2 中,研究者将 S^2 -Attn 与几种典型的 efficient attention 进行了比较,可以发现,前者不仅能够实现高效的微调,还支持 full attention 测试。
此外,S^2 -Attn 容易实现,它只涉及两个步骤:(1) 转换半注意力头中的 token (2) 将 token 维度的特征移至批次维度。这个过程使用几行代码就够了。
改进长上下文 LoRA
LoRA 是一种有效且流行的方法,可使 LLM 适应其他数据集。与完全微调相比,它节省了很多可训练参数和内存成本。然而,将 LLM 从短上下文长度调整为长上下文长度并不容易。研究者观察到 LoRA 和完全微调之间存在明显的差距。如下表 3 所示,随着目标上下文长度的增大,LoRA 和完全微调之间的差距也会增大。
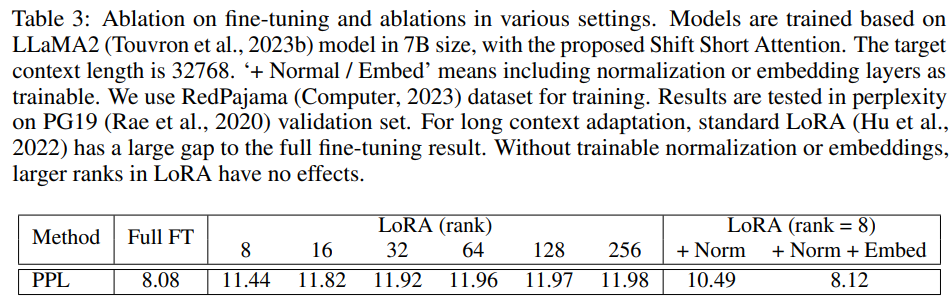
为了弥补这一差距,研究者打开嵌入层和归一化层进行训练。如表 3 所示,它们占用的参数有限,但对长上下文适应有影响。特别是归一化层,在整个 LLaMA2 7B 的参数占比仅为 0.004%。在实验中,研究者将这种改进的 LoRA 表示为 LoRA+。
实验及结果
研究者扩展了预训练的 7B、13B 和 70B LLaMA2 模型。7B 模型的最大扩展上下文窗口大小为 100k,13B 模型的最大扩展上下文窗口大小为 65536,70B 模型的最大扩展上下文窗口大小为 32768。
研究者沿用了 Position Interpolation 中的大部分训练超参数,不过批大小更小,因为只是在某些情况下使用单台 8×A100 GPU 设备。所有模型都通过下一个 token 预测目标进行微调。研究者使用 AdamW,其中 β_1 = 0.9,β_2 = 0.95。7B 和 13B 模型的学习率设定为 2 × 10^−5,70B 模型的学习率设定为 10^−5。
他们还使用了线性学习率预热。权重衰减为零。每台设备的批大小设为 1,梯度累积步骤设为 8,这意味着使用 8 个 GPU,全局批大小等于 64。模型进行了 1000 步的训练。
研究者使用 Redpajama 数据集进行训练,并构建了一个长上下文 QA 数据集 LongQA,用于监督微调。Redpajama 微调的模型呈现了良好的困惑度,但它们的聊天能力是有限的。研究者收集了超过 3k 个问题 - 答案对,它们都是与技术论文、科幻小说和其他书籍等材料有关的。设计的问题包括总结、关系、人物等。
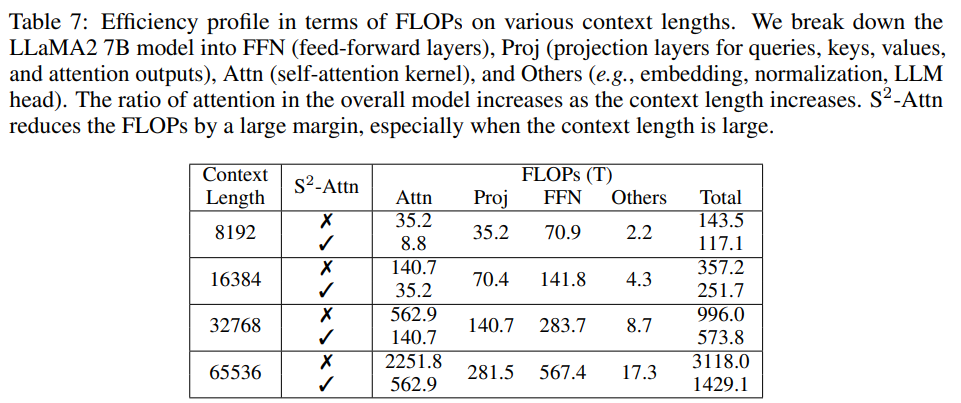
从下表 4 中可以发现,在相同的训练和评估上下文长度的情况下,困惑度随着上下文大小的增加而降低。
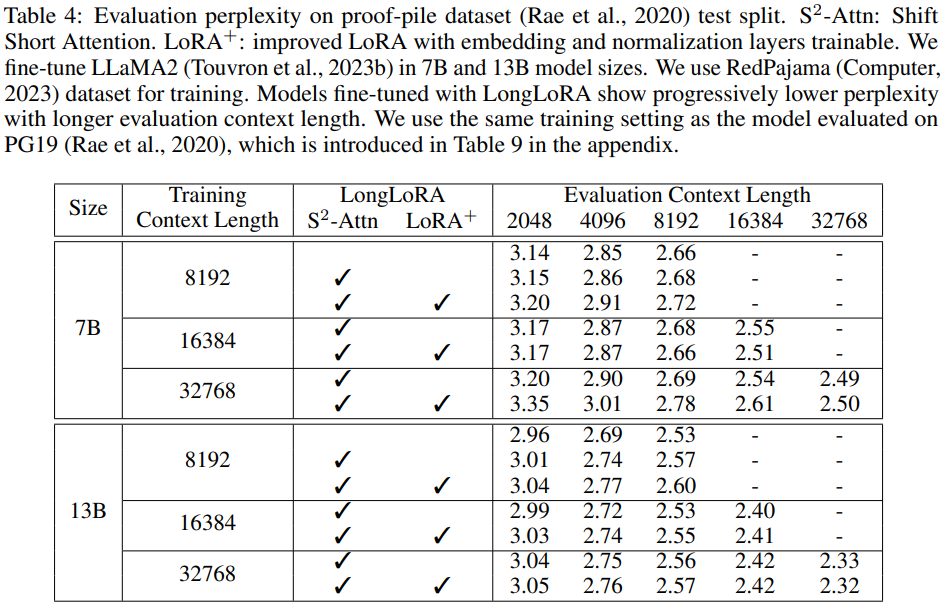
在下表 5 中,研究者进一步考察了在单台 8×A100 设备上可微调的最大上下文长度。他们分别将 LLaMA2 7B、13B 和 70B 扩展到 100k、65536 和 32768 上下文长度。LongLoRA 在这些超大设置上取得了令人满意的结果。此外,实验还发现扩展模型在较小的上下文长度上会出现一些困惑度下降。
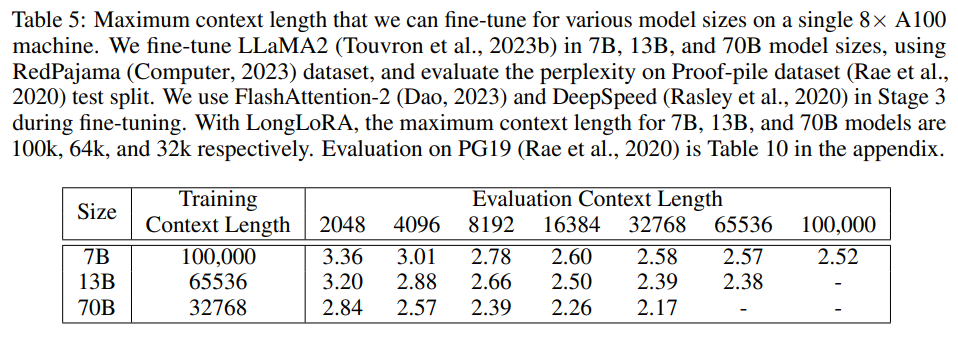
在下表 6 中,研究者将模型与其他开放式 LLM 在 LongChat 中引入的主题检索任务上进行比较。这个任务是从很长的对话中检索目标话题,对话长度从 3k、6k、10k、13k 到 16k 不等。
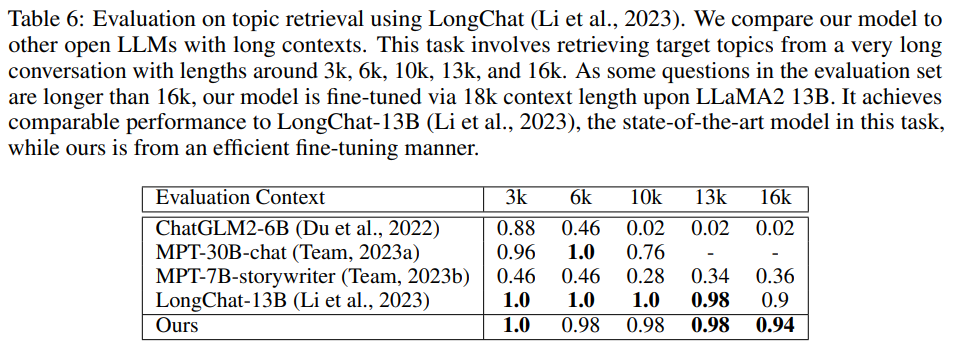
消融实验
在下表 7 中,研究者将 LLaMA2 7B 细分为各种类型的层。他们分析了 FLOPs:对于 full attention,随着上下文长度的增加,Attn 的比例也急剧增加。例如,在上下文长度为 8192 时,Attn 占总 FLOP 的 24.5%,而在上下文长度为 65536 时,则增至 72.2%。当使用 S^2 -Attn 时,则下降到 39.4%。
下表 8 展示了在 PG19 验证集上扩展到 8192 上下文长度时, LLaMA2 7B 模型的复杂度与微调步骤之间的关系。可以发现,如果不进行微调,在第 0 步时,模型的长上下文能力有限。完全微调比低阶训练收敛得更快。两者在 200 步后逐渐接近,最后没有出现大的差距。

下表 2 显示了微调过程中不同注意力模式的效果。
效果展示
模型在阅读《哈利・波特》的内容后,能够告诉你斯内普为什么看起来不喜欢哈利,甚至还能总结人物之间的关系。

不仅如此,给它一篇论文,还能帮助你立刻了解相关信息。

更多详细内容,请参阅原文。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK