

Bootstrap PostgreSQL on Kubernetes
source link: https://www.percona.com/blog/bootstrap-postgresql-on-kubernetes/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Bootstrap PostgreSQL on Kubernetes
August 29, 2023
PostgreSQL has become increasingly popular in modern cloud-native environments. However, managing PostgreSQL clusters on Kubernetes can be a complex task. This is where the Percona Operator comes into play, offering a powerful solution to deploy and manage PostgreSQL clusters effortlessly. Developers often seek an easy way to bootstrap the clusters with data so that applications can start running immediately. It is especially important for CICD pipelines, where automation plays a crucial role.
In this blog post, we will explore the immense value of provisioning PostgreSQL clusters with Percona Operator by using bootstrap capabilities:
- Start the cluster with init SQL script
- Bootstrap the cluster from the existing cluster or backup
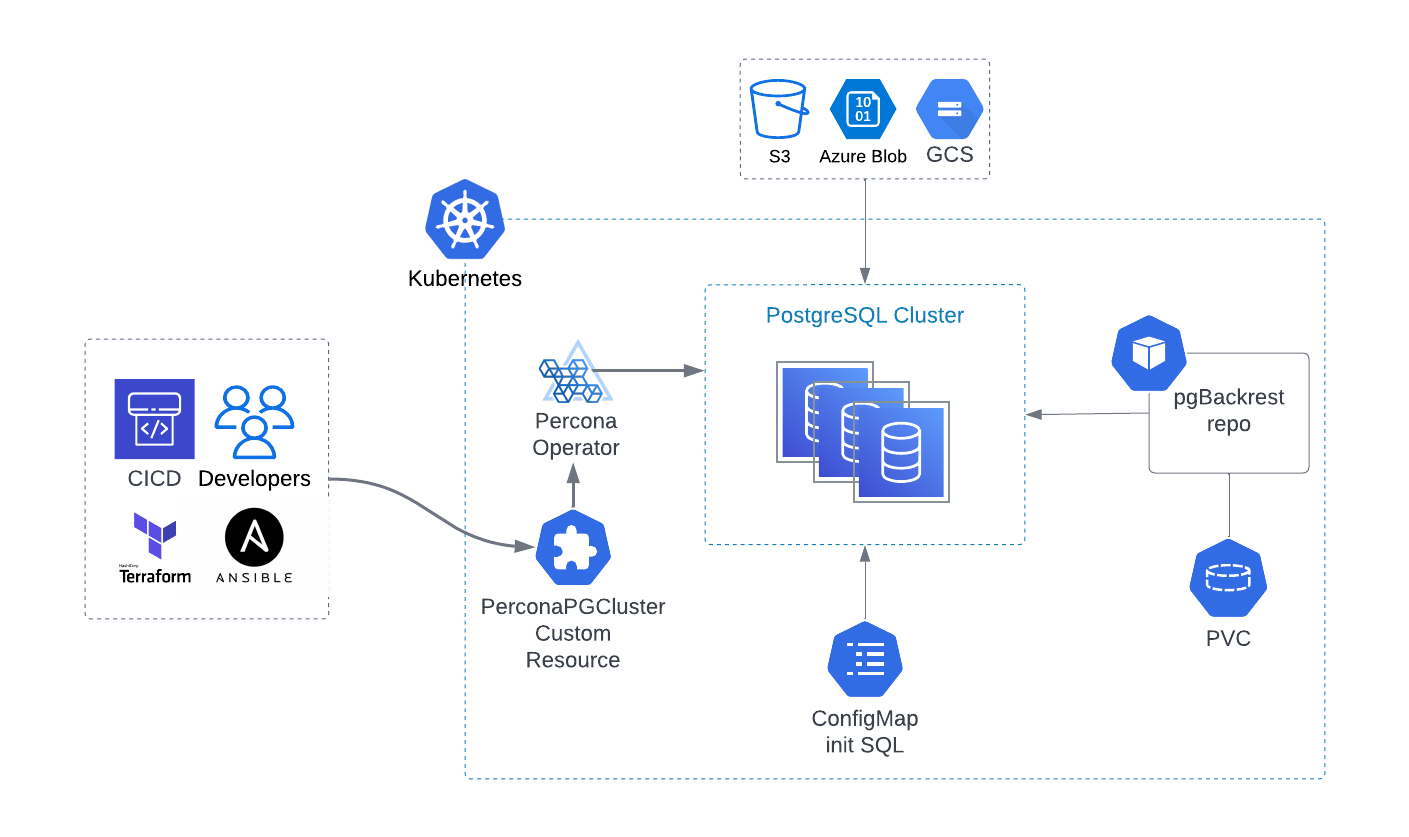
Getting started
You need to have the Percona Operator for PostgreSQL deployed. Please follow our installation instructions and use your favorite way.
You can find all examples from this blog post in this GitHub repository. A single command to deploy the operator would be:
kubectl apply -f https://raw.githubusercontent.com/spron-in/blog-data/master/bootstrap-postgresql-k8s/00-bundle.yaml --server-side |
Init SQL script
Init SQL allows the creation of the database cluster with some initial data in it. Everything is created with postgres admin user. The way it works is the following:
- Create the ConfigMap resource with the SQL script
- Reference it in the PerconaPGCluster Custom Resource
The operator will apply the SQL during cluster creation. It is quite usual to combine this feature with the user creation.
Create the ConfigMap from 01-demo-init.yaml manifest:
The init.sql does the following:
- Connects to demo-db database
- Creates schema media for user myuser
- Creates 2 tables – BLOG and AUTHORS in the schema
I’m combining bootstrapping with the user and database creation functionality that the Operator also provides. In my 02-deploy-cr.yaml manifest, I created the user myuser and database demo-db:
users: - name: myuser databases: - demo-db |
Reference the ConfigMap in the custom resource:
databaseInitSQL: key: init.sql name: demo-cluster-init |
Applying the manifest would do the trick:
kubectl apply -f https://raw.githubusercontent.com/spron-in/blog-data/master/bootstrap-postgresql-k8s/02-deploy-cr.yaml |
Troubleshooting
To verify if init SQL was executed successfully or to check if something went wrong, see the Operator’s log. Search for init SQL. For example, the following tells me that I had a syntax error in my SQL script for demo-cluster:
$ kubectl logs --tail=2000 percona-postgresql-operator-6f96ffd8d4-ddzth | grep 'init SQL' time="2023-08-14T09:37:37Z" level=debug msg="applied init SQL" PostgresCluster=default/demo-cluster controller=postgrescluster controllerKind=PostgresCluster key=init.sql name=demo-cluster-init namespace=default reconcileID=1d0cfdcc-0464-459a-be6e-b25eb46ed2c9 stderr="psql:<stdin>:11: ERROR: syntax error at or near "KEYS"nLINE 2: ID INT PRIMARY KEYS NOT NULL,n ^n" stdout="You are now connected to database "demo-db" as user "postgres".nCREATE SCHEMAnCREATE TABLEn" version= |
Bootstrap from cluster or backup
ConfigMaps cannot store more than one MB of data, which means that init SQL approach is good for some small data bootstraps. If you have a big dataset that you want to roll out along with cluster creation, then there are two ways to do that:
- From an existing cluster in Kubernetes
- From the backup
From the cluster
To use this, you must have a running cluster and pgBackrest configured repo for it. Now, you can create the second cluster.
03-deploy-cr2.yaml manifest will provision demo-cluster-2. I have removed the spec.databaseInitSQL section while keeping spec.users. To instruct the Operator to restore from demo-cluster and its repo1 I added the dataSource section:
dataSource: postgresCluster: clusterName: demo-cluster repoName: repo1 |
The new cluster will be created once the manifest is applied:
$ kubectl apply -f https://raw.githubusercontent.com/spron-in/blog-data/master/bootstrap-postgresql-k8s/03-deploy-cr2.yaml $ kubectl get pg NAME ENDPOINT STATUS POSTGRES PGBOUNCER AGE demo-cluster demo-cluster-pgbouncer.default.svc ready 1 1 14m demo-cluster-2 demo-cluster-2-pgbouncer.default.svc ready 1 1 13m |
demo-cluster-2 will have the same data as demo-cluster. Keep in mind that even if data is the same, the user passwords would be different by default. You can change this; please see users documentation.
From the backup
Another common case is bootstrapping from an existing backup in case the database cluster is not running anymore, or it is isolated in another Kubernetes cluster. In this case, the backups should be stored on some object storage. Please use our documentation to configure backups.
For example, my demo-cluster configuration in 04-deploy-cr.yaml looks like this if I want to take the backups to Google Cloud Storage (GCS):
pgbackrest: global: - secret: name: demo-cluster-gcs repos: - name: repo1 schedules: full: "0 0 * * 6" bucket: "my-demo-bucket" |
Once you have backups stored in the object storage, you can delete the cluster and reference it in the manifest anytime for bootstrapping. For example, in 05-deploy-cr3.yaml, dataSource section looks like this:
dataSource: pgbackrest: stanza: db configuration: - secret: name: demo-cluster-gcs global: repo1-path: /pgbackrest/demo/repo1 repo: name: repo1 bucket: "my-demo-bucket" |
The fields have the same structure and reference the same Secret resource where GCS configuration is stored.
Troubleshooting
When you bootstrap the cluster from pgBackrest backup, the Operator creates a pgbackrest-restore pod. If it crashes and jumps into Error state, it indicates that something went wrong.
$ kubectl get pods NAME READY STATUS RESTARTS AGE demo-cluster-3-pgbackrest-restore-74dg5 0/1 Error 0 27s $ kubectl logs demo-cluster-3-pgbackrest-restore-74dg5 Defaulted container "pgbackrest-restore" out of: pgbackrest-restore, nss-wrapper-init (init) + pgbackrest restore --stanza=db --pg1-path=/pgdata/pg15 --repo=1 --delta --link-map=pg_wal=/pgdata/pg15_wal WARN: unable to open log file '/pgdata/pgbackrest/log/db-restore.log': No such file or directory NOTE: process will continue without log file. WARN: --delta or --force specified but unable to find 'PG_VERSION' or 'backup.manifest' in '/pgdata/pg15' to confirm that this is a valid $PGDATA directory. --delta and --force have been disabled and if any files exist in the destination directories the restore will be aborted. WARN: repo1: [FileMissingError] unable to load info file '/pgbackrest/demo/repo1/backup/db/backup.info' or '/pgbackrest/demo/repo1/backup/db/backup.info.copy': FileMissingError: unable to open missing file '/pgbackrest/demo/repo1/backup/db/backup.info' for read FileMissingError: unable to open missing file '/pgbackrest/demo/repo1/backup/db/backup.info.copy' for read HINT: backup.info cannot be opened and is required to perform a backup. HINT: has a stanza-create been performed? ERROR: [075]: no backup set found to restore |
Conclusion
One of the key advantages of running PostgreSQL with Percona Operator is the speed of innovation it brings to the table. With the ability to automate database bootstrapping and management tasks, developers and administrators can focus on more important aspects of their applications. This leads to increased productivity and faster time-to-market for new features and enhancements.
Furthermore, the integration of bootstrapping PostgreSQL clusters on Kubernetes with CICD pipelines is vital. With Percona Operator, organizations can seamlessly incorporate their database deployments into their CI/CD processes. This not only ensures a rapid and efficient release cycle but also enables developers to automate database provisioning, updates, and rollbacks, thereby reducing the risk of errors and downtime.
Try out the Operator by following the quickstart guide here.

You can get early access to new product features, invite-only ”ask me anything” sessions with Percona Kubernetes experts, and monthly swag raffles. Interested? Fill in the form at percona.com/k8s.
Percona Distribution for PostgreSQL provides the best and most critical enterprise components from the open-source community, in a single distribution, designed and tested to work together.
Download Percona Distribution for PostgreSQL Today!
Share This Post!
Subscribe

Label
Recommend
-
30
README.md Kubernetes The Hard Way This tutorial walks you through setting up Kubernetes the hard way. This guide is not for people looking for a fully...
-
71
README.md Postgres Operator
-
8
PGO: The Postgres Operator from Crunchy Data Run Cloud Native PostgreSQL on Kubernetes with PGO: The Postgres Operator from Crunchy Data! PGO, the...
-
7
Autoscaling Databases in Kubernetes for MongoDB, MySQL, and PostgreSQL Back to the Blog
-
4
Migrating PostgreSQL to Kubernetes Back to the Blog More and more companies are adopting Kubernetes. For some it is about being cutting-edge, for some, it is a well-define...
-
27
PostgreSQL 14 on Kubernetes (with examples!) October 04, 2021 Jonathan S. Katz ...
-
7
How to Run the SAFE Stack on Kubernetes with a PostgreSQL Backend This website stores cookies on your computer. These cookies are used to collect information about how you interact with our website and allow us to reme...
-
6
Percona Distribution for PostgreSQL Operator allows you to deploy and manage highly available and production-grade PostgreSQL clusters on Kubernetes with...
-
6
Install Percona Distribution for PostgreSQL on Google Kubernetes Engine (GKE)¶
-
10
Run PostgreSQL on Kubernetes with Percona Operator & Pulumi Back to the Blog Avoid vendor lock-in, provide a private Database-as-a-Service for internal teams, quickly...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK