

Cloud and ML leadership with Neoverse V2 - Infrastructure Solutions blog - Arm C...
source link: https://community.arm.com/arm-community-blogs/b/infrastructure-solutions-blog/posts/arm-neoverse-v2-platform-best-in-class-cloud-and-ai-ml-performance
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Arm Neoverse V2 Platform: Best in Class Performance/TCO for the Cloud

The future is being built on Arm. This is no longer an aspiration, rather it demonstrates the cumulative progress of Arm’s deliberate strategy to deliver meaningful performance uplift with industry-leading power efficiency, while expanding software ecosystem support. The ubiquity of Arm technology in every aspect of modern life is well established. With more than 250+ billion Arm-based chips shipped to date, (30+ billion in the past year alone) - covering everything from embedded, mobile, edge and datacenter - the world is witnessing the innovation and benefits of technology developed by Arm and its ecosystem partners.
With the introduction of the Neoverse N1 platform in 2019, comprising the Neoverse N1 core, Corelink CMN-600 interconnect and supporting System IP, Arm led the industry in performance-per-watt efficiency enabling best-in-class SoCs for cloud-to-edge deployments. It’s successor, the Neoverse V1 platform, Arm set the bar even higher by delivering the highest performance from any Arm-designed core, achieved through a radical re-design of the CPU micro-architecture using wider and deeper pipelines and a 2x256 bit wide vector unit executing Scalable Vector Extension (SVE) instructions with support for the new bfloat16 data type for AI/ML-assisted workloads.
We now have the pleasure of revealing the Arm Neoverse V2 platform, detailed at the HotChips 2023 conference, delivering double-digit gains on cloud Infrastructure workloads and triple-digit gains for ML and HPC workloads over the Neoverse V1 platform. Neoverse V2 platform builds on top of the capabilities of existing Neoverse platforms delivering maximum performance per TCO$ while enabling multi-chiplet/socket solutions with DDR5/HBM3 memory, PCIe5 IO and CXL2.0-attached memory or coherent accelerators.
What’s new in the Neoverse V2 Platform?
The Neoverse V2 Platform brings significant improvements to the overall Neoverse compute architecture, with singular focus on improving performance while ensuring that the micro-architecture changes do not incur a disproportionately high cost of power and area. Let’s highlights some of the new capabilities that are introduced with the Neoverse V2 Platform.
Neoverse V2 Core
Neoverse V2 platform comprises the latest infrastructure-focused Neoverse V2 CPU cores, implementing new capabilities of the Armv9 Architecture. The following figure touches on some of the specific updates on the different layers of the core.
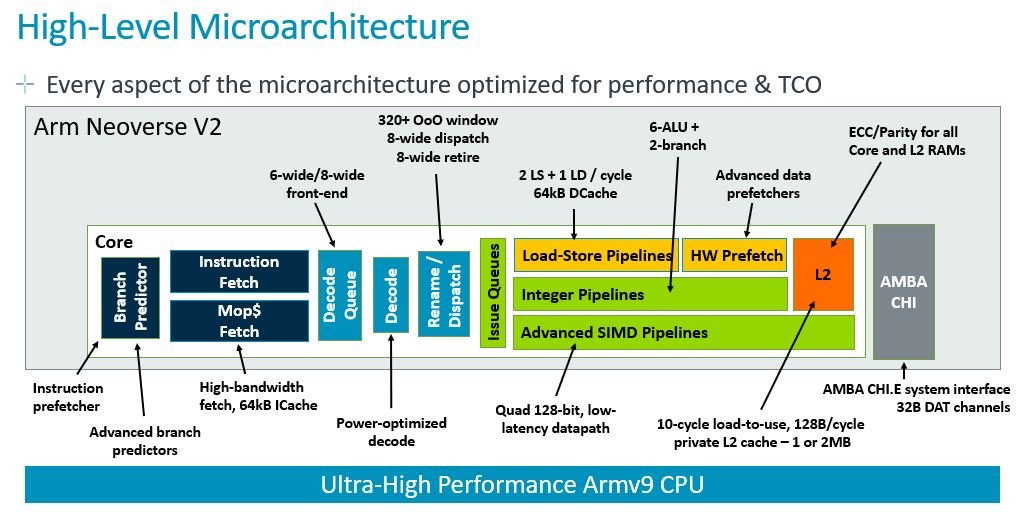
Every stage of the CPU core pipeline from prefetcher, branch prediction, dispatcher, cache etc. has been architected to deliver a streamlined and predictable performance per TCO$ improvement on some of the most frequently used applications running in the datacenter. For example, compared to V1, 10x larger branch target buffers, 2x larger TAGE tables, 2x instruction TLB/cache bandwidth, 2x fetch queue size are all implemented in the branch predict/fetch/iCache blocks which, along with other changes has resulted in a 13% increase in SPECspeed 2017 integer performance, and a 10.5% reduction in system-level cache misses.
Scalable Vector Extension 2 (SVE2)
The main goal for SVE2 is to enable maximum flexibility for specialized compute. SVE2 brings SVE and Neon under the same umbrella, added 4x128 option while delivering the key value proposition across Machine learning, Multimedia Applications, Cryptography, Data Compression and Decompression use cases.
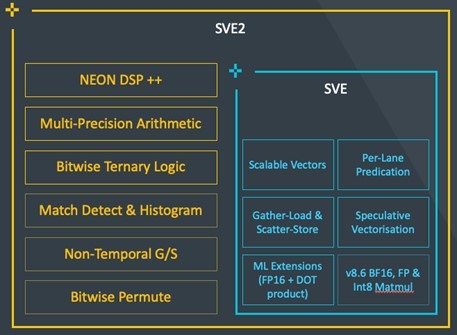
Additional details on SVE2 can be found here.
Memory Tagging (MTE) Extension
Memory safety issues in software have traditionally been the largest source of security vulnerabilities. For infrastructure products, security vulnerabilities can have significant negative impact on operational and financial metrics affecting brand reputation. Although software mitigation techniques exist, the performance impact on server workloads prevents their widespread deployment. Memory Tagging Extension (MTE) addresses these challenges, bringing performant and scalable solutions that prevent both spatial and temporal memory safety violations targeted by malicious code. MTE can locate memory safety issues both before and after deployment at scale. And it helps developers find hard-to-catch memory safety errors through very low overhead and accurate reporting, reducing the attack surface in large scale deployments.
MTE operates as a two-phase system, known as the ‘lock’ and the ‘key’. If the key matches, then the lock memory access is permitted; otherwise, access can be recorded or faulted. The lock and key phases comprise of address and memory tagging. Address tagging acts as the key adding four bits to the top of every pointer used in the execution thread. Memory tagging functions as the lock. It also consists of four bits, linked with every aligned 16-byte region in the application’s memory space. Arm refers to these 16-byte regions as tag granules. These four bits are not used for application data and are stored separately. If you are interested, you can find detail information about MTE here.
Optimization for Workload Performance and Power
Various improvements have been made on workload performance both at the CPU core and the platform level. For example, provisioning for larger L2 and system-level cache (SLC) sizes coupled with various microarchitectural pipeline improvements has resulted in significant performance improvements over previous generations for multiple real-world workloads have seen significant performance improvement. Case in point, XGBoost, which is a leading machine learning library of algorithms for regression, classification, and ranking problems, demonstrates greater than 2X performance improvements over Neoverse V1 when run on a similarly configured (Core count, Frequency, memory bandwidth and standard compiler options) Neoverse V2 system.
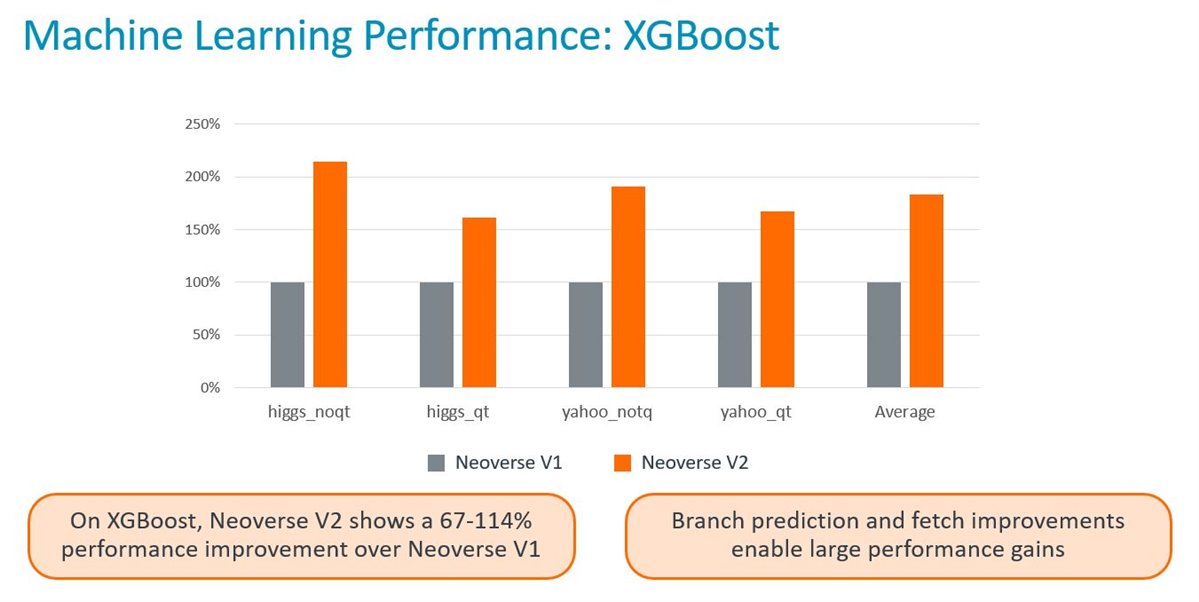
Additionally, specialized micro-architectural power optimization techniques – collectively referred to as Performance Defined Power (PDP) - have been implemented that programmatically allow CPU cores to trade off a small performance loss for significant savings in dynamic power. This is very useful in saving system power while running workloads where the highest performance is not required or workloads where there’s considerable latency waiting for external memory/IO data.
Existing power management technologies seen in previous generation Neoverse cores, such as Dynamic Voltage-Frequency Scaling (DVFS), Max power Mitigation (MPMM), Activity Monitoring (AMU), and Dispatch Throttling (DT) are also incorporated in V2 platform to maximize opportunities to optimize power while continuing to deliver needed performance.
Neoverse V2 Platform Enablement
The performance and scalability of the Neoverse V2 CPU is complemented by CMN-700, MMU-700, GIC-700, DDR5/HBM2e/HBM3 memory controllers, IO controllers, CXL 2.0 bridges to external memory and a host of other ARM and 3rd party designed IP.
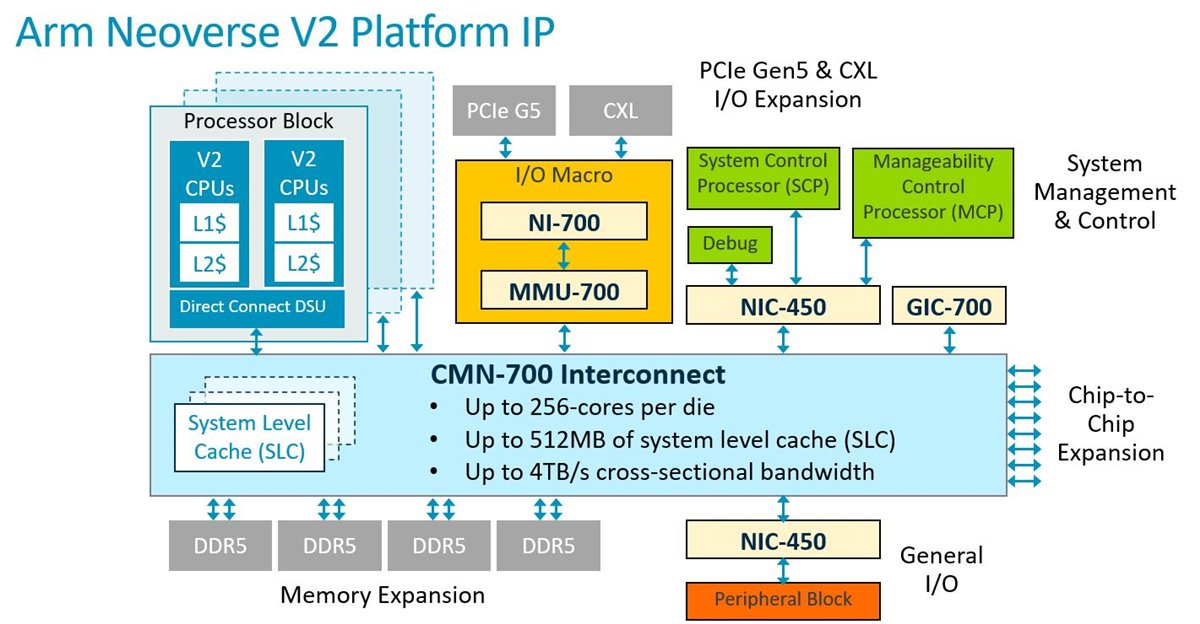
To assist our partners, for rapid design and time to market, Arm is also delivering a pre-validated Reference Design.
Conclusion
The Neoverse V2 platform is designed to deliver leadership performance on cloud computing workloads, at the lowest TCO$. It also represents a significant step forward in performance leadership on AI/ML and HPC workloads with immediate availability through our partner NVIDIA with their Grace CPU Superchip and Grace-Hopper Superchip line of CPUs. The NVIDIA Grace CPU integrates the Neoverse V2 core with the NVIDIA Scalable Coherency Fabric for high-bandwidth data movement and the first data center LPDDR5X memory to deliver 2X the performance per W of leading data center CPUs. Their platforms have recently been certified as SystemReady SR.
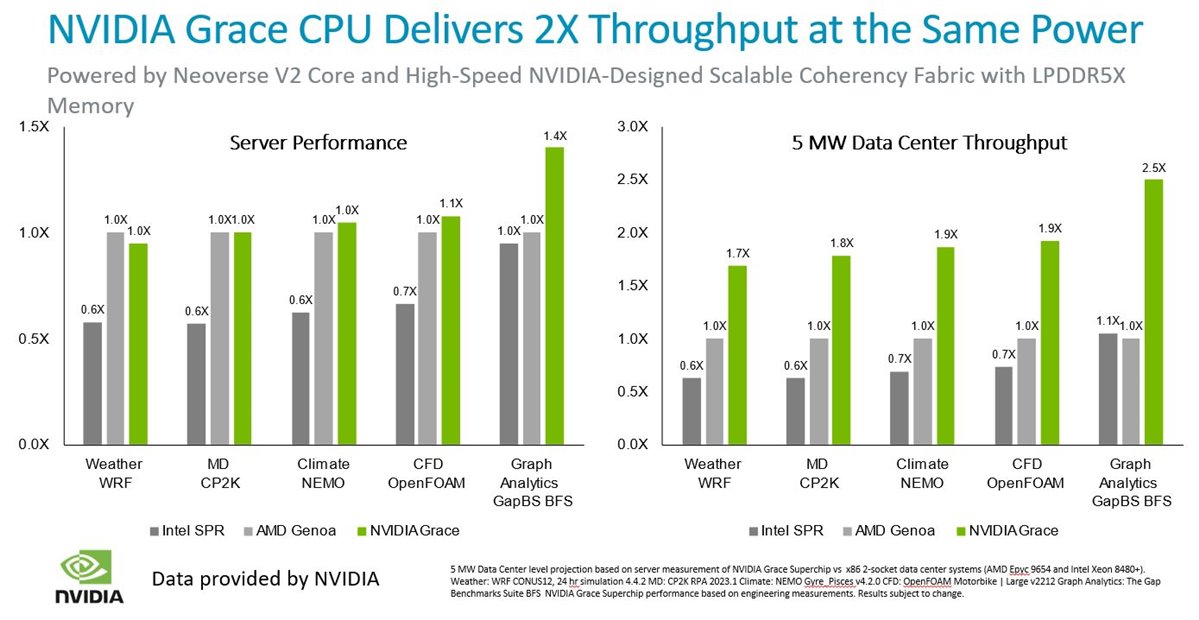
Additional partner silicon announcements using the Neoverse V2 platform are expected in the near future.
If you would like more information about Neoverse V2 and the V2 RD refer to the Neoverse Reference Design page and Neoverse V2 developer page.
Reference
Performance and benchmark disclaimer
- This benchmark presentation made by Arm Ltd and its subsidiaries (Arm) contains forward-looking statements and information. The information contained herein is therefore provided by Arm on an "as-is" basis without warranty or liability of any kind. While Arm has made every attempt to ensure that the information contained in the benchmark presentation is accurate and reliable at the time of its publication, it cannot accept responsibility for any errors, omissions or inaccuracies or for the results obtained from the use of such information and should be used for guidance purposes only and is not intended to replace discussions with a duly appointed representative of Arm. Any results or comparisons shown are for general information purposes only and any particular data or analysis should not be interpreted as demonstrating a cause and effect relationship. Comparable performance on any performance indicator does not guarantee comparable performance on any other performance indicator.
- Any forward-looking statements involve known and unknown risks, uncertainties and other factors which may cause Arm’s stated results and performance to be materially different from any future results or performance expressed or implied by the forward-looking statements.
- Arm does not undertake any obligation to revise or update any forward-looking statements to reflect any event or circumstance that may arise after the date of this benchmark presentation and Arm reserves the right to revise our product offerings at any time for any reason without notice.
- Any third-party statements included in the presentation are not made by Arm, but instead by such third parties themselves and Arm does not have any responsibility in connection therewith.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK