

用大白话聊聊向量数据库 - 更多 - dbaplus社群:围绕Data、Blockchain、AiOps的企业级...
source link: https://dbaplus.cn/news-160-5521-1.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
用大白话聊聊向量数据库
可能你之前已经听说过它们了,但直到现在才真正关心它们——至少,我猜你阅读本篇文章就是这个原因。
如果你只是想要简单的答案,那继续阅读吧。
向量数据库是一种存储和管理非结构化数据(如文本、图像或音频)的数据库,它使用向量嵌入(高维向量)来快速查找和检索相似的对象。
如果这个定义让你更加困惑,别着急,我会从三个不同的难度来逐步解释。
一、五岁儿童解释向量数据库
这有点离题了,但你知道我不明白什么吗?
当人们按颜色整理书架时。—— 我的天呐!
当他们不知道书的封面是什么颜色时,他们怎么找书呢?

如果你想快速找到一本特定的书,按照类型和作者来整理书架比按照颜色来整理要更有意义。这就是为什么大多数图书馆都以这种方式整理书籍,以帮助你快速找到你要找的书。
但是,如果你想根据查询而不是类型或作者来找到一本书,该怎么办呢?比如,如果你想找一本和《饥饿的毛虫》相似的书,或者一本关于一个和你一样喜欢吃东西的主角的书,怎么办呢?
如果你没有时间在书架上浏览,最快的方法就是向图书管理员寻求推荐,因为他们读过很多书,会准确地知道哪本书最符合你的要求。
在整理书籍的例子中,你可以将图书管理员看作是一个向量数据库,因为向量数据库被设计用于存储关于对象(比如一本书)的复杂信息(比如书的情节)。因此,向量数据库可以帮助你根据特定的查询(比如一本关于…… 的书)而不是几个预定义的属性(比如作者)来找到对象,就像图书管理员一样。
二、向数字原住民和技术爱好者解释向量数据库
现在,让我们继续使用图书馆的例子,稍微深入一点到技术层面。当然,如今有更先进的技术可以在图书馆中搜索一本书,而不仅仅是按照类型或作者。
如果你去图书馆,通常角落里会有一台电脑,它可以帮助你通过一些更具体的属性来找到一本书,比如书名、ISBN、出版年份或一些关键词。根据你输入的关键词,会查询一个可用书籍的数据库。这个数据库通常是传统的关系型数据库。

关系型数据库和向量数据库之间的区别是什么?
关系型数据库和向量数据库的主要区别在于它们存储的数据类型。关系型数据库设计用于存储适应表格形式的结构化数据,而向量数据库则适用于非结构化数据,例如文本或图像。
存储的数据类型也影响着数据的检索方式:在关系型数据库中,查询结果基于对特定关键词的匹配。而在向量数据库中,查询结果基于相似性。
你可以将传统的关系型数据库想象成电子表格。它们非常适合存储结构化数据,例如关于一本书的基本信息(例如书名、作者、ISBN 等),因为这些信息可以存储在列中,并且非常适合进行筛选和排序。
使用关系型数据库,你可以快速获取所有书名中包含 “毛毛虫” 一词的儿童书籍。
但是,如果你喜欢的这本《饥饿的毛虫》是关于食物的书籍呢?你可以尝试搜索关键词 “食物”,但是除非书籍摘要中提到了关键词 “食物”,否则你无法找到《饥饿的毛虫》。相反,你可能会得到一堆关于烹饪的书籍和失望。
这就是关系型数据库的一个限制:你必须添加所有你认为可能需要的信息来找到特定物品。但是你如何知道要添加哪些信息以及添加多少信息呢?添加所有这些信息耗时且不能保证完整性。
现在,向量数据库就登场了!
首先,我们先要介绍一下一个叫做向量嵌入的概念。
现在的机器学习(ML)算法可以将给定的对象(例如单词或文本)转换为保留该对象信息的数值表示。想象一下,你给一个 ML 模型一个单词(例如 “食物”),然后这个 ML 模型进行一些神奇的操作,然后返回给你一个长长的数字列表。这个长长的数字列表就是你的单词的数值表示,被称为向量嵌入。
因为这些嵌入是一长串数字,所以我们称它们为高维的。现在假设这些嵌入只有三维,以便更好地进行可视化,如下所示。
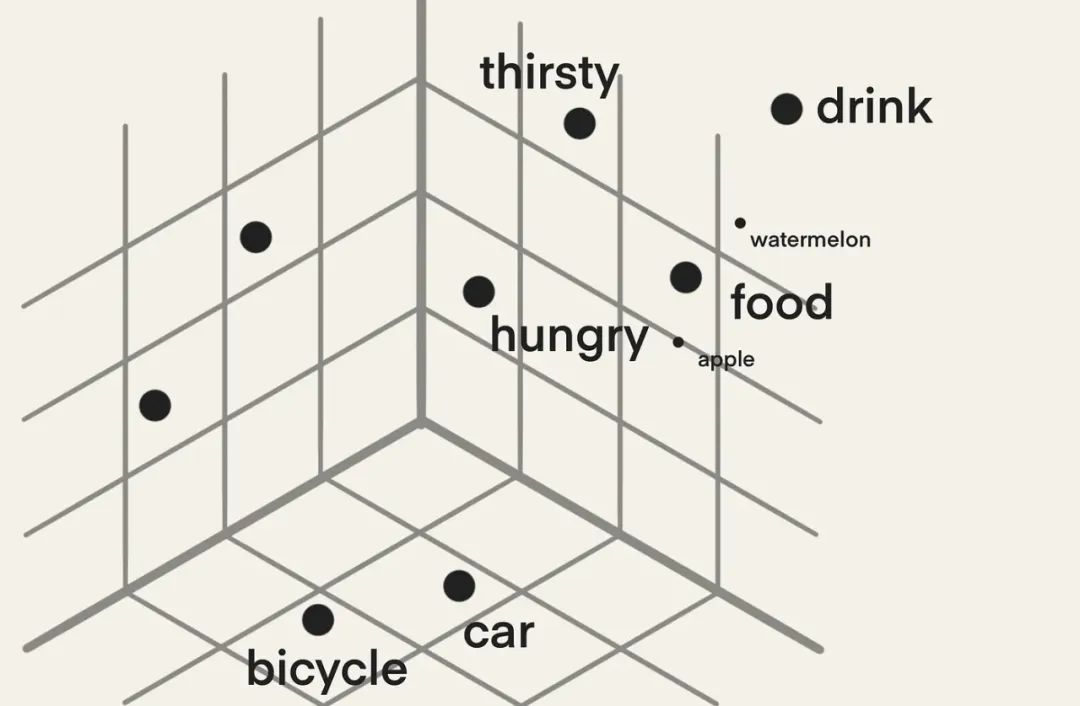
你可以看到,类似的词如 “饥饿”、“口渴”、“食物” 和 “饮料” 都聚集在相似的角落,而其他词如 “自行车” 和 “汽车” 虽然彼此接近,但位于向量空间的不同角落。
这些数值表示使我们能够对对象(例如单词)应用数学计算,而这些对象通常不适合进行计算。例如,除非你用它们的嵌入替换单词,否则以下计算是无法进行的:
drink - food + hungry = thirsty由于我们能够使用嵌入进行计算,我们还可以计算嵌入对象之间的距离。两个嵌入对象越接近,它们就越相似。
正如你所看到的,向量嵌入非常强大。
让我们回到我们的例子,并假设我们将图书馆中每本书的内容进行嵌入,并将这些 Embedding 存储在向量数据库中。现在,当你想要找一本 “儿童书中的主角喜欢食物” 的书时,你的查询也被嵌入,并且返回与你的查询最相似的书,比如《饥饿的毛虫》或者《金发姑娘和三只熊》。
向量数据库的使用案例有哪些?
向量数据库在大语言模型(LLM)引起关注之前就已经存在了。最初,它们用于推荐系统,因为它们可以快速找到与给定查询相似的对象。但是由于它们能够为 LLM 提供长期记忆,最近它们也被用于问答应用中。
三、向工程师和数据专业人士解释向量数据库
如果你在打开本文之前就猜到向量数据库可能是一种存储向量嵌入的方式,并且只想知道向量嵌入的底层原理,那么让我们深入探讨一些技术细节,并讨论算法。
向量数据库是如何工作的?
向量数据库能够快速检索与查询相似的对象,是因为它们已经预先计算了这些相似度。其中的基本概念称为近似最近邻(ANN)搜索,它使用不同的算法进行索引和相似度计算。
当你拥有数百万个嵌入时,使用简单的 K 近邻(kNN)算法计算查询与你拥有的每个嵌入对象之间的相似度会变得耗时。通过使用近似最近邻搜索,你可以在一定程度上牺牲一些准确性以换取速度,并检索出与查询近似最相似的对象。
索引 - 为此,向量数据库对向量嵌入进行索引。这一步将向量映射到一种数据结构中,以实现更快的搜索。
你可以将索引视为将图书馆中的书籍按照不同的类别进行分组,例如按照作者或类型。但是由于嵌入可以包含更复杂的信息,进一步的分类可能包括 “主角的性别” 或 “情节的主要地点”。索引可以帮助你检索出所有可用向量的一小部分,从而加快检索速度。
我们不会深入讨论索引算法的技术细节,但如果你有兴趣进一步了解,可以开始查阅关于 “Hierarchical Navigable Small World(HNSW)” 的资料。
相似度度量 - 为了从索引向量中找到与查询最接近的邻居,向量数据库应用相似度度量。常见的相似度度量包括余弦相似度、点积、欧几里德距离、曼哈顿距离和汉明距离。
向量数据库相对于将向量嵌入存储在 NumPy 数组中的优势是什么?
我经常(已经)遇到的一个问题是:我们不能只使用 NumPy 数组来存储嵌入吗?当然,如果你的 Embedding 数量不多,或者只是进行一些有趣的业余项目,你当然可以使用 NumPy 数组。但是如你所料,当你有大量 Embedding 时,向量数据库的速度明显更快,并且你不必将所有内容都保存在内存中。
作者丨张伟 来源丨公众号:分布式实验室(ID:DistributedLab) dbaplus社群欢迎广大技术人员投稿,投稿邮箱:[email protected]Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK