

论文解读(WIND)《WIND: Weighting Instances Differentially for Model-Agnostic Do...
source link: https://www.cnblogs.com/BlairGrowing/p/17584262.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

论文解读(WIND)《WIND: Weighting Instances Differentially for Model-Agnostic Domain Adaptation》
Note:[ wechat:Y466551 | 可加勿骚扰,付费咨询 ]
论文标题:WIND: Weighting Instances Differentially for Model-Agnostic Domain Adaptation
论文作者:
论文来源:2021 ACL
论文地址:download
论文代码:download
视屏讲解:click
出发点:传统的实例加权方法由于不能学习权重,从而不能使模型在目标领域能够很好地泛化;
方法:为了解决这个问题,在元学习的启发下,将领域自适应问题表述为一个双层优化问题,并提出了一种新的可微模型无关的实例加权算法。提出的方法可以自动学习实例的权重,而不是使用手动设计的权重度量。为了降低计算复杂度,在训练过程中采用了二阶逼近技术;
-
- 提出了一种新的可微实例加权算法,该算法学习梯度下降实例的权重,不需要手动设计加权度量;
- 采用了一种二阶近似技术来加速模型的训练;
- 对三个典型的NLP任务进行了实验:情绪分类、机器翻译和关系提取。实验结果证明了该方法的有效性;
事实:把域外、域内数据联合训练做领域适应,但并不是所有来自域外数据集的样本在训练过程中都具有相同的效果。一些关于神经机器翻译(NMT)任务的研究表明,与域内数据相关的域外实例是有益的,而与域内数据无关的实例甚至可能对翻译质量有害 。
目前的实列加权方法:
-
- 核心思想:根据实例的重要性以及与目标域的相似性来加权实例;
- 问题:当前领域适应场景中,域外语料库的规模大于域内语料库,容易导致学习到的权值偏向于域外数据,导致域内数据的性能较差;
为避免域内数据的性能较差,如何有效地利用 Din 是域转移的关键。为解决这个问题,首先从 Din 中抽取子集 Dit={(xi,yi)}n1i=1,并为每个实例 (xi,yi)∈Dit∪Dout 分配一个标量权值 wi。本文希望在训练过程中,模型能够找到最优的权重 w=(w1,…,wn1+m),因此,权重 w 是可微的,并可通过梯度下降优化。此外,将 DNN 表示为由 θ 参数化的函数 fθ:X→Y,并将 xi 从输入空间映射到标签空间。
最终训练损失遵循一个加权和公式:
Ltrain (θ,w)=1n1+m∑(xi,yi)∈Dit∪Dout wiℓ(fθ(xi),yi)
其中 ℓ 表示损失函数,可以是任何类型的损失,如分类任务的交叉熵损失,或标签平滑交叉熵损失。
由于域内和域外数据集的数据分布存在差异,简单联合优化 θ 和 w 可能会对 w 引入偏差。本文期望在 w 上训练的模型可以推广到域内数据。受 MAML 的启发,本文建议从 Din 中采样另一个子集 Dq={(xi,yi)}n2i=1 命名为查询集,使用这个查询集来优化 w。具体来说,目标是得到一个权重向量 w 减少 Dq 上的损失:
Lq(θ)=1n2∑(xi,yi)∈Dqℓ(fθ(xi),yi)
总结:随机初始化 w,用 Ltrain (θ,w) 训练一个模型,得到优化后的参数 θ∗,接着固定 θ∗ ,最小化在查询集上的损失,得到新的 w。
该过程表述为以下双层优化问题:
minwLq(θ∗) s.t. θ∗=argminθLtrain (θ,w)
上述双层优化问题由于求解复杂性高,难以直接解决。受 MAML 中的优化技术启发,将每次迭代的训练过程分为以下三个步骤:
ˆθ=θ−β⋅∇θLtrain (θ,w)
- 实例权重更新
w∗=argminwLq(ˆθ)=argminwLq(θ−β⋅∇θLtrain (θ,w))
ˆw=w−γ⋅∇wLq(ˆθ)
θ←θ−β⋅∇θLtrain (θ,ˆw)
对 ∇wLq(ˆθ) 使用链式法则:
ˆw=w−γ⋅∇wLq(ˆθ)=w−γ⋅∇ˆθLq⋅∇wˆθ=w+βγ⋅∇ˆθLq⋅∇2θ,wLtrain
问题:使用 |θ|,|w| 分别表示 θ,w 的维数,二阶推导 ∇2θ,wLtrain 是一个 |θ|×|w| 矩阵,无法计算和存储。幸运的是,可采用 DARTS 中使用的近似技术来解决这个问题,这种技术使用了有限差分近似:
∇ˆθLq⋅∇2θ,wLtrain ≈∇wLtrain (θ+,w)−∇wLtrain (θ−,w)2ϵθ+=θ+ϵ∇ˆθLqθ−=θ−ϵ∇ˆθLq

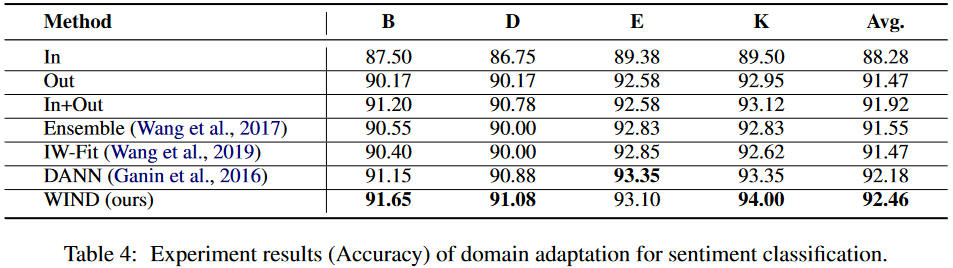
4 实验结果
__EOF__
Recommend
-
140
teletype-client The editor-agnostic library managing the interaction with other clients to support peer-to-peer collaborative editing in Teletype for Atom. Ha...
-
22
About the speaker Chang Liu is an Applied Research Scientist and a member of the Georgian Impact team. She brings her in-depth knowledge of mathematical and combinatorial optimization to helping Georgian’s port...
-
12
MarketsTesla shares fall 6% as it enters the S&P 500 with 1.69% weighting, fifth largestPublished Sun, Dec 20 20203:43 PM ESTUpdated Mon, Dec...
-
5
A comparison of different weighting schemes for ranking sports teams 0 A previ...
-
7
[Submitted on 28 Apr 2016] Two Differentially Private Rating Collection Mechanisms for Recommender Systems Wenji...
-
3
Creating dynamic EMF model from XSDs and loading its instances from XML as SDOs January 3, 2011 This post describes how to read...
-
5
Machine Learning: Oversampling vs Sample Weighting How do you “influence” a ML model? For example, imagine a scenario where you’d like to detect anomalies in a given data set. You reach for your favourite algorithm –...
-
2
Apple rules the S&P 500 with highest weighting for any company...
-
5
[Submitted on 30 Mar 2022] Differentially Private All-Pairs Shortest Path Distances: Improved Algorithms and Lower Bounds
-
8
Computer Science > Machine Learning [Submitted on 9 Nov 2022] Almost Tight Error Bounds on Differen...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK