

AWS Data Tools
source link: https://wilsonmar.github.io/aws-data-tools/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

AWS data processing tools: Databases, Big Data, Data Warehouse, Data Lakehouse
Here are my notes reflecting what I’ve figured out so far about how developers and administrators can process data in the AWS cloud. I’m trying to present this in a logical sequence. But there are a lot of products that seem to do the same thing.
NOTE: Content here are my personal opinions, and not intended to represent any employer (past or present). “PROTIP:” here highlight information I haven’t seen elsewhere on the internet because it is hard-won, little-know but significant facts based on my personal research and experience.
Competition in Cloud Databases
In 2022 Gartner named AWS (Amazon Web Service), among all other cloud database vendors, the one with the best ability to execute and completeness of vision:
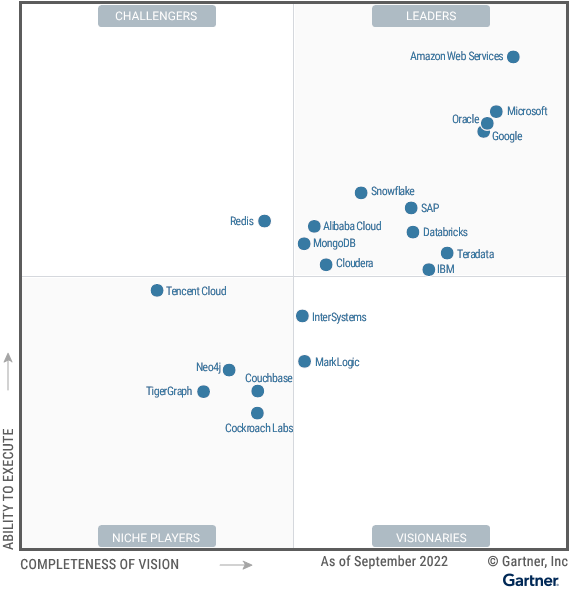
Some may argue that Snowflake and Databricks for their “Delta Lake” (using Parquet-structured data) removes the separation between OLTP and OLAP is now leading the field. Also see my notes on:
QUESTION: Where is Amazon on the transition from ELT to ETL to Streaming and from Schema on write to Schema on Read?
Below is an alphabetical list of third-party databases cloud customers can install in AWS like (some like they used to do on-prem):
- Cassandra
- Cockroach Labs
- Cloudera
- Couchbase (No-SQL)
- InterSystems
- MarkLogic
- MariaDB
- MySQL
- MongoDB (No-SQL)
- Neo4j (graph database)
- Oracle
- PostgreSQL
- Redis
- SAP HANA
- SQL Server
- Teradata
- TigerGraph
(Listed separately are China-based offering)
Data Lifecycle
The data analytics lifecycle:
- Define
- Interpret
- Clean and Transform
- Enhance
- Analyze
- Visualize
Categories of tools
One AWS certification conceptually organizes data tools in these categories:
Data Collection
-
AWS Kinesis 4 capabilities, namely: Video Streams, Data Streams, Firehose, Data Analytics. Data API and Streams do not require a VPC to be setup to accept SQL commands. Integrates with EventBridge. Max 24 hr duration, 100 KB query size, 100 MB query result size. Auth using AWS Secretes Manager. FAQs. Commands: describe-statement, execute-statement, get-statement-result. troubleshooting and scenario-based questions, like how would you solve a ProvisionedThroughPutExceeded error, when should you merge or split shard, what encryption options are available, and how the Kinesis service integrates with other services.
- Database Migration Service (DMS)
- Simple Queue Service (SQS)
- Snowball
- AWS Internet of Things (IOT)
- AWS Direct Connect
Storage and Data Management:
- Simple Storage Service (S3)
- DynamoDB (cloud document database)
- Amazon Elasticsearch Service
Processing
- AWS Lambda
- AWS Glue - serverless bookmarks, DynamicFrame functions, job metrics, and etc. Troubleshooting Glue Jobs: what should you do if Glue throws an error.
- Amazon EMR
-
Elastic MapReduce, including Apache Spark, Hive, HBase, Presto, Zeppelin, Splunk, and Flume
- AWS Lake Formation
- AWS Step Functions for orchestrations
- AWS Data Pipeline
Analysis
- Amazon Kinesis Data Analytics
- Amazon ElasticSearch Service - Generally for log analysis, look for an ES solution along with Kibana
- Amazon Athena
- Amazon Redshift and Redshift Spectrum
-
Amazon SageMaker for Machine Learning & AI
- AWS TensorFlow
- AWS Cognito
Visualization/Analytics:
- Quicksight
-
Other Visualization Tools (not a managed service): Salesforce Tableau, D3.js, HighCharts, and a custom chart as a solution,
- Relational Database Service (RDS) and Aurora
Security:
- Cloud HSM (Hardware Security Module)
- STS (Security Token Service)
- Amazon Inspector
Evolution in AWS Data Tools
Amazon’s new official “flat” icons are used here to illustrate AWS cloud technologies evolving from “Lift and Shift” to Serverless to Low-Code to Machine Learning.

Click the video above for the step-by-step commentary below, with links to additional commentary:
-
The first generation of Amazon’s capabilities in the cloud was to enable EC2 (Elastic Compute Cloud) Virtual Machines to run applications in the cloud within images containing full operating systems.
-
When the world began processing “Big Data” for “Business Intelligence” in the AWS cloud, they manually setup and tuned individual EC2 servers running Apache Spark accessing data stored in
-
S3 (Simple Storage Service) objects. S3 cloud storage has been available since Amazon Web Services first appeared.
-
creates cryptographic keys to encrypt and decrypts objects stored in S3. It is used by AWS Secrets Manager, which automates the rotation and retrieval of credentials, API keys, and other secrets.
-
From the perspective of Data Analysts who use the AWS QuickSight visualization tool. Tableau (from Salesforce) offers a competing solution with fancier graphics.
For an additional monthly cost, rather than using a direct SQL query, data can be optionally be imported into a dataset that uses SPICE (Super-fast, Parallel, In-memory Calculation Engine) allocated for use by all users within each region to rapidly perform advanced calculations and serve data. Internally, SPICE uses columnar in-memory storage.
-
QuickSight can access more data sources than shown on this diagram, such as text from GitHub, Twitter, and other APIs.

-
QuickSight can reach those legacy data warehouses. In fact, QuickSight can create visualizations directly from many different sources.
-
Earlier, applications were programmed in the Java programming language which uses JDBC/ODBC protocols to interact with Relational database software Oracle and Microsoft SQL popular in enterprise data centers at the time.
-
 Over time, AWS enabled various programs in AWS Lambda (serverless) functions are able to reach databases using ODBC and other protocols. This enables dynamic triggers to send messages and perhaps update databases.
Over time, AWS enabled various programs in AWS Lambda (serverless) functions are able to reach databases using ODBC and other protocols. This enables dynamic triggers to send messages and perhaps update databases.The earliest approach to bring SQL to the cloud is what’s called “lift and Shift” of database operations.
However, direct connections with databases from the public internet pose a vulnerability.
-
Amazon RDS (Relational Database Service) is a web service that makes it easier to set up, operate, and scale a relational database in the AWS Cloud, easier than if they were on-prem. But with RDS, AWS takes care of the hardware and operating system patching across several regions. But customer admins still upgrade database software.
-
Amazon Aurora brings to RDS SQL query compatibility with open-source relational database software MySQL and PostgreSQL. Conceptually, Aurora is a database engines within RDS. However, it operates differently than other RDS engines.
In RDS, applications reference the CNAME of each database within RDS. RDS takes care of replication to a single secondary replica in the same region. But only the primary instance is updated. When RDS detects a need for failover, this multi-az instance approach switches DNS, which can take several minutes.
The multi-az cluster approach replicates to two replicas. Replicas can be readers, to relieve such loads.
Aurora users can replicate to more than two replicas. Replicas can be read by a separate reader endpoint. Aurora’s Backtrack features allow in-place rewind to a previous point in time.
Unlike RDS local storage, Aurora uses cluster volumes that are shared. Aurora can detect SSD disk failures and repairs them. Replication occurs at the storage level. (Storage billed based on the “high watermark” level is being phased out).
-
has a GUI that looks like RDS, but is serverless, fully managed implementation of open-source graph database software. Since May 30, 2018, it runs with continuous backups to S3 within a VPC that’s private by default. It’s a for highly connected datasets where relationships between elements are as important as the data. Graph databases provide flexibility to address the most complex of data relationships – used for mapping knowledge graphs, social networking, recommendations, fraud detection, life sciences, and network/IT operations. Neptune supports popular open-source W3C RDF (Resource Description Framework) and query languages Apache TinkerPop’s Gremlin, openCypher, and SPARQL (but not licensed Neo4j).
-
AWS DynamoDB is a key-value store. It’s used for workloads such as session stores or shopping carts, taking place of MongoDB, Couchbase, and other document DBs in the AWS-managed cloud. Unlike SQL, DynamoDB has limited queries and doesn’t have joins. Amazon also offers Firestore DocumentDB to get around MongoDB open-source licensing.
DynamoDB adds replication (streams) of table activity across geographic regions. Within each region, it provides fault tolerance in automatic synchronous replication across 3 data centers. Being a cloud service, it automatically allocates storage in partitions and imposes no limit to data storage.
-
Instead of reaching DynamoDB directly, AWS has created DAX (DynamoDB Accelerator) agents installed on client servers to reach an in-memory cache in front of DynamoDB, like Redis.
-
is used to create a “data lake” of petbyte scale data warehouse for OLAP (Analytical Processing). OLAP uses columnar data structures such as “star schema” to hold summarized data in more rigid structure than OLTP.
RedShift’s “Federal Query” means it can join with data from S3 objects and other foreign data in queries. But one has to configure and launch underlying compute infrastructure since RedShift is not serverless and requires servers to be provisioned plus enhanced VPC.
Redshift Spectrum means that it can query from S3 without loading data.
Incremental encrypted backups are automatic into S3 with every 8 hours, with retention for 1-35 days.
-
is an AWS-managed SaaS offering. Athena’s console GUI offers a simplified Jupyter Python Notebook developer experience that supports ODBC/JDBC drivers (like Amazon DynamoDB) as well as REST API calls.
What’s new about Athena is that its Apache Spark Presto data structures are stored into S3 without setting up EC2 servers (unlike Redshift and EMR). So Athena users only pay for data scanned ($5 per terabyte in most regions).
-
Also, Athena can access the results of traditional EMR (Elastic MapReduce) jobs stored in S3 buckets. So Athena can benefit from EMR’s direct, lower-level access to Spark Hadoop internals. For example: Data scientists can use EMR to run machine learning TensorFlow jobs. Analysts can run SQL queries on Presto. Engineers can utilise EMR’s integration with streaming applications such as Kinesis or Spark…
Amazon EMR serverless was released in November 2021 for petabyte-scale analytics processing.
EMR costs around $14-16 per day while AWS Glue costs around $21 per day. Although EMR requires customer operations attention to setup and scale versus Glue’s serverless platform, EMR provides quicker start times. EMR has a wider range of server sizes.
Streams
To build real-time data pipelines for receiving streams of data (such as logs, there is a open-source Apache Kafka.
But AWS has several additional technologies to make the creation and absorption of data streams easier and cheaper.
-
<a target=”_blank” href=”https://docs.aws.amazon.com/msk/latest/developerguide/what-is-msk.html><img align=”right” width=”100” src=”https://res.cloudinary.com/dcajqrroq/image/upload/v1692390286/aws-icons/Amazon-Timestream.png>Amazon MSK (Managed Stream for Kafka)</a> is a serverless web app that runs rgw Kafka cache server.
-
AWS Glue is a serverless data integration service that makes it easy to discover properties (schema), transform, prepare, and combine data for analytics, app and API development, and machine learning. Glue creates a centralized Data Catalog that forms the basis to visually create, run, and monitor pipelines for several workloads and types.
-
Some Athena users have migrated from EMR to Glue for ETL processing because Athena can also access AWS Glue Catalogs also stored in a serverless architecture.
ETL vs ELT
ETL (Extract, Transform, Load) is the traditional approach to arranging data for storage and analytics. This approach emerged at a time when disk space was more expensive and took time to obtain. So the “Transform” part meant stripping out data not of immediate interest.
ELT (Extract, Load, Transform) is a more modern approach that uses more storage because data is stored in an unredacted form for transformation later. This enables retrospect analysis of attributes not considered previously.
-
Glue Crawler …
-
Glue ETL Jobs
-
Amazon Kinesis Data Firehose is a serverless (AWS-managed) service to deliver (in near real-time) continuous streams of data (including video) to S3 buckets, other Amazon services, or any other HTTP endpoint destination (with or without transformation before send). “Low-code” Blueprints can be specified in Lambda to do some transformations on the fly.
-
Amazon Kinesis
 Kinesis Data Streams is a web service to collect, process, and analyze – in real-time – continuous streams of audio, video (and other data) from video cameras and social media platforms. This is done for fraud detection, trademark enforcement, customer engagement, and other monitoring.
Kinesis Data Streams is a web service to collect, process, and analyze – in real-time – continuous streams of audio, video (and other data) from video cameras and social media platforms. This is done for fraud detection, trademark enforcement, customer engagement, and other monitoring.Unlike SQS, Kinisis can store 1 to 365 days of streams from multiple producers. Multiple consumers can read streams at different granularities.
-
Kinesis Data Analytics processes complex SQL commands on behalf of other Kinesis services. It can also reference data from S3 such as player scores for a leaderboard in an e-sports, election, or security app.
-
<img align=”right” width=”100” src=”https://res.cloudinary.com/dcajqrroq/image/upload/v1692390286/aws-icons/Amazon-Timestream.png>Amazon Timestream is a Time Series database designed to store a large amount of sensor data for IoT and DevOps application monitoring. It keeps recent data in memory and automatically moves historical data to a cost-optimized storage tier. It integrates with AWS IoT Core, Amazon Kinesis, Amazon MSK, open-source Telegraf, Amazon QuickSight, SageMaker.
-
As a serverless provider, the Athena web service is always ready to query data. So it is used for infrequent or ad hoc data analysis such as any type of log data exported into S3, such as Application Load Balancer, Amazon CloudWatch app logs, AWS CloudTrail, Amazon CloudFront, etc.
-
Amazon Kinesis
</a>Kinesis Data Streams is a web service to collect, process, and analyze – in real-time – streams of video and other continuous feeds of data being served up by YouTube, Vimeo, Facebook, and other social media platforms. This is done for fraud detection, trademark enforcement, customer engagement, and other monitoring.??? aggregation of data followed by loading the aggregate data into a data warehouse or map-reduce cluster.
-
Kinesis IoT Core provides a GUI to manage telemetry from robots.
-
Kinesis Data Streams is used to process Social Media streams for sentiment and engagement
Kinesis Data Analytics runs standard SQL queries on incoming data stream. Once data is available in a target data source, it kicks off a AWS Glue ETL job to do further transform data and prepare it for additional analytics and reporting.
-
Lake Formation provides a central way to manage with fine-grained permissions to a lot of data across AWS data services.
-
Amazon has investest heavily in its SageMaker ML (Machine Learning) Modeling tool for AI (Artificial Intelligence).
Amazon has leveraged its AI capabilities by embedding Machine Learning skills its its offerings.
-
Macie uses Machine Learning to analyze keywords in the content of data to detect whether critical data is being leaked.
-
Amazon Inspector detects vulnerabilities running in apps running within EC2 servers and in Lambda Functions.
Recap
Individual AWS Data Tools
Among the 200+ services that make up AWS, these cloud have the most with processing data (alphabetically):
Which Query Service?
- https://www.cloudinfonow.com/amazon-athena-vs-amazon-emr-vs-amazon-redshift-vs-amazon-kinesis-vs-amazon-sagemaker-vs-amazon-elasticsearch/
- https://awsvideocatalog.com/analytics/athena/appnext-kinesis-emr-athena-redshift-choosing-the-right-tool-for-your-analytics-jobs-wEOm6aiN4ww/
-
https://medium.com/codex/amazon-redshift-vs-athena-vs-glue-comparison-6ecfb8e92349
- https://www.linkedin.com/pulse/aws-glue-vs-datapipeline-emr-dms-batch-kinesis-what-ramamurthy/
- https://skyvia.com/etl-tools-comparison/aws-glue-vs-aws-data-pipeline
AWS Data Exchange
Amazon Data Exchange provides data products among Amazon’s marketplace to purchase data from various sources “3rd-party” to Amazon. Many datasets are free.
QUESTION: RDS now has compatibility with other databases as well?
https://github.com/terraform-aws-modules/terraform-aws-rds
Aurora
https://github.com/terraform-aws-modules/terraform-aws-rds-aurora
https://github.com/terraform-aws-modules/terraform-aws-s3-bucket
Redshift
![]()
![]() Redshift is an AWS-managed data warehouse, based on open-source PostgreSQL with JDBC & ODBC drivers with SQL.
It’s intended to competed with Oracle.
It’s not for blob data.
Redshift is an AWS-managed data warehouse, based on open-source PostgreSQL with JDBC & ODBC drivers with SQL.
It’s intended to competed with Oracle.
It’s not for blob data.
Redshift is designed for the fastest performance on the most complex BI SQL with multiple joins and subqueries. Amazon Redshift Spectrum is an optional service to query any kind of data (videos) stored in Amazon S3 buckets without first being loaded into the Redshift data warehouse. No additional charge for backup of provisioned storage and no data transfer charge for communication between Amazon S3 and Amazon Redshift.
Redshift uses machine learning and parallel processing of queries of columnar storage on very high performance disk drives. It can also be expensive as it is always running.
Redshift mirros data across a cluster, and automatically detects and replaces any failed node in its cluster. Failed nodes are read-only until replaced. An API is used to change number, type of nodes.
Redshift’s internal components include a leader node and multiple compute nodes that provide parallel data access in the same format as queries. The leader node has a single SQL endpoint. As queries are sent to the SQL endpoint, jobs are started in parallel on the compute nodes by the leader node to execute the query and return the results to the leader node. The leader gives the user results after combining results from all compute nodes.
Port number 5439 is the default port for the Redshift data source
https://github.com/terraform-aws-modules/terraform-aws-redshift
Kinesis
Kinesis, is a real-time data streaming service used for collecting, processing, and analyzing real-time data. It’s not for long-term storage. It’s more suitable for streaming data processing rather than interactive analytics.
- Input KPL, agent, PUT API
- Output KCL
Kinesis Data Streams ingests continuous streams of data (to shards), replicated across three AZs in a Region. It uses a cursor in DynamoDB to restart failed apps at the exact position within the stream where failure occured.
Kinesis Storm Sprout reads from a Kinesis stream into Apache Storm.
Kinesis Data Firehose can be adjusted via API calls for specified data rates (capacity).
Kinesis Data Analytics provisions capacity in Kinesis Processing Units (KPU) for memory and corresponding computing and networking capacity. Kinesis Data Analytics supports two runtime environments: Apache Flink and AWS Glue.
Kinesis Video Streams automatically provisions and elastically scales to millions of devices and scales down when devices are not transmitting.

CloudWatch
Amazon CloudWatch is a web service to monitor and manage various metrics, and configure alarm actions based on data from those metrics.
Amazon CloudWatch Logs is a web service for monitoring and troubleshooting your systems and applications from your existing system, application, and custom log files. You can send your existing log files to CloudWatch Logs and monitor these logs in near-real time.
https://github.com/terraform-aws-modules/terraform-aws-cloudwatch
CloudFront
https://github.com/terraform-aws-modules/terraform-aws-cloudfront
CloudTrail
AWS CloudTrail is a web service that records AWS API calls for your account and delivers log files to you. The recorded information includes the identity of the API caller, the time of the API call, the source IP address of the API caller, the request parameters, and the response elements that the AWS service returns.
![]() Amazon EMR (Elastic Map Reduce) is a PaaS service - setup on a collection of EC2 instances called nodes running
“Big Data” utilities Hadoop, Spark, and Presto running in the AWS cloud.
Amazon EMR (Elastic Map Reduce) is a PaaS service - setup on a collection of EC2 instances called nodes running
“Big Data” utilities Hadoop, Spark, and Presto running in the AWS cloud.
- EMR automates the launch of compute and storage nodes powered by Amazon EC2 instances.
- Each EMR cluster has master, core, and task nodes. Each node is a EC2 (Elastic Compute Cloud) instance.
- Master node manages the cluster, running software components to coordinate the distribution of data and tasks across other nodes for processing.
- Core nodes have software components that run tasks and store data in the Hadoop Distributed File System (HDFS)
- Task node is made up of software components that only run tasks and do not store data in HDFS.
EMR can store data securely using customer encryption keys using an HDFS (Hadoop Distributed File System). EMR secures querying of data stored outside the cluster, such as in relational databases, S3, AWS Fargate K8s. EMR is often used for predictable data analysis tasks, typically on clusters maee available for extended periods of time. But it also supports Reserved Instances and Savings Plans for EC2 clusters and Savings Plans for Fargate, which can help lower cost. Only pay for when cluster is up.
https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-supported-instance-types.html
EMR is a managed Hadoop framework that provides a platform to run big data processing jobs at scale.
- Created in a private subnet within a VPC.
- There’s an EMR-managed Security Group for master, core/task, and manger? cluster in private subeta
- Additional security groups to control network access via NAT serv through a gateway
- Security groups can only be added on create.
-
Rules within a Security Group can be added, edited, and deleted after creation.
- EMR can use ENI to connect directly with EC2, Athena, EMR, Kenesis Firehose, Streams, RedShift, SageMaker, and VPC Endpoints.
- EMR clusters can be configured to use AWS Glue Data Catalog as the metastore for Apache Hive and Apache Spark.
ENI (Elastic Network Interface) connects with other AWS services. ENIs are virtual network interfaces that provide a primary private IP address, one or more secondary private IP addresses, and a MAC address to the nodes.
An S3 Gateway Endpoint is used to provide a secure and private connection between the EMR cluster and the S3 bucket. It allows traffic to flow directly between the EMR cluster and the S3 bucket without leaving the Amazon network
EMR v1.4.0 can use HDFS transparent encryption.
EMRFS on S3 for encryption at rest. Amazon Certificate Manager is used, not AWS Certificate Manager Private Certificate Authority (ACM PCA).
https://github.com/terraform-aws-modules/terraform-aws-emr
AWS Glue
![]() AWS Glue is a serverless data integration service that runs on top of Apache Spark for job scale-out execution
for users of analytics to find, prepare, move from 70+ data sources (SQL, not No-SQL).
AWS Glue is a serverless data integration service that runs on top of Apache Spark for job scale-out execution
for users of analytics to find, prepare, move from 70+ data sources (SQL, not No-SQL).
- Glue bulk imports Hive metastore into Glue Data Catalog
- Glue automatically provides job status to CloudWatch events triggering SNS notifications. With EMR you need to setup CloudWatch.
- Glue doesn’t handle heterogeneous ETL job types (which EMR does).
- Glue doesn’t handle streaming except for Spark Streaming.
For an hourly rate billed by the minute, Glue crawls through data and generates crawler Python code for ETL.
Glue creates a centralized Data Catalog which it can visually create, run, and monitor ETL (extract, transform, and load) and ELT pipelines for several workloads and types.
Query cataloged data using Amazon Athena, Amazon EMR, and Amazon Redshift Spectrum.
https://medium.com/@leahtarbuck/the-small-files-problem-in-aws-glue-49f68b6886a0
Johnny Chivers:
DynamoDB
It’s managed via a REST API.Its SELECT operations are like SQL but not exactly.
So it’s for ports of apps from SQL relational databases that have joins.
Use S3 for storing blob data > 400 KB.
DAX (DynamoDB Acellerator) provides a cluster of cloud-based caching nodes that receives DynamoDB traffic through a client added on EC2 servers. Frequently-referenced DynamoDB data are held in-memory within 3-10 nodes to deliver up to a 10 times performance improvement. One of the nodes serves as the primary node for the cluster. Additional nodes (if present) serve as read replicas. All this without requiring developers to manage cache invalidation, data population, or cluster management.
SageMaker
Amazon SageMaker is an AWS-managed service used to build, train, and deploy ML (Machine Learning) models. It has automatic Application Auto Scaling. Billing by the second, broken down by on-demand ML instances, ML storage, and fees for data processing in hosting instances. It has no maintenance windows or scheduled downtimes since its replication configured across three facilities in each AWS region to provide fault tolerance in the event of a server failure or Availability Zone outage.
QuickSight
DOCS Amazon QuickSight</a> is an AWS-managed SaaS interactive visual dashboard for displaying results from BI (Business Intelligence) ad hoc queries, not canned highly-formatted reports.
For an additional monthly cost, rather than using a direct SQL query, data can be optionally be imported into a dataset that uses SPICE (Super-fast, Parallel, In-memory Calculation Engine) allocated for use by all users within each region to rapidly perform advanced calculations and serve data. Internally, SPICE uses a combination of columnar storage in-memory.
QuickSight enable decision-makers to explore and interpret data from a variety of sources.
QuickSight offers these types of visualization:
- KPI values for a single metric of a single area or function (such as Net Promoter Score)
- Distributions of a metric (not over time) such as a scatter chart
- Relationship between two metrics (shown in a scatter chart or bubble chart of 3rd variable)
- Composition of a metric (shown using a pie chart or Tree Map, Stacked Area Chart)
- Comparisons
Each visualization is for a specific database.
Data analysts share Snapshots with others after preserving the configuration of an anlysis session, with that set of filters, parameters, controls, and sort order. Each snapshot reflects the data at the time of capture. Snapshots are not dynamically regenerated.
Enterprise Edition users can embed snapshots in a website. It’s not not like they can instead display a photo of the snapshot, because users can click on data points to drill down.
With QuickSight Enterprise edition, data stored in SPICE is encrypted at rest. Enterprise edition users also get Machine Learning and extra Enterprise security features (granular permissions, federated single-sign-on, row-level security, encryption at rest, on-prem VPC.
PROTIP: Access from QuickSight to Redshift need to be authorized.
AWS Batch
AWS Batch computing processes jobs without manual interaction.
https://github.com/terraform-aws-modules/terraform-aws-batch
AWS Lake Formation
AWS Lake Formation is used to create secure data lakes that centralize fine-grained access by role in AWS Glue ETL Data Catalog databases and tables, using familiar database-like grants for:
- Amazon Athena,
- Amazon Redshift Spectrum
- Amazon EMR for Apache Spark
- AWS Glue ETL
while making metadata available for wide-ranging analytics and machine learning (ML).
AWS Data Exchange to create a data mesh or meet other data sharing needs with no data movement. using services by Lake Formation include:
- Source crawl for content
- ETL and data prep
- Data catalog
QUESTION: Perhaps Lake Formation ensures that KMS (Key Management Service is used appropriate?
https://github.com/terraform-aws-modules/terraform-aws-kms
Secrets Manager
AWS Secrets Manager provides key rotation, audit, and access control.
https://github.com/terraform-aws-modules/terraform-aws-secrets-manager
https://github.com/terraform-aws-modules/terraform-aws-ec2-instance
Lambda
https://github.com/terraform-aws-modules/terraform-aws-lambda
EventBridge
https://github.com/terraform-aws-modules/terraform-aws-eventbridge
https://github.com/terraform-aws-modules/terraform-aws-eks
DMS (Database Migration Service)
https://github.com/terraform-aws-modules/terraform-aws-dms
AWS data certifications
Among 12 certifications are 2 for data:
AWS Certified Database - Specialty
PDF (DBS-C01): $300 to answer 65 questions in 180-minute
AWS Certified Database - Specialty in these domains:
1. Workload-Specific Database Design 26%
1.1 Select appropriate database services for specific types of data and workloads.
- Differentiate between ACID vs. BASE workloads
- Explain appropriate uses of types of databases (e.g., relational, key-value, document, in-memory, graph, time series, ledger)
- Identify use cases for persisted data vs. ephemeral data
1.2 Determine strategies for disaster recovery and high availability.
- Select Region and Availability Zone placement to optimize database performance
- Determine implications of Regions and Availability Zones on disaster recovery/high availability strategies
- Differentiate use cases for read replicas and Multi-AZ deployments
1.3 Design database solutions for performance, compliance, and scalability.
- Recommend serverless vs. instance-based database architecture
- Evaluate requirements for scaling read replicas
- Define database caching solutions
- Evaluate the implications of partitioning, sharding, and indexing
- Determine appropriate instance types and storage options
- Determine auto-scaling capabilities for relational and NoSQL databases
- Determine the implications of Amazon DynamoDB adaptive capacity
- Determine data locality based on compliance requirements
1.4 Compare the costs of database solutions.
- Determine cost implications of Amazon DynamoDB capacity units, including on-demand vs. provisioned capacity
- Determine costs associated with instance types and automatic scaling
- Design for costs including high availability, backups, multi-Region, Multi-AZ, and storage type options
- Compare data access costs
2. Deployment and Migration 20%
2.1 Automate database solution deployments.
- Evaluate application requirements to determine components to deploy
- Choose appropriate deployment tools and services (e.g., AWS CloudFormation, AWS CLI)
2.2 Determine data preparation and migration strategies.
- Determine the data migration method (e.g., snapshots, replication, restore)
- Evaluate database migration tools and services (e.g., AWS DMS, native database tools)
- Prepare data sources and targets
- Determine schema conversion methods (e.g., AWS Schema Conversion Tool)
- Determine heterogeneous vs. homogeneous migration strategies
2.3 Execute and validate data migration.
- Design and script data migration
- Run data extraction and migration scripts
- Verify the successful load of data
3. Management and Operations 18%
3.1 Determine maintenance tasks and processes.
- Account for the AWS shared responsibility model for database services
- Determine appropriate maintenance window strategies
- Differentiate between major and minor engine upgrades
3.2 Determine backup and restore strategies.
- Identify the need for automatic and manual backups/snapshots
- Differentiate backup and restore strategies (e.g., full backup, point-in-time, encrypting backups cross-Region)
- Define retention policies
- Correlate the backup and restore to recovery point objective (RPO) and recovery time objective (RTO) requirements
3.3 Manage the operational environment of a database solution.
- Orchestrate the refresh of lower environments
- Implement configuration changes (e.g., in Amazon RDS option/parameter groups or Amazon DynamoDB indexing changes)
- Automate operational tasks
- Take action based on AWS Trusted Advisor reports
4. Monitoring and Troubleshooting 18%
4.1 Determine monitoring and alerting strategies.
- Evaluate monitoring tools (e.g., Amazon CloudWatch, Amazon RDS Performance Insights, database native)
- Determine appropriate parameters and thresholds for alert conditions
- Use tools to notify users when thresholds are breached (e.g., Amazon SNS, Amazon SQS, Amazon CloudWatch dashboards)
4.2 Troubleshoot and resolve common database issues.
- Identify, evaluate, and respond to categories of failures (e.g., troubleshoot connectivity; instance, storage, and partitioning issues)
- Automate responses when possible
4.3 Optimize database performance.
- Troubleshoot database performance issues
- Identify appropriate AWS tools and services for database optimization
- Evaluate the configuration, schema design, queries, and infrastructure to improve performance
5. Database Security 18%
5.1 Encrypt data at rest and in transit
- Encrypt data in relational and NoSQL databases
- Apply SSL connectivity to databases
- Implement key management (e.g., AWS KMS, AWS CloudHSM)
5.2 Evaluate auditing solutions
- Determine auditing strategies for structural/schema changes (e.g., DDL)
- Determine auditing strategies for data changes (e.g., DML)
- Determine auditing strategies for data access (e.g., queries)
- Determine auditing strategies for infrastructure changes (e.g., AWS CloudTrail)
- Enable the export of database logs to Amazon CloudWatch Logs
5.3 Determine access control and authentication mechanisms
- Recommend authentication controls for users and roles (e.g., IAM, native credentials, Active Directory)
- Recommend authorization controls for users (e.g., policies)
5.4 Recognize potential security vulnerabilities within database solutions
- Determine security group rules and NACLs for database access
- Identify relevant VPC configurations (e.g., VPC endpoints, public vs. private subnets, demilitarized zone)
- Determine appropriate storage methods for sensitive data
AWS Certified Data Analytics - Specialty
PDF (DAS-C01): $300, 75% or _ questions in 190 minute
AWS Certified Data Analytics - Specialty
- https://docs.aws.amazon.com/whitepapers/latest/big-data-analytics-options/welcome.html
- https://d1.awsstatic.com/whitepapers/Migration/migrating-applications-to-aws.pdf
- https://towardsdatascience.com/becoming-an-aws-certified-data-analytics-new-april-2020-4a3ef0d9f23a
- https://portal.tutorialsdojo.com/courses/aws-certified-data-analytics-specialty-practice-exams/
https://medium.com/@athlatif/how-to-prepare-for-aws-certified-data-analytics-specialty-exam-das-c01-ebbfdd237e5e
- avoid using EMR when the question asks for “cost-effective” and “easy to manage” solutions.
- Quicksight can’t visualize data in real-time or near real-time, use OpenSearch and Kibana to achieve this.
- Kinesis data streams can’t write to S3 or Redshift directly, use Kinesis firehouse instead.
- Copy command is used to copy data to Redshift, Unload command is used to copy data from Redshift.
- Athena can’t query S3 Glacier you need to use Glacier select.
- The recommended file format is always ORC or parquet.
1. Collection 18%
1.1 Determine the operational characteristics of the collection system
- Evaluate that the data loss is within tolerance limits in the event of failures
- Evaluate costs associated with data acquisition, transfer, and provisioning from various sources into the collection system (e.g., networking, bandwidth, ETL/data migration costs)
- Assess the failure scenarios that the collection system may undergo, and take remediation actions based on impact
- Determine data persistence at various points of data capture
- Identify the latency characteristics of the collection system
1.2 Select a collection system that handles the frequency, volume, and source of data
- Describe and characterize the volume and flow characteristics of incoming data (streaming, transactional, batch)
- Match flow characteristics of data to potential solutions
- Assess the tradeoffs between various ingestion services taking into account scalability, cost, fault tolerance, latency, etc.
- Explain the throughput capability of a variety of different types of data collection and identify bottlenecks
- Choose a collection solution that satisfies connectivity constraints of the source data system
1.3 Select a collection system that addresses the key properties of data, such as order, format, and compression
- Describe how to capture data changes at the source
- Discuss data structure and format, compression applied, and encryption requirements
- Distinguish the impact of out-of-order delivery of data, duplicate delivery of data, and the tradeoffs between at-most-once, exactly-once, and at-least-once processing
- Describe how to transform and filter data during the collection process
2. Storage and Data Management 22%
2.1 Determine the operational characteristics of the storage solution for analytics
- Determine the appropriate storage service(s) on the basis of cost vs. performance
- Understand the durability, reliability, and latency characteristics of the storage solution based on requirements
- Determine the requirements of a system for strong vs. eventual consistency of the storage system
- Determine the appropriate storage solution to address data freshness requirements
2.2 Determine data access and retrieval patterns
- Determine the appropriate storage solution based on update patterns (e.g., bulk, transactional, micro batching)
- Determine the appropriate storage solution based on access patterns (e.g., sequential vs. random access, continuous usage vs.ad hoc)
- Determine the appropriate storage solution to address change characteristics of data (append-only changes vs. updates)
- Determine the appropriate storage solution for long-term storage vs. transient storage
- Determine the appropriate storage solution for structured vs. semi-structured data
- Determine the appropriate storage solution to address query latency requirements
2.3 Select appropriate data layout, schema, structure, and format
- Determine appropriate mechanisms to address schema evolution requirements
- Select the storage format for the task
- Select the compression/encoding strategies for the chosen storage format
- Select the data sorting and distribution strategies and the storage layout for efficient data access
- Explain the cost and performance implications of different data distributions, layouts, and formats (e.g., size and number of files)
- Implement data formatting and partitioning schemes for data-optimized analysis
2.4 Define data lifecycle based on usage patterns and business requirements
- Determine the strategy to address data lifecycle requirements
- Apply the lifecycle and data retention policies to different storage solutions
2.5 Determine the appropriate system for cataloging data and managing metadata
- Evaluate mechanisms for discovery of new and updated data sources
- Evaluate mechanisms for creating and updating data catalogs and metadata
- Explain mechanisms for searching and retrieving data catalogs and metadata
- Explain mechanisms for tagging and classifying data
3. Processing 24%
3.1 Determine appropriate data processing solution requirements
- Understand data preparation and usage requirements
- Understand different types of data sources and targets
- Evaluate performance and orchestration needs
- Evaluate appropriate services for cost, scalability, and availability
3.2 Design a solution for transforming and preparing data for analysis
- Apply appropriate ETL/ELT techniques for batch and real-time workloads
- Implement failover, scaling, and replication mechanisms
- Implement techniques to address concurrency needs
- Implement techniques to improve cost-optimization efficiencies
- Apply orchestration workflows
- Aggregate and enrich data for downstream consumption
3.3 Automate and operationalize data processing solutions
- Implement automated techniques for repeatable workflows
- Apply methods to identify and recover from processing failures
- Deploy logging and monitoring solutions to enable auditing and traceability
4. Analysis and Visualization 18%
4.1 Determine the operational characteristics of the analysis and visualization solution
- Determine costs associated with analysis and visualization
- Determine scalability associated with analysis
- Determine failover recovery and fault tolerance within the RPO/RTO
- Determine the availability characteristics of an analysis tool
- Evaluate dynamic, interactive, and static presentations of data
- Translate performance requirements to an appropriate visualization approach (pre-compute and consume static data vs. consume dynamic data)
4.2 Select the appropriate data analysis solution for a given scenario
- Evaluate and compare analysis solutions
- Select the right type of analysis based on the customer use case (streaming, interactive, collaborative, operational)
4.3 Select the appropriate data visualization solution for a given scenario
- Evaluate output capabilities for a given analysis solution (metrics, KPIs, tabular, API)
- Choose the appropriate method for data delivery (e.g., web, mobile, email, collaborative notebooks)
- Choose and define the appropriate data refresh schedule
- Choose appropriate tools for different data freshness requirements (e.g., Amazon Elasticsearch Service vs. Amazon QuickSight vs. Amazon EMR notebooks)
- Understand the capabilities of visualization tools for interactive use cases (e.g., drill down, drill through and pivot)
- Implement the appropriate data access mechanism (e.g., in memory vs. direct access)
- Implement an integrated solution from multiple heterogeneous data sources
5. Security 18%
5.1 Select appropriate authentication and authorization mechanisms
- Implement appropriate authentication methods (e.g., federated access, SSO, IAM)
- Implement appropriate authorization methods (e.g., policies, ACL, table/column level permissions)
- Implement appropriate access control mechanisms (e.g., security groups, role-based control)
5.2 Apply data protection and encryption techniques
- Determine data encryption and masking needs
- Apply different encryption approaches (server-side encryption, client-side encryption, AWS KMS, AWS CloudHSM)
- Implement at-rest and in-transit encryption mechanisms
- Implement data obfuscation and masking techniques
- Apply basic principles of key rotation and secrets management
5.3 Apply data governance and compliance controls
- Determine data governance and compliance requirements
- Understand and configure access and audit logging across data analytics services
- Implement appropriate controls to meet compliance requirements
6 courses on Pluralsight (by different authors):
-
Collecting Data on AWS by Fernando Medina Corey 2h 18m
-
Storing Data on AWS by Fernando Medina Corey 2h 51m
-
Processing Data on AWS by Dan Tofan 1h 57m
-
Analyzing Data on AWS by Clarke Bishop 2h 12m
-
Visualizing Data on AWS by Mohammed Osman 34m
-
Securing Data Analytics Pipelines on AWS by Saravanan Dhandapani 1h 9m
Labs:
Classses
-
https://www.linkedin.com/learning/paths/prepare-for-the-aws-certified-data-analytics-specialty-das-c01-certification 3h 41m by the prolific Noah Gift!
-
Coursera 5 course by Whizlabs 5-7 hours each. No instructor name.
-
https://aws.amazon.com/blogs/big-data/how-to-delete-user-data-in-an-aws-data-lake/
Social
References
https://www.wikiwand.com/en/Timeline_of_Amazon_Web_Services
https://www.youtube.com/watch?v=tykcCf-Zz1M Top AWS Services A Data Engineer Should Know
More on Amazon
This is one of a series about Amazon:
Others must know: please click to share:
AWS Data Tools was published on August 20, 2023.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK