

论文解读(CTDA)《Contrastive transformer based domain adaptation for multi-sour...
source link: https://www.cnblogs.com/BlairGrowing/p/17638890.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

论文解读(CTDA)《Contrastive transformer based domain adaptation for multi-source cross-domain sentiment classification》
Note:[ wechat:Y466551 | 可加勿骚扰,付费咨询 ]
论文标题:Contrastive transformer based domain adaptation for multi-source cross-domain sentiment classification
论文作者:Yanping Fu, Yun Liu
论文来源:2021 aRxiv
论文地址:download
论文代码:download
视屏讲解:click
动机:传统的域自适应方法侧重于减少源域和目标域之间的域差异,从而实现情绪迁移,忽略了有效源的选择,无法处理负转移,导致性能有限;
-
- (1)设计一个混合选择器权重所有相关来源或挑选出Top-K来源根据两个领域之间的空间相似性;
- (2)构建一个适配器提取域不变的特性的信息通过最小化两个领域之间的瓦瑟斯坦距离;
- (3)构造一个鉴别器捕获的域私人信息特征对比学习;
- (4)执行加权分类器根据多个训练的源分类器预测目标域的情绪趋势;
-
- 提出了一种混合多源域选择策略来对所有相关源进行加权或选择 Top-K 源,它选择相关源,消除无关源或恶意源,以减少负传递的影响;
- 提出了一种域适配器和鉴别器来自动捕获包含域共享和域私有信息的特征,从而最好地支持实现跨域自适应的最终预测;
- 提出了一种新的加权策略来聚合多个源分类器来构建一个情绪预测器,它可以强调不同源域的重要性;
- 在FDU-MTL和Amazon审查数据集上进行了广泛的实验,结果表明我们的CTDA框架可以在无监督的MCSC任务上实现显著的性能;
2 相关知识
-
- 由来自不同域的数据引起的域偏移;
- 在消除域差异时保留域私有特征;
- 负迁移问题;
-
- 通过生成域不变和域私有特征[8,9]来构建情绪分类器;
- 利用域自适应方法来弥补域的差距;
Note:共享私有模型,特征空间被划分为共享空间还是私有空间,主要取决于这些词在统计上是否相同。随后,通过应用深度神经网络将 pivot 和 non-pivots 提取为域共享和域私有特征。然而,这些方法也存在一些问题,如域不变特征,包括一些无关的域私有特征,共享的域特征被划分为私有空间,它们削弱了情绪分类器在 UCSC 任务中的识别能力。
多源域情感分类存在的问题:
-
- ① 如何从多个源域中选择合适的来源,以及如何对所选的来源进行加权,以获得有效的情绪传递。传统的策略是直接结合所有源域的知识,将其转移到目标域。然而,无关源或恶意源会对 MCSC 任务的性能产生负面影响;
- ② 如何将多个源域的知识转移到目标域?目前还没有合适的方案来平衡域自适应和域私有信息;
整体框架:
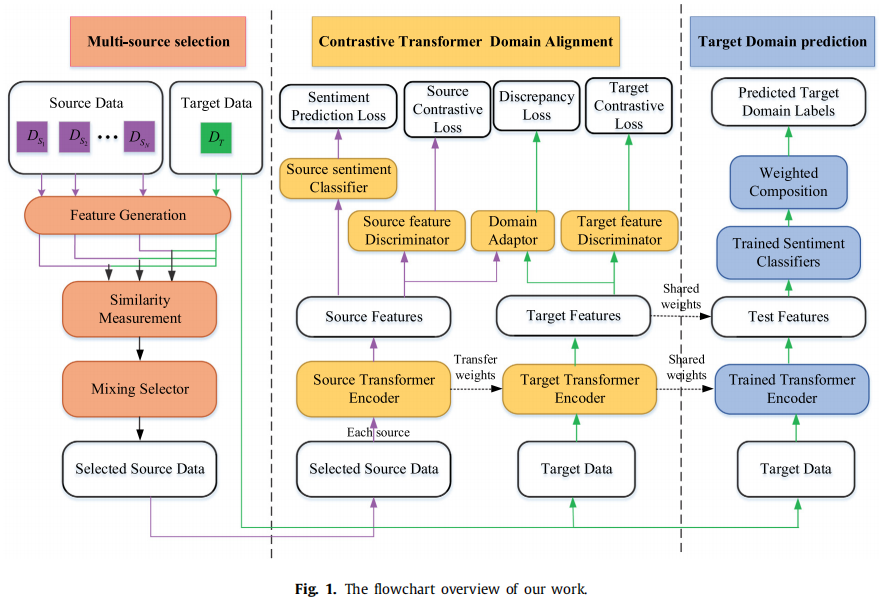
3.1 多源选择策略

特征提取:
RSi=BERT(XSi)
RT=BERT(XT)
考虑每个源域和目标域之间特征的 KL 散度来评估相似性:
KLi=KL(gSi‖gT)+KL(gT‖gSi)
gSi=exp(norm(g′Si)),g′Si=1nSi∑nSik=1RSi(k)
gT=exp(norm(g′T)),g′T=1nT∑nTk=1RT(k)
Note:norm 为 l2 归一化操作,k 表示第 i 个源域中的第 k 个样本;
相似性得分如下:
SCi=βKLi
受 [44] 启发,多源选择器依赖于 “ 特征分布距离越近,实例越相关 ” 的理论。根据相似度方差提出了一种混合选择策略,其计算方法如下:
Va2=∑Ni=1(SCi−M)2N
式中,M 为相似度得分的平均值,N 为源域的个数;
在得到相似性方差之后,混合选择策略包括如下两种方案:
-
- 加权选择方法;
- Top-K 选择方法;
加权选择方法
当相似度方差较小时,不同对源域和目标域之间的分布差异波动较小。即,所有的源域和目标域几乎都位于同一相似性级别上。因此,利用所有源的知识来预测目标域。由于每个源域的知识转移的贡献是不同的,加权选择方法是对最终预测器的所有加权源域进行和,将每个源的权值表示为 αsi,转迁移如下:
PT=∑nSii=1αSiP(XSi)
αSi=SCi∑nSii=1SCi
注意:P(XSi) 表示第 i 个源预测器预测的目标域的边际分布,PT 表示目标域的最终边际分布;
当相似度方差较大时,不同对源域和目标域之间的分布差异波动较大。即,只有部分域对之间的分布差异较小,而其他域对之间的分布差异较大。因此,基于这个假设, 选择与 Top-K 相关的源域作为可转移域,并消除其他源域以减少负转移。Top-K 选择方法的具体计算过程与加权选择方法相同。在本文中,设置了 Top 30% 来验证该算法的可行性。
3.2 对比 transformer 域对齐
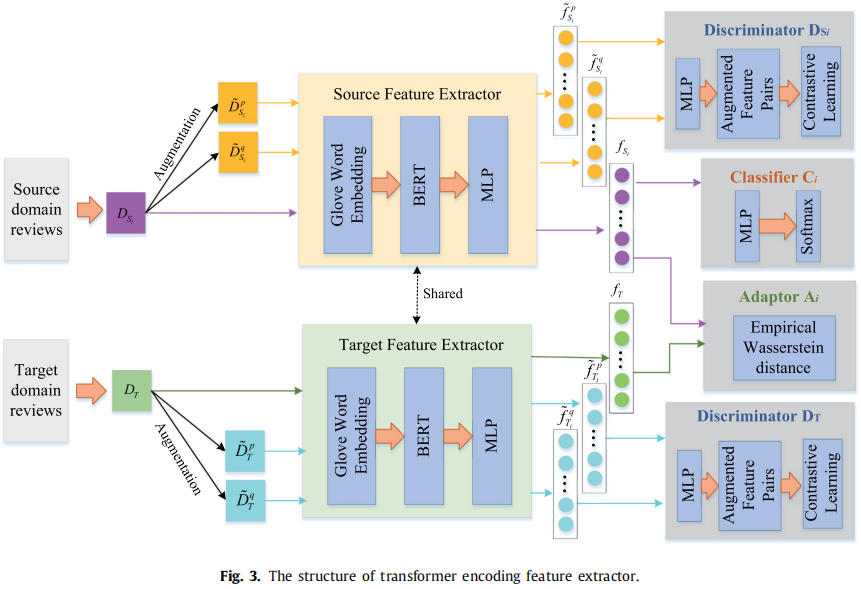
在本节中,我们描述了所提出的对比 transformer 域对齐框架,它将有效的信息从选定的源域传输到未标记的目标域。如 Figure 3 所示,对于每一对源域和目标域,我们的框架由一个 domain adaptor、两个 domain discriminator 和一个 sentiment classifier 组成。特别地,domain adaptor 通过评估瓦瑟斯坦距离来消除域偏移,获得域共享信息;domain discriminator 通过对比学习方法分别保留两个域的域私信息;利用域共享和域私信息等特征对源域的标记数据进行训练得到的 sentiment classifier。
目的:将有效信息从选定的源域传输到未标记的目标域;
特征提取器(以源域数据为例):
wSi(k)=Glove(xSi(k))
bSi(k)=BERT(wSi(k))
fSi(k)=AbSi(k)+c
原始输入 fSi、fT,源域特征 ˜fpSi、˜fqSi,目标域特征 ˜fpT、˜fqT。
Domain adaptor
对于无监督的跨域分类,最关键的目标是通过减少域差异来消除域偏移。域自适应是一种有效的方法,其目的是通过最小化两个域之间的距离来捕获域共享特征。我们的域适配器应用瓦瑟斯坦距离来估计域的差异,并以对抗性的方式优化特征提取器,其理论优点是其梯度特性和有前途的泛化界。
目的:通过减少域差异来消除域偏移;
策略:对抗性训练(Wasserstein distance);
文档特征 fSi 和 fT,瓦瑟斯坦距离:
Wa(fSi,fT)=sup‖fw‖L≤1Efsi[fw(fSi)]−EfT[fw(fT)]
其中:fw 是满足 1-Lipschitz 约束 的特征映射函数,参数为 θw;
为实现域混淆,最小化两个域之间的距离 Lwf:
Lwf(fSi,fT)=1nSi∑fSi∈DSifw(fSi)−1nt∑fT∈Dtfw(ft)
因为 fw 需满足 Lipschitz 约束,所以进行权重裁剪在 [−c,c] 范围内。为避免由权重裁剪引起的梯度消失、爆炸,提出梯度惩罚函数 Lwg:
Lwg(fSi,fT)=‖∇ˆdfwf(ˆd)‖−1
式中,ˆd 为 fSi 和 fT 串联中的随机点。
通过计算以下损失函数,得到瓦瑟斯坦距离:
Lw=maxθw{Lwf(fSi,fT)−λ⋅Lwg(fSi,fT)}
Note:首先通过迭代学习特征表示来训练 Lw 的最优性,优化完成后,固定参数并设置 λ=0,最小化瓦瑟斯坦距离 Lw。通过以较低的瓦瑟斯坦距离迭代学习特征,对抗性目标最终可以学习域不变特征。因此,最小化域适配器的损失函数被提出如下。
minWa(θe)=minθeLw
其中,θe 表示特征提取器的参数。
目的:域对齐过程中,域自适应在捕获域共享特性时导致了域私有信息的丢失,所以本节提出了域鉴别器,用对比学习方法来保留域私有特征;
对比损失:
l(p,q)=−logexp(sim(~SpSi,~SqSi)/δ)∑2Mj=1I[j≠p]exp(sim(˜fpSi,˜fjSi)/δ)
虽然 ˜fpSi,˜fqSi 的正对是一致的,但负对是不同的。受 [45] 的启发,最终的对比损失函数被表述为:
Lficon =12M∑Mk=1[l(p(k),q(k))+I(q(k),p(k))]
由于为每对源域和目标域构造参数共享域鉴别器,所以最终对比损失如下:
Lcon=Lsicon+LTcon
情绪分类器是一层的 MLP ,情绪损失如下:
Lsent =−1nsi∑nsik=1yPsi(k)ln(ytSi(k))+(1−ypsi(k))(1−ln(ytSi(k)))
其中,ytSi(k) 表示情绪标签;
3.3 联合训练
训练目标:
Ltotle =∑ˆNj=1Ljtotle =∑ˆNj=1(σLjWa+τLjcon +Ljsent )
其中,ˆN 表示多源选择策略决定的源域数量;

3.4 分类器加
对于 MCSC 任务,不同源分类器的组合方法会直接影响到预测性能。因此,提出了一种新的分类器加权组件,用于应用所选择的源域。对应于每个源域的模型,基于学习到的编码器提取目标域的特征 fjT,并使用训练好的情绪分类器得到情绪预测 CjT(fjT)。让所选的源域数为 ˆN,将每个源分类器的不同预测组合起来,得到最终结果:
CT=∑Nj=1αSiCjT(fjT)
由于学习到的特征包含情感和语义信息,并且特征空间比原始数据可以更好地表示两个域之间的距离关系,因此使用了一个新的权重分量 αSi。所提出的加权策略是强调更多相关的来源,而抑制不太相关的来源。应用训练模型中的第 i 个源和目标之间估计的瓦瑟斯坦距离 LWi,并将该距离映射到一个标准高斯分布 N(0,1)。因此,每个域 α′Si 的权值可以计算如下:
α′Si=e−L2Wi2∑nSii=1e−L2Wi2
实验关注的问题:
-
- 混合选择策略能解决负转移问题吗?
- CTDA能否捕获包括域共享和域私有信息在内的特性,并获得比基线实验更好的性能?
- 分类器加权分量的建议是否有效?
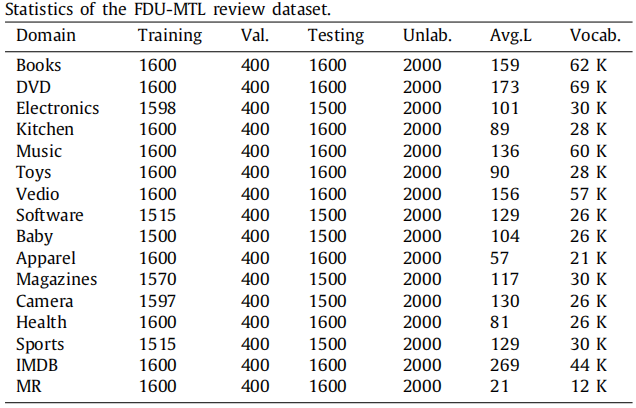
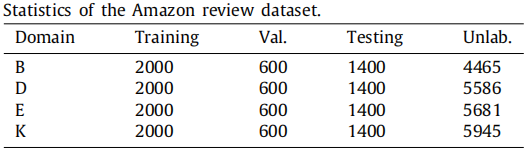
数据集
多源选择策略的效果
FDU-MTL数据集包括16个域,它们有足够的源来允许选择不同的策略,只在FDU-MTL审查数据集上进行了实验,以验证多源选择策略;
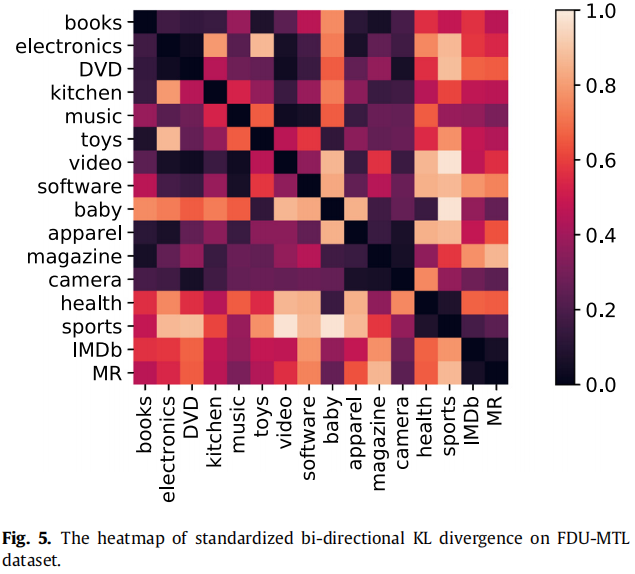
两个域之间的 KL 散度越小,其相似性越高。
为了评估目标域与其他源域之间的相似度的分散程度,我们计算了每个目标域的相似度得分的变化。Table 4 显示了每个源域和目标域对每个目标域形成的域对的相似度得分的方差。Table 4 显示了方差中的两个数量级,即 0.1 和 0.01。在概率论中,方差被用来度量离散值与其均值之间的偏差。对于方差为0.1的目标域,目标域与所有源域形成的域对的相似度得分相对分散;因此,在所有源域中,某些域的相关性高于其他域。而对于方差为0.01的目标域,则相反,所有的源域都与目标域具有相似的相关性。因此,对于域方差幅度为 0.1 级,如 baby, apparel, health, sports, IMDB, MR ,我们应用Top-K 选择方法选择来源,和域方差 0.01 数量级,如 books, music, software, electronics, toys, DVD, video, magazines, kitchen,camera ,使用加权选择的方法来选择源。

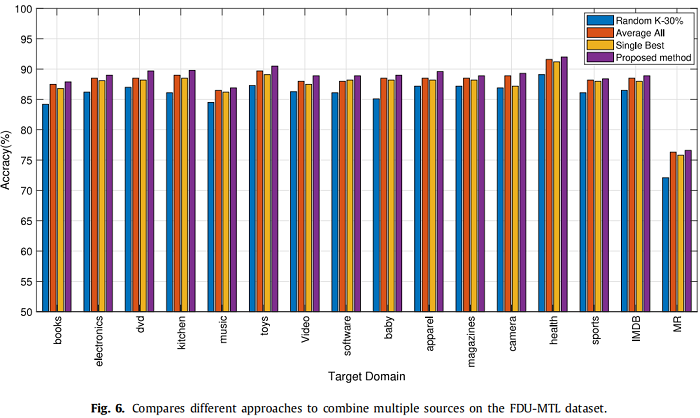
为了验证所提出的多源选择策略的效果,我们将所提出的算法的性能与来自随机Top-K源的选择方法进行了比较,平均所有源、单一最佳源,分别称为“Random Top-30%”、“Average All”、“Single Best”。Figure 6 显示了在FDU-MTL数据集上使用不同选择策略的不同方法的结果。从 Figure 6 可以看出,该算法对所有域都优于“Random Top-30%”、“Average All”和“Single Best”,证明了简单选择策略可能会引入太多的不相关域作为源域,导致负转移。因此,总体分析表明,所提出的混合选择策略减轻了负转移问题,并导致了显著的性能改进。
Amazon review dataset 仅包含四个域;当一个域作为目标域时,只有其他三个域可以是多源域。对于我们的Top-30%选择方法,可用源域的数量小于 1,因此,我们只将我们的加权选择方法应用于所有源域来传递每个目标域的情绪。
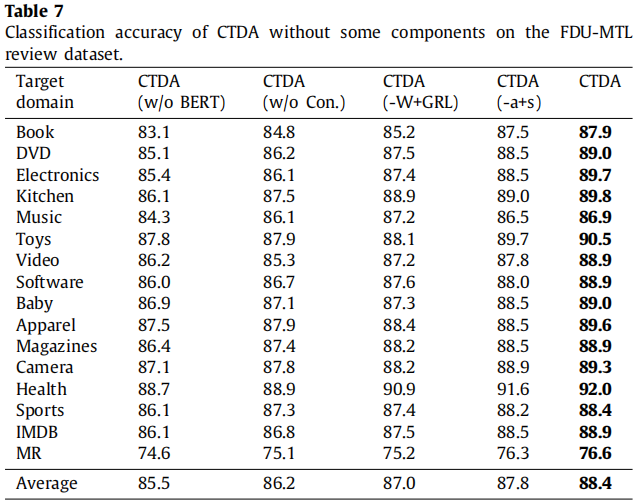
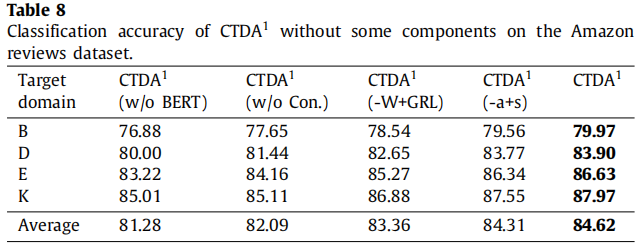
分类结果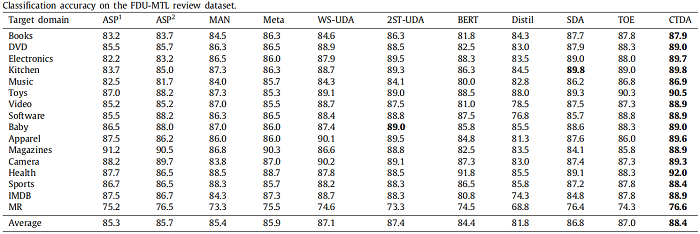

__EOF__
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK