

How Flexport halved testing costs with an auto-scaling CI/CD cluster
source link: https://flexport.engineering/how-flexport-halved-testing-costs-with-an-auto-scaling-ci-cd-cluster-8304297222f
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

How Flexport halved testing costs with an auto-scaling CI/CD cluster
At Flexport, we believe in fast iteration. We want our engineers to be able to quickly try out ideas, build features, and ship products. In pursuit of this goal, we set out to build a Continuous Deployment (CD) system — a mechanism to ship code to production without human intervention, ideally on every commit.
We started with something pretty rudimentary and eventually scaled up to an advanced setup that runs hundreds of automatic deploys every week — all while halving our test infrastructure costs! It delights engineers every day and has been a huge boon to productivity. For the exciting details, read on. . . .
Before continuous deployment
Being big fans of automation, we have had a Continuous Integration (CI) setup for a while — CI entails running your tests automatically on every commit to ensure that new code doesn’t break existing tests. We used a very popular CI platform: Travis. It integrates with a GitHub repo and can run test suites on every pull request and commit to master. Coupled with a good set of tests that lend a fair bit of confidence to the code being merged (which we have as a direct result of our strong emphasis on testing), tools like this are crucial for a fast-moving engineering org.
Deployments, on the other hand, were a different story. Every engineer would merge their code and then run a production deploy. Our stack is Rails + React and we use Capistrano to deploy code. Each deploy in this setup takes 20–30 minutes, locks the machine to the master branch, and maxes out CPU. In addition to this, we also incur all the risks of deploying from local machines (potential for stale assets, old code, wrong environment).
This still allowed us to deploy 10+ times a day. But imagine dozens of engineers spending 30+ mins a day just staring at a terminal and waiting for deploys to finish! It was a huge drain on productivity.
First solution: Travis deploys

Our first solution for the deployment problem was to use Travis. It was already set up to pull the latest master and build assets; we just had to make it run a deploy script at the end of test runs.
We were able to get this to work, although we had to improvise a bit on the way. We used a third-party script to coordinate the various test jobs (Travis now has native support for this); we set up Slack to notify every dev whose changes went out with the last deploy (huge hit among the devs); and we had to handle out-of-order build completion — how not to deploy old code.
Engineers quickly grew to love this system —just merge your code and wait for Slack to notify you when your code gets deployed! It saved a lot of time and headache for the team. There were some hiccups now and then, but for the most part, we had pretty reliable automatic deploys.
This served us well for a while, but eventually we realized the need for more advanced features. Our primary concerns were: control over the machines (more RAM — because webpack, installed packages), a better way to specify the relationship between test jobs (build assets once and share, enable more parallelization), and resource contention. Resource contention on our limited build machines was becoming an especially critical issue as we hired more engineers and more code was being merged every day. We upgraded our Travis plan a few times, but it was still not enough.
These issues made us wonder if there were better alternatives out there. After some investigation, we decided to try out Buildkite.
Buildkite deploys

Buildkite is a build automation framework. It follows a different model than its more traditional counterparts. It allows you to create pipelines (which specify the various steps needed to execute a build) with a powerful syntax. You can model fan-out/fan-in relationships, use artifacts to avoid repeated work, trigger builds from one pipeline to another, and even dynamically create pipelines.
You write yaml files to specify these pipelines and then Buildkite’s service handles the orchestration of builds. Builds can be triggered via github merges and pull requests, and can even be created via the UI. So you can run tests on your experimental changes without creating a PR or run a hotfix deploy — all from the UI!
Another salient feature of Buildkite is that the builds run on your own infrastructure. You could set it up to run builds on an AWS cluster, or your own data center, or even on your engineers’ laptops (not recommended!). Ideally, you would run builds on an auto scaling cluster and unsurprisingly they provide you a template for it — you can use this to set up an auto scaling cluster on AWS with just one click. Buildkite’s auto scaling setup is great for CI/CD because the machines go down during off hours, weekends, and holidays — thus saving significant infrastructure costs.
There is native support for docker, so you get full environment control — you can install all the packages and tools your builds require and thus get very repeatable builds. We utilize this to also pre-cache our bundler gems and yarn packages. So a particular test build only needs to download the gems and packages that are new since the last docker image.
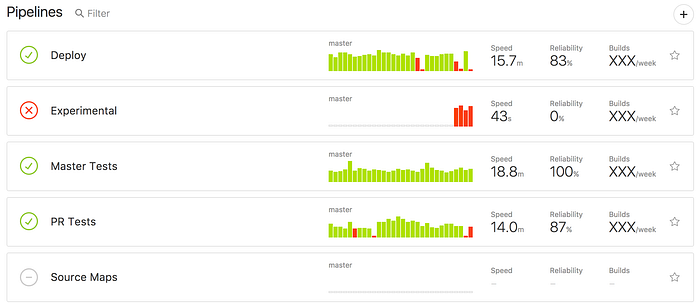
Buildkite was mostly straightforward to set up. We have it currently running all our PR tests, master tests, and deploys. Every week, our Buildkite setup runs millions of tests and hundreds of deploys, but costs half what we were paying previously!
Future goals
The aspirational goal for this system is to enable 5 min test runs and 5 min deploys! We hope to achieve this with more parallelization and by moving non-critical components to an async pipeline — but the good news is that our framework of choice (Buildkite) has support for these.
Interested in solving these types of problems? Follow us here or on Twitter to learn more about interesting problems in the world of freight, or if you’re ready to take the next step, we’re hiring (check out our current openings)!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK