

Memory Management & Reference Counting Internals of Python
source link: https://codeconfessions.substack.com/p/cpython-reference-counting-internals
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

How CPython Implements Reference Counting: Dissecting CPython Internals
An Extensive Walkthrough of Python’s Primary Memory Management Technique, Reference Counting
This week we are diverting from AI and machine learning to discuss a more intense CS topic — memory management in Python. Memory management refers to the techniques used by the programming language runtime to allocate and free memory as programs execute. Understanding how memory management functions in a language is crucial to writing efficient and high-performing software. In this article, we will discuss how CPython (the reference C implementation of Python) implements memory management. It won't be a vague discussion; we will dive into the internals of CPython to see how everything is implemented. By the end of this article, not only will you grasp a key implementation detail of memory management, but you'll also be capable of exploring the CPython source on your own. So, if you're curious about how CPython operates under the hood and its internals, keep reading!
The article explores a very technical topic in great detail and it is not possible to provide all the background here. The readers are expected to have some knowledge about how interpreted languages work and their execution model (such as bytecode virtual machines). In order to understand the parts about CPython internals, some knowledge of C is required (specifically structs and memory allocation).
If you enjoy reading my work, please show your support by subscribing.
Basics of Memory Management in CPython
Memory is a scarce resource, and programming language runtimes need to devise strategies to manage it judiciously so programs don't exhaust memory and crash. Most programming languages typically utilize a garbage collector (GC) to achieve this. A GC is a background process that periodically identifies all inactive objects and reclaims their memory.
However, GC is not the only means of managing memory. In the case of CPython, it employs two techniques for managing memory: reference counting and garbage collection. It uses reference counting as its principal strategy for reclaiming memory from inactive objects. Yet in some situations, reference counting might leave behind a few objects, for these cases CPython uses a GC.
In this article we will limit our discussion to reference counting only. Until we don’t understand how reference counting works, we cannot discuss the cases where it doesn’t work, for which a GC is needed. We will discuss the limitations of reference counting towards the end of the article.
Understanding Reference Counting in CPython
Let's start with understanding the first technique: reference counting. CPython primarily employs reference counting to manage its memory. First, let's discuss references. When we create an object and assign it to a variable, the variable contains a reference to the object, not the object itself. You can think of a reference as a hyperlink — when a document needs to refer to another article, it simply includes a hyperlink to said document instead of copying all of its content. Similarly, a variable contains a reference to an object, and multiple variables can refer to the same object.
Mechanism of Reference Counting
Let's clarify how reference counting functions. Each object in CPython keeps a count of references pointing to it. Once we create an object, it commences with a reference count of one. The following illustration demonstrates how an object and its reference would be represented internally by CPython. It illustrates how the variable relates to the string object and how the object stores the value and the reference count.
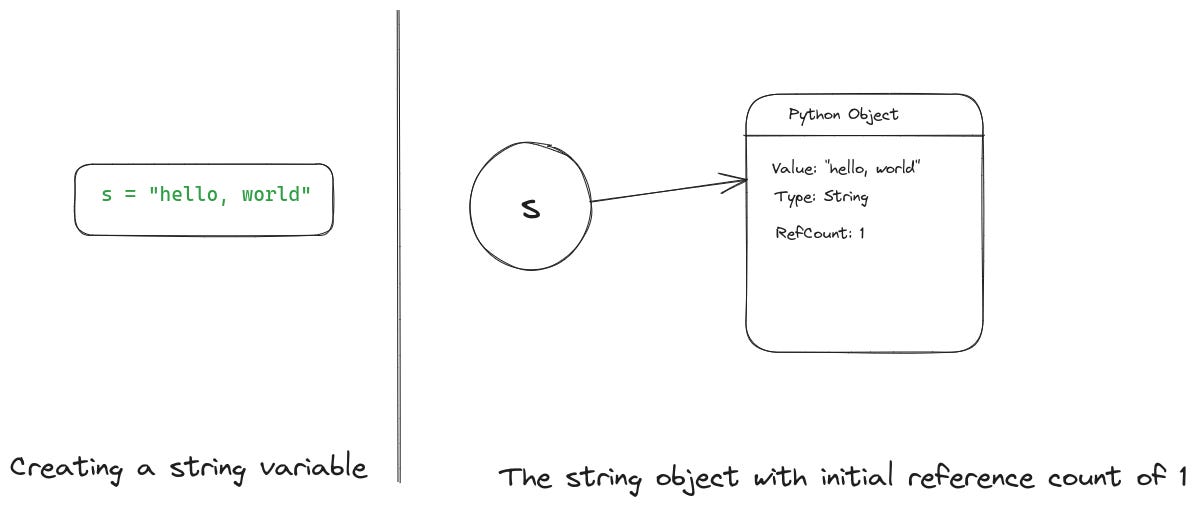
Whenever we assign that object to a new variable, or pass it to a function as a parameter, the object’s reference count increases by one. This illustration illustrates how assigning the object to a second variable results in the object’s reference count incrementing to two.

And finally, as each variable exits from scope, the object’s reference count decreases by one. When the object’s reference count reaches 0, it's freed.
If you want to see the reference counts of an object, you can use the function sys.getrefcount() to do that. Be aware that the reference count returned by this function is one more than the expected reference count because, when we call getrefcount(), we pass it the object as a parameter. This results in the reference count increasing by one while that function is executing.
>>> import sys
>>> s = "hello, world"
>>> sys.getrefcount(s)
2
>>> s2 = s
>>> sys.getrefcount(s)
3If you found this article useful, please subscribe to receive future articles directly in your inbox.
CPython Internals of Reference Counting
Now we come to the exciting part where we start looking at how reference counts are represented, updated, and utilized inside the CPython code.
Note: All of the CPython code discussed here, refers to the release version 3.12. The details of reference counting implementation may change in future versions. You can find the GitHub repo of CPython here.
How CPython Represents Objects in Memory
Having understood the basics of reference counting, let's look under the hood to see how the internals of CPython implement this. As the CPython core is implemented in C, core Python objects are defined as C structs. Each object's definition begins with a header called PyObject. This header houses metadata about the object, including its reference count and object type. PyObject is defined in the file Include/object.h as struct _object, with its definition below.

The
ob_refcntfield stores the reference count of the object.ob_typefield stores the type of the object. ThePyTypeObjectitself is a struct defined in Include/cpython/object.h. It stores a ton of other information apart from the type, such as basic size of the type, and pointers to type specific functions. The struct is too big to show here, but you can refer to the CPython source if you are interested.
If you are wondering that I showed the definition of _object, but I’ve been discussing PyObject, then you are right. This struct has been typedef’d to PyObject in Includes/pytypedefs.h, as shown below.

Modifying Reference Counts in CPython
Now that we have seen how reference counts are stored in objects, let’s explore how they are increased and decreased. Whenever an object’s reference count needs to be manipulated, CPython provides functions to do that. These are called Py_INCREF and Py_DECREF, and they are defined in Includes/object.h.
First, let's closely examine the definition of Py_INCREF. In order to simplify, I'm presenting a simplified version here. For the full definition of Py_INCREF in the official CPython code, see here.

Let’s break it down:
The
_Py_IsImmortalcheck ensures that the object is not an immortalized object. Immortalization was introduced in Python 3.12 to improve performance. It ensures that immutable objects such as None, True, False, etc., are truly immutable at runtime and their reference counts don’t change. Read more about it here.If it is not an immortal object, its reference count increments.
Next, let’s take see a simplified definition for Py_DECREF. You can find the official CPython source code for it here.

Again, if it is an immortal object we don’t touch it.
Otherwise, we decrement its reference count. If the reference count has reached 0, then we can safely deallocate the object as it is not used anymore.
Implementation of the Integer (int) Object in CPython
Now that we've covered how objects store reference counts and how those reference counts are manipulated, let's examine the implementation of an actual Python object used in real Python programs. We'll select the integer object because it's straightforward and everyone uses it.
Note: Even though the type of any integer object is reported as ‘int’ in Python, but within the CPython implementation it is referred to as
longeverywhere. So you will see names like_PyLongValueandPyLongObjectin code listings.
Definition of Integer Object
The integer object is defined in the file Include/cpython/longintrepr.h and its definition is show below.

Here, the struct _longobject defines the integer object. As you can see, it starts by including the struct PyObject as its first field, forming the header for the object. The second field (long_value) defines the actual value stored by the object.
The struct _longobject is typedef’d as PyLongObject in the file Includes/pytypedefs.h. The rest of the CPython code uses
PyLongObjectinstead of_longobject.
Initialization of Integer Object
As we know, when a new object is created its reference count is set to one. Let's see where and how this becomes reality for the integer object. The related implementation code for the integer object can be found in the file Objects/longobject.c. The following picture shows the definition of the _PyLong_new function, which is responsible for creating and initializing a new PyLong object.
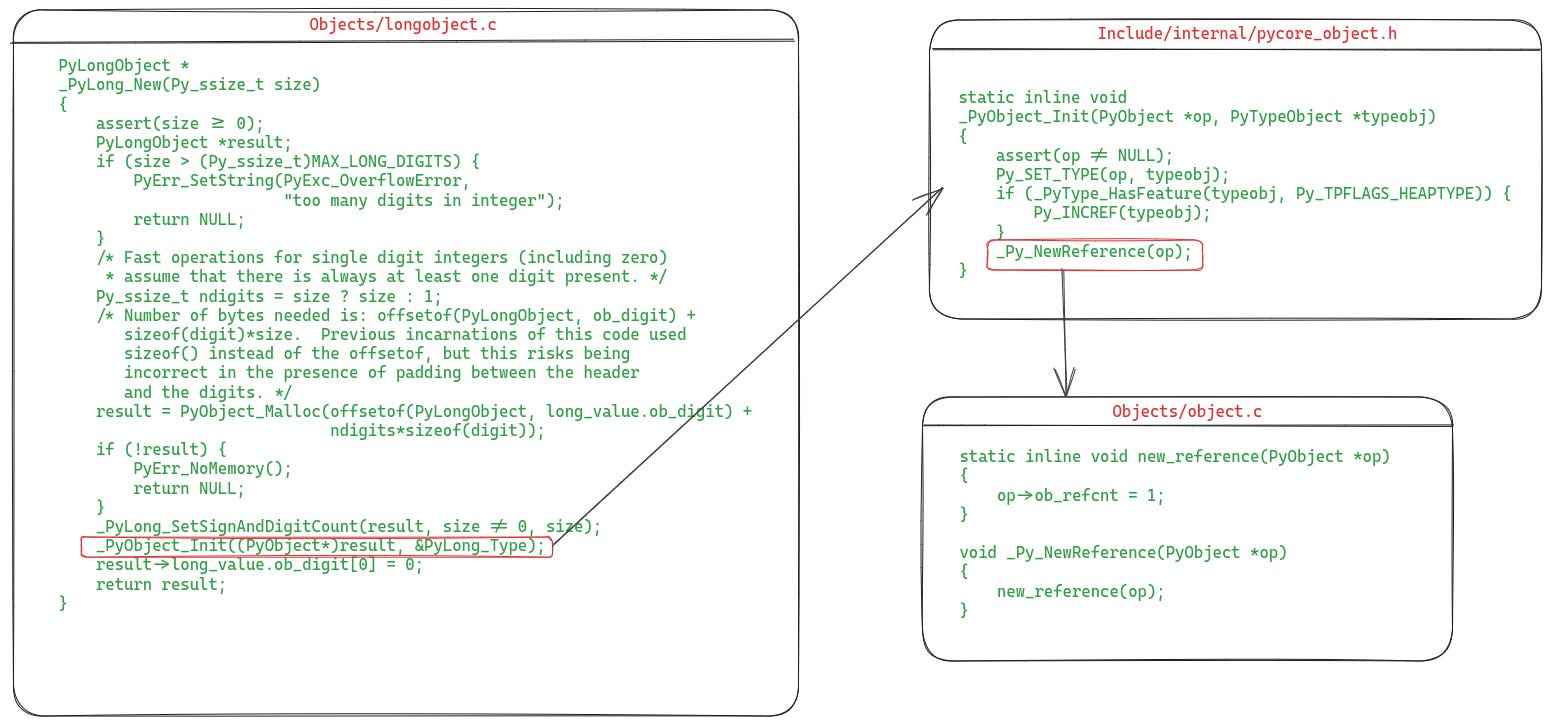
Let’s understand the parts relevant to reference counting here:
In the
_PyLong_Newfunction, thePyObject_Malloc callallocates memory for the object.PyObject_Mallocis one of CPython’s primary memory allocation functions, as typically most of the objects are allocated using it.Once the memory is allocated,
_PyObject_Initis called which is defined in Include/internal/pycore_object.h. This function is responsible for setting up the initial state for a new object. This is where the reference count for the object is set to one via a call tonew_reference(defined in Objects/object.c). I have shown a simplified version ofnew_referenceto make it easier to understand.
If you enjoyed reading this article, consider subscribing to encourage me writing more such articles.
The Role of Reference Counting in CPython's Virtual Machine
Now let's look at the part of CPython where reference counts are actually updated. Reference counts are only modified when we use objects in Python code, e.g., assign them to variables or pass them to functions as arguments. Thus, we need to look into the core of CPython where user code is executed, i.e., the bytecode virtual machine (VM).
Bytecode Virtual Machine: CPython compiles the Python code to a bytecode representation which is then executed by a stack based virtual machine (VM). In a stack VM, instructions are executed in terms of the push and pop operations on the stack.
A Very Brief Introduction to Python Bytecode
First, let's familiarize ourselves with some of the bytecode instructions we will investigate. We'll take a simple Python function and examine its bytecode.

The above code shows the bytecode for a simple add function, which adds two variables together. We are using the dis module which disassembles the given code object and gives back its bytecode. Let’s quickly understand these instructions.
The
LOAD_FASTinstruction loads a local variable onto the stack. In our example,aandbare passed as parameters to the function, thus they're represented as local variables and need to be pushed onto the stack.LOAD_FASTachieves this by looking up the variables in an array explicitly used to store local variables. The variable's index is passed toLOAD_FASTas an argument. In this example, you can see that it's passed arguments 0 and 1 for loadingaandb, respectively. After the twoLOAD_FASTinstructions are executed,aandbare the top two objects on the stack.The
BINARY_OPinstruction executes the given binary operation by popping the top two values from the stack. The binary operation is passed as an argument to the instruction, in this case0for+. The result of theBINARY_OPinstruction will be pushed back onto the stack.Lastly, the
RETURN_VALUEinstruction pops the top value from the stack, making it the return value of the function.
Execution of Bytecode Instructions in CPython Virtual Machine
Now we can observe how the code for executing these instructions is implemented in CPython.
Note that the code shown below for LOAD_FAST and BINARY_OP is taken from the file generated_cases.c.h. This file is generated by the CPython build and is not part of git. For reference, I have put the generated file for CPython version 3.12b4 as a GitHub gist here.
LOAD_FAST Execution
The following listing shows the code from Cpython VM which executes the LOAD_FAST instruction.

Let’s understand what is happening here:
The
GETLOCAL(oparg)call looks up the variable from the locals array by using the index passed as the argument toLOAD_FAST.Py_INCREFincrements the reference count of the object because the object has been assigned to a variable (here, it is assigned to the function parameter).The line:
stack_pointer[-1] = value, pushes that object onto the stack.
BINARY_OP Execution
The following listing is a simplified version of the code to handle the BINARY_OP instruction. You can see the actual code here.

Let’s break down the important bits:
The first two lines are popping the top two values from the stack as the
lhsandrhsof the binary operation to be executed.The line
binary_ops[oparg]looks up the function which should be called for the given binary operation.lhsandrhsare passed as arguments to that function and the result is stored inres.After the binary operation, we are done with the two variables and they will go out of scope. Therefore, their reference counts are decremented using
Py_DECREF. At this point, they might get deallocated if their reference count drops to 0.Finally, the result of the binary operation is pushed onto the stack using
stack_pointer[-1] = res.
The Limits of Reference Counting and the Role of a Garbage Collector
While reference counting plays a crucial role in CPython's memory management, it does have its limitations. Let's discuss.
Although reference counting is a low-overhead and efficient technique for managing memory, it fails if the objects have cyclic references to each other. For instance, an object A has a reference to B and object B has a reference to A. In such situations, even if A and B don't have external references, their reference count will not drop to 0 because they still maintain references to each other. Let's look at a more tangible example:
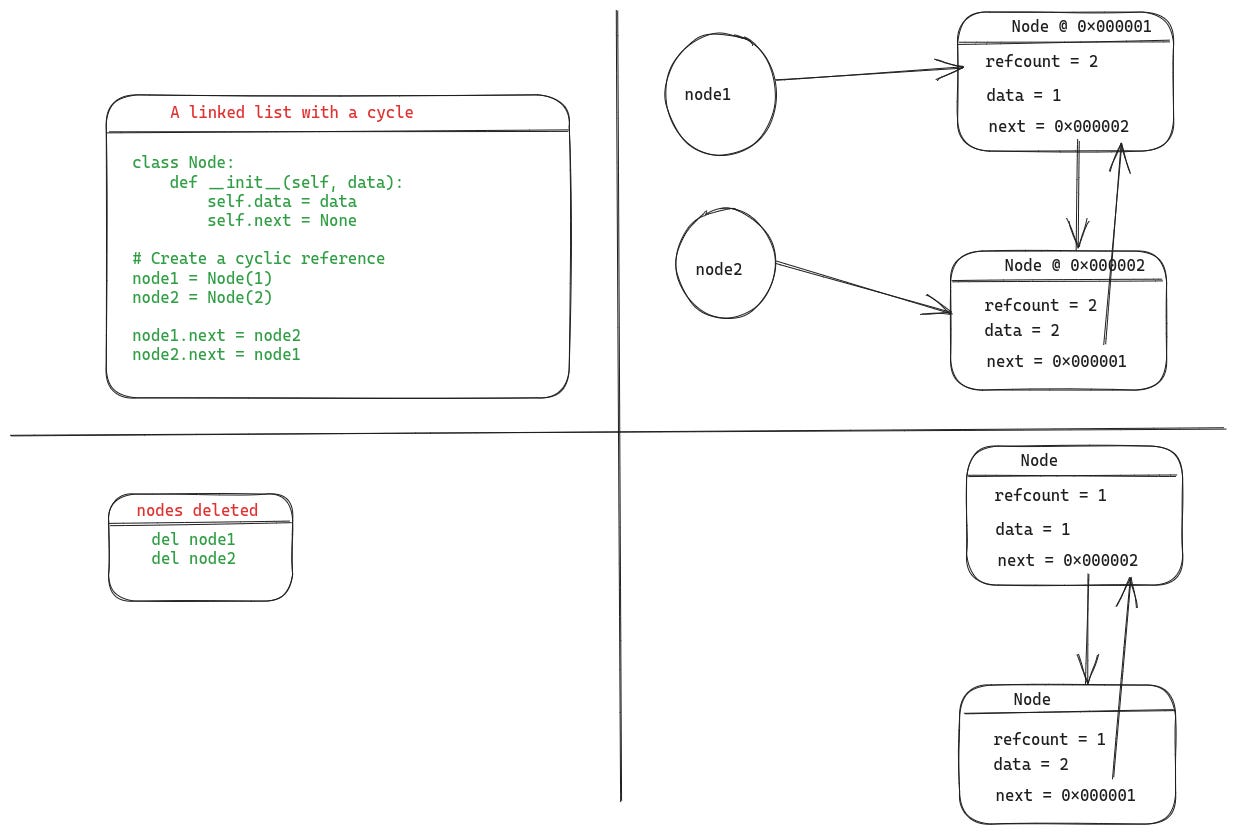
Here, in the upper half of the illustration, we've created a linked list with two nodes. The two nodes point to each other, resulting in a cyclic reference. As you can see, those two nodes have two references — one because of the variables (node1 and node2), and the other due to them internally holding a reference to each other (as their next field values).
As you can see in the bottom half of the illustration, even after we delete node1 and node2, the objects remain behind because their reference counts are still one. To claim memory from such objects, Python has a garbage collector, which runs periodically to detect such cycles frees up the memory where possible.
The details of the garbage collector in CPython are also exciting. There are intriguing details around how the cycles are detected and optimizations utilized to minimize the overhead of the GC. However, it would require a separate article to explore the GC internals of CPython. If there's interest, we can examine that in a future article. Let me know if you'd like to read about it in the comments.
Wrapping Up
This concludes a long winded tour of a part of memory management code in CPython. I say a part, because we did not discuss how the garbage collector works here. However, we did cover the guts of reference counting implementation. We looked at the definitions of some of the key structs which form the core of Python objects. Then as a concrete example, we looked at how the integer object is implemented. Finally to tie everything up, we peeked inside the CPython bytecode interpreter code to see how it executes some of the instructions and how the execution of those instructions affects the reference count of the objects. We also covered how reference counting cannot free objects with cyclic references, for which CPython uses a GC.
This post, I hope, provides you with clarity on how you can write more memory-efficient code. For instance, unnecessary variable assignment results in overhead of reference count updates, and creating cyclic references between objects means they will reside in memory for longer times (until the GC cleans them up). Additionally, the exploration of the CPython code should equip you to independently read and explore the CPython source and potentially contribute to the project.
If you would like to see more posts like this explaining how CPython works and explore its implementation details, then let me know via likes and shares of this post. Trust me, there are a lot of interesting details and a ton of engineering lessons buried in CPython code base.
If you read this far and enjoyed the article, consider subscribing and sharing it with your friends.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK