

Pandas 的 Merge 函数详解
source link: https://www.51cto.com/article/763310.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

在日常工作中,我们可能会从多个数据集中获取数据,并且希望合并两个或多个不同的数据集。这时就可以使用Pandas包中的Merge函数。在本文中,我们将介绍用于合并数据的三个函数merge、merge_ordered、merge_asof。
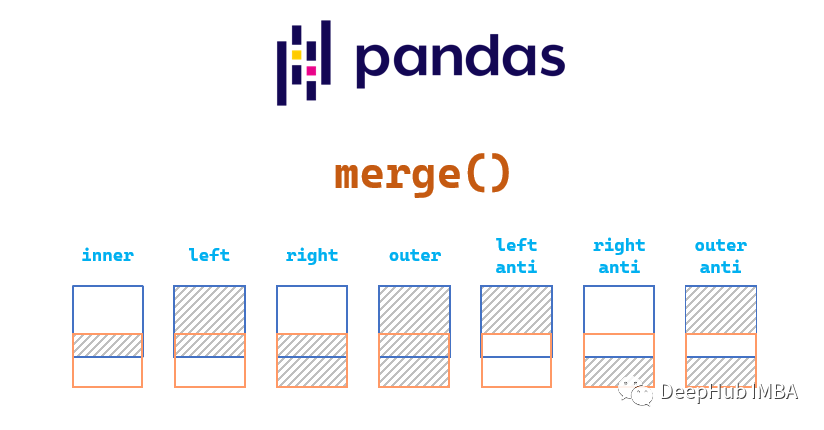
merge
merge函数是Pandas中执行基本数据集合并的首选函数。函数将根据给定的数据集索引或列组合两个数据集。
我们使用下面试示例:
import pandas as pd customer = pd.DataFrame({'cust_id': [1,2,3,4,5],
'cust_name': ['Maria', 'Fran', 'Dominique', 'Elsa', 'Charles'], 'country':
['German', 'Spain', 'Japan', 'Poland', 'Argentina']}) order =
pd.DataFrame({'order_id': [200, 201,202,203,204], 'cust_id':[1,3,3,4,2],
'order_date': ['2014-07-05', '2014-07-06', '2014-07-07', '2014-07-07',
'2014-07-08'], 'order_value': [10.1, 20.5, 18.7, 19.1, 13.5]})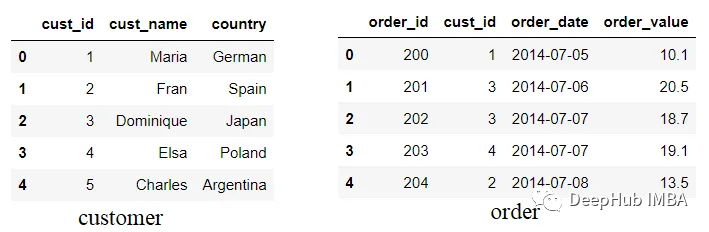
我们尝试模拟两个不同的数据集:客户和订单数据,其中cust_id列同时存在于两个DataFrame中。
pd.merge(customer, order)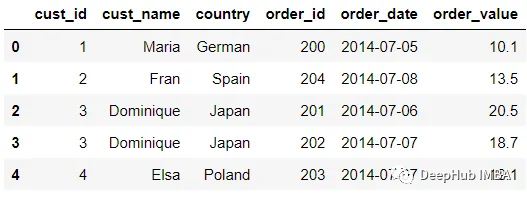
默认情况下,merge函数是这样工作的:
将按列合并,并尝试从两个数据集中找到公共列,使用来自两个DataFrame(内连接)的列值之间的交集。
列和索引合并
在上面合并的数据集中,merge函数在cust_id列上连接两个数据集,因为它是唯一的公共列。我们也可以指定要在两个数据集上连接的列名。
如果两个列的名称都存在于两个DataFrame中,则可以使用参数on。
pd.merge(customer, order, on = 'cust_id')结果与前面的示例类似,因为cust_id是唯一的公共列。但是如果两个DataFrame都包含两个或多个具有相同名称的列,则这个参数就很重要。
我们来创建一个包含两个相似列的数据。
customer = pd.DataFrame({'cust_id': [1,2,3,4,5], 'cust_name': ['Maria',
'Fran', 'Dominique', 'Elsa', 'Charles'], 'country': ['German', 'Spain', 'Japan',
'Poland', 'Argentina']}) order = pd.DataFrame({'order_id': [200,
201,202,203,204], 'cust_id':[1,3,3,4,2], 'order_date': ['2014-07-05',
'2014-07-06', '2014-07-07', '2014-07-07', '2014-07-08'], 'order_value': [10.1,
20.5, 18.7, 19.1, 13.5], 'country' : ['German', 'Indonesia', 'Armenia',
'Singapore', 'Japan'] })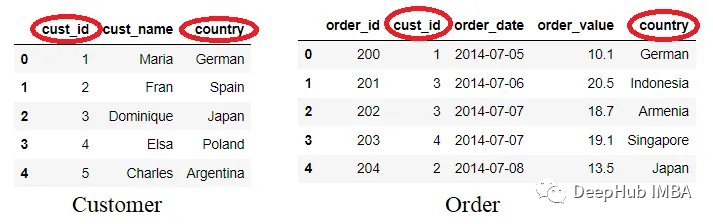
数据集现在包含两个名称相似的列:cust_id和country。让我们看看如果使用默认方法合并两个DataFrame会发生什么。
pd.merge(customer, order)
只剩下一行了,这是因为merge函数将使用与键名相同的所有列来合并两个数据集。所以现在是通过cust_id和country中找到的相同值来实现合并的。
还有一个问题,我们指定一个列后,其他的重复列(这里是country),现在存在country_x和country_y列。这两列是来自各自数据集的国家列。country_x来自Customer数据集,country_y来自Order数据集。
为了帮助区分合并过程中相同列名的结果,我们可以将一个元组对象传递给suffix参数。
pd.merge(customer, order, on ='cust_id', suffixes = ('_customer',
'_order'))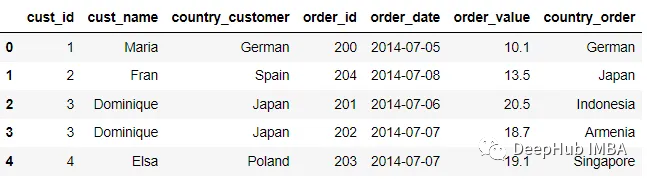
使用suffix参数,可以让我们避免混淆,或者在合并前我们直接将列改名
customer = customer.rename(columns = {'country':'customer_country'}) order =
order.rename(columns = {'country':'delivery_country'})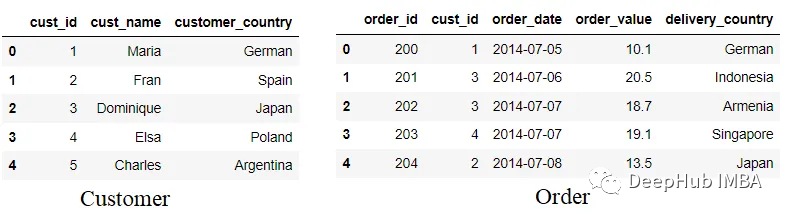
这样就不会造成混淆了。
然是如果我们要合并的列名在两个数据集不同时,on参数就没有效果了,这时就需要使用left_on和right_on参数,我们这里以刚刚改名的country列为例:
pd.merge(customer, order, left_on = 'customer_country', right_on =
'delivery_country', suffixes = ('_customer', '_order'))
在上面的代码中,我们将左侧数据集(Customer)上想要合并的列传递给left_on参数,将右侧数据集(Order)的列名传递给right_on参数。
left_on和right_on参数是串联工作的,因此我们不能在left_on参数中传递列名,而将right_on参数保留为空。
我们也可以使用left_index和right_index来替换left_on和right_on参数。right_index和left_index参数控制merge函数,以根据索引而不是列连接数据集。
pd.merge(customer, order, left_index = True, right_on = 'cust_id', suffixes =
('_customer', '_order'))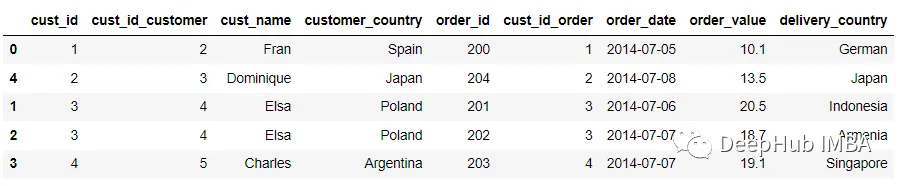
在上面的代码将True值传递给left_index参数,表示希望使用左侧数据集上的索引作为连接键。合并过程类似于下图。
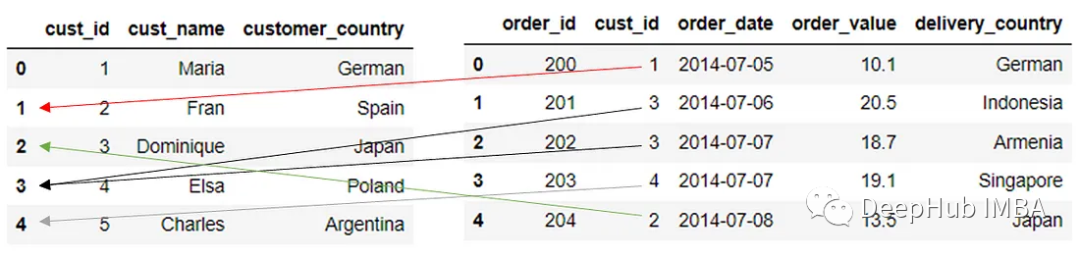
当我们按索引和列合并时,DataFrame结果将由于合并(匹配的索引)会增加一个额外的列。
合并类型介绍
默认情况下,当我们合并数据集时,merge函数将执行Inner Join。在Inner Join中,根据键之间的交集选择行。匹配在两个键列或索引中找到的相同值。
下图显示了Inner Join图,其中只选择了Customer和Order数据集上的列和/或索引之间匹配的值。
pd.merge(customer, order, left_on = 'customer_country', right_on =
'delivery_country', suffixes = ('_customer', '_order'), how = 'inner')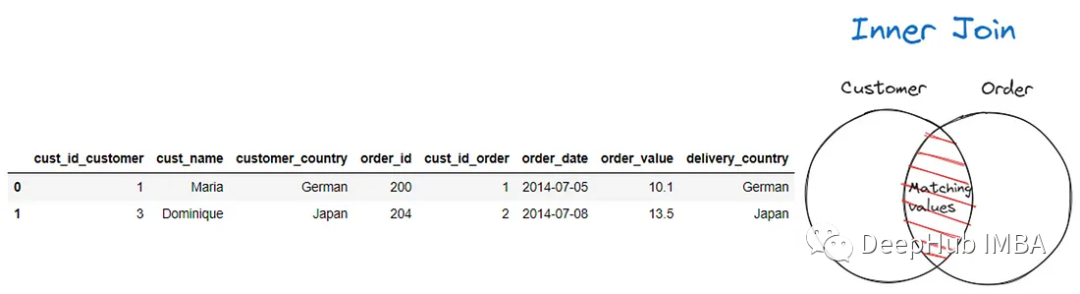
我们也可以使用左连接和右连接来保留想要的DataFrame。
pd.merge(customer, order, left_on = 'customer_country', right_on =
'delivery_country', suffixes = ('_customer', '_order'), how = 'left', indicator
= True)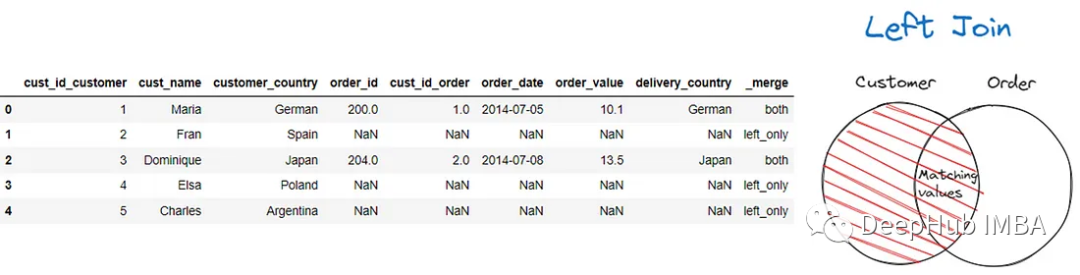
上面的代码,所有与订单数据值不匹配的客户数据值都用NaN值填充。
indicator=True参数,将创建_merge列。在上面的结果中,可以看到两个值都表明该行来自DataFrame和left_only的交集,其中该行来自第一个DataFrame(左侧)。
如果要执行右连接,可以使用以下代码。
pd.merge(customer, order, left_on = 'customer_country', right_on =
'delivery_country', suffixes = ('_customer', '_order'), how = 'right', indicator
= True)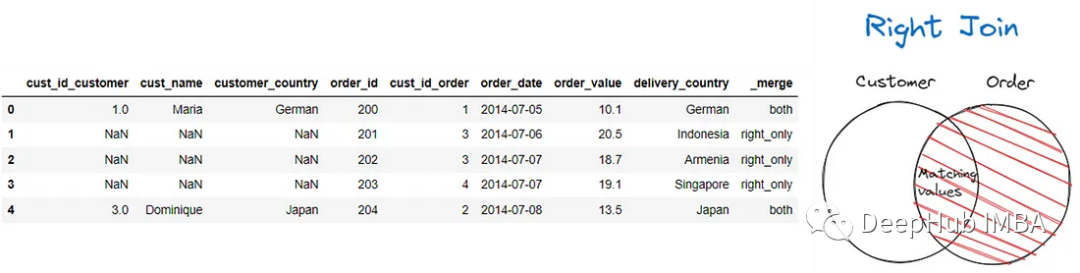
还可以在合并过程中使用外连接来保留两个DataFrame。我们可以把外连接看作是同时进行的左连接和右连接。
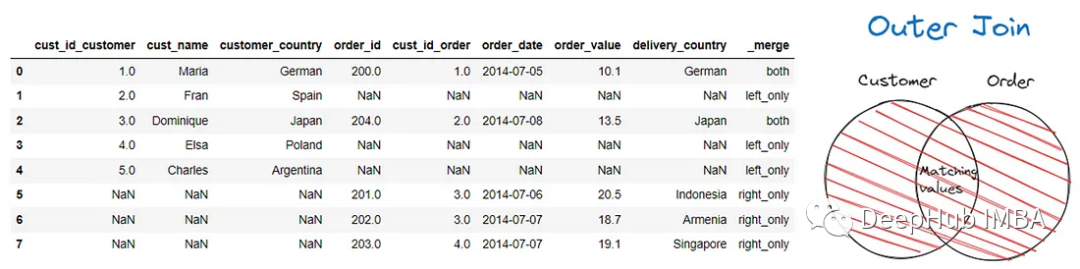
最后就是交叉连接,将合并两个DataFrame之间的每个数据行。
让我们用下面的代码尝试交叉连接。
pd.merge(customer, order, how = 'cross', suffixes = ('_customer',
'_order'))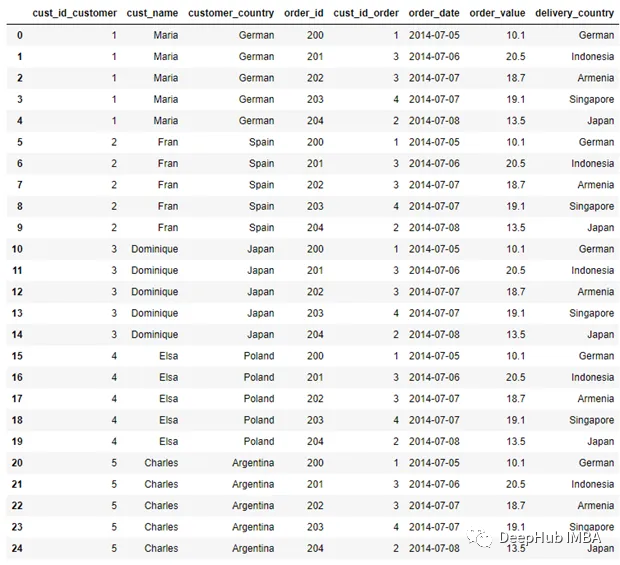
DataFrame将Customer数据中的每一行都与Order数据结合起来。
merge_ordered
在 Pandas 中,merge_ordered 是一种用于合并有序数据的函数。它类似于 merge 函数,但适用于处理时间序列数据或其他有序数据。merge_ordered 在合并时会保留原始数据的顺序,并且支持对缺失值进行处理。
pd.merge_ordered(customer, order)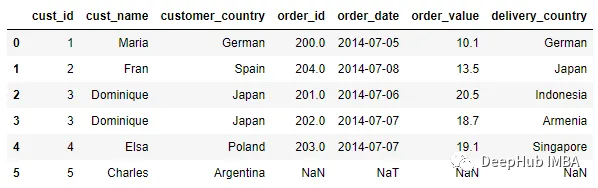
默认情况下,merge_ordered将执行Outer Join并根据连接键对数据进行排序。我们也可以像更改合并类型一样调整how参数。
merge_ordered是为有序数据(如时间序列)开发的。所以我们创建另一个名为Delivery的数据集来模拟时间序列数据合并。
order = pd.DataFrame({'order_id': [200, 201,202,203,204],
'cust_id':[1,3,3,4,2], 'order_date': ['2014-07-05', '2014-07-06', '2014-07-07',
'2014-07-07', '2014-07-08'], 'order_value': [10.1, 20.5, 18.7, 19.1, 13.5],
'delivery_country' : ['German', 'Indonesia', 'Armenia', 'Singapore', 'Japan'] })
delivery = pd.DataFrame({'delivery_date': ['2014-07-06', '2014-07-08',
'2014-07-09', '2014-07-10'], 'product': ['Apple', 'Apple', 'Orange',
'Orange']})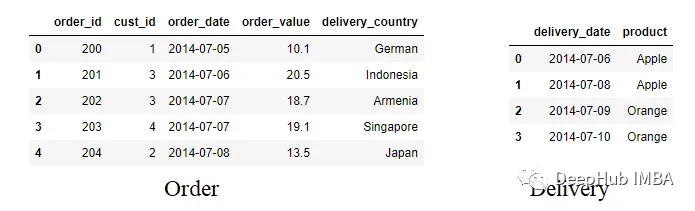
让我们假设delivery_date是投递时间,它包含与Order数据集中的order_date一起使用。另外就是我们还需要将日期列转换为datetime对象。
order['order_date'] = pd.to_datetime(order['order_date'])
delivery['delivery_date'] = pd.to_datetime(delivery['delivery_date'])让我们尝试按日期列合并两个数据集。
pd.merge_ordered(order, delivery, left_on = 'order_date', right_on =
'delivery_date')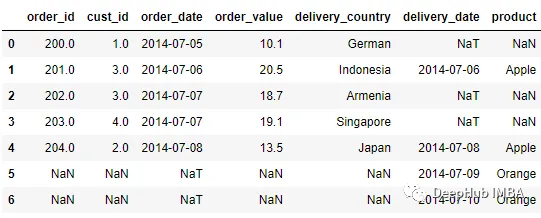
合并的DataFrame是按连接键排序的Order和Delivery数据集的Outer Join结果。
由于是外连接,一些数据点是空的。对于merge_ordered,有一个选项可以通过使用fill_method参数来填充缺失的值。
pd.merge_ordered(order, delivery, left_on = 'order_date', right_on =
'delivery_date', fill_method = 'ffill' )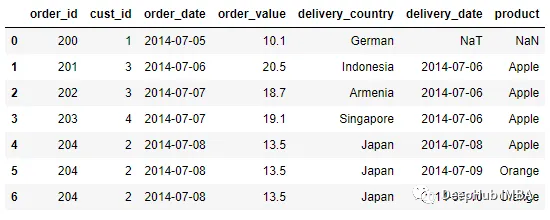
在上面的DataFrame中执行前向填充方法来计算缺失的值。
最后merge_ordered函数还可以基于数据集列执行DataFrame分组,并将它们一块一块地合并到另一个数据集。
pd.merge_ordered(order, delivery, left_on = 'order_date', right_on =
'delivery_date', right_by = 'product')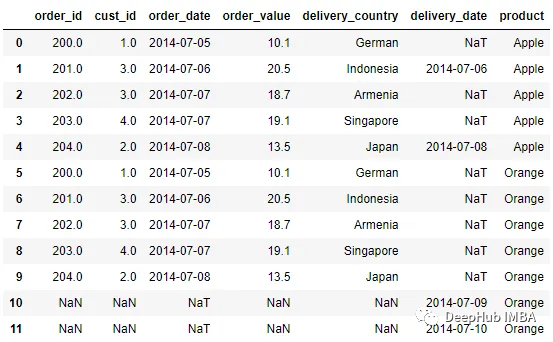
在上面的代码中将product列传递给right_by参数,这样product列中的每个值都映射到每个可用行,并且用于对数据进行分组的同一DataFrame中不存在的数据用NaN填充。
为了进一步理解,我们在合并之前添加日期来对数据进行分组。
pd.merge_ordered(order, delivery, left_on = 'order_date', right_on =
'delivery_date', right_by = ['delivery_date','product'])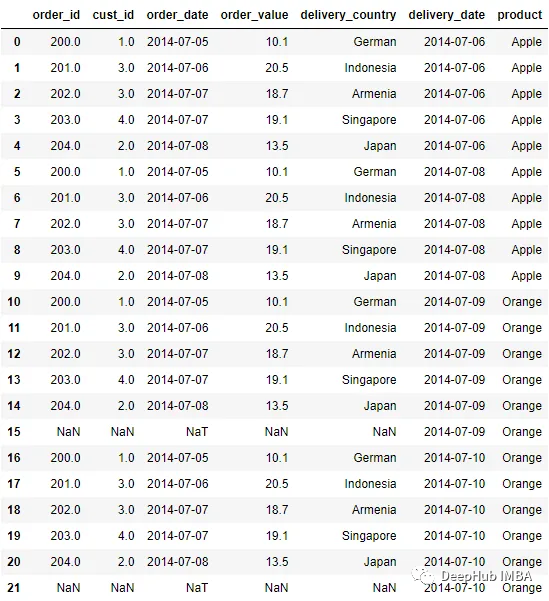
在上面的合并过程中,我们最终得到了4个不同的组:
['2014–07–06', 'Apple'], ['2014–07–08', 'Apple'], ['2014–07–09', 'Orange'],
['2014–07–10', 'Orange']该组基于所使用列中的现有行,因此它不是所有惟一值的组合。例如,没有[' 2014-07-09 ','Apple']组,因为此数据不存在。
在上面的DataFrame中可以看到Order数据集中的每一行都映射到Delivery数据集中的组。
merge_asof
merge_asof 是一种用于按照最近的关键列值合并两个数据集的函数。这个函数用于处理时间序列数据或其他有序数据,并且可以根据指定的列或索引按照最接近的值进行合并。
order = pd.DataFrame({'order_id': [199, 200, 201,202,203,204],
'cust_id':[1,1,3,3,4,2], 'order_date': ['2014-07-01', '2014-07-05',
'2014-07-06', '2014-07-07', '2014-07-07', '2014-07-08'], 'order_value': [11,
10.1, 20.5, 18.7, 19.1, 13.5], 'delivery_country' : ['Poland', 'German',
'Indonesia', 'Armenia', 'Singapore', 'Japan'] }) delivery =
pd.DataFrame({'delivery_date': ['2014-07-06', '2014-07-08', '2014-07-09',
'2014-07-10'], 'product': ['Apple', 'Apple', 'Orange', 'Orange']})使用merge_asof函数的一个注意事项是,必须按键对两个DataFrame进行排序。这是因为它将根据键的距离合并键,而未排序的DataFrame将抛出错误消息。
使用merge_asof类似于其他的合并操作,需要传递想要合并的DataFrame及其键名称。
pd.merge_asof(order, delivery, left_on = 'order_date', right_on =
'delivery_date')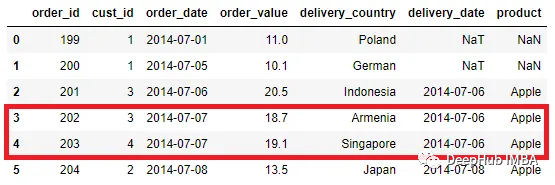
我们可以看到一些数据被合并了,但不是精确的值匹配。比如在第三行和第四行,order_date值为“2014-07-07”,但delivery_date为“2014-07-06”。
使用merge_asof会丢失数据。默认情况下它查找最接近匹配的已排序的键。在上面的代码中,与delivery_date不完全匹配的order_date试图在delivery_date列中找到与order_date值较小或相等的键。
delivery_date中小于等于order_date' 2014-07-07 '的值为' 2014-07-06 '。这就是为什么合并发生在这个键上。而order_date ' 2017-04-01 '和' 2017-04-05 '根本没有匹配,因为在delivery_date中没有小于或等于它们的值的值。
如果在正确的DataFrame中有多个重复的键,则只有最后一行用于合并过程。例如将更改delivery_date数据,使其具有多个不同产品的“2014-07-06”值。
delivery = pd.DataFrame({'delivery_date': ['2014-07-06', '2014-07-06',
'2014-07-08', '2014-07-10'], 'product': ['Apple', 'Orange', 'Apple',
'Orange']})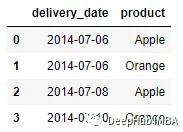
然后我们将执行与之前相同的合并过程。
pd.merge_asof(order, delivery, left_on = 'order_date', right_on =
'delivery_date')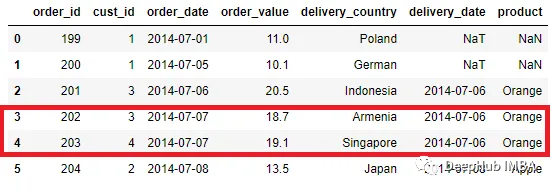
可以看到,合并过程对Orange产品而不是Apple产品使用delivery_date ,尽管两者具有相同的键值。另外具有精确匹配的键也会受到影响,它们会选择最后一行键。
可以通过设置allow_exact_matches=False来关闭精确匹配合并。
pd.merge_asof(order, delivery, left_on = 'order_date', right_on =
'delivery_date', allow_exact_matches = False)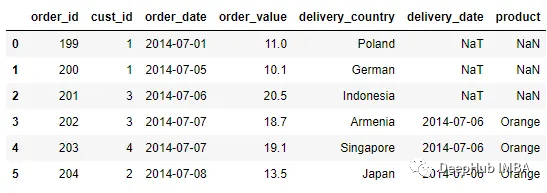
通过使用direction 参数来改变查找键的策略。例如使用向前策略:
pd.merge_asof(order, delivery, left_on = 'order_date', right_on =
'delivery_date', direction = 'forward')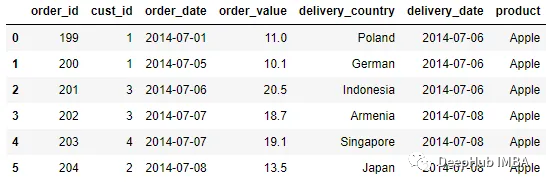
向前策略与向后策略类似,不同之处在于该函数将通过查看大于或等于正确DataFrame键的值来尝试合并。
另一个可以使用的策略是就近策略。在这个策略中使用向后或向前策略;取绝对距离中最近的那个。如果有多个最接近的键或精确匹配,则使用向后策略。
pd.merge_asof(order, delivery, left_on = 'order_date', right_on =
'delivery_date', direction = 'nearest')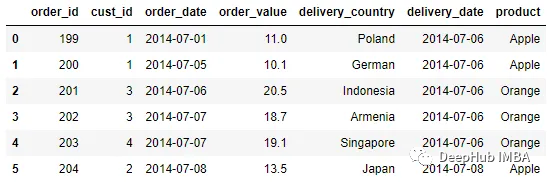
最后还可以通过使用tolerance 参数来控制键之间的距离。
pd.merge_asof(order, delivery, left_on = 'order_date', right_on =
'delivery_date', direction = 'forward', tolerance = pd.Timedelta(1, 'd'))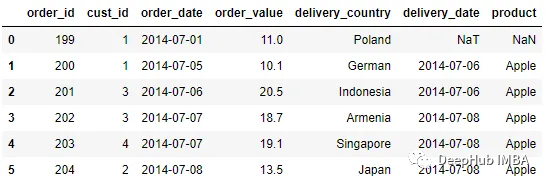
在上面的示例中,只有第一行包含缺失值。这是因为order_date第一行与最近的日期delivery_date之间的距离大于一天。第二行成功合并,因为只差一天。
Pandas函数提供了Merge函数可以轻松的帮助我们合并数据,而merge_ordered函数和merge_asof可以帮助我们进行更加定制化的合并工作,虽然这两个函数可能并不常见,但是它们的确在一些特殊的需求上非常的好用。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK