

贾佳亚团队提出LISA大模型:理解人话「分割一切」,在线可玩
source link: https://www.qbitai.com/2023/08/75031.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
贾佳亚团队提出LISA大模型:理解人话「分割一切」,在线可玩

能让LISA找Lisa的那种
金磊 整理自 凹非寺
量子位 | 公众号 QbitAI
分割一切这事,又有一项重磅研究入局。
香港中文大学终身教授贾佳亚团队,最新提出LISA大模型——理解人话,精准分割。

例如让AI看一张早餐图,要识别“哪个是橙子”是比较容易的,但若是问一句“哪个食物维他命C最高”呢?
毕竟这不是一个简单分割的任务了,而是需要先认清图中的每个食物,还要对它们的成分有所了解。
但现在,对于这种人类复杂的自然语言指令,AI已经是没有在怕的了,来看下LISA的表现:

不难看出,LISA精准无误的将橘子分割了出来。
再“投喂”LISA一张图并提问:
是什么让这位女士站的更高?请把它分割出来并解释原因。

从结果上来看,LISA不仅识别出来了“梯子”,而且也对问题做出了解释。
还有一个更有意思的例子。
许多朋友在看到这个大模型的名字,或许会联想到女子组合BLACK PINK里的Lisa。
贾佳亚团队还真拿她们的照片做了个测试——让LISA找Lisa:

不得不说,会玩!
基于LISA,复杂分割任务拿下SOTA
根据发布的论文来看,LISA是一个多模态大模型,它在这次研究中主攻的任务便是推理分割(Reasoning Segmentation)。
这个任务要求模型能够处理复杂的自然语言指令,并给出精细的分割结果。

如上图所示,推理分割任务具有很大的挑战性,可能需要借鉴世界知识(例如,左图需要了解“短镜头更适合拍摄近物体”),或进行复杂图文推理(如右图需要分析图像和文本语义,才能理解图中“栅栏保护婴儿”的含义),才能获得最终理想的分割结果。
尽管当前多模态大模型(例如Flamingo[1], BLIP-2[2], LLaVA[3], miniGPT-4[4], Otter[5])使得AI能够根据图像内容推理用户的复杂问题,并给出相应的文本分析和回答,但仍无法像视觉感知系统那样在图像上精确定位指令对应的目标区域。
因此,LISA通过引入一个<SEG>标记来扩展初始大型模型的词汇表,并采用Embedding-as-Mask的方式赋予现有多模态大型模型分割功能,最终展现出强大的零样本泛化能力。
同时,这项工作还创建了ReasonSeg数据集,其中包含上千张高质量图像及相应的推理指令和分割标注。
那么LISA这种精准理解人话的分割能力,具体是如何实现的呢?
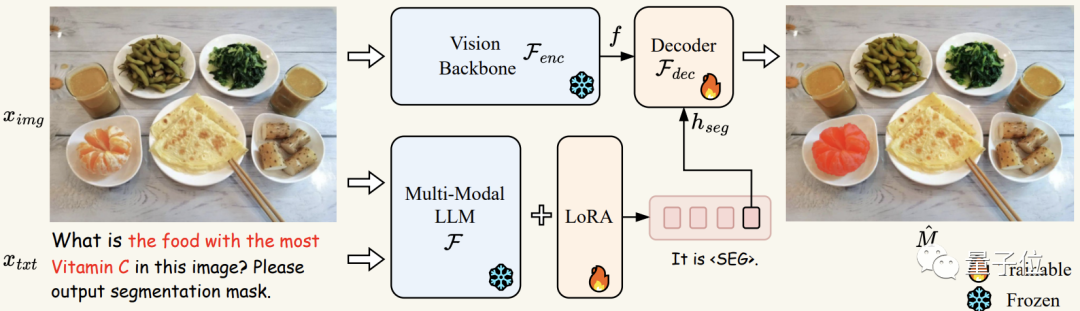
首先将图像ximg和文本xtxt送到多模态-大语言模型F(在实验中即LLaVA),得到输出的文本结果,如果此时文本结果包含<SEG>标记,则表示需要通过输出分割预测来解决当前问题。反之,若不包含<SEG>标记,则无分割结果输出。
如果存在标记,则将<SEG>标记在多模态大模型F最后一层对应的embedding经过一个MLP层得到hseg,并将其与分割视觉特征f一起传递给解码器Fdec(其中分割视觉特征f由输入编码器Fenc对图像ximg进行编码得到)。
最终,Fdec根据生成最终的分割结果M。
LISA在训练过程中使用了自回归交叉熵损失函数,以及对分割结果监督的BCE和DICE损失函数。
实验证明,在训练过程中仅使用不包含复杂推理的分割数据(通过将现有的语义分割数据如ADE20K[6],COCO-Stuff[7]以及现有指代分割数据refCOCO系列[8]中的每条数据转换成“图像-指令-分割Mask”三元组) ,LISA能在推理分割任务上展现出优异的零样本泛化能力。
此外,进一步使用239个推理分割数据进行微调训练还能显著提升LISA在推理分割任务上的性能。而且LISA还表现出高效的训练特性,只需在8张具有24GB显存的3090显卡上进行10,000次训练迭代,即可完成7B模型的训练。
最终,LISA不仅在传统的语言-图像分割指标(refCOCO、refCOCO+和refCOCOg)上展现出优异性能,还能处理以下分割任务情景:⑴复杂推理;⑵联系世界知识;⑶解释分割结果以及⑷多轮对话。

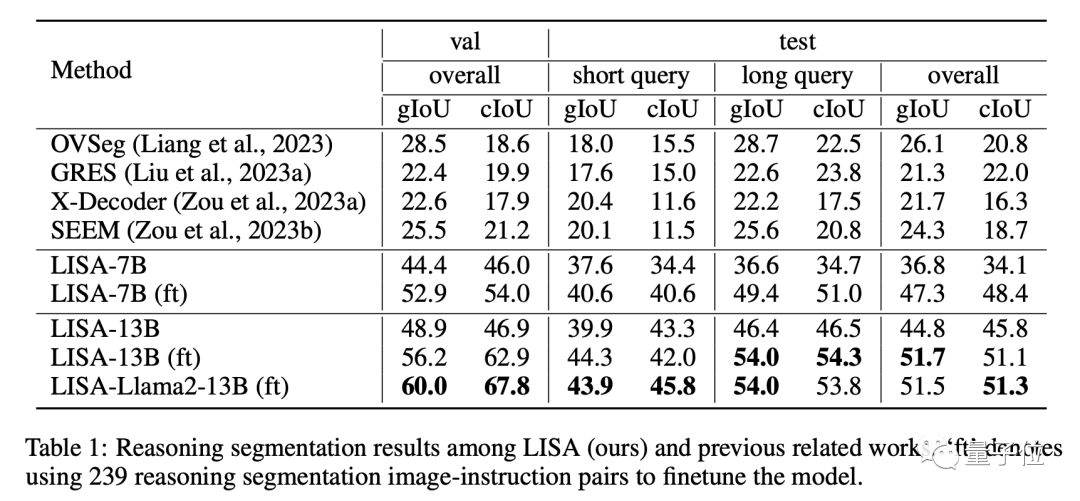
在有复杂情景的ReasonSeg数据集上,LISA显著领先于其他相关工作,进一步证明其出色的推理分割能力。
值得一提的是,LISA的推理分割能力已经出了demo,可以在线体验的那种。
操作也极其简单,只需填写“指令”,然后上传要处理的图像即可。
若是不会描述指令,Demo下方也给出了一些示例,小伙伴们也可以参照一下。
GitHub地址:
https://github.com/dvlab-research/LISA
论文地址:
https://arxiv.org/pdf/2308.00692.pdf
Demo地址:
http://103.170.5.190:7860/
参考链接:
[1] Alayrac, Jean-Baptiste, et al. “Flamingo: a visual language model for few-shot learning.” In NeurIPS, 2022.
[2] Li, Junnan, et al. “Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models.” In arXiv preprint, 2023.
[3] Liu, Haotian, et al. “Visual instruction tuning.” In arXiv preprint, 2023.
[4] Zhu, Deyao, et al. “Minigpt-4: Enhancing vision-language understanding with advanced large language models.” In arXiv preprint, 2023.
[5] Li, Bo, et al. “Otter: A multi-modal model with in-context instruction tuning.” In arXiv preprint, 2023.
[6] Zhou, Bolei, et al. “Scene parsing through ade20k dataset.” In CVPR, 2017.
[7] Caesar, Holger, Jasper Uijlings, and Vittorio Ferrari. “Coco-stuff: Thing and stuff classes in context.” In CVPR, 2018.
[8] Kazemzadeh, Sahar, et al. “Referitgame: Referring to objects in photographs of natural scenes.” In EMNLP, 2014.
Recommend
-
1
贾佳亚团队开源全球首个70B长文本大语言模型,读论文看小说直接ProMax 作者:金磊 2023-10-09 12:36:08 最近,香港中文大学贾佳亚团队联合MIT宣布了一项新研究,一举打破如此僵局。
-
1
北大团队搞出ChatExcel,说人话自动处理表格,免费且不限次使用量子位·2023-03-05 07:02“你是懂TNT的”看,输入想要干...
-
52
贾佳亚是 2017 年 5 月加入优图实验室,担任总经理一职的。1 年 3 个月之后,他以「可以看到、可以感受到、可以用到」为标准,精选了优图实验室的一众技术,在上海完成了实验室的第一次对外公开亮相。 这是一场非常罕见的、完全...
-
55
-
36
加入极市专业CV交流群,与 1 0000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流! 同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业...
-
0
两行代码,「三体」一次读完!港中文贾佳亚团队联手MIT发布超长文本扩展技术,打破LLM遗忘魔咒 作者:新智元 2023-10-09 14:17:00 大模型上下文从此不再受限!港中文贾佳亚团队联手MIT发布了全新超长文本扩展技术L...
-
1
两行代码解决大语言模型对话局限!港中文贾佳亚团队联合MIT发布超长文本扩展技术-品玩 业界动态 两行代码解决大语言模型对话局限!港中文贾佳...
-
16
CVPR 2020 oral 首次提出VPSnet用于分割界新问题-视频全景分割 Original...
-
2
AI分割一切!智源提出通用分割模型SegGPT,「一通百通」的那种
-
61
千万别养边牧,人话听多了容易成精
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK