

OpenAI just admitted it has a bot that crawls the web to collect AI training dat...
source link: https://finance.yahoo.com/news/openai-just-admitted-bot-crawls-211032730.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

OpenAI just admitted it has a bot that crawls the web to collect AI training data. If you don't block GPTbot, that's self-sabotage.

Spiderbots have been crawling the web for years collecting data.
Some of these bots have been helpful because they send users to sources of original content online.
The rise of generative AI and LLMs is undermining this grand internet bargain.
I hate spiders. When I traveled around the world in 2003, the thought of chunky, hairy arachnids creeping beneath my mosquito net kept me awake on many a tropical night.
Unbeknownst to most people, there are digital spiders crawling all over the websites you read and create. The most active one is probably Googlebot, which automatically collects web information so Google can later rank and serve it up in Search results.
Right now, there are several of these spiderbots crawling all over these words I wrote here, which is kinda creepy.
Some of these digital crawlers have also been incredibly helpful. Take the book I wrote about my travels in 2003. When Google's bot crawls my book webpage, I'm happy because when people later search for travel books they might be sent to my book. Maybe they'll buy it and read it.
This is the grand bargain that has made the internet economy thrive: Google scrapes your content and sends you traffic so you have an incentive to keep posting information online.
AI is undermining the grand web bargain
Now the rise of generative AI and large language models is undermining this deal. OpenAI recently admitted that it has one of these spiders crawling around the web. It's called GPTbot and it's being used to scrape and collect online content for AI model training. The next big model, GPT-5, will likely be trained on the data scooped up by this bot.
GPT-4, ChatGPT, and other powerful models cleverly answer questions immediately, so there's less need to send users to the sources of the original information. This may be a great user experience, but the incentives to share high-quality free information online begin to break down pretty quickly.
Why would any producer of free online content let OpenAI scrape its material when that data will be used to train future LLMs that later compete with that creator by pulling users away from their site? You can already see this in action as fewer people visit Stack Overflow to get software coding help.
 Fortune
FortuneA.I. can identify keystrokes by just the sound of your typing and steal information with 95% accuracy, new research shows
Researchers had artificial intelligence listen to the sounds of typing through a phone and over Zoom, with eerie results.
20h ago USA TODAY
USA TODAYKia has another hit electric vehicle on its hands with 2024 EV9 | Review
With features like mesh headrests and three rows of seats, the SUV that replaces Kia's popular Telluride will eventually be built in Georgia.
4h ago Fortune
FortuneCrypto heavyweights back new cybersecurity standards after nearly $4 billion was lost to hacks in 2022
Led by CAT Labs, the initiative would create an industry norm, with support from Fireblocks, Amphibian Capital, and Lockton.
1d ago Business Insider
Business InsiderNvidia stock is still a 'top pick' at Bank of America even after its stunning AI-driven 209% rally
"Demand isn't the issue, its supply and importantly the pace with which US cloud service providers are able to set up genAI compute instances."
2d ago TipRanks
TipRanksThis Is the Biggest Investment in High-Speed Internet Ever — and These Stocks Are Set to Reap the Rewards
At the end of June, the Biden Administration unveiled an ambitious goal to ensure reliable broadband internet access for the entire US, even the most remote rural areas. The project will involve a federal outlay of $42 billion, allocated to the states over the next two years. The President touts the initiative as a move to close the ‘digital gap’ that separates the haves and have-nots in the world of high-speed connectivity. “It’s the biggest investment in high-speed internet ever, because for t
13h ago CoinDesk
CoinDeskPayPal’s New Stablecoin and the ‘2 Wolves’ Inside Crypto
Here’s some confirmation that crypto isn’t entirely toxic: In the hours after internet payments pioneer PayPal announced a stablecoin on Ethereum, the company’s stock rallied 2%. Of course, as ever in the world of crypto, it’s not all sunshine and roses: After the surprise PYUSD stablecoin announcement, a bevy of imposter tokens like “pepeyieldunibotsatoshidoge” (aka PYUSD) have launched on Ethereum, various layer 2s and BNB Smart Chain looking to capitalize on post-announcement ignorance and buzz. This is an excerpt from The Node newsletter, a daily roundup of the most pivotal crypto news on CoinDesk and beyond.
20h ago Investor's Business Daily
Investor's Business DailyCybersecurity Stocks To Watch Amid Shift To AI, Cloud
Cybersecurity stocks have underperformed in 2023. But cloud security companies may be better positioned as corporate budgets tighten.
2d ago AP Finance
AP FinanceZoom, which thrived on the remote work revolution, wants workers back in the office part-time
Zoom, the video conferencing pioneer, is asking employees who live within a 50-mile radius of its offices to work onsite two days a week, a company spokesperson confirmed in an email. The statement said the company has decided that "a structured hybrid approach – meaning employees that live near an office need to be onsite two days a week to interact with their teams – is most effective for Zoom.” The new policy, which will be rolled out in August and September, was first reported by the New York Times, which said Zoom CEO Eric Yuan fielded questions from employees unhappy with the new policy during a Zoom meeting last week.
21h ago Engadget
EngadgetChina reportedly had ‘deep, persistent access’ to Japanese networks for months
Late last year, Nikkei Asia reported that Japan was planning to add thousands of personnel to its military cyber defense unit. Now, we might know why — according to a report from the Washington Post, hackers in China had "deep, persistent access" to Japanese defense networks. When the National Security Agency is said to have first discovered the breach in late 2020, NSA Chief and Commander of US Cyber Command General Paul Nakasone flew to Japan with White House deputy national security advisor Matthew Pottinger to report the breach to officials.
2d ago CoinDesk
CoinDeskBlockchain Security Firm Forta Upgrades Its Scam Detector to Battle Growing Crypto Fraud
Hundreds of millions of dollars have been lost to scams and exploits in July alone.
1d ago Reuters
ReutersTwo US lawmakers raise security concerns about Chinese cellular modules
WASHINGTON (Reuters) -Two U.S. lawmakers on Tuesday asked the Federal Communications Commission (FCC) to address questions about potential security concerns involving cellular modules made by Chinese companies including Quectel and Fibocom Wireless. The Republican chair of the House of Representatives China Select Committee, Mike Gallagher, and the panel's top Democrat, Raja Krishnamoorthi, in a letter to FCC Chair Jessica Rosenworcel raised alarm that U.S. medical equipment, vehicles and farm equipment could be accessed and controlled remotely from China if they use Chinese-made cellular modules.
21h ago Fortune
FortuneFormer Brex duo raises $5 million for new, pre-revenue A.I. agent startup meant to help fintech teams scale
AJ Asver and Miguel Rios-Berrios closed the round for Parcha AI in mid-July—a mere two months after publicly launching the company.
1d ago CoinDesk
CoinDeskBrevan Howard Backs Crypto Infrastructure Startup Puffer in $5.5M Round
The seed round for the liquid staking startup was co-led by Lemniscap and Lightspeed Faction.
22h ago News Direct
News DirectDeFi Lending Protocol Dolomite Launches ⚡Zap for One-Click Collateral
Dolomite, the lending protocol for efficient capital deployment, has announced ⚡Zap, a one-step collateral solution. This first-of-its-kind feature enables DeFi users to increase their collateral a...
22h ago AP Finance
AP FinanceWhite House holds first-ever summit on the ransomware crisis plaguing the nation's public schools
The White House on Tuesday held its first-ever cybersecurity “summit” on the ransomware attacks plaguing U.S. schools, in which criminal hackers have dumped online sensitive student data, including medical records, psychiatric evaluations and even sexual assault reports. “If we want to safeguard our children’s futures we must protect their personal data,” first lady Jill Biden, who is a teacher, told the gathering. “Every student deserves the opportunity to see a school counselor when they’re struggling and not worry that these conversations will be shared with the world.”
22h ago Zacks
ZacksSuper Micro Computer (SMCI) Surpasses Q4 Earnings and Revenue Estimates
Super Micro (SMCI) delivered earnings and revenue surprises of 3.24% and 0.92%, respectively, for the quarter ended June 2023. Do the numbers hold clues to what lies ahead for the stock?
15h ago Yahoo Finance
Yahoo FinanceESPN, PENN Entertainment strike $2 billion sports betting deal, Dave Portnoy buys back Barstool Sports
ESPN and PENN Entertainment struck a landmark sports betting deal on Tuesday that will see the Worldwide Leader in Sports join the sports betting space, with PENN also announcing it sold Barstool Sports back to its founder, Dave Portnoy.
53m ago Zacks
ZacksUpstart Holdings, Inc. (UPST) Q2 Earnings and Revenues Surpass Estimates
Upstart Holdings, Inc. (UPST) delivered earnings and revenue surprises of 200% and 1.39%, respectively, for the quarter ended June 2023. Do the numbers hold clues to what lies ahead for the stock?
15h ago Business Insider
Business InsiderBeer billionaire Jim Koch buys a random stock every 2 weeks - and trusts his former babysitter to execute his trades
Boston Beer Company's cofounder spent about $140 on two shares of Procter & Gamble more than six decades ago. They're worth $20,000 today.
17h ago TipRanks
TipRanksThe Future of Hydrogen Power Is Here — and These Stocks Are Leading the Charge
We’re in the midst of a major economic transition, one that may eventually match the changes of the Industrial Revolution. The change, of course, is the advent of the green economy, and the switch from fossil fuel energy sources to renewable energy. While wind and solar power are soaking up the headlines, a more plausible long-term green power source is already near at hand: hydrogen. Hydrogen, the most common element in the universe, is all around us – highly reactive and non-polluting. When us
2d ago TipRanks
TipRanks2 ‘Strong Buy’ Penny Stocks That Could Rally All the Way to $10 (or More)
Finding solid returns is the key to success in stock investing, but there are almost as many paths to that as there are investors. You can pack your portfolio with long-term stocks featuring slow appreciation; you can invest heavily in trending stocks that are riding a bubble, hoping to cash out at the right time; or you can buy into low-cost equities that feature high potential to boom. That last is the allure behind the penny stocks. Traditionally priced for a dollar or less per share, today t
1d ago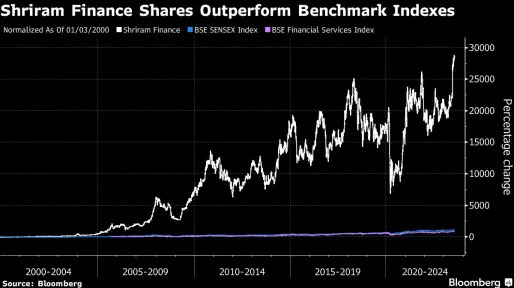 Bloomberg
BloombergTycoon Who Gave Away $750 Million Sees Profit in Loans to Poor
(Bloomberg) -- He built a fortune lending to low-income borrowers shunned by banks. He paid staff below-market wages and thought they still earned too much. He gave away almost all his wealth to a handful of employees, content with his small house and a $5,000 car.Most Read from BloombergEveryone Wants to Work at UPS After Teamsters DealWeWork Tumbles After Raising ‘Substantial Doubt’ About FutureTycoon Who Gave Away $750 Million Sees Profit in Loans to PoorTesla CFO Kirkhorn Exits With $590 Mil
14h ago Fortune
FortuneMillennials and Gen Z are filled with financial regrets, and it’s sending them into a stress spiral
Nothing hurts like an empty nest egg.
18h ago Investor's Business Daily
Investor's Business DailyThe CPI Inflation Rate Is Expected To Rise In July. Why The Federal Reserve Won't Care.
The annual CPI inflation rate is expected to rise in July. Here why investors shouldn't expect a Federal Reserve policy shift.
1h ago Investor's Business Daily
Investor's Business DailyJust 5 Stocks Produce 10% Of $75.7 Trillion Global Stock Market Wealth, Study Shows
5 stocks accounted for 10.3% of total global wealth created between 1990 and 2020. 159 stocks accounted for 50%.
23h ago CBS MoneyWatch
CBS MoneyWatchMoody's downgrades banks over risks. Here are the 10 impacted.
Ratings agency says its also watching some of nation's biggest lenders for possible cuts amid ongoing financial strain.
18h ago Business Insider
Business InsiderShort-seller Hindenburg has fueled a massive wealth wipeout for 3 of the world's richest men this year
Hindenburg Research has made high-profile bets against Gautam Adani, Jack Dorsey, and Carl Icahn in 2023.
19h ago Reuters
ReutersStruggling Chinese graduates return to hometowns as job market sags
BEIJING (Reuters) -A growing number of Chinese graduates are abandoning the bright lights of the country's mega-cities, with state media reporting almost half are returning to their hometowns within six months of graduation amid a sagging job market. Feeling the pinch of rising housing costs and a slowing economy, the jobless graduates are forfeiting cities that have traditionally provided a stepping stone to middle-class wealth. China's youth jobless rate jumped to a record 21.3% in June as offers during the traditional job-hunting season proved limited as the economy struggled and regulatory clamp-downs left the property, tech and education sectors bruised.
5h ago Investopedia
Investopedia5 Things to Know Before Markets Open
Shares of Penn Entertainment surged after it struck a branding deal with ESPN and shares of online loan provider Upstart dove after its lower-than-expected quarterly revenue forecast. Here’s what investors need to know today.
2h ago Zacks
ZacksTopgolf Callaway Brands (MODG) Surpasses Q2 Earnings Estimates
Topgolf Callaway (MODG) delivered earnings and revenue surprises of 18.18% and 0.68%, respectively, for the quarter ended June 2023. Do the numbers hold clues to what lies ahead for the stock?
14h ago Investor's Business Daily
Investor's Business DailyNvidia Reveals New AI Chip For Data Centers — Is NVDA Stock A Buy?
Nvidia continues to skyrocket on blowout earnings and guidance due to its AI leadership. But is NVDA a buy?
17h ago Benzinga
Benzinga'People Are So Silly': Joe Rogan Drinks Bud Light, Blasts Boycott Over Dylan Mulvaney During Podcast — Could This Be A Turning Point For The Battered Beer Brand?
Bud Light received mixed reactions after partnering with transgender social media influencer Dylan Mulvaney in April. But renowned podcaster and comedian Joe Rogan still enjoys the brew. In a recent episode of "The Joe Rogan Experience" podcast, he cracked open a can of Bud Light with country music star Zach Bryan. "And we're drinking Bud Lights, ladies and gentlemen. Sorry. There's nothing wrong with it," Rogan said. "People are so silly. We were just talking about silliness. One person made a
22h ago Investor's Business Daily
Investor's Business DailyEli Lilly Has A Big Stake In Weight Loss And Alzheimer's Drugs; But Is The Stock A Buy?
Eli Lilly surged 15% in one day on enthusiasm for weight-loss and Alzheimer’s drugs. But is LLY stock a buy now? Here's what you should know.
2h ago Zacks
ZacksPubMatic, Inc. (PUBM) Reports Q2 Loss, Tops Revenue Estimates
PubMatic, Inc. (PUBM) delivered earnings and revenue surprises of -22.22% and 5.69%, respectively, for the quarter ended June 2023. Do the numbers hold clues to what lies ahead for the stock?
16h ago Barrons.com
Barrons.comIt’s Disney Earnings Day. The Kingdom’s Magic Is Missing.
Wall Street has many worries, including softer demand for Disney+ and weak performance at the box office.
1h ago Bloomberg
BloombergOil Hits Fresh High for the Year on Simmering Black Sea Risks
(Bloomberg) -- Oil climbed to its highest in almost nine months on concern that a possible escalation of the conflict between Russia and Ukraine may hamper supplies in an already tightening market.Most Read from BloombergEveryone Wants to Work at UPS After Teamsters DealWeWork Tumbles After Raising ‘Substantial Doubt’ About FutureTycoon Who Gave Away $750 Million Sees Profit in Loans to PoorTesla CFO Kirkhorn Exits With $590 Million FortuneWall Street WhatsApp, Texting Fines Exceed $2.5 BillionW
50m ago Barrons.com
Barrons.comThese Stocks Are Moving the Most Today: Upstart, Penn, Marqeta, Lyft, Doximity, Rivian, Akamai, and More
Shares of Upstart fall sharply after the artificial-intelligence lending company issues a third-quarter earnings and revenue forecast that was below expectations, while Penn Entertainment surges after striking a deal with ESPN.
2h ago Investor's Business Daily
Investor's Business DailyCELH Stock Guzzles Big Gains After Drink Maker Trounces Views
Fitness, energy drink maker Celsius beat expectations with record Q2 sales late Tuesday. CELH stock rallied to all-time highs early Wednesday.
56m ago Bloomberg
BloombergTilray to Buy Eight Beverage Brands for $85 Million From AB InBev
(Bloomberg) -- Tilray Brands Inc. shares jumped the most since February 2021 after the cannabis and consumer packaged goods company agreed to buy eight beer and beverage brands from the owner of Budweiser.Most Read from BloombergEveryone Wants to Work at UPS After Teamsters DealWeWork Tumbles After Raising ‘Substantial Doubt’ About FutureTycoon Who Gave Away $750 Million Sees Profit in Loans to PoorTesla CFO Kirkhorn Exits With $590 Million FortuneWall Street WhatsApp, Texting Fines Exceed $2.5
17h ago Fortune
FortuneOver $200 billion of Apple’s market cap has vaporized since Thursday. Here’s what’s going on
“The gravity of a challenging smartphone market particularly in developed regions that should continue…is a headwind for the stock,” UBS analyst David Vogt said.
2d ago Zacks
ZacksThe Zacks Analyst Blog Highlights NVIDIA, Lam Research, NXP Semiconductors and ON Semiconductor
NVIDIA, Lam Research, NXP Semiconductors and ON Semiconductor are included in this Analyst Blog.
3h ago Investor's Business Daily
Investor's Business DailySuper Micro Computer Revenue Outlook Disappoints Amid AI Buzz
Super Micro Computer reported fiscal fourth-quarter results that topped views but shares plunged as its fiscal 2024 outlook disappointed.
17h ago Yahoo Finance
Yahoo FinanceStocks trending in afternoon trading: Beyond Meat, Eli Lilly, and Palantir
Several stocks moved near 20% in either direction on Tuesday afternoon following earlier earnings reports.
21h ago Yahoo Finance
Yahoo FinanceStocks attempt to recover with inflation, Disney in focus: Stock market news today
Stock futures rose Wednesday, looking to shake off losses driven by banking-sector worries, as attention shifted to a key US inflation report in the wake of disappointing Chinese price data.
6m ago Zacks
ZacksHere's What Key Metrics Tell Us About Doximity (DOCS) Q1 Earnings
While the top- and bottom-line numbers for Doximity (DOCS) give a sense of how the business performed in the quarter ended June 2023, it could be worth looking at how some of its key metrics compare to Wall Street estimates and year-ago values.
15h ago Zacks
ZacksZacks Industry Outlook Highlights Visa, Mastercard, Fidelity National, Global Payments and Equifax
Visa, Mastercard, Fidelity National, Global Payments and Equifax have been highlighted in this Industry Outlook article.
5h ago Barrons.com
Barrons.comPenn, Barstool Win in ESPN’s Betting Move. Why to Buy the Dip in Rival Gambling Stocks.
Shares in sports gambling names have fallen in the wake of Penn's $2 billion deal for ESPN rights.
2h ago SmartAsset
SmartAsset$600,000 Will Buy You This Much Retirement
One of the biggest worries associated with retirement planning is making sure you have enough money tucked away. While some people might aim to save $1 million or even $2 million for the future, your goal might be to save … Continue reading → The post How Long Will $600,000 Last in Retirement? appeared first on SmartAsset Blog.
1d ago Zacks
ZacksZacks Industry Outlook Highlights Freeport-McMoRan, Ero Copper, Energy Fuels and Coeur
Freeport-McMoRan, Ero Copper, Energy Fuels and Coeur have been highlighted in this Industry Outlook article.
5h ago Zacks
ZacksTeradata (TDC) Q2 Earnings Beat Estimates, Revenues Rise Y/Y
Teradata's (TDC) second-quarter 2023 results reflect the impacts of growing recurring, perpetual and consulting revenues.
21h ago Zacks
ZacksVeritone, Inc. (VERI) Reports Q2 Loss, Tops Revenue Estimates
Veritone, Inc. (VERI) delivered earnings and revenue surprises of -40% and 1.17%, respectively, for the quarter ended June 2023. Do the numbers hold clues to what lies ahead for the stock?
14h ago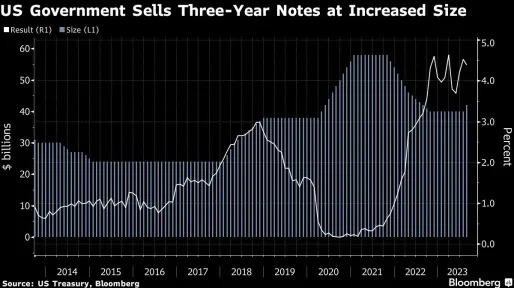 Bloomberg
BloombergTreasury Auctions Off to Good Start, With Strong Demand for Three-Year Notes
(Bloomberg) -- So far, so good for this week’s historic Treasury debt auctions — following trepidation last week when the announced sizes topped most bond dealer expectations.Most Read from BloombergEveryone Wants to Work at UPS After Teamsters DealWeWork Tumbles After Raising ‘Substantial Doubt’ About FutureWall Street WhatsApp, Texting Fines Exceed $2.5 BillionUS Bank Shares Drop as Moody’s Cuts Ratings, Warns on RisksTesla CFO Kirkhorn Exits With $590 Million FortuneTuesday’s $42 billion sale
18h ago Zacks
ZacksPalantir Earnings Review: Buy the Dip on a Leading AI Platform?
Palantir Technologies is one of the best opportunities for investors to get exposure to AI
16h ago Zacks
ZacksAxon Enterprise (AXON) Q2 Earnings and Revenues Beat Estimates
Axon (AXON) delivered earnings and revenue surprises of 79.03% and 7.79%, respectively, for the quarter ended June 2023. Do the numbers hold clues to what lies ahead for the stock?
16h ago Zacks
Zacks3 Intriguing Stocks to Buy After Earnings
With various scenarios, these top-rated stocks are appealing after reporting their Q2 results on Monday and should have more upside as we progress through 2023.
10h ago FX Empire
FX EmpireEUR/USD Forecast – Euro Pulls Back
The euro has fallen significantly during the trading session on Tuesday, as we continue to see a lot of noisy behavior.
1d ago Forkast News
Forkast NewsBitcoin, Ether rise near key levels, Sol leads gains across top 10 cryptos
Bitcoin and Ether rose during Wednesday afternoon trading in Hong Kong, along with all other top 10 non-stablecoin cryptocurrencies by market capitalization. With over 69% of Bitcoin supply inactive for over a year, long-term investors remain bullish on the world’s first cryptocurrency, industry experts told Forkast.
4h ago Investor's Business Daily
Investor's Business DailyThese Are The 5 Best Stocks To Buy And Watch Now
Buying a stock is easy, but buying the right stock without a time-tested strategy is incredibly hard. So what are the best stocks to buy now or put on a watchlist?
18h ago Investor's Business Daily
Investor's Business DailyDow Jones Chip Giant Intel, 3 Other Top Stocks To Buy And Watch
Dow Jones chip giant Intel, along with MercadoLibre and Lennar, are top stocks to buy and watch in today's stock market action.
22h ago Zacks
ZacksWynn Resorts (WYNN) to Report Q2 Earnings: What's in Store?
Wynn Resorts' (WYNN) second-quarter top line is likely to have benefited from strong demand for sports betting, non-gaming revenue-boosting strategies and expansion efforts.
2d ago Investor's Business Daily
Investor's Business DailyDow Jones Falls With 9 Big Earnings Movers; Roblox Crashes On Earnings
The Dow Jones dropped Wednesday morning, with nine big earnings movers. Roblox crashed 19% on weak earnings results.
3m ago Zacks
ZacksKulicke and Soffa (KLIC) Surpasses Q3 Earnings and Revenue Estimates
Kulicke and Soffa (KLIC) delivered earnings and revenue surprises of 66.67% and 0.43%, respectively, for the quarter ended June 2023. Do the numbers hold clues to what lies ahead for the stock?
15h ago American City Business Journals
American City Business JournalsToast to move headquarters to Fort Point from Fenway
Early next year, the company will move into a brick-and-beam office building now occupied by GoTo, formerly known as LogMeIn.
14h ago Barrons.com
Barrons.comTesla CFO Departure Means Stock Sales Could Be Coming
Outgoing Tesla Chief Financial Officer Zachary Kirkhorn is the beneficial owner of about 2.7 million shares of Tesla stock. He could choose to monetize them soon.
22h ago Zacks
ZacksThe Zacks Analyst Blog Highlights M&T Bank, Associated Banc-Corp, U.S. Bancorp, Truist Financial and Capital One
M&T Bank, Associated Banc-Corp, U.S. Bancorp, Truist Financial and Capital One are included in this Analyst Blog.
5h ago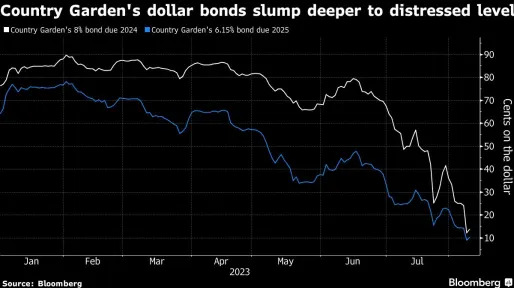 Bloomberg
BloombergCountry Garden Is in Danger of a Default Rivaling Evergrande
(Bloomberg) -- A debt crisis that rivals China Evergrande Group’s default may be brewing in the world’s second-largest economy.Most Read from BloombergEveryone Wants to Work at UPS After Teamsters DealWeWork Tumbles After Raising ‘Substantial Doubt’ About FutureTycoon Who Gave Away $750 Million Sees Profit in Loans to PoorTesla CFO Kirkhorn Exits With $590 Million FortuneWall Street WhatsApp, Texting Fines Exceed $2.5 BillionCountry Garden Holdings Co., helmed by one of China’s richest women, Ya
4h ago Reuters
ReutersBond traders prepare to brave 'painful' yield curve bets as rate hikes slow
Bond traders are eyeing a return to a type of trade that left them battered earlier this year - betting on yield curves returning to a more normal shape as slowing economies force central banks to cut interest rates. The shape of the yield curve has been in the spotlight over the last week, with U.S. and European 10-year bond yields rising sharply compared to their shorter-dated peers. Many investors say the big rush into such wagers will come when central banks look poised to cut interest rates to bolster growth.
9h ago Zacks
Zacks3D Systems (DDD) Reports Q2 Loss, Lags Revenue Estimates
3D Systems (DDD) delivered earnings and revenue surprises of 0% and 4.51%, respectively, for the quarter ended June 2023. Do the numbers hold clues to what lies ahead for the stock?
2h ago AP Finance
AP FinanceCampbell is buying Rao’s. Fans are worried, but the soup maker says it won't touch the sauce
Campbell Soup is set to buy Sovos Brands, the maker of Rao’s pasta sauces. In a Monday announcement, the two companies said they had entered an agreement for Campbell's to acquire Sovos for $23 per share in cash — reflecting a total value of about $2.7 billion. The transaction will help diversify and strengthen Campbell’s Meals & Beverages division, Campbell’s President and CEO Mark Clouse said in a statement.
1d ago Investor's Business Daily
Investor's Business DailyBest Stocks To Buy And Watch Now: Broadcom Headlines 5 Top Tech Stocks For August 2023
The best stocks to buy and watch in the tech sector aren't in large supply these days. Here's a look at some of the best performers.
23h ago Skift
SkiftTUI Returns to Profit, Eyes Shifts From Extreme Weather
TUI is acutely aware that its holiday package tours could be prone to seasonality shifts, as the group has just had to deal with the impact of severe weather warnings and wildfires. Despite all this and rising prices, travel demand from its main markets remains strong.
1h ago The Wall Street Journal
The Wall Street JournalWeWork Raises Doubt About Its Survival
WeWork on Tuesday raised doubt about its ability to stay in business as the co-working space provider faces losses and a dwindling cash pile amid major changes in the way people work.
14h ago Benzinga
Benzinga3 REITS That Beat The Estimates On Forward Guidance
A common occurrence during earnings season is that companies that report favorable quarterly earnings may still experience a decline in share price. An earnings report signifies the results of the past three months, but it's often forward guidance falling short of the Wall Street consensus estimate that's the reason for a price decline. Conversely, when a company surpasses expectations in its guidance range, its stock price usually increases as investors react positively to the better-than-antic
1d ago Investor's Business Daily
Investor's Business Daily10 S&P 500 Stocks Completely Crushed This Earnings Season
When it comes to corporate earnings, good isn't good enough. What matters is making more than expected — some S&P 500 just pulled it off.
2h ago The Telegraph
The TelegraphGerman electric cars are too expensive, top economic adviser to Berlin admits
German car makers must do more to make electric vehicles cheaper and more appealing because manufacturers are losing out to China, the head of Berlin’s top group of economic advisers has warned.
1d ago Bloomberg
BloombergInternational Flavors Drops 20% on Softening Consumer Demand
(Bloomberg) -- International Flavors and Fragrances Inc. posted its biggest drop since at least 1980 after slashing its full-year sales guidance as customers pull back on spending while working through their stashes of products instead of replenishing their pantries. Most Read from BloombergUS Bank Shares Drop as Moody’s Cuts Ratings, Warns on RisksWall Street WhatsApp, Texting Fines Exceed $2.5 BillionMusk Says He May Need Surgery, Will Get MRI on Back and NeckThe Global South Breaks Away From
23h ago Zacks
ZacksBackblaze, Inc. (BLZE) Reports Q2 Loss, Tops Revenue Estimates
Backblaze, Inc. (BLZE) delivered earnings and revenue surprises of 7.69% and 1.33%, respectively, for the quarter ended June 2023. Do the numbers hold clues to what lies ahead for the stock?
15h ago Fox Business
Fox BusinessDisney battle with Ron DeSantis one of investors' top issues
Disney will have the attention of many investors come Wednesday when it puts outs its latest set of quarterly results. FOX Business takes a look at some top issues for investors.
14h ago Reuters
ReutersTarget sued by investor over backlash to LGBTQ merchandise
A conservative legal organization sued Target on Tuesday on behalf of an investor, saying the retailer misrepresented the adequacy of its risk monitoring when customer backlash over LGBTQ-themed merchandise caught it by surprise. America First Legal filed the lawsuit in Florida federal court on behalf of investor Brian Craig against Target, chief executive Brian Cornell and the company's board of directors. America First is a nonprofit group headed by Stephen Miller, a former adviser to ex-President Donald Trump.
13h ago American City Business Journals
American City Business JournalsNovavax reports surprise Q2 profit but reiterates 'going concern' warning
The Gaithersburg biotech says a successful fall launch of a new Covid-19 vaccine could be crucial to its survival.
19h ago
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK