

我真的想知道,AI编译器中的IR是什么? - ZOMI酱酱
source link: https://www.cnblogs.com/ZOMI/p/17578148.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

随着深度学习的不断发展,AI 模型结构在快速演化,底层计算硬件技术更是层出不穷,对于广大开发者来说不仅要考虑如何在复杂多变的场景下有效的将算力发挥出来,还要应对 AI 框架的持续迭代。
AI 编译器就成了应对以上问题广受关注的技术方向,让用户仅需专注于上层模型开发,降低手工优化性能的人力开发成本,进一步压榨硬件性能空间。IR对于AI编译器来说是非常重要的一种数据结构鸭!!!
IR 中间表达
什么是IR
IR(Intermediate Representation)中间表示,是编译器中很重要的一种数据结构。编译器在完成前端工作以后,首先生成其自定义的 IR,并在此基础上执行各种优化算法,最后再生成目标代码。
从广义上看,编译器的运行过程中,中间节点的表示,都可以统称为 IR。从狭义上讲编译器的 IR,是指该编译器明确定义的一种具体的数据结构,这个数据结构通常还伴随着一种语言来表达程序,这个语言程序用来实现这个明确定义的 IR。大部分时间,不太严格区分这个明确定义的 IR 以及其伴随的语言程序,将其统称为 IR。
如图所示,在编译原理中,通常将编译器分为前端和后端。其中,前端会对所输入的程序进行词法分析、语法分析、语义分析,然后生成中间表达形式 IR。后端会对 IR 进行优化,然后生成目标代码。
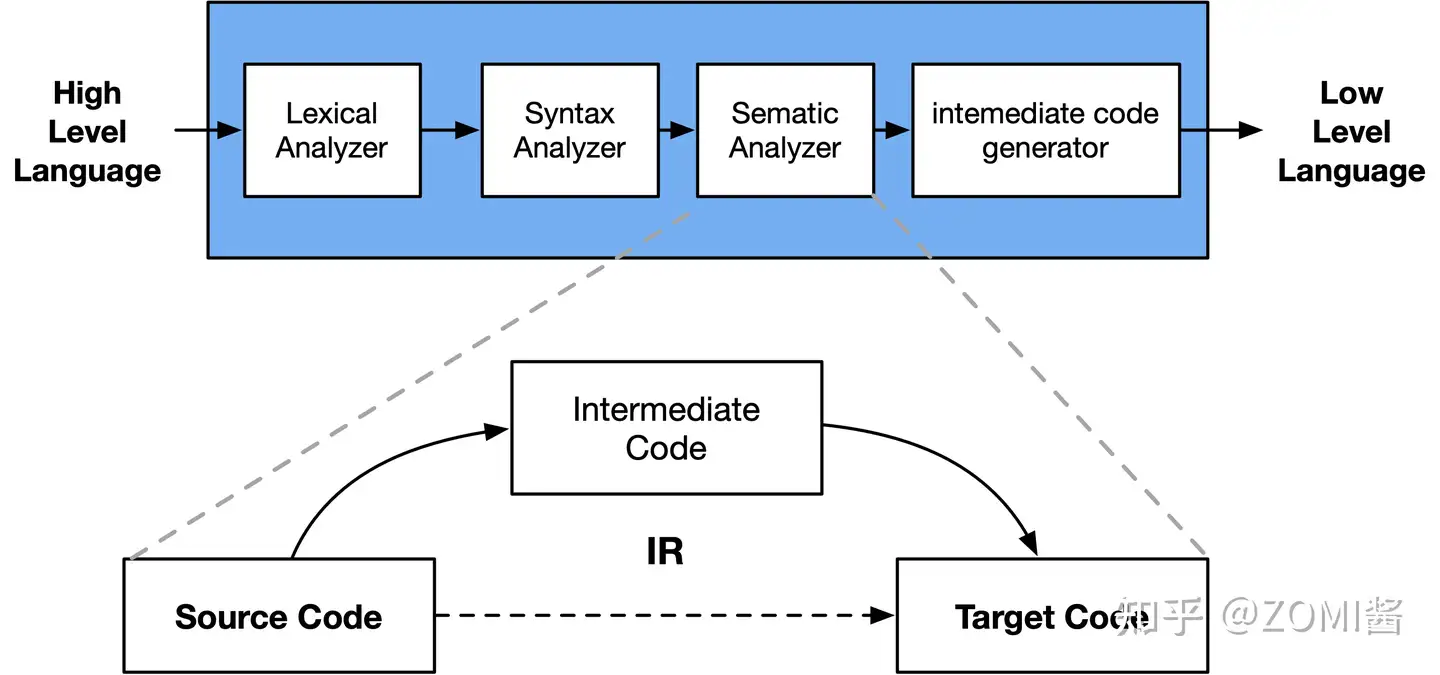
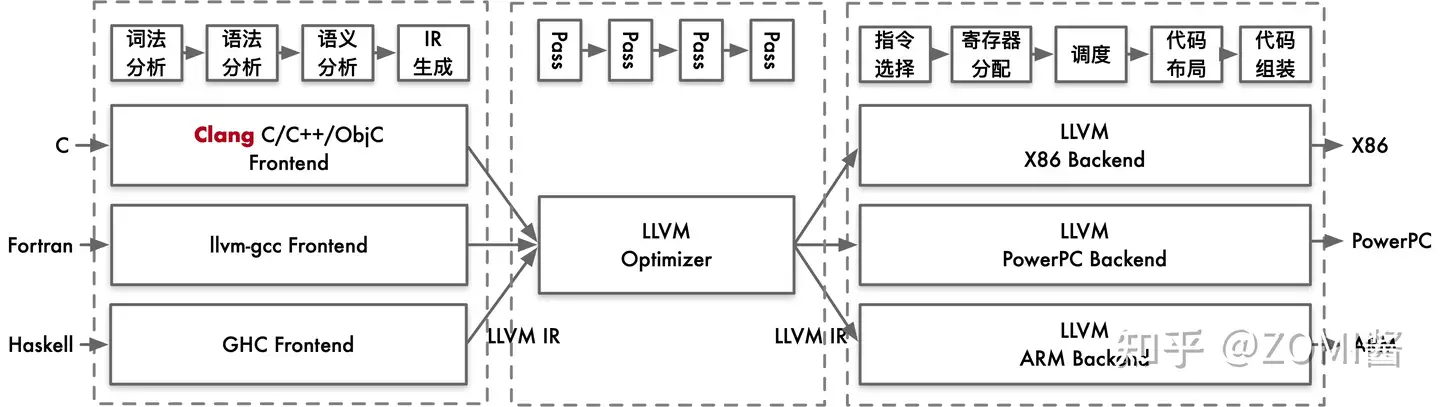
例如:LLVM 把前端和后端给拆分出来,在中间层明确定义一种抽象的语言,这个语言就叫做 IR。定义了 IR 以后,前端的任务就是负责最终生成 IR,优化器则是负责优化生成的IR,而后端的任务就是把 IR 给转化成目标平台的语言。LLVM 的 IR 使用 LLVM assembly language 或称为 LLVM language 来实现 LLVM IR的类型系统,就指的是 LLVM assembly language 中的类型系统。
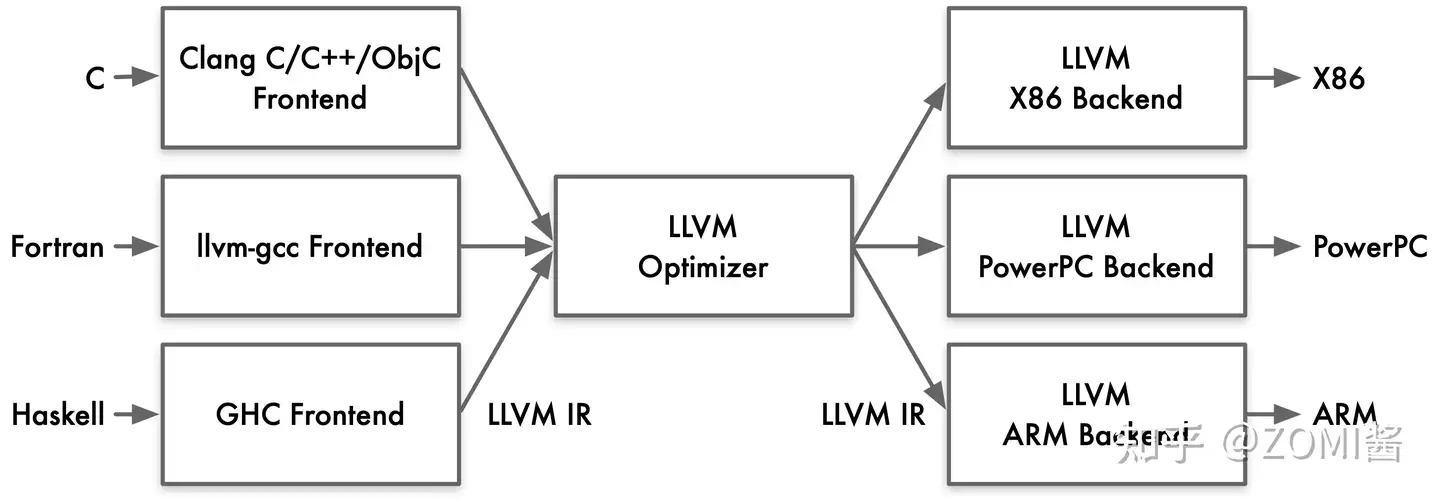
因此,编译器的前端,优化器,后端之间,唯一交换的数据结构类型就是 IR,通过 IR 来实现不同模块的解耦。有些IR还会为其专门起一个名字,比如:Open64的IR通常叫做WHIRL IR,方舟编译器的IR叫做MAPLE IR,LLVM则通常就称为LLVM IR。
IR的定义
IR 在通常情况下有两种用途,1)一种是用来做分析和变换,2)一种是直接用于解释执行。
编译器中,基于 IR 的分析和处理工作,前期阶段可以基于一些抽象层次比较高的语义,此时所需的 IR 更接近源代码。而在编译器后期阶段,则会使用低层次的、更加接近目标代码的语义。基于上述从高到低的层次抽象,IR 可以归结为三层:高层 HIR、中间层 MIR 和 底层 LIR。
HIR(High IR)高层 IR,其主要负责基于源程序语言执行代码的分析和变换。假设要开发一款 IDE,主要功能包括:发现语法错误、分析符号之间的依赖关系(以便进行跳转、判断方法的重载等)、根据需要自动生成或修改一些代码(提供重构能力)。此时对 IR 的需求是能够准确表达源程序语言的语义即可。
其实,AST 和符号表就可以满足上述需求。也就是说,AST 也可以算作一种特殊的 IR。如果要开发 IDE、代码翻译工具(从一门语言翻译到另一门语言)、代码生成工具、代码统计工具等,使用 AST(加上符号表)即可。基于 HIR,可以执行高层次的代码优化,比如常数折叠、内联关联等。在 Java 和 Go 的编译器中,有不少基于 AST 执行的优化工作。
MIR(Middle IR),独立于源程序语言和硬件架构执行代码分析和具体优化。大量的优化算法是通用的,没有必要依赖源程序语言的语法和语义,也没有必要依赖具体的硬件架构。这些优化包括部分算术优化、常量和变量传播、死代码删除等,实现分析和优化功能。
因为 MIR 跟源程序代码和目标程序代码都无关,所以在编译优化算法(Pass)过程中,通常是基于 MIR,比如三地址代码(Three Address Code,TAC)。
三地址代码 TAC 的特点:最多有三个地址(也就是变量),其中赋值符号的左边是用来写入,右边最多可以有两个地址和一个操作符,用于读取数据并计算。
LIR(Low IR),依赖于底层具体硬件架构做优化和代码生成。其指令通常可以与机器指令一一对应,比较容易翻译成机器指令或汇编代码。因为 LIR 体现了具体硬件(如 CPU)架构的底层特征,因此可以执行与具体 CPU 架构相关的优化。
多层 IR 和单层 IR 比较起来,具有较为明显的优点:
- 可以提供更多的源程序语言的信息
- IR表达上更加地灵活,更加方便优化
- 使得优化算法和优化Pass执行更加高效
如在 LLVM 编译器里,会根据抽象层次从高到低,采用了前后端分离的三段结构,这样在为编译器添加新的语言支持或者新的目标平台支持的时候,就十分方便,大大减小了工程开销。而 LLVM IR 在这种前后端分离的三段结构之中,主要分开了三层 IR,IR 在整个编译器中则起着重要的承上启下作用。从便于开发者编写程序代码的理解到便于硬件机器的理解。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK