

CMDB平台建设指南
source link: https://wiki.eryajf.net/pages/4bcf72/#%E6%9C%80%E5%90%8E
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

本文写就于2022年,是本人在CMDB领域的钻研探索实践之后的一些经验分享,全文约计1.7w字,凝聚了我全部的心血,从平台架构的设计,到项目周期的管理,甚至项目完成之后的推广,都有所涉猎,如果你也在折腾CMDB,那么本文是你不可错过的入门必读之作。
同时:我们的团队基于各个领域的实践,汇集成了一本《高性能之道--SRE视角下的运维架构实践》 (opens new window),欢迎大家购买品读。

# 前言
我们的运维团队汇聚了一群优秀的,富有想法的年轻人。每次周会里边,当我们完成了各自日常工作的交流沟通之后,总是会跳出当下,天南海北,胡言乱语地头脑风暴一番。
在这些看似 闲笔 的沟通当中,我们进行了大量的运维规范以及最佳实践的讨论,而当我们进行地讨论越多,越能够发现一个问题,无论是对于一个全流程(指一个项目的整个生命周期)命名的规范约束落地,还是对发布平台以应用维度的主机列表维护,都步步绕不开一个能够真正解决运维痛点的 CMDB 平台。
注意,这里在 CMDB 这个名词的前边加了一个定语,真正解决运维痛点。
事实上在这之前,我们并非没有做过 CMDB 平台的建设,只不过由于我们以往对这一概念的认知不足,完全交由运维开发同学,按他的一些经验想法开发出来的 CMDB,却总是难以真正在实际运维生产当中落地,简而言之就是,CMDB 平台做过,但都失败了。
我想,失败的原因大概有如下三点:
- 第一:没有比较好的理论方向做支撑,从而使得开发者通常都是照着 Excel 管理的思路转移到 web 平台上,真正能够解决的实际问题并不多。
- 第二:以开发视角主导的平台建设,总是会给运维以
何不食肉糜的感觉,当然这里没有丝毫揶揄开发的意思,真正好的平台其实还是需要开发来把想法实现,只是从客观事实呈现的效果来看,的确会走向这样一个窘境。 - 第三:从运维人员的角度来讲,只是在一开始说需要一个某某某平台,然后就坐等着开发将一个令自己满意的平台交付出来,这对于开发者而言,同样会有一些
何不食肉糜的感觉。人言说鞋子合不合适只有脚知道,如果一个平台的最终使用者从来没有参与过平台的建设,那么最终这个平台也的确很难做到令其满意。
实际上,在公司里边造的轮子,通常很难会被判定为失败,这里边包含很多现实的原因,公司能不能够勇敢地站出来知错认错改错,通常取决于领导人的魄力。很多时候阻碍我们成长发展的,正是那些被太多本不应掺杂其中的表面因素给影响的,可能我们司空见惯了实事求是这个词儿,从而觉得这个词儿的落地也是顺理成章的事情,但,我们的确经常会因为没能做到实事求是,以至于鞋子不合脚也会说服自己让脚去适应鞋子,而忘记了穿一双鞋子的本质是为了让脚舒服。
没错,有时候阻碍我们成功的唯一因素,可能就是实事求是。当然这里并不是哲学思想研讨会,我不会对这一理论做过多深入分析,简单一提算是抛砖引玉,让我们在意识中埋下一条行事准则,接下来还是回到 CMDB 平台建设的分享上来。
对于建设 CMDB 平台而言,实事求是的指导意义就在于,我们能够认真审视上边提到的失败的每一个原因,而我也会在接下来的内容当中,时不时地回来过剖析,实际推进设计,开发平台的过程与以上问题的碰撞。
这里我要感谢我的领导,能够勇于认识到以往平台建设的问题,并勇于启用我作为新阶段平台建设的主负责。
# 了解 CMDB
# 是什么
之所以说领导启用我是一种勇敢,是因为我在这之前并没有任何 CMDB 平台建设的经验心得,这次受命,则完全是从零基础开始。
因此这里也提前与大家露个怯,我并不算是 CMDB 领域的专家,仅仅是经历过一个平台建设,收获了一些心得,不揣愚昧与大家做一个交流分享,每家公司的运维架构以及实际需求场景都各不相同,这里仅是针对一些比较有共性的底层设计,以及平台建设过程与实际落地应用之间的问题,做一些分享。
当我接到这个任务之后,首先去了解了一下 CMDB 的概念,CMDB(Configuration Management Database)即配置管理数据库,或者叫资产管理系统。网上还有从这个概念发散出来的一大堆名词概念,一番查阅之后,我如坠五里雾之中,变得更加迷茫与模糊,好在之前一直有关注行业内一些前沿动态,多少了解一些开源的 CMDB 平台,当我把这些平台部署起来,真切体验之后,才慢慢形成了一些个人对 CMDB 平台的理解和方向上的把控。
在这里要首先感谢这些开源项目,正是他们将自己在这个领域的超前认知以及凝聚心血的智慧开源出来,才使得我们能够站在巨人的肩膀上思索当下的问题。
- 腾讯蓝鲸:https://github.com/Tencent/bk-cmdb
- OpsAny 社区版:http://www.opsany.com
我们的 CMDB 平台建设,底层设计思路很多地方参考如上两个平台,但也并非只是简单地拾人牙慧,我在一开始部署体验这些平台,阅读了其中全部文档之后,又结合了自己业务中的实际场景和问题,做了重新的梳理设计,这些内容在后边都会一一呈现。
最后表明一下我个人心中对 CMDB 的理解:
- 从使用角度来看,首先 CMDB 平台要解决运维乃至研发在日常工作中的基础查询需求,这是我们日常工作中应用频率最高的场景,其次,CMDB 平台也应该作为运维规范,流程固化实施推行的舞台。
- 从核心设计来看,CMDB 要以资源数据为中心,将运维同学真正关心的云上数据以及本地数据简单快捷地在平台上维护起来;CMDB 最终以应用为核心,成为本地应用与云端服务器域名数据库等资源关联起来的桥梁。
能够做好这两点,我想,这个平台距离真正解决运维痛点,也就不远了。
本节内容也将会围绕这些问题,平铺展开。
# 为什么
事实上我在组织部门成员第一次碰面会之前,就遇到过其他开发同学问过这样的问题:CMDB 好干啥?
我当时用运维实际日常工作的一个小场景对此做了解释,大家也可以看看自己在日常运维工作中有没有这样的痛点。
我当时这样回答:举个例子,你有没有遇到过这样一个问题,你知道客户端服务所在主机,现在的需求是要在服务端入口对客户端请求加白名单,但是客户端主机走的是统一的 NAT 出口,这个操作的流程会是什么样呢?
- 以往的流程
- 登陆云平台 --> 搜索该客户端主机 --> 主机详情中看到子网 ID,点击链接跳到子网页面 --> 此时可以看到子网绑定的路由表,复制路由表名字 --> 到路由表页面搜索(云平台的路由表不能直接跳转,只能复制名字过来搜索) --> 点进去详情中看到 NAT 名字,通过链接点进去 --> 点进去没有跳到想要的地方(云平台有时候的使用也并不理想) --> 点击到 NAT 列表,搜索刚刚的 NAT 名字点进去 --> 然后就能看到 NAT 关联的弹性 IP(亦即我们一开始的需求,客户端主机对应的出口 IP)。
- 大约耗费 9 步且有一些步骤比较繁琐的情况下得到了我们想要的信息。
- CMDB 平台的流程
- CMDB 平台中统一搜索框搜索该客户端主机 --> 跳到主机关联 VPC --> 跳到 VPC 关联 NAT --> 在 NAT 详情中拿到关联的弹性 IP。
- 大约耗费 4 步通过点击链接跳转得到了我们想要的信息。
事实上运维同学在日常工作中,需要面对的类似问题数不胜数,很多问题都是这种很繁琐的重复性工作,CMDB 平台就应该在提供资源对象的基础属性之外,还要考虑资源之间的关系,这两点,都需要通过抽象出来的模型进行维护,后边会详述。
# 平台设计
一个平台的建设, 设计是第一步,开发才是第二步,尽管项目启动之后,参与其中的开发人员已经开始催促你拿出方案,但我劝你,别着急,你需要冷静地思考,耐心地梳理,把你想要的东西和样子想清楚,并把你该做的准备工作做充分,否则你一定会被后续开发过程中遇到的诸多问题干扰,从而在大平台的小细节中迷失。这是作为项目 PO 必须在一开始就要注意的。
为了便于大家快速领会整个平台设计的方向,这里先将我们落地下来的页面左侧导航陈列与此:
这个导航将会作为后续内容展开的参照。
# 模型的应用
# 前摇
现在很多 CMDB 平台的最佳实践,至少都同步到了这样一个共识:需将资源进行抽象,通过模型表达资源的属性及关系。
乍一听可能会有一些懵,这里我可以从个人所经历的资产管理的几个阶段来做一个说明。
最早的时候,我与小伙伴所管理的服务器资源(其他资源则大多疏于登记管控),都是基于 Excel 来进行管理的,彼时表格里边大概会这样来对服务器资源进行登记:
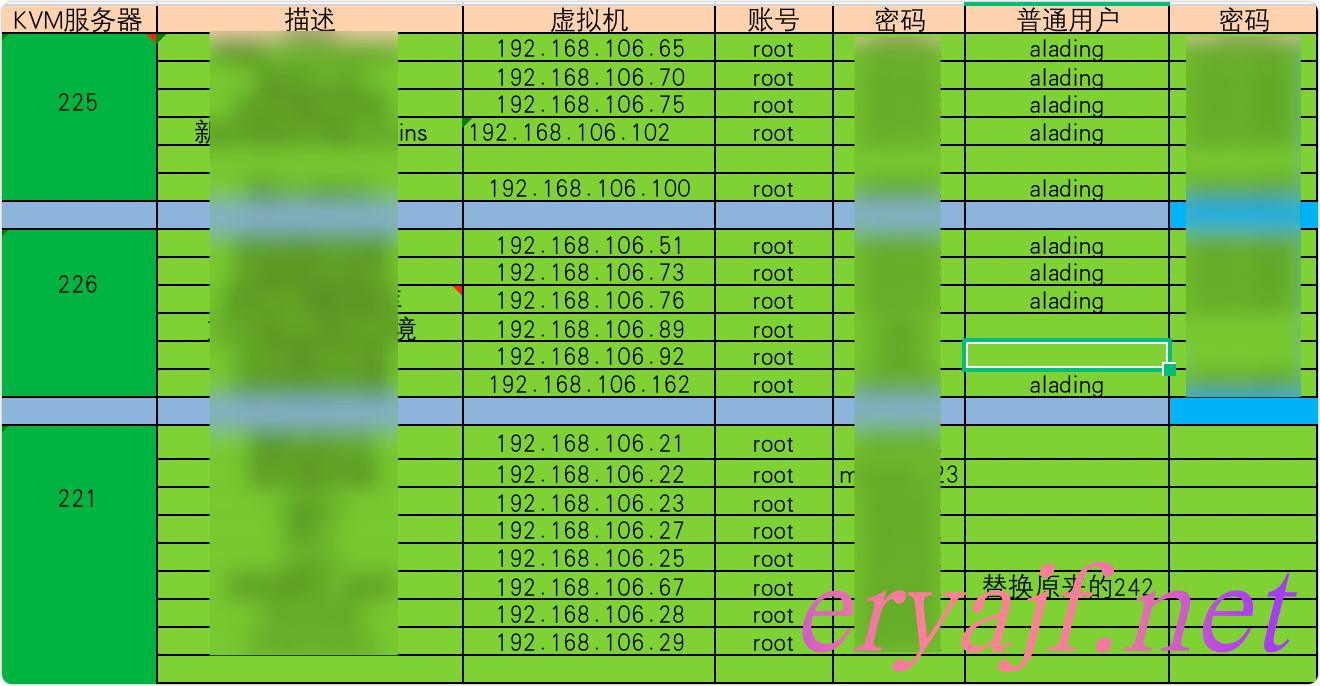
表格维护,缺点多多,相信经历过的同学必有同感,维护麻烦与数据准确性是表格维护的最大问题。那时候我与几个运维小伙伴将这些 Excel 维护在了 SVN 当中,每个人更新了表格内容之后,就通过小乌龟将内容同步上去,想来这应该算是远古时期的手工时代了,现在公有云时代的运维,恐怕没有几个人会甘心做这样的手工活了。
当时有不少服务器是在自建机房的 kvm 中运行,因此就先以单台宿主机服务器作为大分类,然后逐个记录运行在服务器上的虚拟机,后边的则是一些相对重要的虚拟机属性信息。如果想要获取虚拟机更多的信息,就只能登陆到主机上凭经验查找确认了。
再往后会有一些运维同学自学了开发,或者是部门有专门的运维开发同学,也做过 CMDB 平台的建设,只不过,大多是服务器资源数据在云厂商那里平搬到本地数据库,然后在 web 页面提供了一个可供搜索的框而已,看似跨出了很大一步,实则对实际很多应用场景,都是没有太多帮助的。
这算是半自动时代,资源的字段属性在数据库,乃至在前后端代码内,都是固定了的,如果你想要新增一个你关心的字段,则需要牵动前后端开发者,乃至 DBA 同学,一同来做一波变更,从而满足这样一个需求。还有一个问题是,这种单资源对象的管理,通常都没有把不同资源之间的关系维护起来,从而很难在实际运维工作中解决掉运维的痛点。
上边一些描述中,需要大家注意一些关键词,这些关键词也组成了新平台的纲领。
- 维护简单:一个好的平台,一定要考虑到尽可能减少维护成本,如果你运维的服务器只有 10 台,那么我想,Excel 的维护方式似乎没有什么问题,而如果这个数量扩大十倍百倍乃至更多,那么每一个单台主机数据维护成本的增加都将会是指数级增长的。因此,维护简单是一个平台成败的关键。当然,有一些方面的简单,事实上会依赖运维规范化的制定以及推行的,比如一个应用的名字,将会是其全生命周期中很多地方同用的唯一标识,当业务方打算要新上一个应用,则必须经过 CMDB 平台创建这个应用,然后这个创建动作会自动在 gitlab 仓库将项目创建出来,名字也是应用名,以此类推。
- 数据准确:数据准确是 CMDB 平台的立身之本,如果数据不准确,则会逐次消磨掉运维人员对 CMDB 平台的信任,古语有云:流水不腐,户枢不蠹,任何一个平台都是越用功能才越完善的,失去公信力的平台自然也就等于失去它的用户,进而走入一个恶性循环,渐渐无人问津,越放越凉,然后直接凉凉。
- 灵活可靠:平台的设计需要考虑到运维接入使用的灵活性,这样才能够适应运维工作中面临的复杂性。而建立模型体系,提供模型功能,则是解决灵活性问题的一个理想方案。
# 模型是什么
模型是对 CMDB 平台所有资源的抽象,所有资源都应该基于模型来构筑,模型的核心功能在于:定义资源对象的基础属性,配置资源对象的关联关系。
最终,资源仓库对资源进行展示的时候将会依据模型中资源模型定义的字段以及关系进行呈现。
# 模型的建设流程
模型设计是 CMDB 平台建设的重要环节,如果这一个环节工作做好了,那么后续的开发以及使用都将会变得顺遂起来。而这个建设过程如果没有比较好的方法论支撑,又是很容易陷入焦灼之中的。
模型的产生过程,大概分如下几个步骤:
- 第一步:梳理资源,将自己运维环境中面临的资源进行梳理,做出来一张资源对象图。
- 第二步:梳理字段,梳理关系。这一步对应模型的核心概念,是一个模型元数据设计生成落地的一个过程,前期可以通过表格先维护起来。
- 第三步:同步对齐,一个模型的产生以及落地到平台,不应该是某一个人的独立行为,而应该是运维组内成员共同讨论过,共同评审过的。
- 第四步:平台上建立模型,通常在第二第三步,模型的字段以及关系都已经成型落地,此时在平台上创建模型之后,就可以在资源仓库中维护应用起来了。
# 梳理资源
因为我们的所有业务全部运行在公有云之上,于是我就登录上云平台,将常见资源一一巡查了一波,首先整理出了一张模型草图:
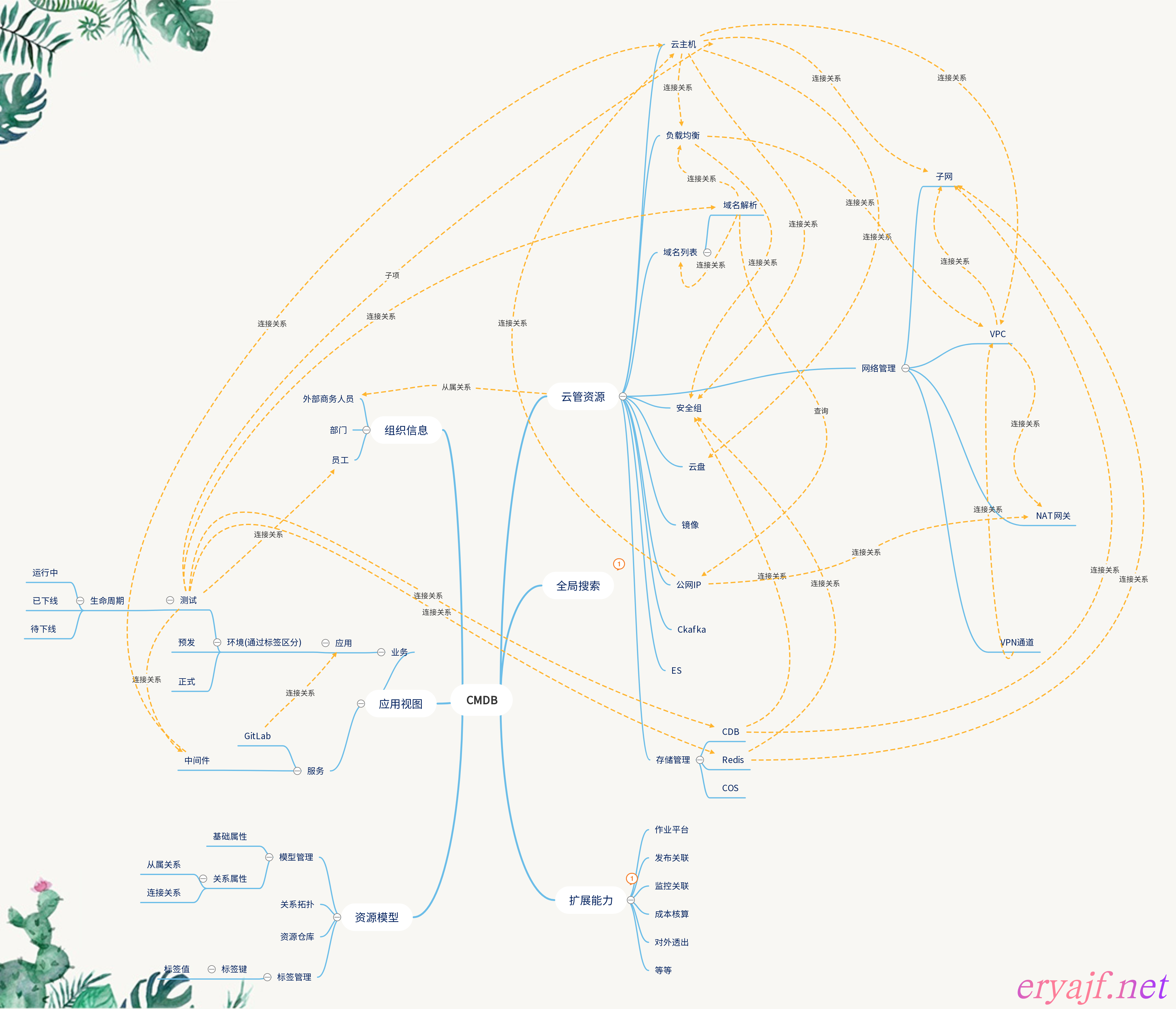
当你读这篇文章,打算建设一个 CMDB 平台,那么梳理出来这样一张图是必不可少的一个步骤,它不仅清晰地展现了 CMDB 平台你想要的内容和样子,最重要的是为后续平台推进奠定了重要的基础。
我来简单说明下这张图,首先图里呈现了我们前边提到过的,CMDB 平台的使命,即将右上角云上的资源与左边我们本地的资源数据,通过关系(下边会详细介绍关系的设计)给串联起来了。有了这样的关系链之后,我们就能够在平台上一目了然地看到一个应用,它的某个环境所涉及到的 GitLab 仓库地址,相关的开发测试运维人员,以及其他中间件,云上各种资源。
一个平台能够做到这一步,其实就已经非常厉害了,通常互联网公司中人员流动都比较大,新人入职花费精力最大的莫过于要去了解每个应用以及它背后隐藏着的一系列相关资源,当我们的平台能够弥补这块儿的空白,就实现了很大的一个价值。
另外,图中还提到过的其他扩展能力,主要需要考虑与其他平台打通的问题,以及成本核算方面的建设,当我们基础建设完成之后,会再添加任务核算出每个应用的花费,然后再结合上该应用的监控数据进行比对,从而在平台上自动提供给我们一个应用成本与产出之间的比例,以便运维同学对其进行评估。
# 梳理字段
当你梳理完资源大纲之后,就可以梳理每个资源的具体字段以及关系了,建议这里使用表格进行统一梳理与维护,这也是从赵班长一次直播分享当中学习到的经验。
Excel 样式大概如下:
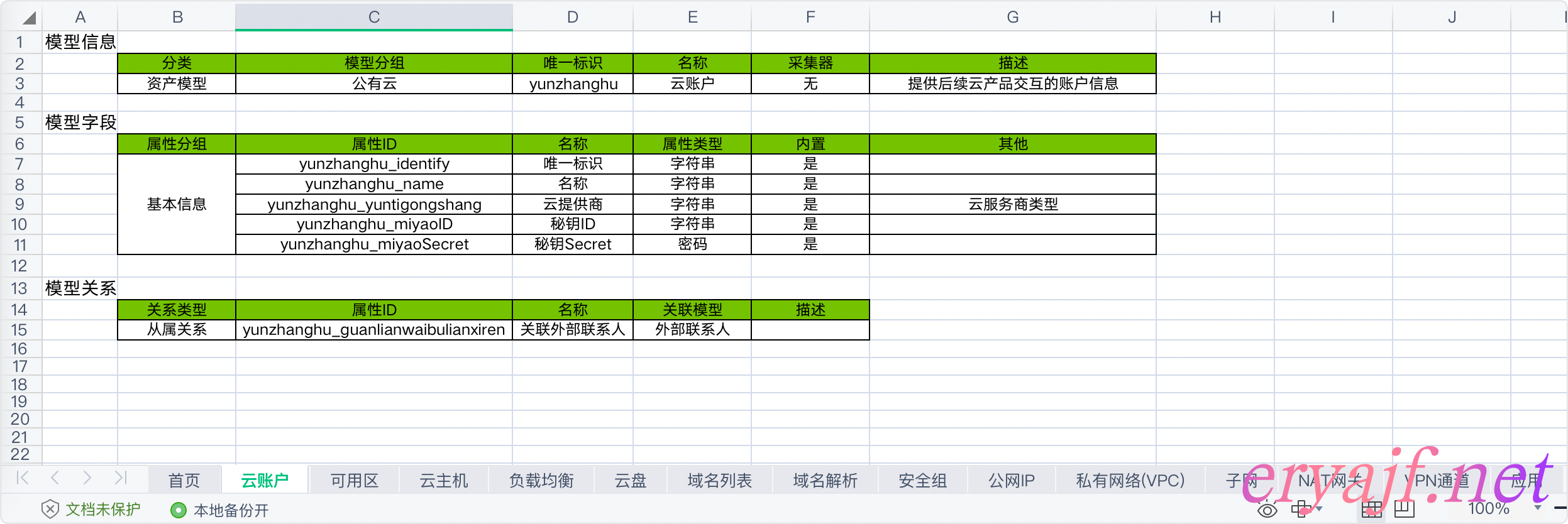
通常一个资源分三组进行维护:
- 模型信息:记录模型的标识名称以及基础介绍。
- 模型字段:记录模型对应的字段信息,主要内容是字段的唯一标识,字段名称与字段类型。另外,我们面向内部使用,通常字段标识方面,最好直接使用拼音,这里强行使用英文反而容易增加使用成本。
- 模型关系:此处记录该模型与其他资源模型之间的关系。下边设计细节中会讲解关系的分类与意义。
# 评估与创建
因为云上资源的字段都是已经固定下来的,因此只需要在资源详情页面对字段进行整理登记即可,这块儿基本上也不需要过多讨论,顶多对一些资源字段的取舍上做一个讨论,因为有一些云上资源的字段对我们来说意义并不大。
如果是本地新增的模型,那么字段有哪些,如何定,则都是需要大家好好讨论的,这块儿我在后边讲应用视图设计的时候会单独介绍应用的字段。
# 编码之前
# 数据库的选型
项目一开始,在技术评审会议上,我们内部对于 CMDB 平台底层存储选型问题也做过专门的讨论。
讨论的核心在于:选择 MySQL 还是 MongoDB。
通常运维平台都是以 MySQL 作为后端存储的,大家用起来也会更加轻车熟路一些。之所以这里要引入 MongoDB,是因为 CMDB 平台的一些特殊性,也正是基于这些特殊性,促使我们在讨论之后,决定选型存储为 MongoDB。
第一个要点:动态字段,我们给资源进行建模,然后在平台上来维护这个资源的字段,因此每个资源模型都是在平台新建的,模型的字段也是新建的,这就要求这些内容落到库中也是动态灵活的。以往使用 MySQL 的思路可能一种资源就是一张表,字段也是一开始就约定好无法随意更改的,这其实是无法满足当前这种需求的。当然,我们也可以在 MySQL 中存一个 json,但是使用起来其实会非常别扭,实际开发过程中也会遇到不少现实的难题。MongoDB 的存储格式为 BSON(一种 json 的扩展),刚好契合这种需求场景,这也是选型 MongoDB 的最重要原因。
第二个要点:全文搜索,前边说过,CMDB 平台使用场景中,有占八成都是查询方面的,通常我们会拿到一个 IP,或者一个关键词,你还不能确定这个信息归属于哪个资源类别,没办法直接去搜索,因此全文搜索也是一个必须要支持的功能。如果选型 MySQL,那么就需要再把数据同步到 ES 或者 MongoDB 来实现,既然 MongoDB 天生支持这种全文模糊搜索,那么为什么不直接选型 MongoDB 呢,是的,就它了!
# 技术选型
其实这个本来不值得多说,语言只是工具,用任何语言栈来实现都是没有问题的,只是说明一下我们之前使用的技术栈,从而在后边对一些具体的知识点分享时大家能心里有数。
- 后端:go
- gin 框架+mongo-driver
- 前端:react
- antd 框架
# 推进流程规划
任何一个平台的建设,都是需要时间的,这一点对于我们项目负责者要提前意识到,更重要的是还需要让你的领导意识到。
所有一旦口渴马上就要喝茶,一旦饿了马上就要把饭吃到嘴里,一旦提出建设平台的想法,只给了一周两周就要看到成品,这些都是小孩子未曾开蒙的行为。行军打仗,首要考虑的就是粮草与天象,负责项目,亦要重视项目拆解与排期。
通常来说,要建设一个基本可用的 CMDB 平台,前后端的开发,以及运维同学的协同配置接入使用,至少需要三期规划,如果开发人员资源不很充足的话,那么最少也需要半年的时间来建设。
接下来我将详细介绍这几个阶段开发推进的流程与细节,大多地方先通过截图让大家有个整体认识,然后将功能细节用任务列表的形式进行解释与说明。
一个大的平台,必然是由无数个小的功能点堆砌而成的,没有人能够把每一个功能点的详情记在脑海中,我也一样,所以我在负责该项目的时候,当我与小伙伴们一起把功能点聊清楚之后,马上就会拆分成每一个功能细节,并用任务列表记录下来。再拆分成前后端开发的具体接口列表,分配给开发者落地到 mock 平台。然后再将这些内容与各位开发者二次确认,以免出现需求理解偏差的问题。在最后项目结期的时候,这个任务列表也会成为我验收项目的一个参考凭据,以免因为忘记某个细节而漏测某个功能点。
项目的开发,在每一期未动工之前,无论费多少口舌,开多少次会议,只要能够把需求对齐到开发者同学的心里,都是值得的。需求理解偏差这种问题,发现越早,提出越早,调整越早,就越好,这也是作为项目负责人,需要在项目推进过程中不断关注并跟进测试的,否则,等到最后做出来却发现货不对板,然后再进行返工,就会对项目推进的整体质量,以及开发者的心气儿都产生极大的影响。
所以,不要着急动工,一旦动工,就一定是想好了。
# 项目推进
# CMDB 第一阶段开发
# 核心目标
完成模型管理这一功能的落地,要求这一期结束之后,能够完成一个资源模型的增删改查,以及能够在资源仓库手动添加删除资源数据。
# 时间排期
建议排期为两个月,这一期看似只是完成了模型管理和资源仓库两个内容,但实际上里边模型的动态字段,复杂的交互逻辑对于前后端的考验都是非常大的。
加之这是项目的开篇阶段,每个开发人员都还不熟悉里边的各种概念,需要一点时间来磨合。我们经历的过程也正是如此,后端开发者,前端开发者,在前期都曾不止一次被里边的概念绕晕,从而导致需求与实现错位,但当我们后边接触越来越多,每个陌生的概念慢慢都变成大家的常识,每个功能点大家也都能参与其中,一起思考,讨论,共建,这个时候才能真正进入快速开发的阶段。
# 设计细节
# 模型管理
样式示例:
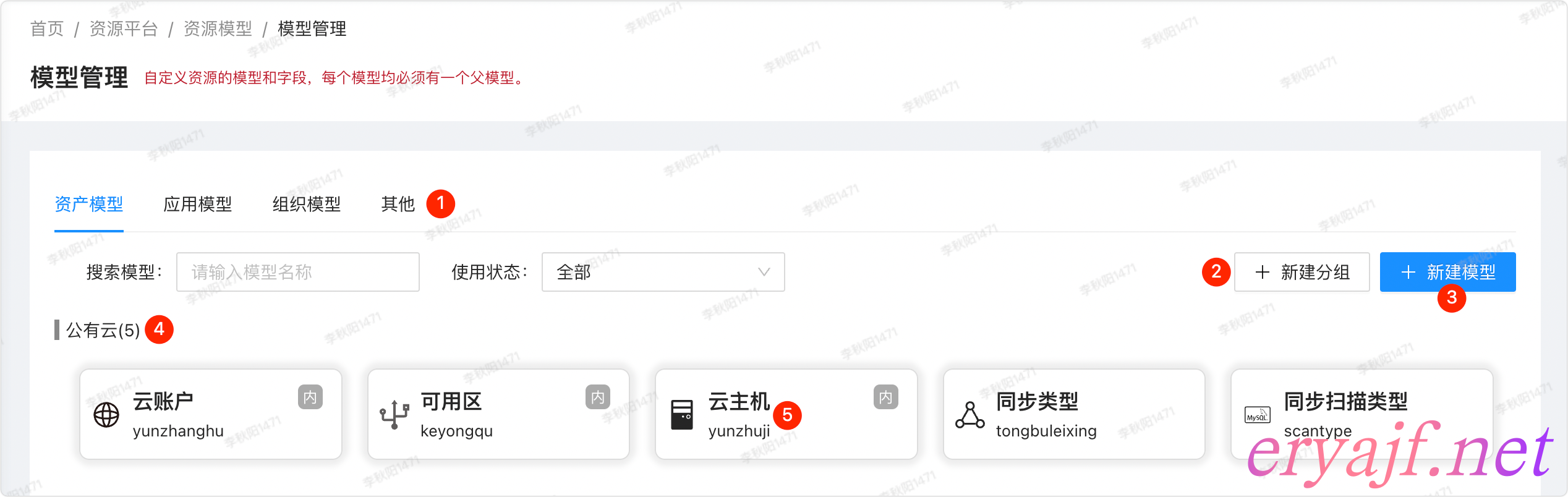
功能细节:
- [ ] 模型管理功能落地
- [ ] 模型内置四大分类:资产模型,应用模型,组织模型,其他,见截图中标号 1
- [ ] 模型分组管理,见截图中标号 4
- [ ] 新建模型分组,见截图中标号 2
- [ ] 删除,如果分组内有模型,则不能删除
- [ ] 模型管理,见截图中标号 5
- [ ] 新建,见截图中标号 3
- [ ] 根据名称搜索模型
- [ ] 根据状态过滤模型
# 模型详情
样式示例:
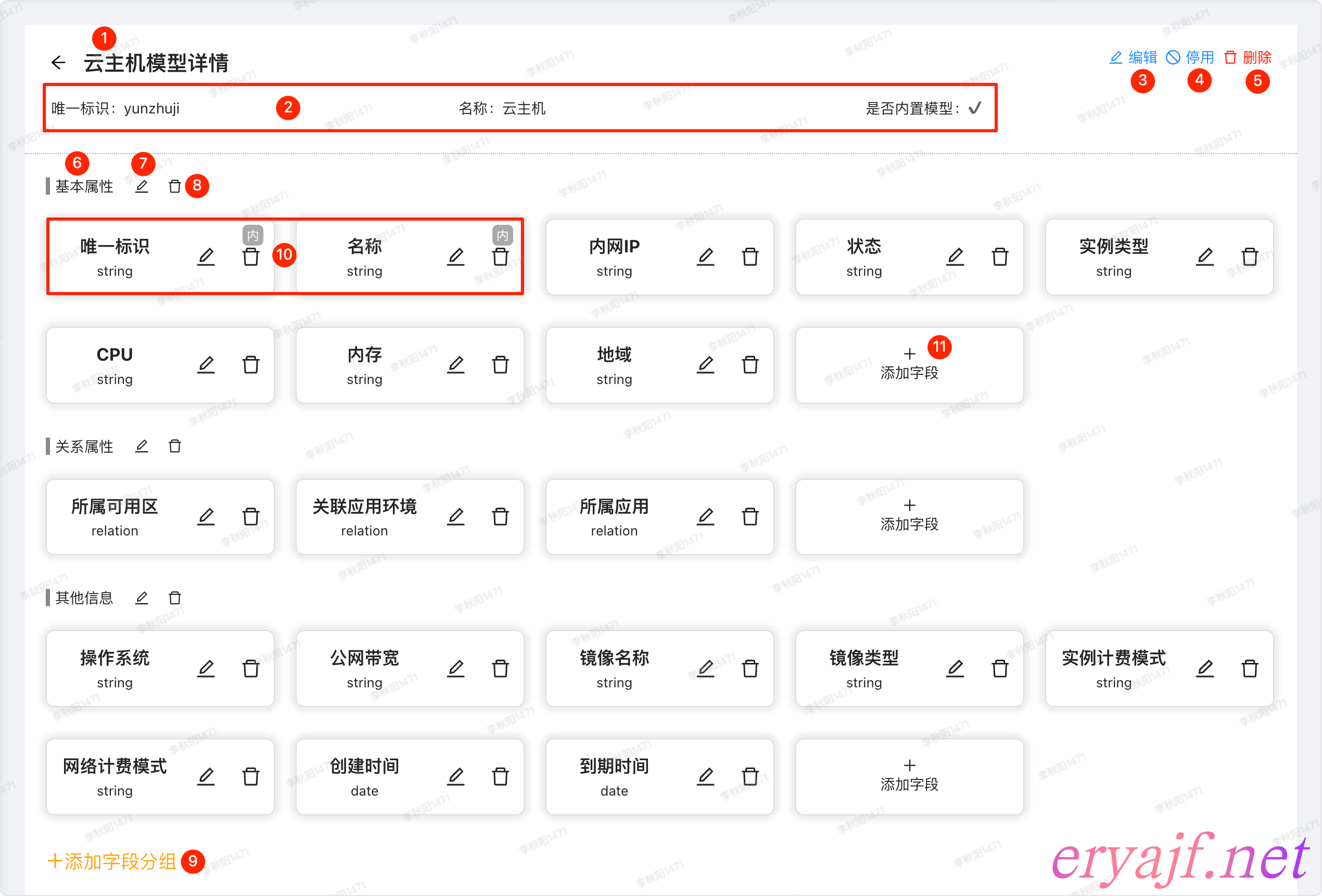
功能细节:
- [ ] 模型详情,见截图中标号 1
- [ ] 展示模型的基础信息,见截图中标号 2
- [ ] 唯一标识
- [ ] 是否为内置模型,是否内置的区别在于,内置模型无法删除
- [ ] 编辑,见截图中标号 3
- [ ] 停用,见截图中标号 4
- [ ] 删除,见截图中标号 5,如果模型下有数据,则不能删除
- [ ] 添加字段,见截图中标号 11
- [ ] 展示模型的基础信息,见截图中标号 2
- [ ] 模型创建完成之后,默认自动创建的分组与字段
- [ ] 两个分组,见截图中标号 6
- [ ] 基本属性
- [ ] 关系属性
- [ ] 两个字段,见截图中标号 10
- [ ] 唯一标识
- [ ] 两个分组,见截图中标号 6
- [ ] 模型字段分组管理
- [ ] 新建,见截图中标号 9
- [ ] 编辑,见截图中标号 7
- [ ] 删除,见截图中标号 8,如果分组下有字段,则不能删除
# 模型字段
字段管理是整个模型管理当中比较复杂的一块儿内容,当然,这个复杂是针对前后端开发者而言的,其实这种开发上的复杂,也正是为了达到使用上的简单。
点击添加字段之后的页面示例:
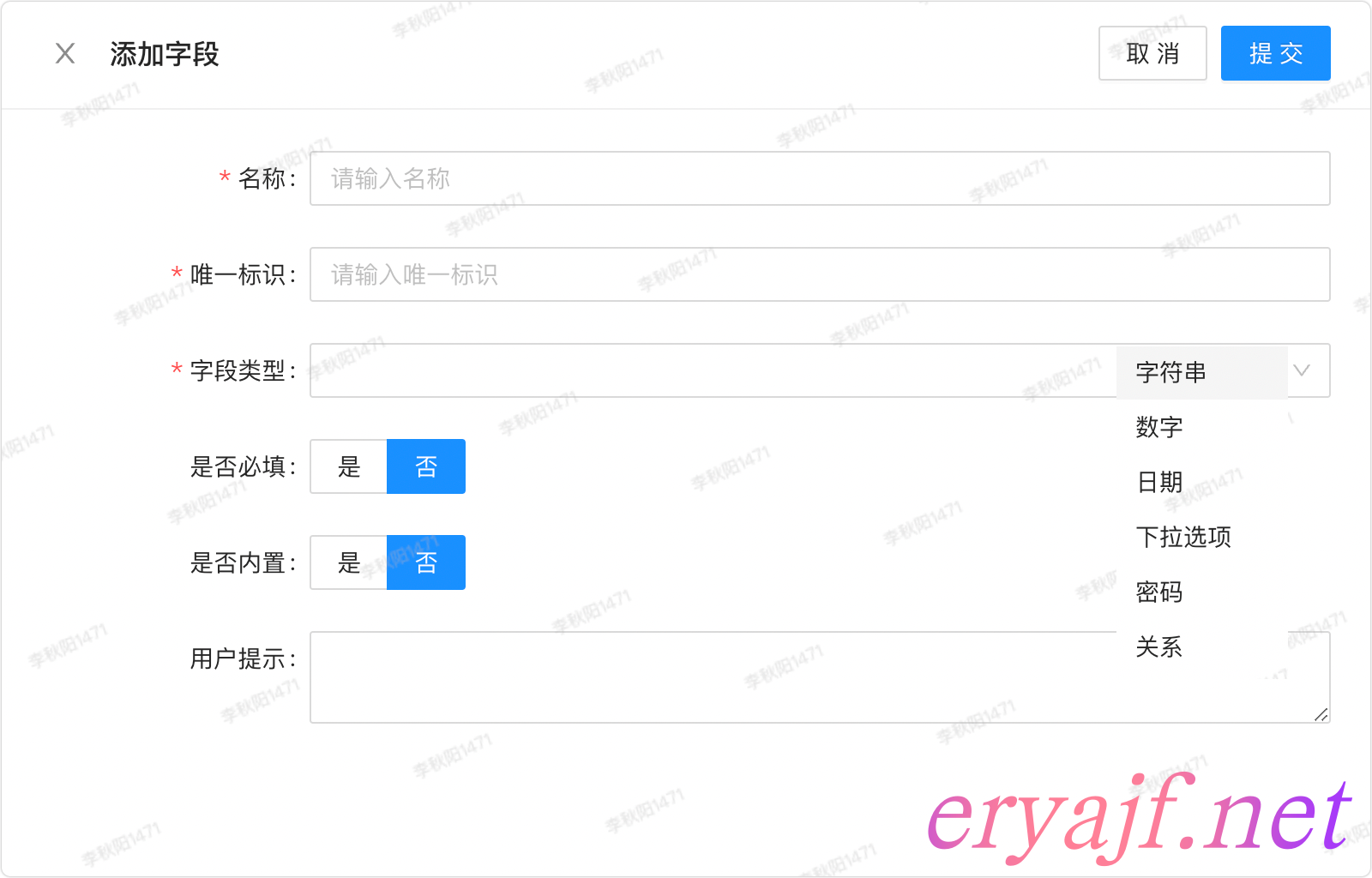
关于字段的类型,不同的平台可能提供的有不同的类别,像蓝鲸 CMDB 中模型的字段类型有如下几种(参考: https://bk.tencent.com/docs/document/6.0/152/6954):
- 短字符:长度 256 个英文字符或 85 个中文字符
- 长字符:长度 2000 英文或 666 个中文字符
- 数字:正负整数
- 浮点数:可以包含小数点的数字
- 枚举:包含 K-V 结构的列表
- 日期:日期格式
- 时间:时间格式
- 时区:国际时区的枚举
- 用户:可以输入蓝鲸中已经录入的用户
- 布尔:布尔类型,常用于开关
- 列表:可以理解为数组类型,只包含值的列表
我根据日常使用场景中经常遇到过的字段类型,将字段类型压缩成了 6 种,以减少运维人员的接入认知成本。分别为:
每一种类型都会有不同的规则约束,也就造成了每种类型的信息表单是不一样的,前端需要根据选择类型的不同,进行表单的动态变化。其中的规则约束基本上都能见名知意,因此不再一一解释。
这里将不同的字段类型表单示例做个分享。
字符串类型
数字类型

日期类型
下拉选项
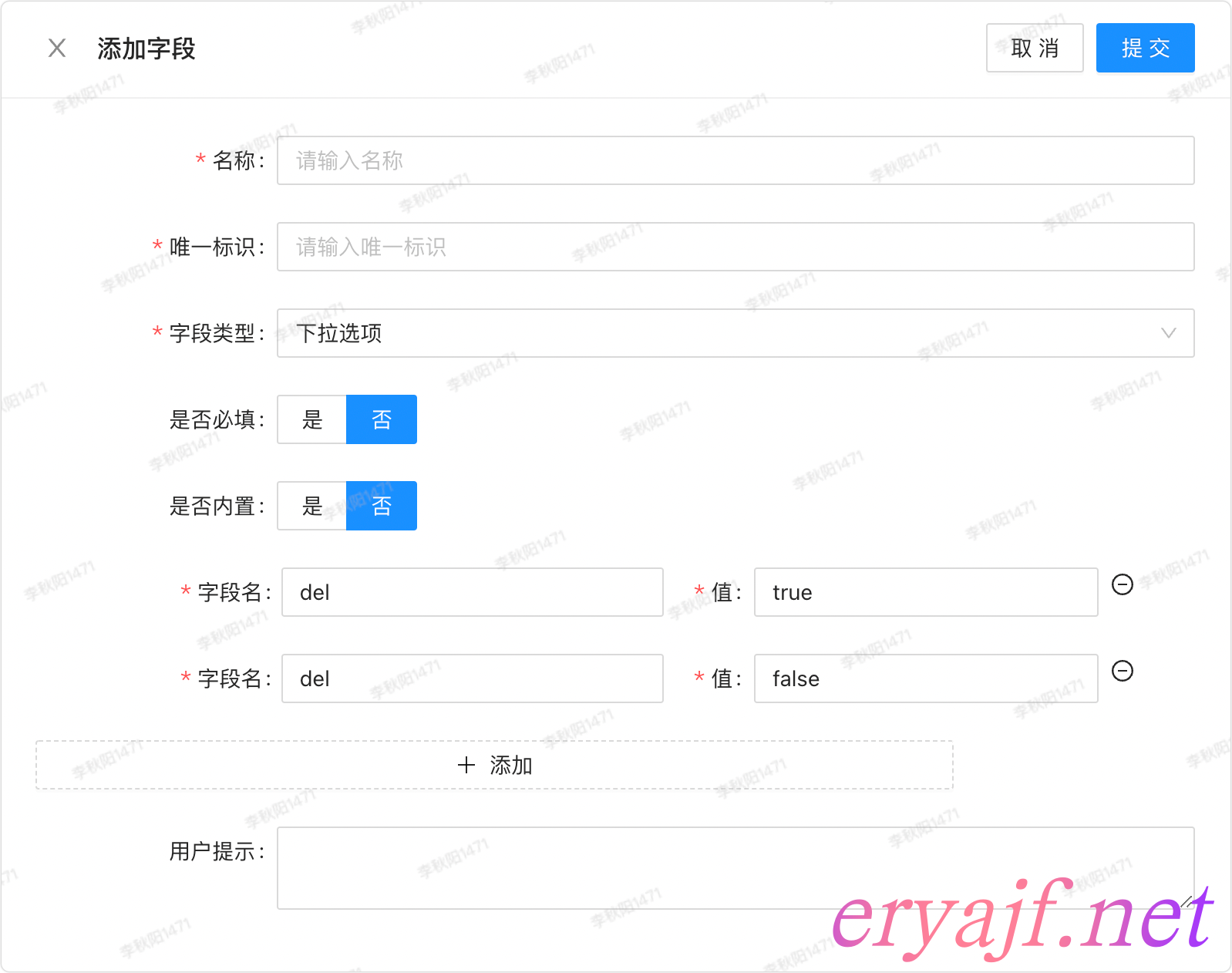
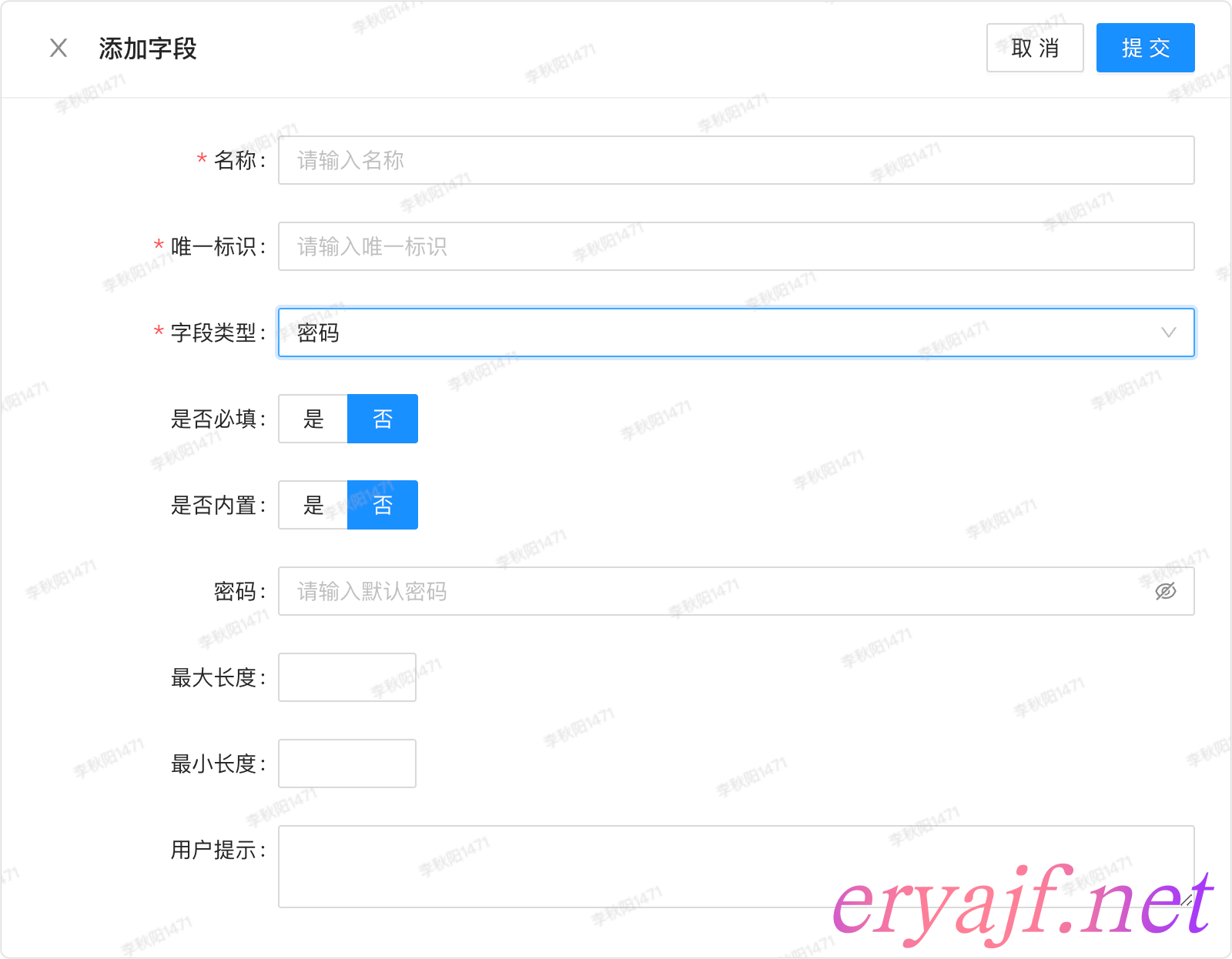
密码类型
关系类型
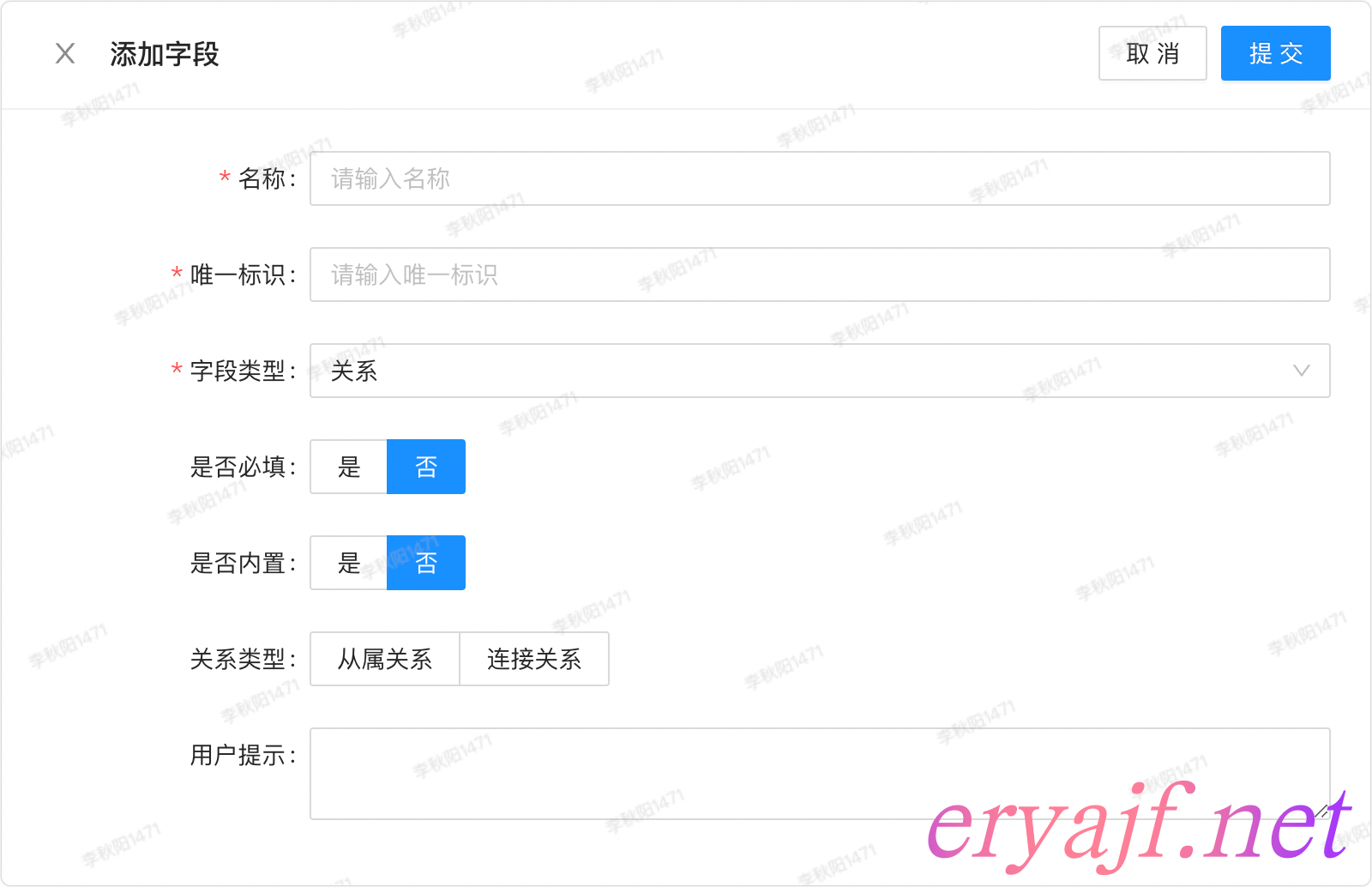
关系是比较复杂的一个类型逻辑,不过前边我们已经有过铺垫,这里将所有的资源之间的关系拆分为从属和连接两种,下边再来拆分看两种关系的不同表单效果。
从属关系
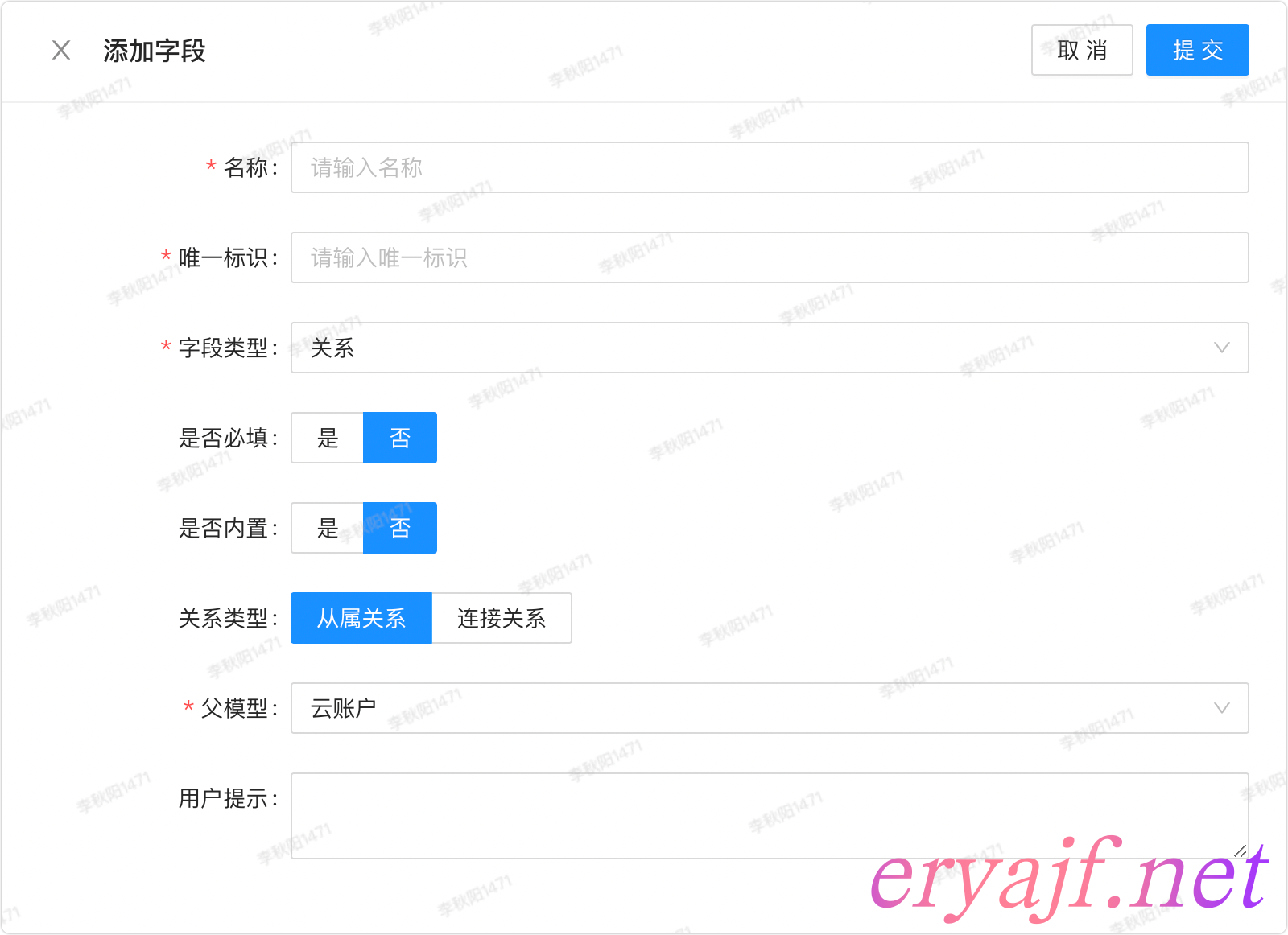
连接关系
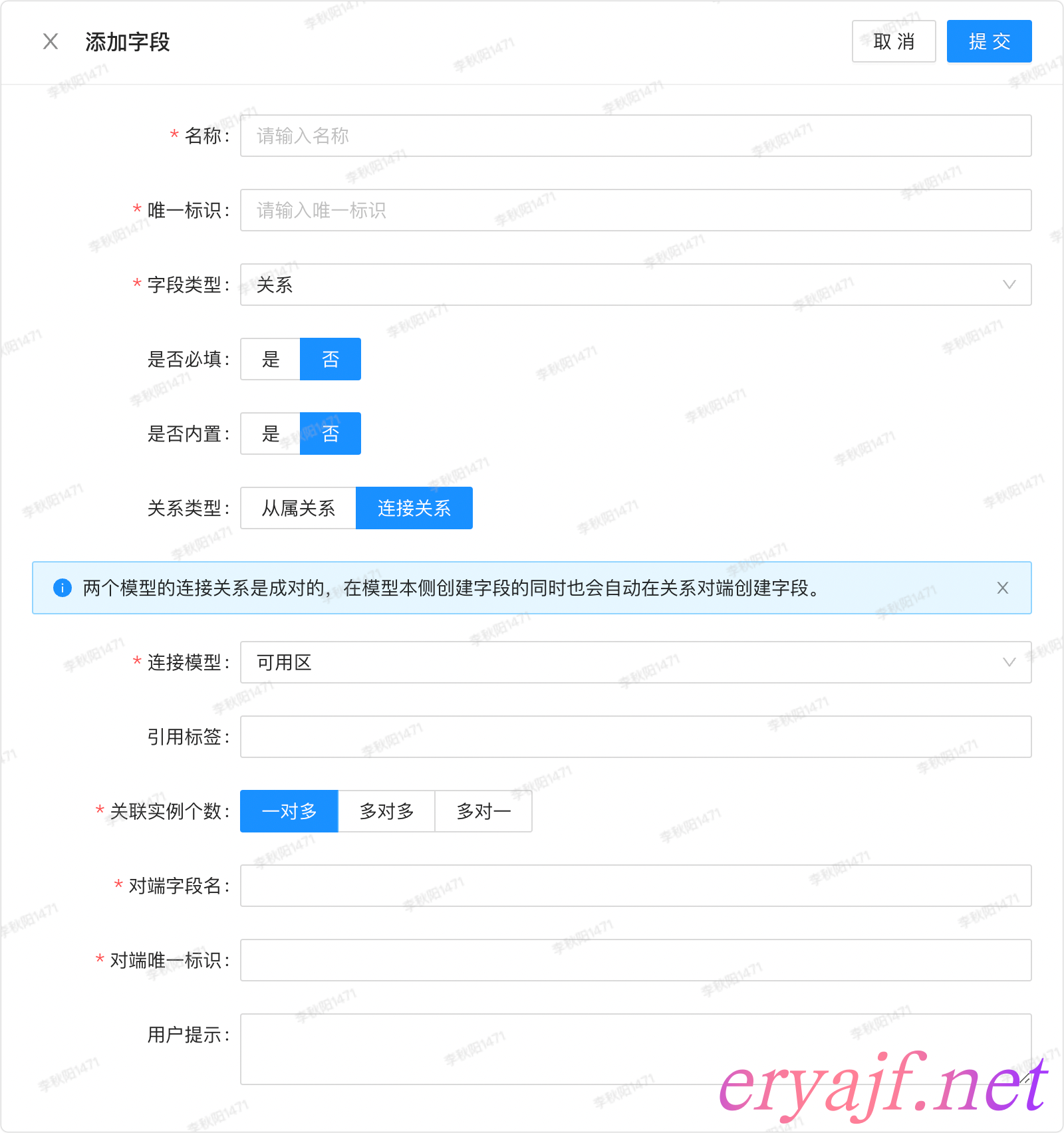
两种关系在这里可能看起来并不够直观,后边在介绍资源仓库的时候,我将通过实例进行详细的讲解。
功能细节:
- [ ] 模型字段管理
- [ ] 新建
- [ ] 唯一标识
- [ ] 字段类型
- [ ] 字符串
- [ ] 下拉选项
- [ ] 关系
- [ ] 从属关系
- [ ] 从属是一对一的关系,一个模型只能从属于某一个模型,比如某台主机会从属它对应的子网网段。
- [ ] 连接关系,一个模型可以关联多个模型,比如主机关联磁盘,关联安全组等。连接关系创建之后,被关联方也要能看到该条关联关系,如果删除了连接关系,则两边都要删除
- [ ] 一对多
- [ ] 多对多
- [ ] 多对一
- [ ] 从属关系
- [ ] 密码,这个类型的数据要求后端对 value 加密保存,展示的时候也是密文透出
- [ ] 校验规则:通过定义一些正则来校验约束用户输入的字段内容,比如邮箱,手机号等
- [ ] 字段设置
- [ ] 是否必填
- [ ] 是否内置
- [ ] 其他内容则根据不同字段类型动态展示表单
- [ ] 编辑:编辑字段只能修改字段的名称以及描述,字段类型与标识不能修改
- [ ] 删除,如果模型内字段有数据,则不能删除该字段
- [ ] 新建
# 资源仓库
资源仓库是所有资源落库之后对外呈现的一个窗口,也是将要开放给运维以及普通开发者的一个数据集合页面。
首页展示
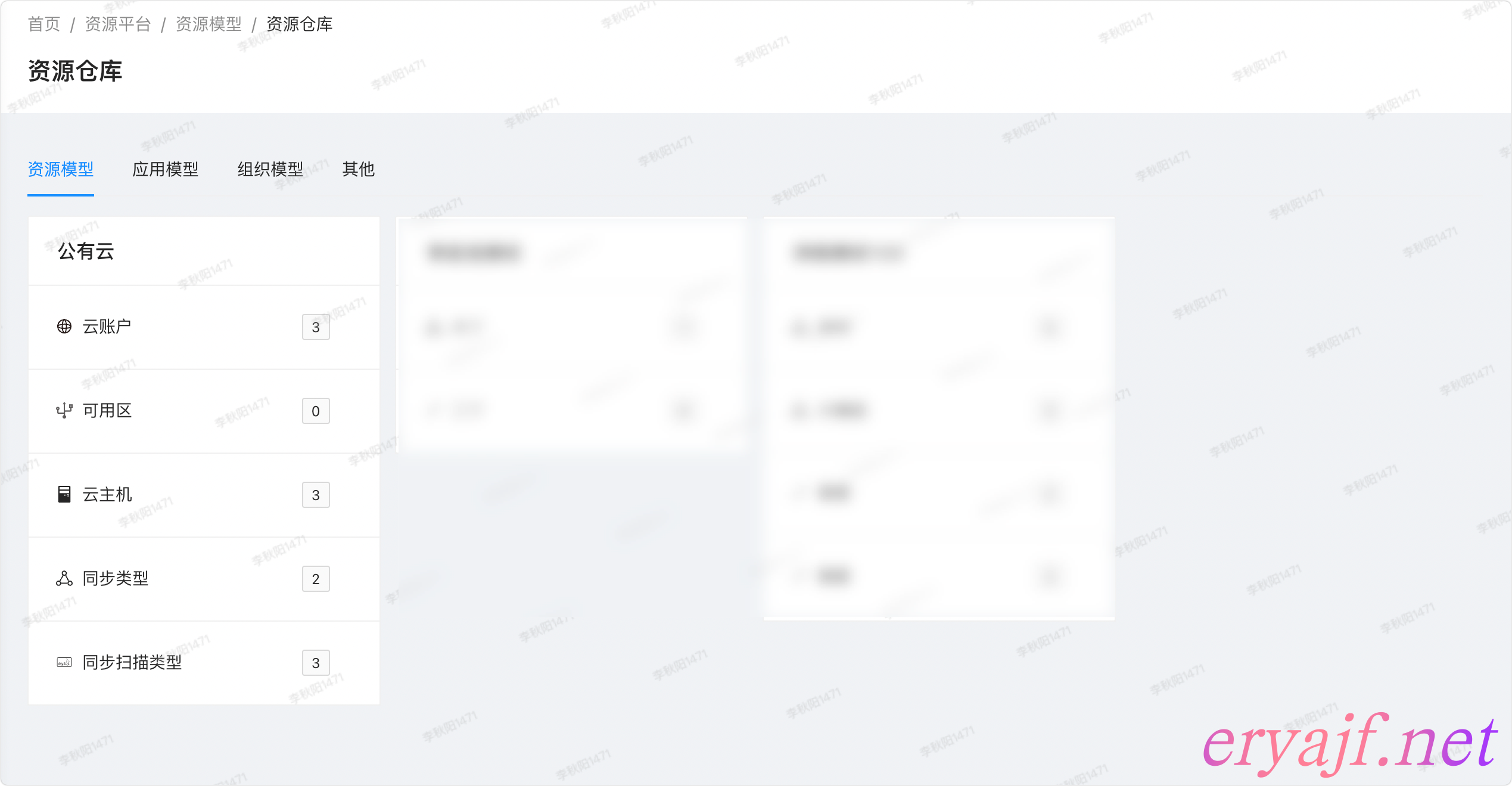
功能细节:
- [ ] 首页布局与模型管理保持一致。
- [ ] 分成资源模型,应用模型,组织模型,其他四大类
- [ ] 每个归类下通过模型分组进行展示,展示分组名,模型列表,以及模型对应的数据总数
- [ ] 点进去之后,将会看到资源的详情
为了说明功能点,我这里在其他分类中创建三个测试模型,以及一些测试数据,分别如下:
在模型管理中其他分类下,创建了一个 CMDB 测试 的模型分组。
- 创建三个模型及字段,分别如下
- 班级:class
- 基本属性
- 唯一标识:class_identify
- 名称:class_name
- 基本属性
- 教师:teacher
- 基本属性
- 唯一标识:teacher_identify
- 名称:teacher_name
- 学科:teacher_xueke
- 基本属性
- 学生:student
- 基本属性
- 唯一标识:student_identify
- 名称:student_name
- 学号:student_xuehao
- 基本属性
- 班级:class
以上是三个模型以及基本属性的字段信息。
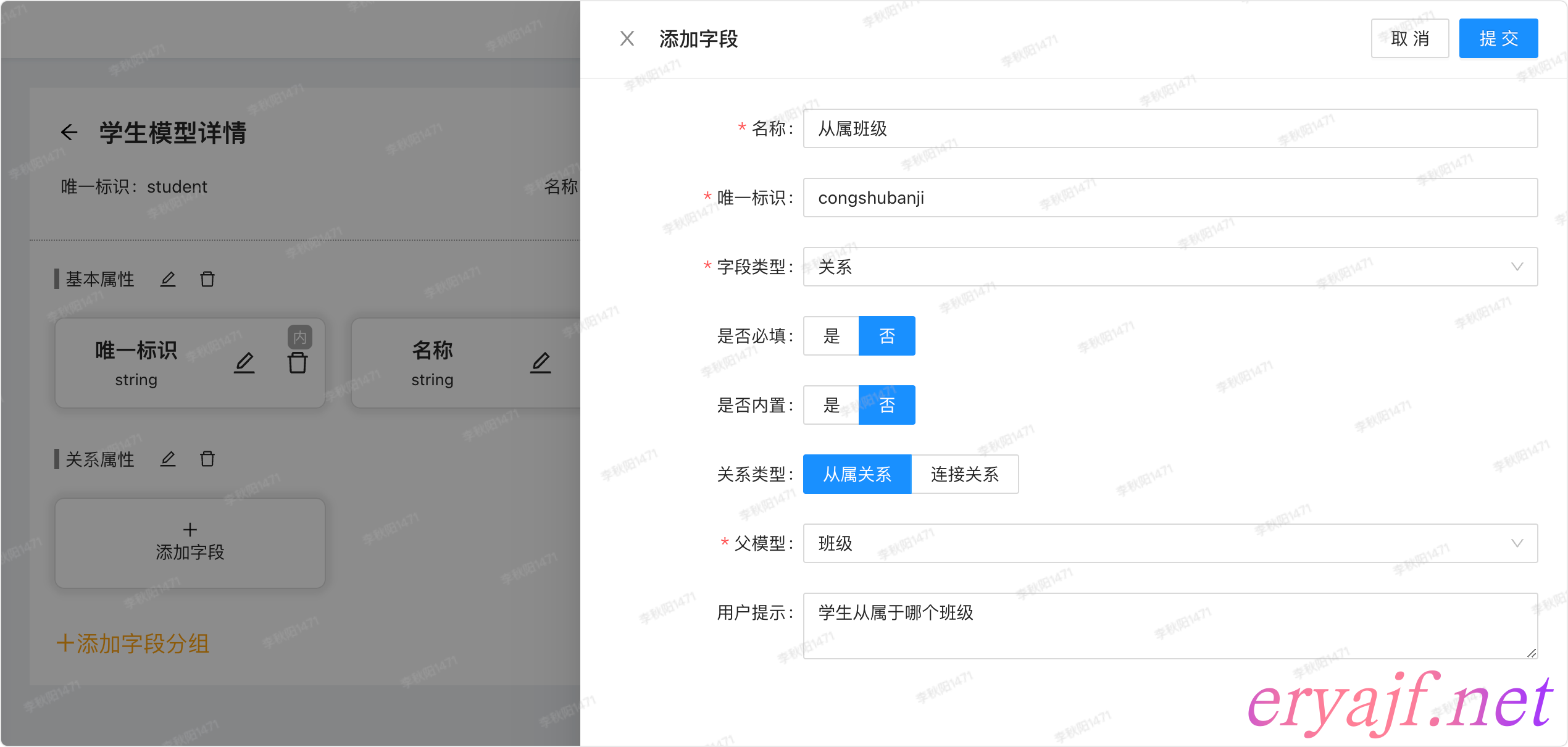
因为关系属性相对抽象,所以这里单独表达:
- 教师与学生从属于班级
- 教师与学生为连接关系
此时我们需要在教师和学生两个模型的关系属性中分别创建一个从属类型的关系,从属模型为班级,如下图:
然后在教师与学生两个模型中任选其一创建一个连接类型的关系,之所以任选其一,是因为在模型管理的功能细节里已经说过,连接关系在某一个模型中创建之后,另一方也需要自动创建这条关系。如下图:

创建测试数据如下:
[
{
"_id": "6279d9e2d440eaf8ddac1255",
"class_identify": "3nian1ban",
"class_name": "3年1班",
"create_at": 1652152802,
"model_identify": "class",
"modify_at": 1652152802
},
{
"_id": "6279d9f4d440eaf8ddac1256",
"class_identify": "3nian2ban",
"class_name": "3年2班",
"create_at": 1652152820,
"model_identify": "class",
"modify_at": 1652152820
}
]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
[
{
"_id": "6279db9cd440eaf8ddac1257",
"create_at": 1652153244,
"model_identify": "teacher",
"modify_at": 1652153244,
"teacher_identify": "lilaoshi",
"teacher_name": "李老师",
"teacher_xueke": "语文"
},
{
"_id": "6279dbb2d440eaf8ddac1258",
"create_at": 1652153266,
"model_identify": "teacher",
"modify_at": 1652153266,
"teacher_identify": "wanglaoshi",
"teacher_name": "王老师",
"teacher_xueke": "数学"
},
{
"_id": "6279dbc9d440eaf8ddac1259",
"create_at": 1652153289,
"model_identify": "teacher",
"modify_at": 1652153289,
"teacher_identify": "zhanglaoshi",
"teacher_name": "张老师",
"teacher_xueke": "英语"
}
]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
[
{
"_id": "6279dc3dd440eaf8ddac125a",
"create_at": 1652153405,
"model_identify": "student",
"modify_at": 1652153405,
"student_identify": "jia",
"student_name": "甲",
"student_xuehao": 1
},
{
"_id": "6279dc47d440eaf8ddac125b",
"create_at": 1652153415,
"model_identify": "student",
"modify_at": 1652153415,
"student_identify": "yi",
"student_name": "乙",
"student_xuehao": 2
},
{
"_id": "6279dc52d440eaf8ddac125c",
"create_at": 1652153426,
"model_identify": "student",
"modify_at": 1652153426,
"student_identify": "bing",
"student_name": "丙",
"student_xuehao": 3
},
{
"_id": "6279dc5dd440eaf8ddac125d",
"create_at": 1652153437,
"model_identify": "student",
"modify_at": 1652153437,
"student_identify": "ding",
"student_name": "丁",
"student_xuehao": 4
},
{
"_id": "6279dcaad440eaf8ddac125e",
"create_at": 1652153514,
"model_identify": "student",
"modify_at": 1652153514,
"student_identify": "wu",
"student_name": "戊",
"student_xuehao": 5
},
{
"_id": "6279dcb6d440eaf8ddac125f",
"create_at": 1652153526,
"model_identify": "student",
"modify_at": 1652153526,
"student_identify": "ji",
"student_name": "己",
"student_xuehao": 6
},
{
"_id": "6279dcc3d440eaf8ddac1260",
"create_at": 1652153539,
"model_identify": "student",
"modify_at": 1652153539,
"student_identify": "geng",
"student_name": "庚",
"student_xuehao": 7
},
{
"_id": "6279dccdd440eaf8ddac1261",
"create_at": 1652153549,
"model_identify": "student",
"modify_at": 1652153549,
"student_identify": "xin",
"student_name": "辛",
"student_xuehao": 8
},
{
"_id": "6279dcd8d440eaf8ddac1262",
"create_at": 1652153560,
"model_identify": "student",
"modify_at": 1652153560,
"student_identify": "ren",
"student_name": "壬",
"student_xuehao": 9
},
{
"_id": "6279dce5d440eaf8ddac1263",
"create_at": 1652153573,
"model_identify": "student",
"modify_at": 1652153573,
"student_identify": "gui",
"student_name": "癸",
"student_xuehao": 10
}
]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
然后将数据按照模型中设计的关系关联起来。
- 李老师和王老师归属于 3 年 1 班。甲乙丙丁四个学生归属于 3 年 1 班,分别关联李老师与王老师。
- 张老师归属于 3 年 2 班。戊己庚辛壬癸 6 个学生归属于 3 年 2 班,都关联与张老师。
这个时候,我们就可以看到数据之间的一些联动关系了。
从资源仓库点击老师这个模型进入详情列表:
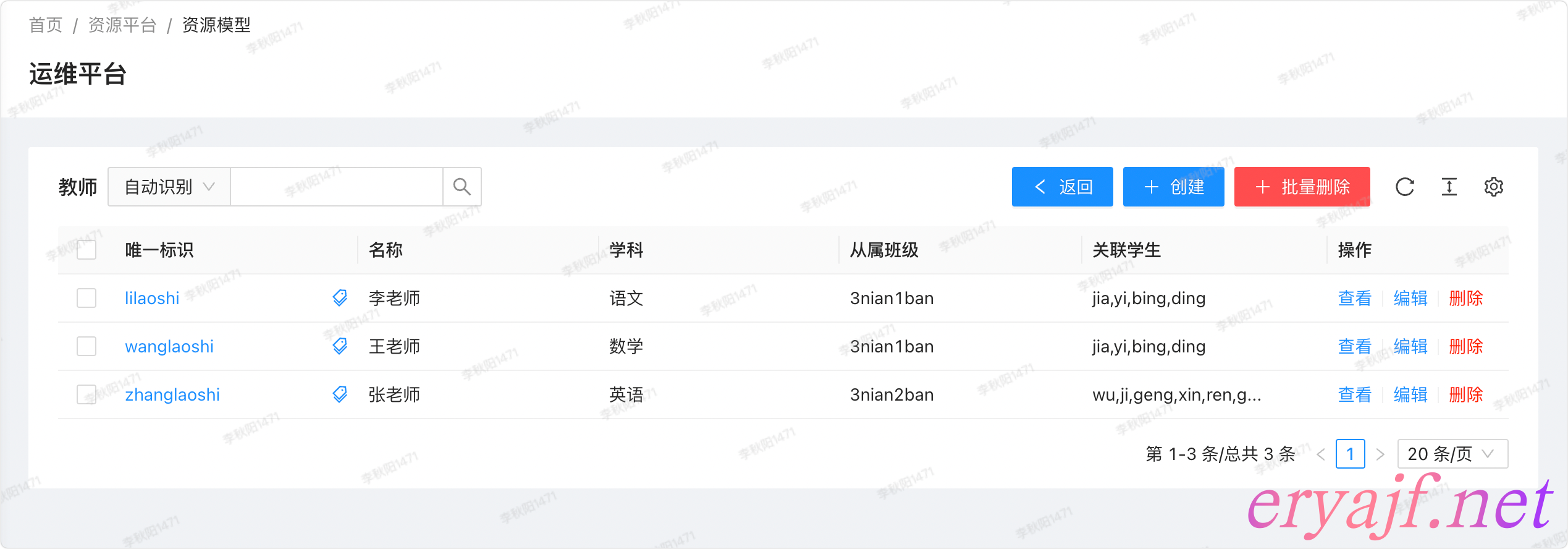
- [ ] 资源以列表形式展示
- [ ] 可通过不同字段进行搜索,也可以选择自动识别进行只能识别搜索,具体实现细节这个在后边我会讲到。
- [ ] 可以手动创建数据
- [ ] 数据管理
- [ ] 数据的批量删除
- [ ] 提供数据的添加标签的能力
此时看一下李老师的信息:
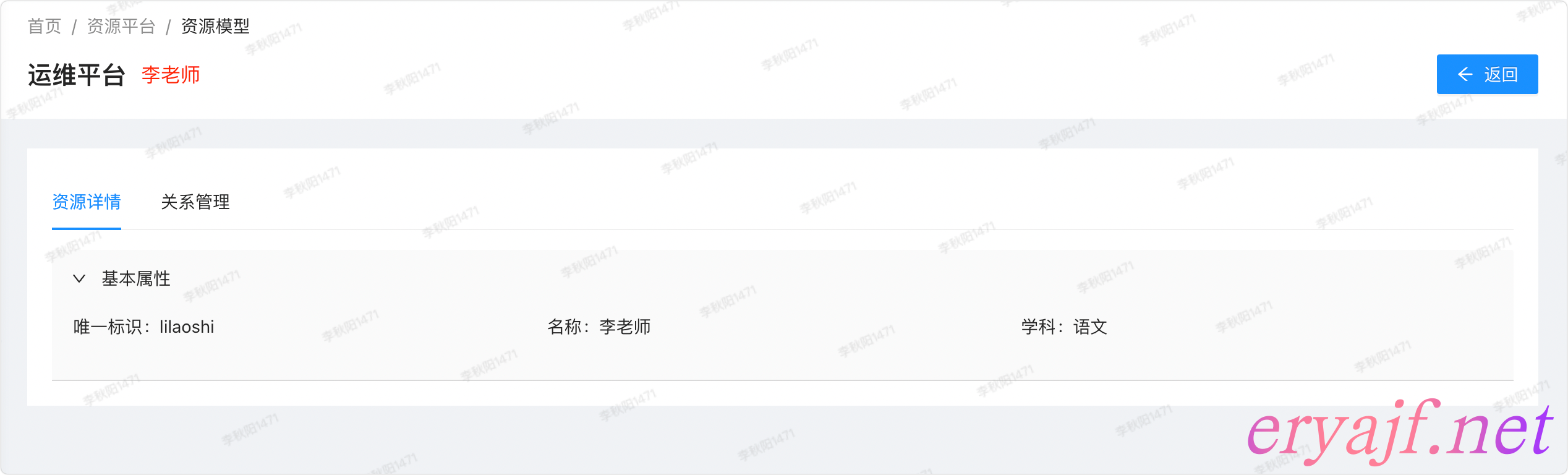
然后看关系管理中的从属关系:
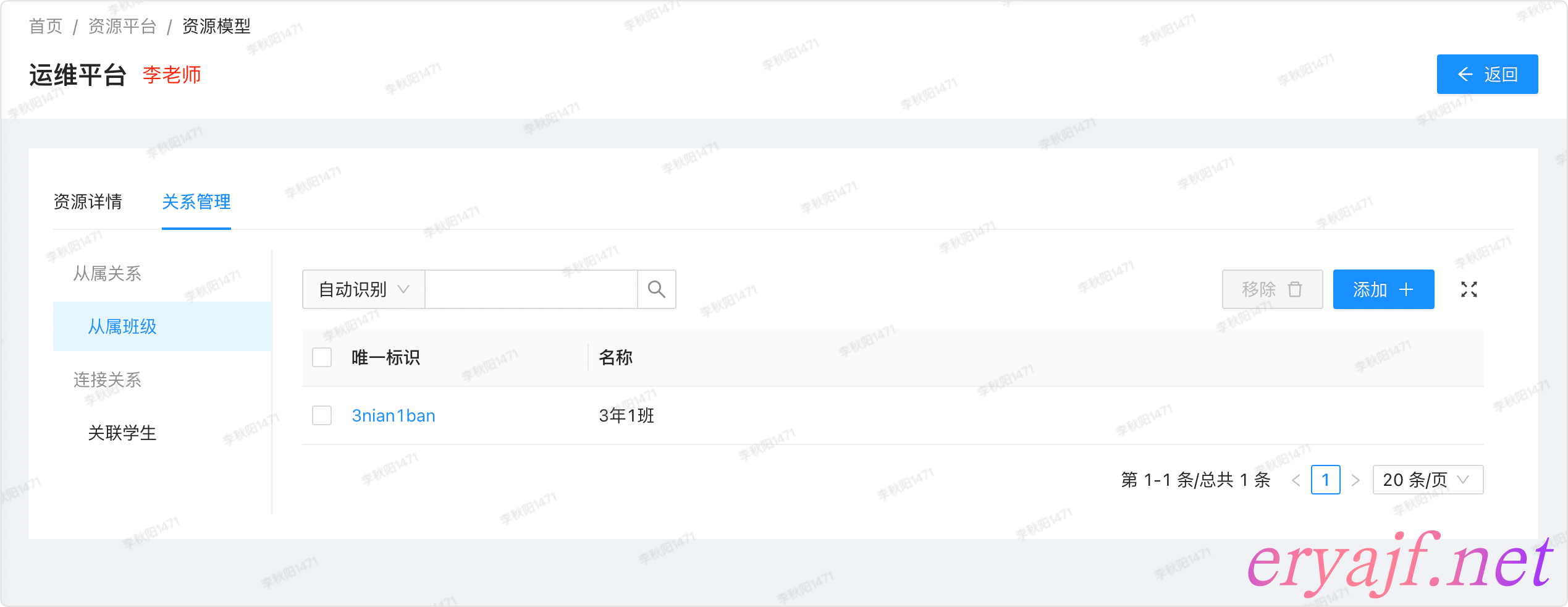
再看连接关系:
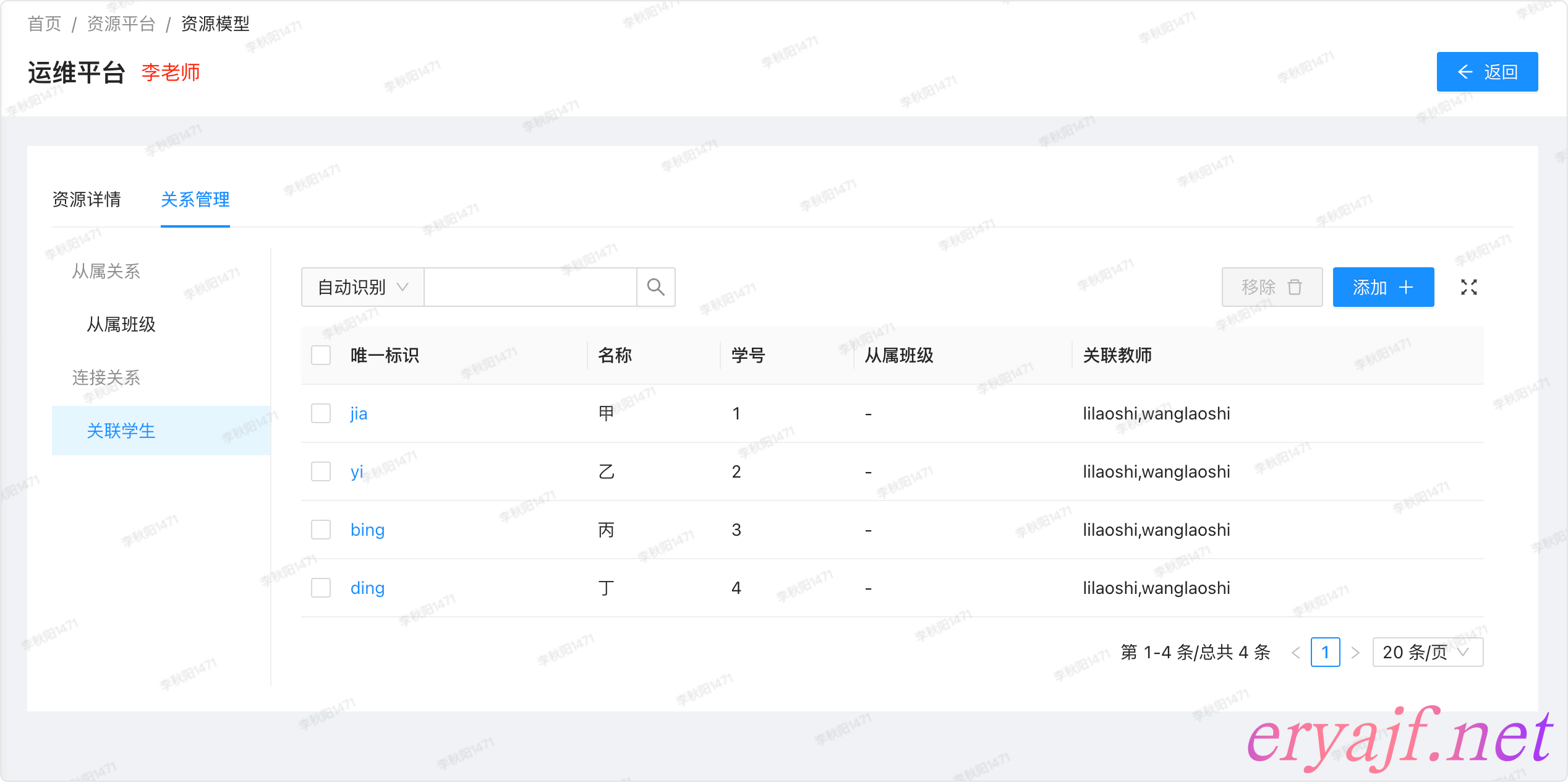
- [ ] 目前展示两种资源信息
- [ ] 资源详情
- [ ] 与模型一致,按字段分组进行展示
- [ ] 关系管理
- [ ] 也是分成从属和连接两种关系进行展示与维护
- [ ] 注意:这里关联的资源,需要在唯一标识上添加对应资源的超链接,从而能够跳转到对应资源的详情页,这是个非常好用且非常重要的小功能。
- [ ] 资源详情
既然可以点击跳转,那我们点击一下学生甲,会在新窗口展示甲的基本信息:
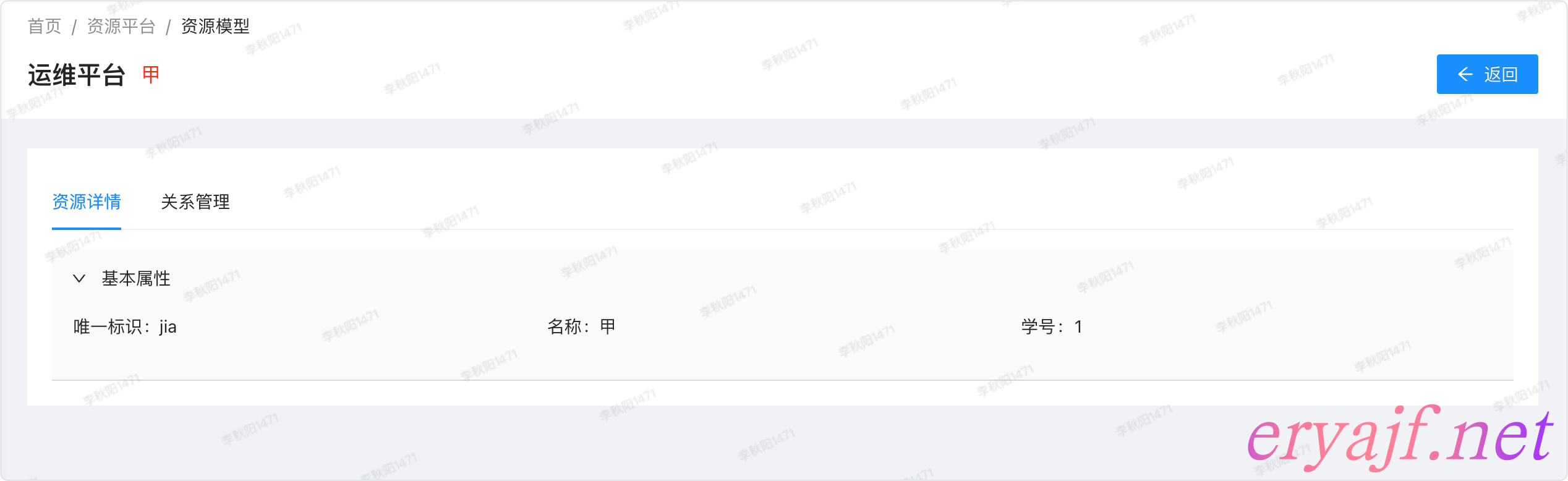
以及同学甲的从属关系:
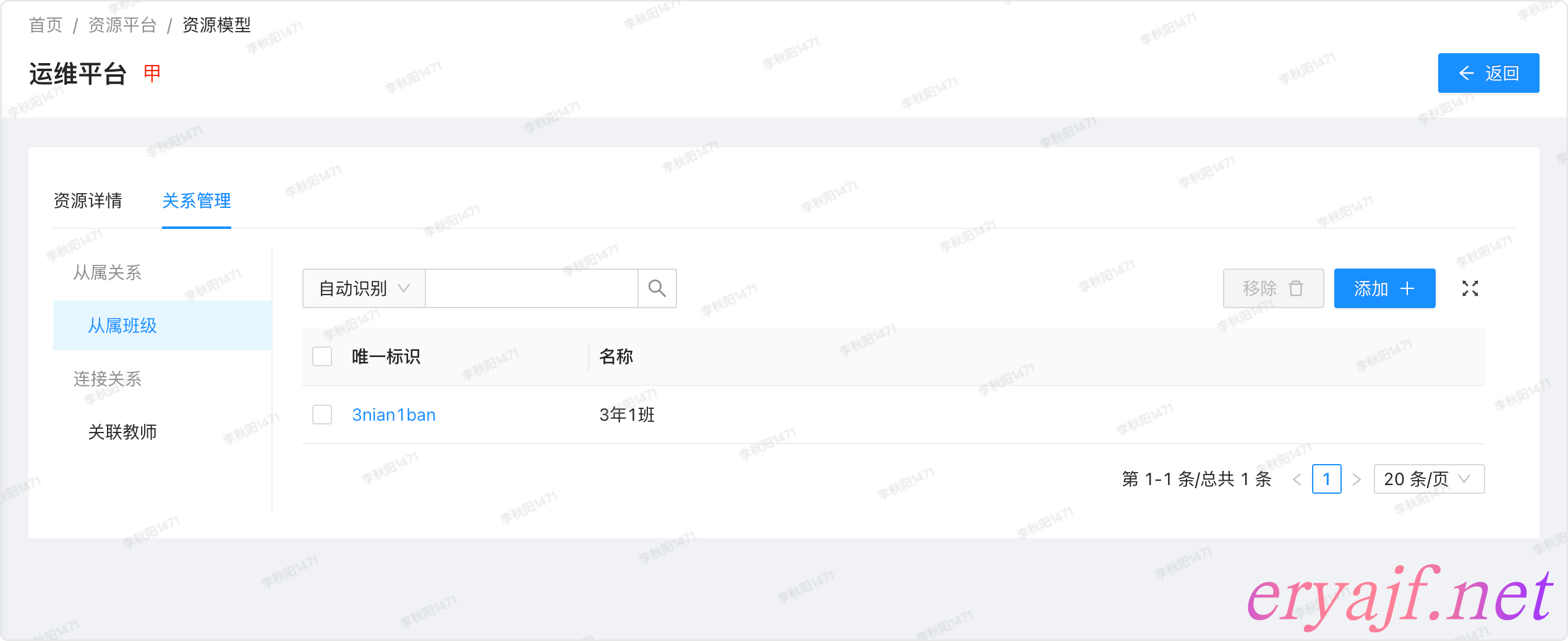
和甲的连接关系:
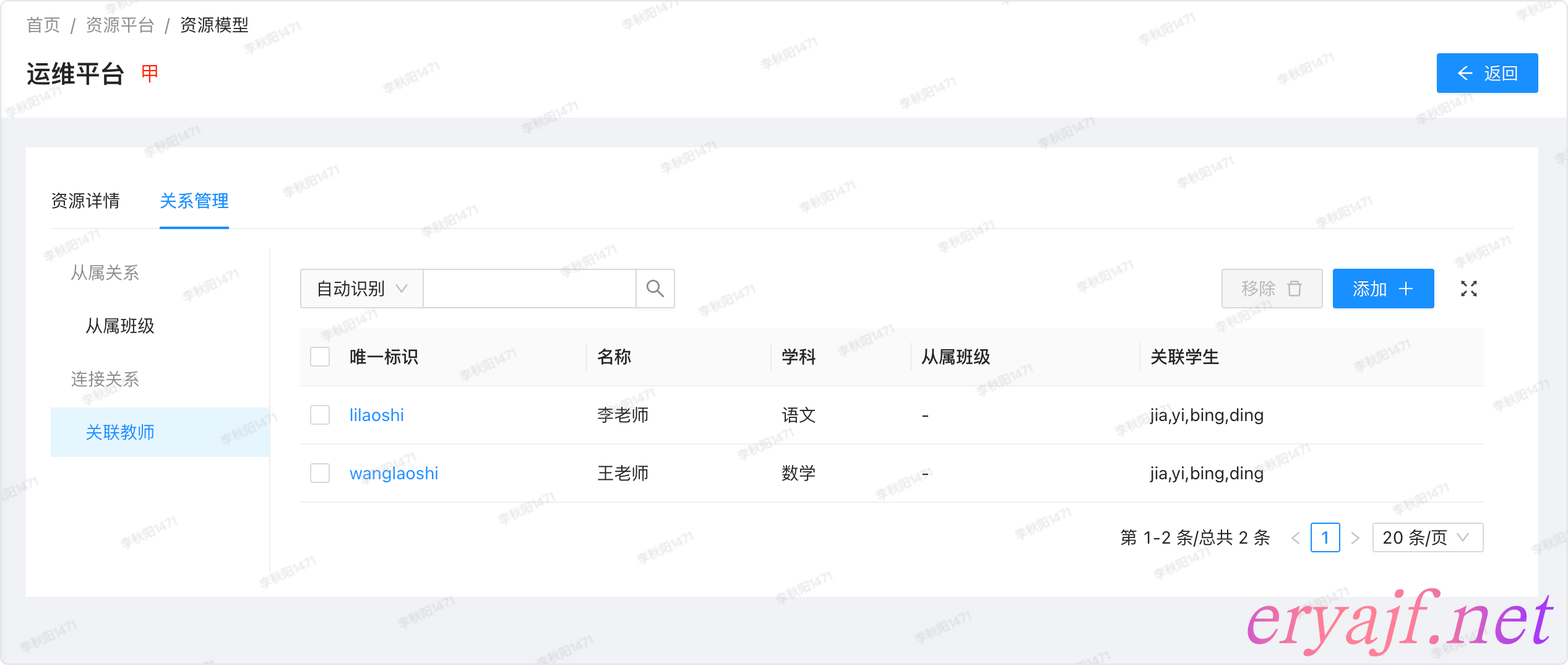
可以看到甲同学所关联的两位老师,最终效果正如我们前边设想的一样。
同理,通过一个内网服务器的 IP,找到它的出口 NAT,就是通过这样的方式来实现的。
其他教师与学生的关系大都类此,因此不再重复截图呈现。
# CMDB 第二阶段开发
# 核心目标
完成云资源基于平台定时任务的落库工作,要求这一期结束之后,云资源能够自动落库,资源关系也要自动维护。
# 时间排期
建议排期为两个月,这一阶段的前后端开发任务比例并不协调,大概是三七开的一个比例。有了第一期模型管理以及资源仓库之后,后端开发者就可以照着云资源的 SDK 编写同步逻辑了。这时就非常考验项目负责人,要把控好不同阶段的工作规划及分配,比如这期前端完成了定时任务的交互页面之后,可以提前着手第三期的标签管理应用视图的开发工作,因为第三期的工作内容,前后端任务比例又反过来了。
这些都是项目 PO 必须要在项目推进过程中考虑的。
# 设计细节
# 定时任务
上边数据仓库的示例中,数据的创建,数据之间关系的维护,全部都是通过手工操作来完成的,非常地繁琐。第二期首先要完成的就是定时任务的管理页面,从而让程序能够自动将云上资源自动获取并落地到本地。
样式示例:
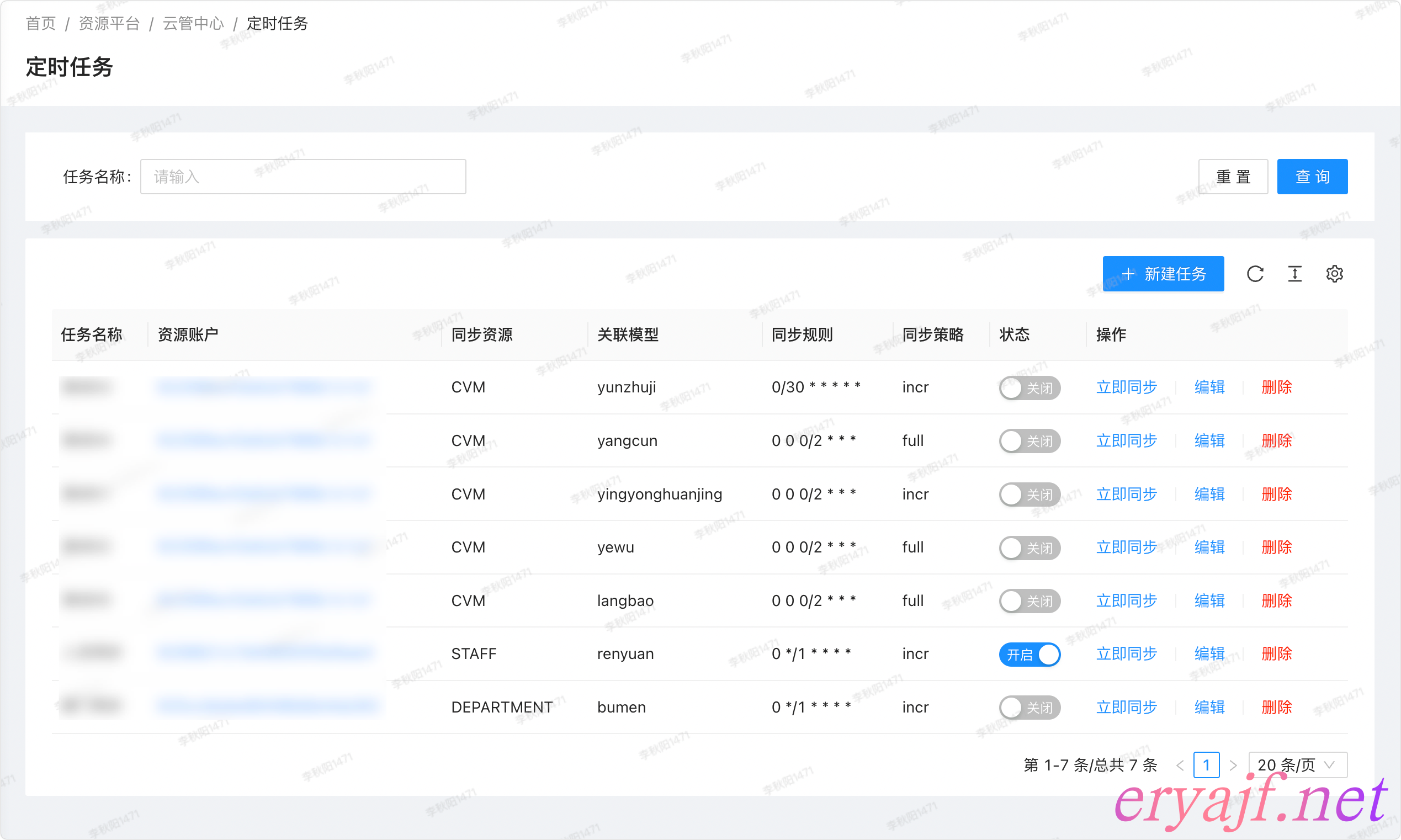
添加任务,云上资源与其他资源一致,不同的是云上资源多了一个扫描可用区的条件选项。
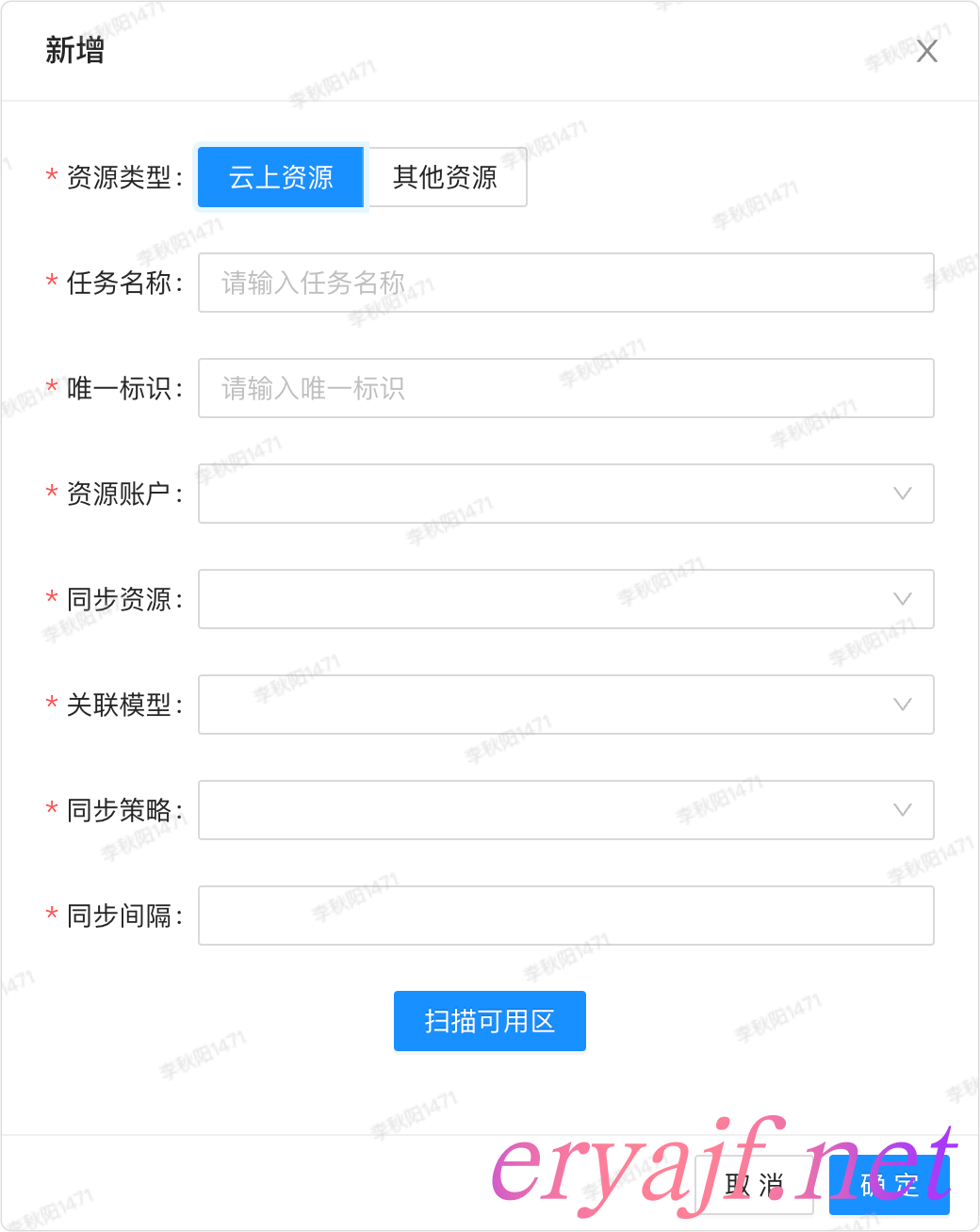
功能细节:
- [ ] 定时任务管理
- [ ] 添加
- [ ] 注意同步策略分为全量和增量两种,设计思考放在后边再讲。
- [ ] 分云上资源,其他资源两种类型
- [ ] 云上资源配置好之后,点击扫描可用区,会将可用区列出来,然后选择需要同步的可用区数据。
- [ ] 添加
当前后端协同完成定时任务接口与页面之后,后端同学就可以开始一一编写云上资源的同步任务了。这个操作以及编码的步骤,我整理如下:
- 配置 scanType 的映射域名,具体域名参考云 SDK 提供的接口文档。
- 通过云控制台拿到远程的一条数据,得到该对象的所有字段。
- 本地创建该对象的模型,字段根据远端字段的列表进行按需创建。
- 后端配置远端和本地模型字段的映射关系。
- 编码开发该资源对象的具体同步逻辑。
- 在 scanType 的资源仓库里面把该资源对象的同步类型添加到库里 (在同步扫描类型这个模型下创建新的 scanType)。
- 在定时任务管理页面添加该资源的定时任务。
- 核查定时任务执行情况。
# 全局搜索
样式示例:
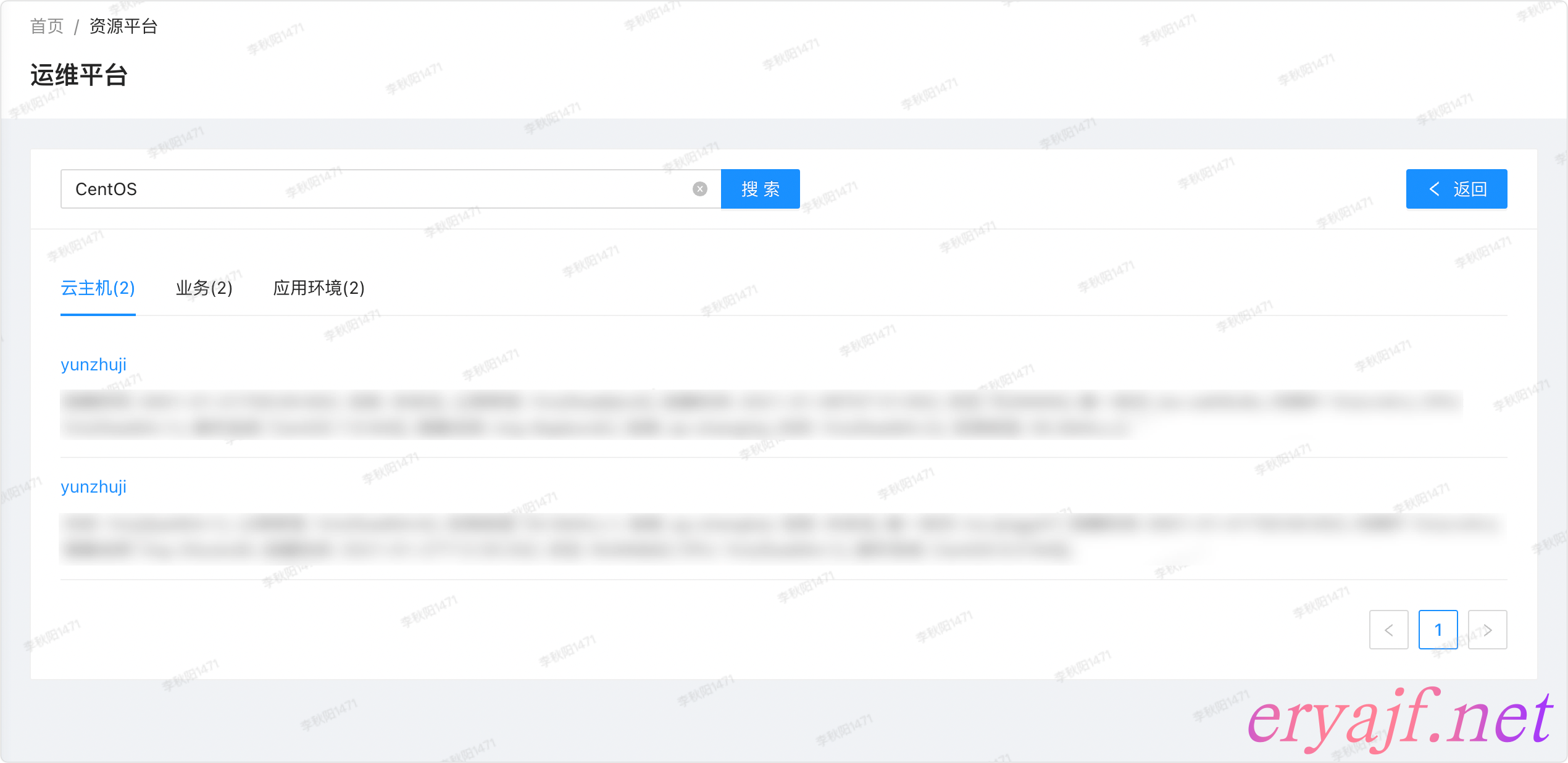
功能细节:
此处是一个单独的页面提供一个搜索框,输入英文或者数字,将会对数据表进行全局搜索。
# CMDB 第三阶段开发
# 核心目标
添加标签管理的能力,完成应用视图。要求这一期结束之后,CMDB 平台进入一个基本可用的状态。
# 时间排期
建议排期为两个月,这一阶段首先要完成的是覆盖全局的标签管理能力,然后再完成应用视图的页面,注意应用的环境管理将借助标签的能力进行二次归纳,这一点会在后边讲到。
我了解过市面上大部分开源的,商业收费的 CMDB 平台,几乎没有一家,能够真正将应用从环境的维度来管理,给做好的,这的确会是一个难题,后边我也会介绍我们在这个过程中的思考,以及为什么选择借助标签来实现环境的管理的。
# 设计细节
# 标签管理
标签也是 CMDB 平台一大重要的设计,许多时候,我们会依赖标签对一批或者某些数据进行标识与管理。
这里先简单说明下标签管理的核心逻辑:
标签管理分标签键和标签值两种,标签键是唯一的,标签值不必唯一,一个标签键可以关联多个标签值,一个标签值可以关联多个资源数据(这里就要求标签值是要与资源仓库的全局进行打通,从而能够提供给用户选择要关联的资源数据)。 这种设计逻辑完成之后,我们就可以通过标签的键值对,过滤搜索我们关心的数据了。
样式示例
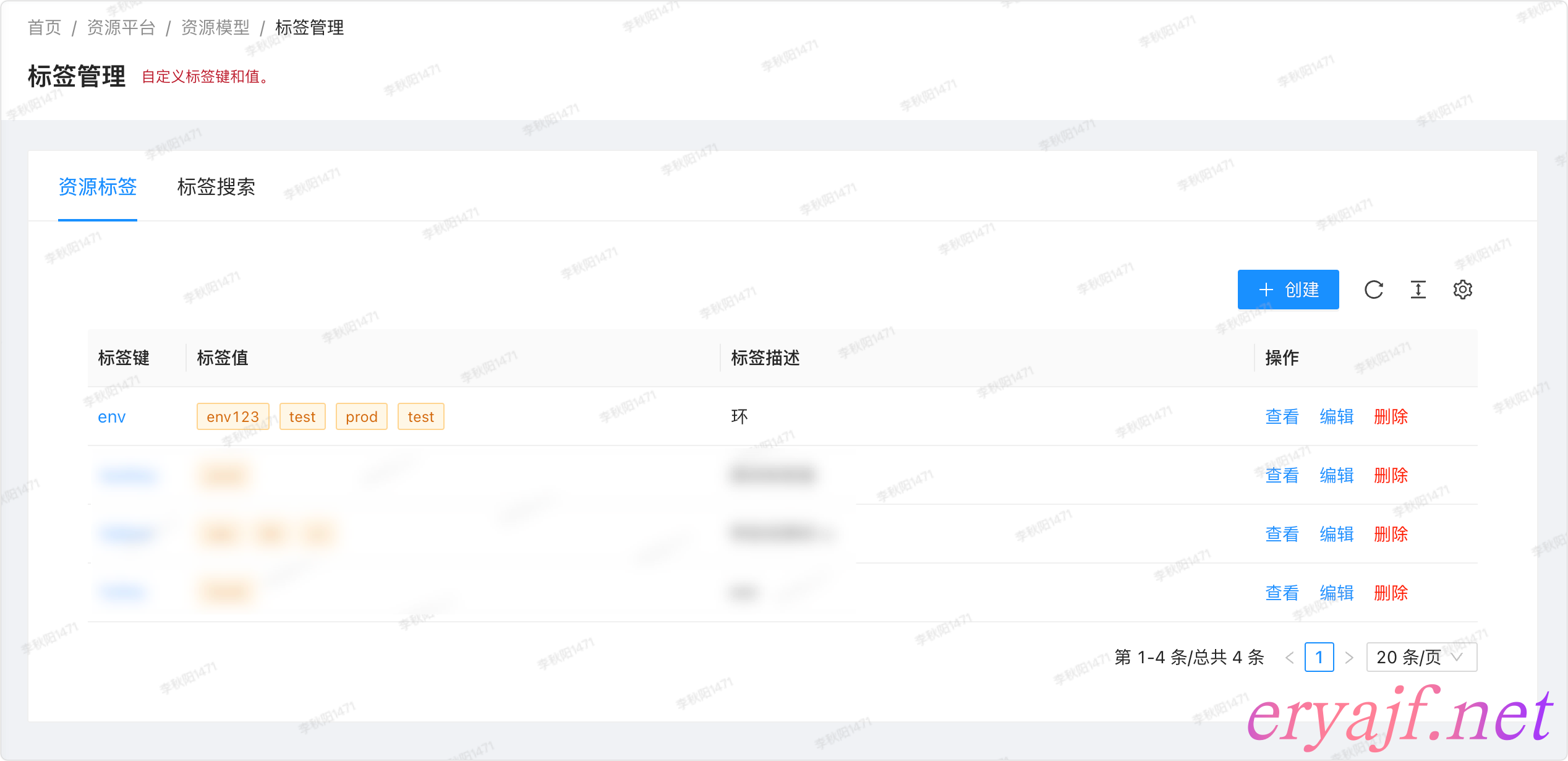
功能细节:
- [ ] 资源标签
- [ ] 创建标签键,标签说明,并且添加标签值
为了说明功能点,这里再次创建一些测试数据:
- 创建一个学科的标签键,包含语文,英语,数学三个值

- 其中语文关联李老师与甲乙两位同学。
- 其中数学关联王老师与丙丁两位同学。
点击查看可以进入到标签的详情:
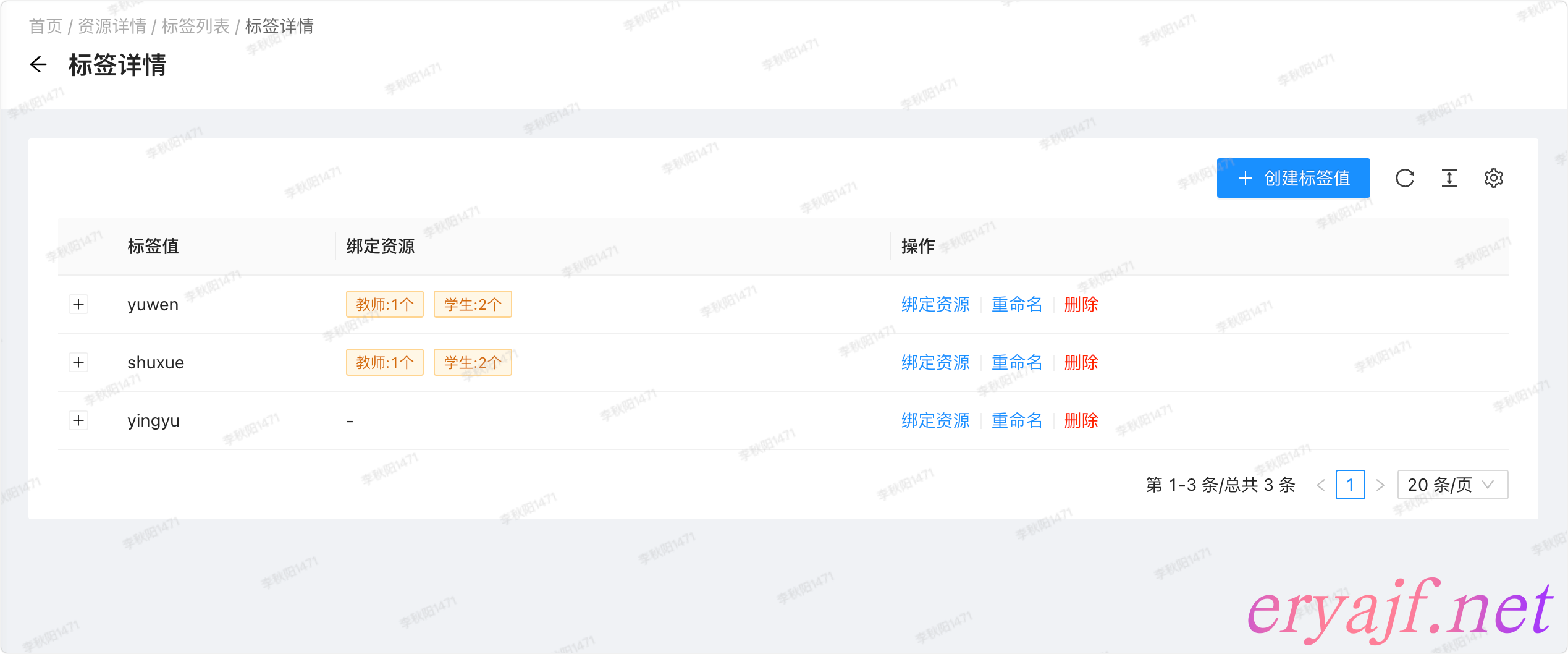
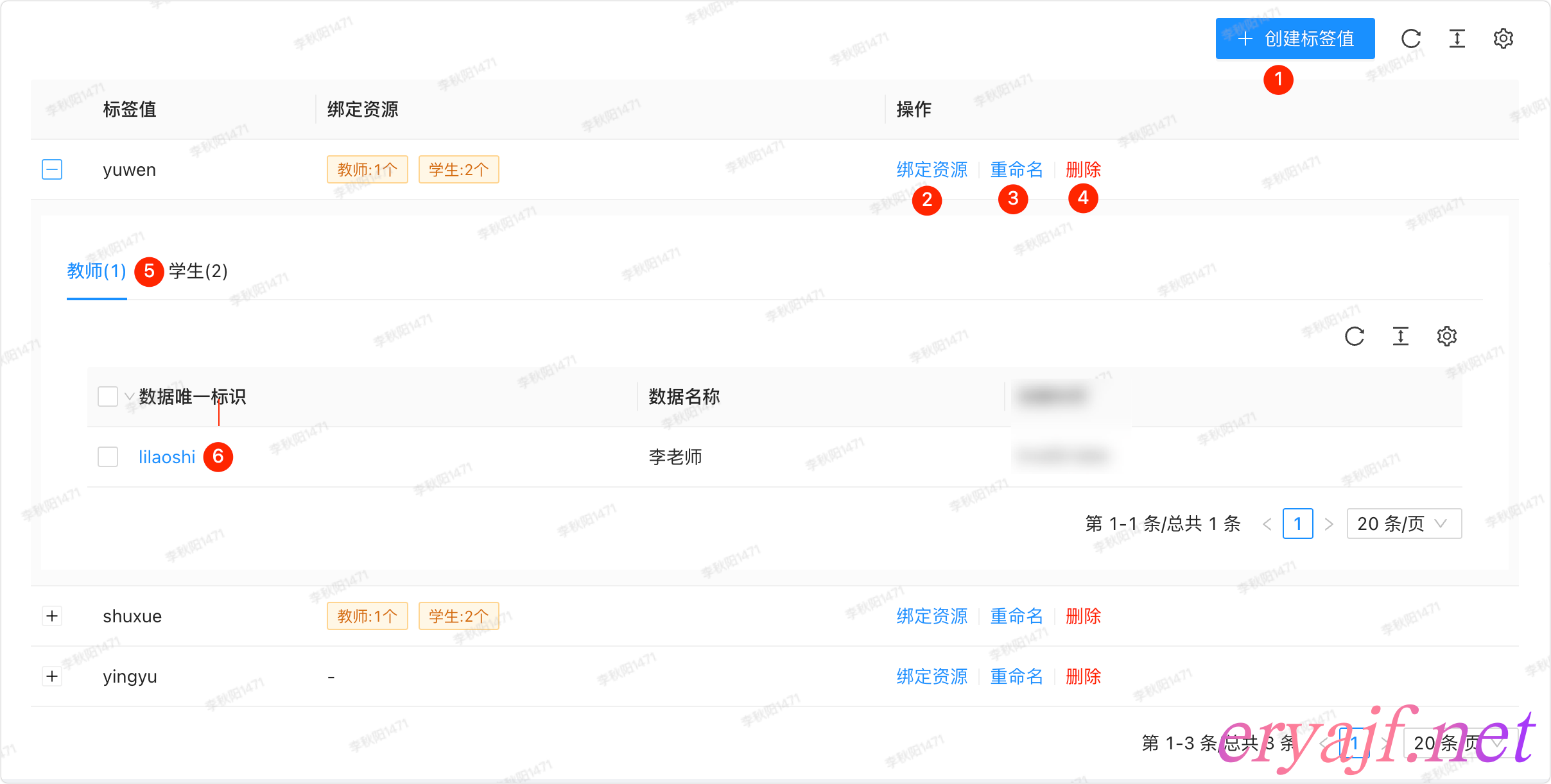
点击左侧+号可以展开标签值关联的数据,我们展开一下 yuwen 看下:
功能细节:
- [ ] 标签值的管理页面
- [ ] 新建,见截图中标号 1
- [ ] 绑定资源,见截图中标号 2
- [ ] 更新,见截图中标号 3
- [ ] 删除,如果标签关联有数据,则不能删除该标签,见截图中标号 10
- [ ] 标签关联数据先以模型作为分类,见截图中标号 5
- [ ] 关联的数据唯一标识同样添加超链接可以跳转到数据详情页,见截图中标号 6
绑定资源的页面视图如下:
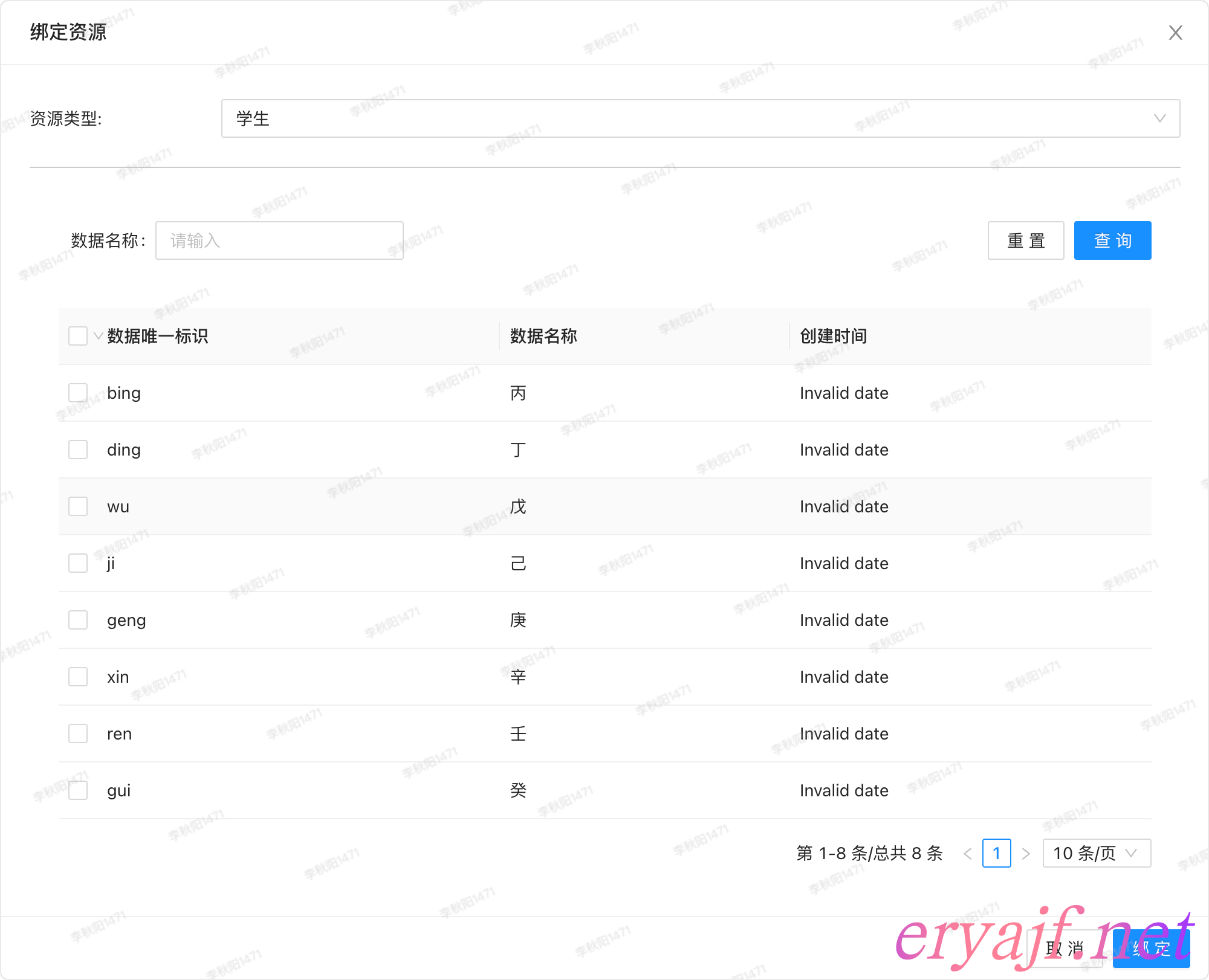
功能细节:
- [ ] 首先选择要绑定的模型
- [ ] 然后从数据列表中选择要关联的数据
- [ ] 有一个可通过名称搜索的框
同理,外边标签搜索页面与绑定资源页面类似:
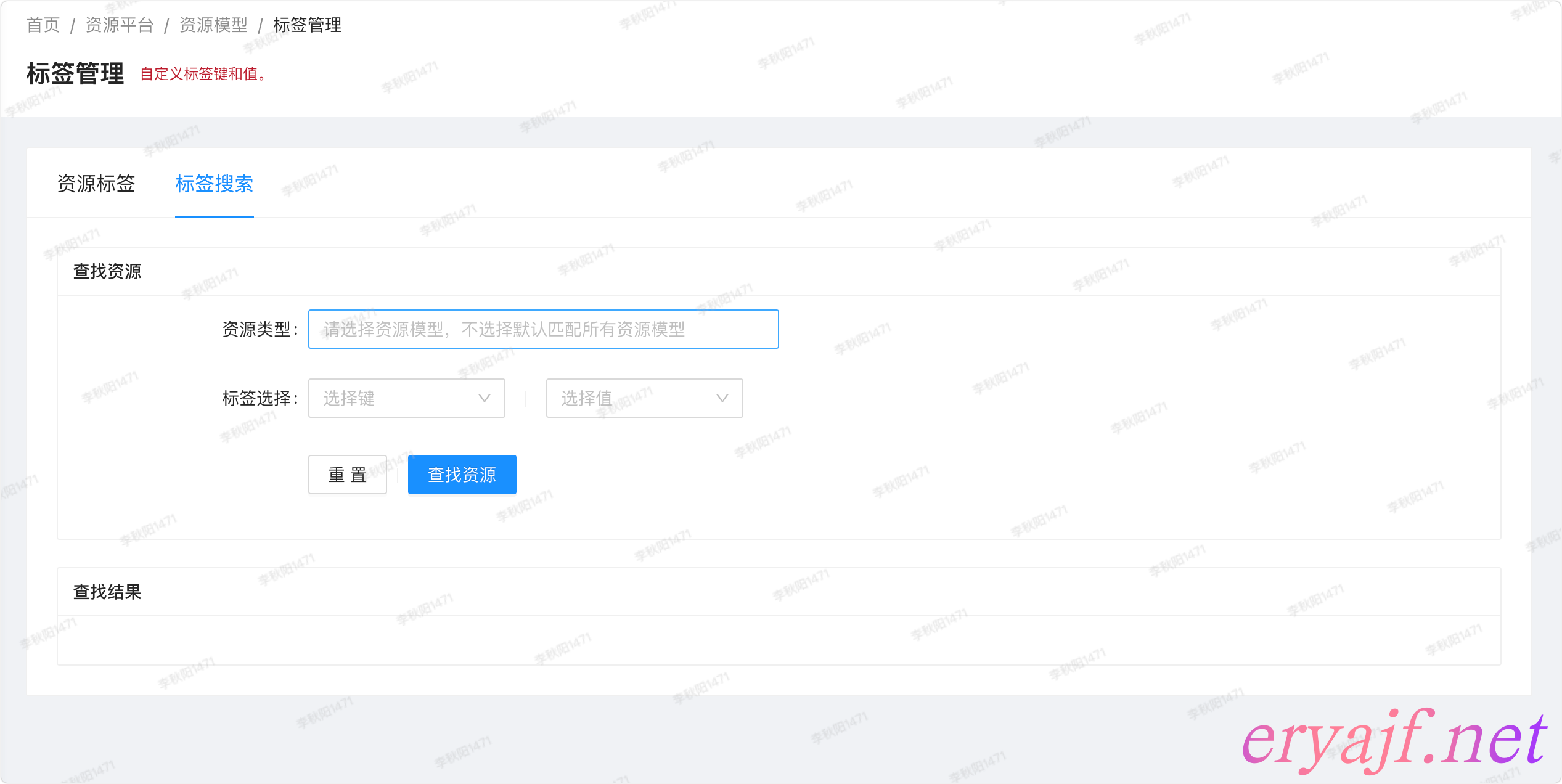
- [ ] 通过标签搜索数据
- [ ] 资源类型:默认过滤所有模型,选择模型之后,则只过滤对应模型
- [ ] 标签选择,选择要过滤的标签
- [ ] 查询之后的结果像标签详情那里分栏展示模型的数据。
# 应用视图
应用视图涉及到内部一些信息,因此这里就拿原型图来做展示及说明。
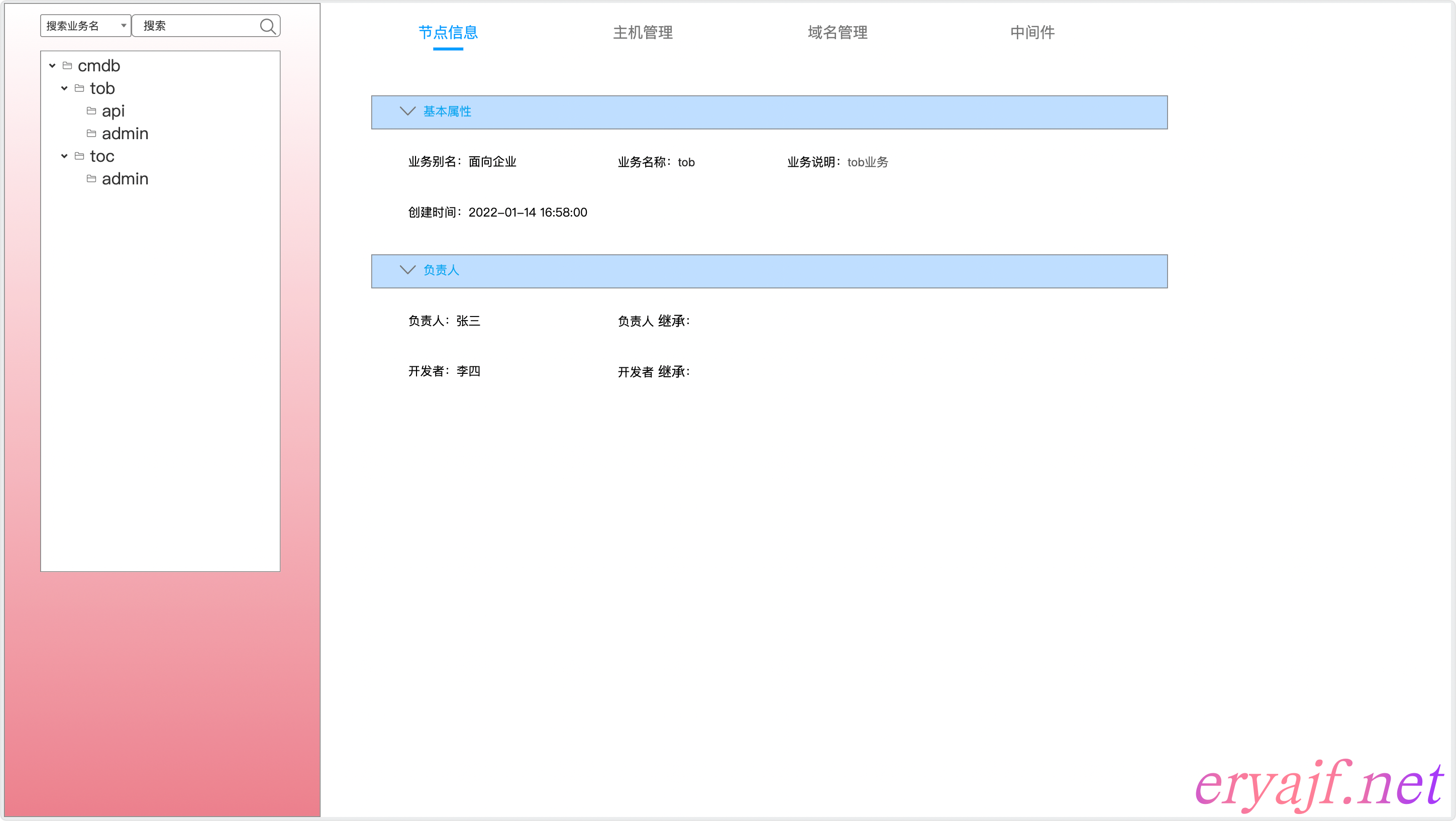
- [ ] 应用视图大概就是如上的一个呈现样式。
- [ ] 左侧是一个树状的业务与应用的分布
- [ ] 一级菜单相当于跟路由
- [ ] 二级菜单表示业务,三级菜单表示应用,应用归属于某个业务。
- [ ] 最多只能三级。
- [ ] 能够通过业务或应用名对其进行搜索。
- [ ] 点击应用时,默认展示该应用的详情
- [ ] 应用关联的主机
- [ ] 应用关联的域名
- [ ] 应用关联的中间件
- [ ] 如上三个资源,均可以通过标签进行环境上的过滤。
主机列表示例如下
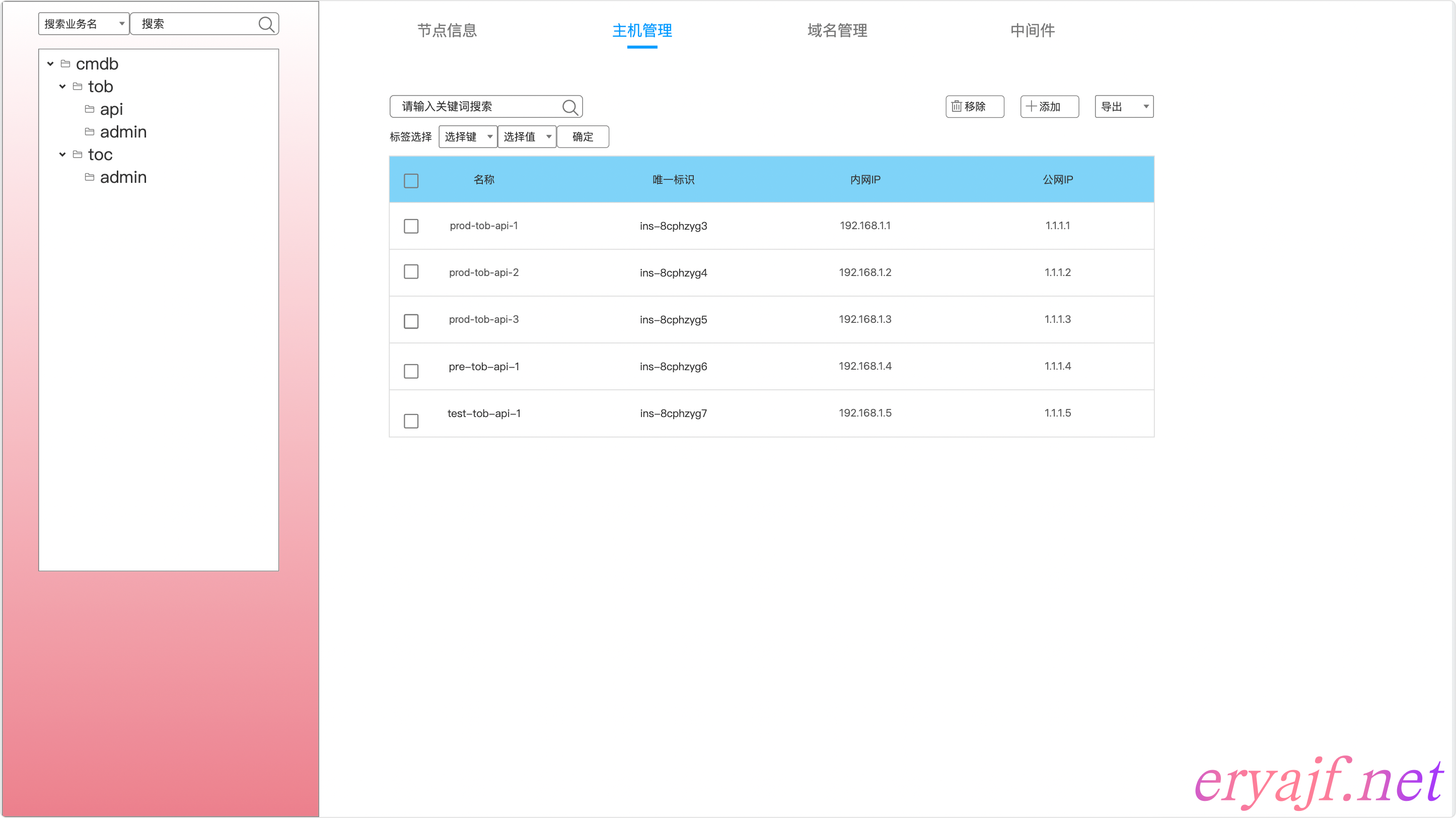
这里主要是通过标签中的环境标识,来区分主机列表中的环境,从而过滤出应用对应不同环境的主机列表。
# 经验分享
# 平台应用的实践推进
这一小节,我们聊聊,一个平台如何渐进式地走入运维组小伙伴们的内心,并夺走他们日常工作的主要关注的。
想要博得大家的关注,我想到了三点:自身硬,常吹风,强约束。
- 自身硬 古语讲:桃李不言下自成蹊,想要吸引人们前来使用平台,给平台提建议,从而促使平台进化,首先平台自身就要有桃李般的甜美才行,即围绕运维的根本痛点考量与设计的平台才能真正获得运维的芳心。
- 常吹风 常吹风体现在宣导上,我从项目未开始的时候就组织会议与大家同步一些平台设计的思路以及理念,以求小伙伴们能够人同此心心同此理。项目推进过程中,一旦有阶段性里程碑,我就会在周会当中与大家同步进展,介绍当下的功能,引导大家了解并体验平台。
- 强约束 强约束分几个层面,一个是自上而下的宣导,也就是说部门领导在项目成败中也起到非常重要的作用,我们要善于借助领导的力量,将一些战略发展性的,命令性的内容经借领导进行下发。另一方面就是其他地方收口,重要功能只能通过平台来完成,比如我们希望项目从产生的时候命名就要规范,而之前因为 GitLab 给了开发者过大的权限,从而很难在一开始就控制这一问题,于是我们把所有普通开发者创建分组和项目的权限给收掉了,以后创建项目只能通过平台来进行,这样即保证了规范交由流程(而非人)约束的原则,也实现了平台集中的愿景。
# 一个资源对象的维护流程
这里将一个资源对象在平台上的维护流程以及一些注意点完整罗列,以便于读者参考时可以方便地了解上手。
# 模型方面
操作之前,首先清空所有的测试数据。
# 模型分组
- 在
资产模型分类下创建公有云的分组 - 在
组织模型分类下创建两个组如下内部组织外部组织
# 模型
所创建的模型以及分组关系如下:
- 组织模型-------------这层是
模型大分类- 外部组织-----------这层是
模型分组- 商务联系人-------这层是
模型- 基本属性------这层是
模型字段分组- 唯一标识----这层是
模型字段
- 唯一标识----这层是
- 基本属性------这层是
- 商务联系人-------这层是
- 外部组织-----------这层是
- 资产模型
- 公有云
- 同步扫描类型
- 公有云
目前先创建这些内容,能够保证云资源的交互可用。
# 模型字段分组及字段
注意: 创建模型的时候需要注意一个细节,模型的 identify 尽量与腾讯云资源的 identify 一致,以便于后续核对排查。
- 组织模型
- 外部组织:waibuzuzhi
- 商务联系人:shangwulianxiren
- 基本属性:shangwulianxiren_basic
- 唯一标识:shangwulianxiren_identify
- 名称:shangwulianxiren_name
- 电话:shangwulianxiren_dianhua
- 邮箱:shangwulianxiren_youxiang
- 关系属性:shangwulianxiren_relation
- 基本属性:shangwulianxiren_basic
- 商务联系人:shangwulianxiren
- 外部组织:waibuzuzhi
- 资产模型
- 公有云:gongyouyun
- 云账户:yunzhanghu
- 基本属性
- 唯一标识:yunzhanghu_identify
- 名称:yunzhanghu_name
- 云提供商:yunzhanghu_yuntigongshang
- 秘钥 ID:yunzhanghu_miyaoID
- 秘钥 Secret:yunzhanghu_miyaoSecret
- 关系属性
- 关联外部联系人:yunzhanghu_guanlianwaibulianxiren,父模型到外部联系人
- 基本属性
- 可用区:zone
- 唯一标识:zone_identify
- 名称:zone_name
- 云主机:instance
- 基本属性
- 唯一标识:instance_identify
- 名称:instance_name
- 内网 IP:instance_neiwangIP
- 状态:instance_zhuangtai
- 实例类型:instance_shilileixing
- CPU:instance_CPU
- 内存:instance_neicun
- 操作系统:instance_caozuoxitong
- 公网带宽:instance_gongwangdaikuan
- 镜像名称:instance_jingxiangmingcheng
- 镜像类型:instance_jingxiangleixing
- 实例计费模式:instance_shilijifeimoshi
- 网络计费模式:instance_wangluojifeimoshi
- 创建时间:instance_chuangjianshijian
- 到期时间:instance_daoqishijian
- 地域:instance_diyu
- 关系属性:当前其他类型暂无,因此关系属性中不创建过多
- 所属可用区:instance_suoshukeyongqu
- 基本属性
- 同步扫描类型:scantype
- 基本属性
- 唯一标识:scantype_identify
- 名称:scantype_name
- 基本属性
- 云账户:yunzhanghu
- 公有云:gongyouyun
其他模型亦按照上边的姿势进行扩展配置同步。
# 标签管理
标签是一个全局数据可关联过滤的系统,目前主要场景会在应用管理界面的环境区分中使用。
# 创建标签
标签是一个独立的 kv 系统,一个标签由一个键多个值组成,键作为一种维度的表意(要求全局唯一),值作为该维度的参数,实际操作中将值与数据进行绑定。
- 创建标签键:environment:环境标识
- test:测试环境
- pre:预发环境
- prod:正式环境
# 关联数据
通过在标签值管理页面,将值关联上所有的资源数据,从而在标签的维度,将所有的数据分成三种环境。
注意: 虽然一条数据能够绑定同一个标签键的不同标签值,但是这里作为环境区隔的时候,并不建议一条数据绑定给多个标签值。换言之,也就是一个资源实例,不能即属于测试环境,又属于其他环境,以做到资源的环境隔离。
在所有云上动作还未集成到平台的时候,可以借助云的一些能力,将数据落实到本地,比如购买云主机的页面,可让腾讯云调配,标签是必填项,那么一台主机在购买的时候,就能做好环境归属的标识工作了。后续集成到平台,则平台的购买流程,同样需要考虑将标签纳入到购买的标准流程中。
# 全量与增量的设计思考
云上的资源我们通过定时任务来进行同步,但是,如果确保本地的数据,对比云上的数据,是准确的,这其实是一个值得思考的问题。
在与小伙伴们讨论分析之后,对于我们现阶段的平台而言,可能将同步任务分割成全量与增量两种比较合适。
- 全量同步比较容易理解,简单讲就是本地与远端保持强一致。
- 增量同步的时候,如果远端没有,本地还有的数据,可以通过标签系统,给这条数据做一个标识,从而能够让运维人员手动将此条数据做状态判断。
在我们的工作场景中,主机的上下线操作是非常频繁的,如果同步任务不能考虑到这种操作毛刺,那么就很容易造成数据不准的问题。于是我们宁愿本地存留一些脏数据,由运维手动来二次确认,也不要简单粗暴地直接将数据删除。
# 笨功夫,为啥删一个模型分组那么难?
吃透了本节内容的同学可能会发现一个细节,这个平台设计上,如果想要删除一个模型分组,其实是非常难的,我整理了一下,大概需要如下步骤:
想要删除一个模型模型分组,首先需要确保该分组下没有模型,然后确保模型下没有模型字段分组,然后确保模型字段分组下没有字段,然后确保模型字段没有数据了,然后才能将模型分组删除。
这么做的目的是:数据的添加或者移除,都要被平台约束,尤其是删除,平台强约束,是保障数据准确的第一个基石。模型分组到最后一条条数据,就是这样的上下关系,如果强行将模型分组删除,就好比直接把一个蜂群的蜂王给干掉了,会让最底层的一条条数据变得无根可依。
# 应用的环境如何更好地管理
市面上大多数 CMDB 平台,对于应用管理的维度,很少有达到环境这一层的,仅见过一两个产品引入了这一概念,却设计不佳,使用麻烦,让人不明所以。
那么应用的环境到底是否重要呢,实际上是非常重要的,我们在制定一些其他规范的时候,环境是一个很重要的参考角度,比如我们制定日志规范,一个应用的所有日志都会在一个集群当中,环境标识就会拼接在应用名后边作为应用对应的日志索引在日志平台进行隔离。
那么,在 CMDB 平台上,应用的环境如何表示?
一开始我想的是,走模型关联的思路,因为上边在模型设计当中讲过,模型可以通过从属和连接两种关系表示资源之间的关系,于是,我们可以这样做:每个应用创建的时候都会再自动创建这个应用关联的三个环境模型,每个环境都会关联云主机等资源,那么就会存在一个问题,一个云主机的模型,最终会被上百个环境进行关联,这是无法接受的。
最后我们决定,走标签搭桥的思路来解决这个问题。
在模型之间,让应用模型直接与其他资源模型进行关联,换言之,资源会首先以应用维度进行区隔,比如 api 应用测试预发正式环境都是两台主机,那么 api 关联的主机资源就是 6 台主机。
然后创建一个环境标识的标签键,标签值有 test,pre,prod,三个标签值去绑定对应环境的资源。
那么一个应用的某个环境的主机列表就可以通过这层关系加上标签过滤给呈现出来了。
# 应用的生命周期的思考与设想
在过往工作过程中,我们发现,有一些应用,说起来已经上线一两周了,然而还会有开发者来找,因为日志没配置采集,不管当事运维是有意还是无意,终究带来的后果是还需要再指派人二次涉足这个应用。有一些应用,明明已经下线了,但是 GitLab 仓库这个项目还好端端躺在那儿,发的 Job 也还在 Jenkins 列表里,甚至主机上进程还在运行着,域名也没有删除,时间久了之后,就没有人能知道这个项目到底是否下线了,这种混淆运维视线的情况,其实最为让人痛心疾首,但是在以往工作中,这些情况却时常存在。
为了应对这种问题,我们甚至专门针对应用上下线,涉及到的各方依赖,做成了流程图来期望能够改善如上描述的问题,但事实证明后来都是收效甚微的。还是那句话,将规范约定交给平台来约束,而不应该单纯靠人的自觉。
比如,我们下线的流程图如下:
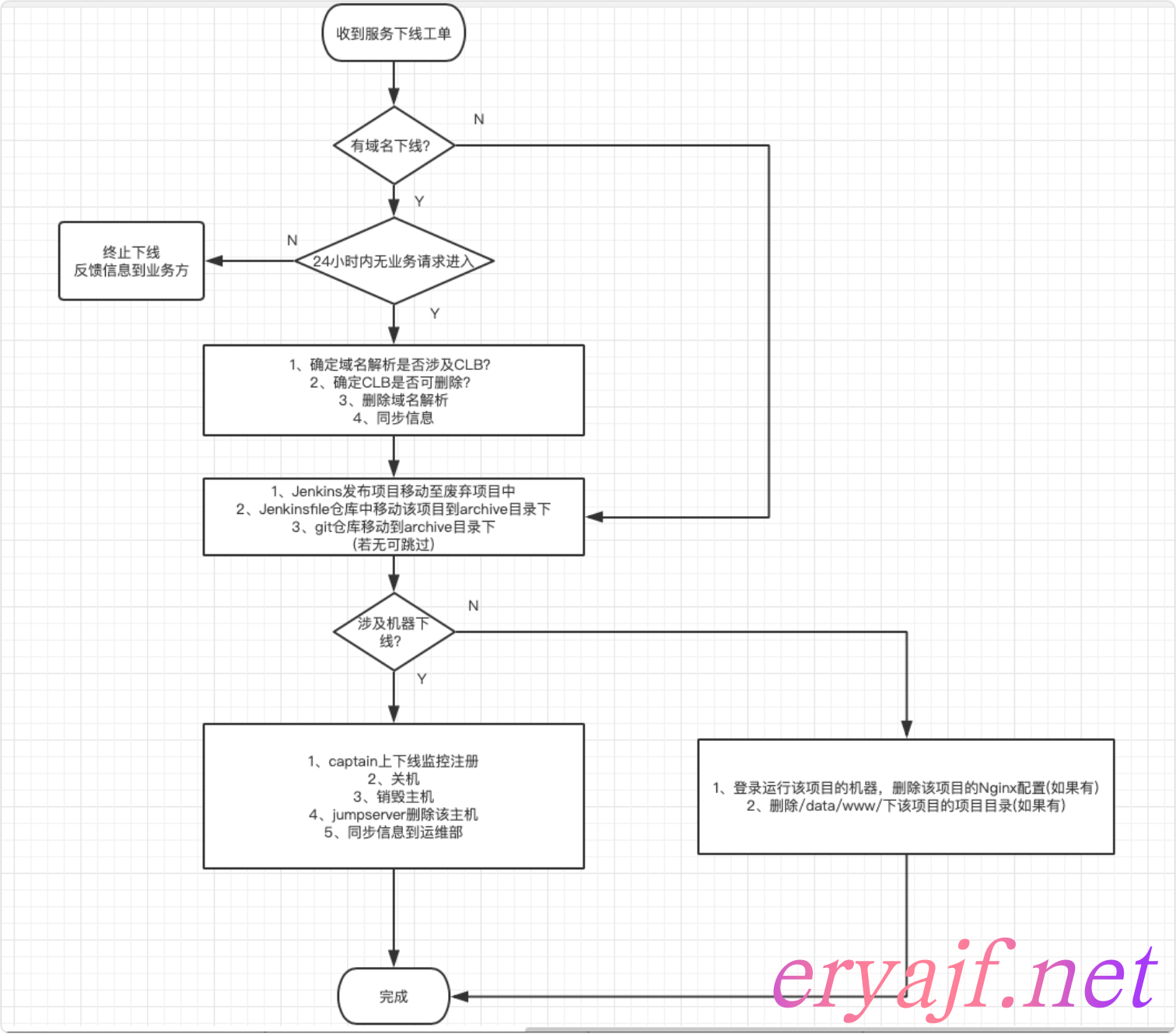
所以,在做平台之初我就一直再考虑,如何才能将这样的流程,结合 CMDB 平台,固化下来,其实就是,应用的生命周期管理。
CMDB 平台上大约有 80% 的数据是自动任务同步上来的,不需要人力介入,还有 20% 则是需要人为介入维护的,其中就包括应用,不过,倒是不必像创建普通数据那样创建应用,而应该把应用的创建集成在工单系统当中来进行流转。
当业务方需要新增一个应用时,要先在工单中提出申请,表单里的内容就是应用对应的字段,提交之后由 leader 进行审核,这一环节主要是核对应用名是否符合规范,应用资源需求是否合理,如果通过之后,将自动把项目在 GitLab 中创建好,然后开发者就可以开始编码了,此时应用的状态为待上线。运维方则可以开始资源准备,环境准备的步骤,这些都在这个应用的上线流程当中,流程还有其他一些配套的步骤,当所有工作做完之后,由运维操作,将应用的状态置为运行中,但是这一个动作会触发一个检测脚本,从而预检一个项目是否还有配套流程没有安排上,如果有步骤未配置到位,则该应用状态无法改为运行中,而不在运行中就意味着,这个应用的上线项目周期是不完整的,自然在产品那里验收也是无法通过的。只有通过这样的强约束倒逼,才能真正将一个应用的各个环节落实到位。
同理,当业务方确认一个应用需要下线,仍旧是先提交应用下线工单,相关配套的下线,就可以做成一个一个的运维脚本来扩展,平台只需要做成一个 checklist,由运维进行操作与核查,只有这些清单都核查过了,方可将该应用置为已下线状态,注意,应用下线,不代表直接将应用从库里删除,一些应用的数据,在很久之后可能还会有查阅的需求,所以应用下线就只需要把应用状态置为已下线即可。
# 开发过程中的一些经验点
本来不打算再分享编程方面的内容,因为自己也属于半路出家自学的go语言,很担心自己的一知半解分享之后误人子弟。但转念又感觉到,对比起来,怯于分享似乎问题更大,文章本身就是写出来供人品评的,如果连分享交流的勇气都没了,前进自然也是困难的。
# MongoDB 自增 ID 的实现
MongoDB 默认的 ID 并不像是 MySQL 那样的自增 ID,如果想要实现自增 ID,则需要借助于另一张表存放该表的 ID,每次存数据的时候,再通过 findAndModify 方法对这个 ID 进行获取并加 1。
# 原生MongoDB语句
$ db.ids.save({name:"user", next_id:NumberInt("0")});
创建一个集合,专门存储其他表的自增信息,默认数字类型是int64,这里通过NumberInt()方法将其指定为int32。
查询该条记录:
$ db.getCollection('ids').find({})
{
"_id" : ObjectId("6234313fb503f6bf2433f4e4"),
"name" : "user",
"next_id" : 0
}
2
3
4
5
6
新增用户的时候,直接调用获取ID:
$ db.user.save({
_id: NumberInt(db.ids.findAndModify({
update:{$inc:{'next_id':NumberInt("1")}},
query:{"name":"user"},
new:true
}).next_id),
username: "eryajf",
site:"https://wiki.eryajf.net"
});
2
3
4
5
6
7
8
9
注:因为findAndModify是一个方法完成更新查找两个操作,所以具有原子性,多线程不会冲突。
然后查询该条记录:
$ db.getCollection('user').find({})
{
"_id" : 1,
"username" : "eryajf",
"site" : "https://wiki.eryajf.net"
}
2
3
4
5
6
# golang的实现
golang的实现与语句差不多,这里只是做示例展示,其中的GetDataID("user")在实际生产使用过程中,需要确保对其错误进行处理。
package main
import (
"context"
"fmt"
"learnmongo/public"
"log"
"math/rand"
"strconv"
"go.mongodb.org/mongo-driver/bson"
"go.mongodb.org/mongo-driver/mongo"
"go.mongodb.org/mongo-driver/mongo/options"
)
var DB *mongo.Database
func init() {
uri := "mongodb://root:[email protected]:27017"
client, err := mongo.Connect(context.TODO(), options.Client().ApplyURI(uri))
if err != nil {
panic(err)
}
DB = client.Database("class")
}
type UserMongo struct {
ID int32 `bson:"_id"`
Name string `bson:"name"`
Phone string `bson:"phone"`
Email string `bson:"email"`
}
func main() {
defer func() {
if err := public.InitDb().Disconnect(context.TODO()); err != nil {
panic(err)
}
}()
fmt.Println("start")
table := DB.Collection("user") // 指定表名为user
_, err := table.InsertMany(context.TODO(), []interface{}{
UserMongo{
ID: GetDataID("user"),
Name: "eryajf" + strconv.Itoa(rand.Intn(11)),
Phone: strconv.Itoa(rand.Intn(11)),
Email: strconv.Itoa(rand.Intn(5)) + "@qq.com",
},
UserMongo{
ID: GetDataID("user"),
Name: "liql" + strconv.Itoa(rand.Intn(11)),
Phone: strconv.Itoa(rand.Intn(11)),
Email: strconv.Itoa(rand.Intn(5)) + "@qq.com",
},
})
if err != nil {
fmt.Print(err)
return
}
fmt.Println("end「👋」")
}
func GetDataID(collname string) int32 {
table := DB.Collection("ids") // 指定表名为ids表
var result struct {
Name string `json:"name" bson:"name"`
NextID int32 `json:"next_id" bson:"next_id"`
}
table.FindOneAndUpdate(
context.TODO(),
bson.M{"name": collname},
bson.M{"$inc": bson.M{"next_id": 1}}).Decode(&result)
return result.NextID
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
自增ID从视觉上更加直观,与DB交互查询的时候也更加简便,某些场景中是可取的方案。CMDB平台中数据存储标签管理都用上了这个能力。
# 全局搜索如何实现
全局搜索的能力主要依赖索引来实现,接下来我们通过一些示例及说明来了解这一功能。
# 准备数据
在开始学习了解之前,先准备一些测试数据如下:
db.datas.insert(
[
{"datas_identify":"eryajf","data":[{"name":"aaa","identify":"aaa-1","create_time":"2020-01-01"}]},
{"datas_identify":"eryajf","data":[{"name":"bbb","identify":"bbb-1","create_time":"2021-01-01"}]},
{"datas_identify":"eryajf","data":[{"name":"ccc","identify":"ccc-1","create_time":"2022-01-01"}]},
{"datas_identify":"eryajf","data":[{"name":"ddd","identify":"ddd-1","create_time":"2023-01-01"}]},
{"datas_identify":"eryajf","data":[{"name":"eee","identify":"eee-1","create_time":"2024-01-01"}]},
{"datas_identify":"liql","data":[{"name":"fff","identify":"fff-1","create_time":"2024-01-01"}]},
{"datas_identify":"liql","data":[{"name":"ggg","identify":"ggg-1","create_time":"2026-01-01"}]},
{"datas_identify":"liql","data":[{"name":"hhh","identify":"hhh-1","create_time":"2027-01-01"}]},
{"datas_identify":"liql","data":[{"name":"iii","identify":"iii-1","create_time":"2028-01-01"}]},
{"datas_identify":"liql","data":[{"name":"aaa","identify":"aaa-1","create_time":"2029-01-01"}]}])
2
3
4
5
6
7
8
9
10
11
12
常规情况下,我们可以针对具体字段进行查询:
db.getCollection('datas').find({"datas_identify":"eryajf"})
db.getCollection('datas').find({"data.name":"aaa"})
这种针对指定字段的查询没有问题,不过如果想要实现一个智能识别的,或者针对当前数据表能够全表搜索的,就需要用到索引了。
# 创建索引
MongoDB可以对任意字段建立全文索引(text index),但需要注意:1个collection中只能包含至多1个全文索引,且只能对String或String数组的字段建立文本索引。
我们可以通过如下命令创建一个文本索引:
db.datas.createIndex({datas_identify: "text"})
这个语句表示将datas_identify字段添加为全文索引,当然也可以指定多个字段,方法如下:
db.datas.createIndex({datas_identify: "text", name: "text"})
执行完毕之后,可以通过如下命令查看当前集合的索引:
$ db.datas.getIndexes()
/* 1 */
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_"
},
{
"v" : 2,
"key" : {
"_fts" : "text",
"_ftsx" : 1
},
"name" : "datas_identify_text",
"weights" : {
"datas_identify" : 1
},
"default_language" : "english",
"language_override" : "language",
"textIndexVersion" : 3
}
]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
- 索引创建之后默认支持的语言是英文,需要注意,MongoDB目前还不支持中文,点击这里 (opens new window)可以查看当前支持的语言列表。
- 当索引字段有多个的时候,可以通过weights字段控制索引字段的权重。
# 数据查询
查询的语句格式如下:
{
$text:
{
$search: <string>,
$language: <string>,
$caseSensitive: <boolean>,
$diacriticSensitive: <boolean>
}
}
2
3
4
5
6
7
8
9
$search:后面跟的是将要搜索的关键字。$language:指定搜索的语言。$caseSensitive:设置是否区分大小写。$diacriticSensitive设置是否区别发音符号。
那么查询 datas_identify为eryajf的方式如下:
$ db.datas.find({ $text: {$search: "eryajf"}})
# 其他进阶
# 数组索引
MongoDB可以给一个数组添加索引,从而提高指定数组的检索效率。
创建一个数组的索引:
$ db.datas.createIndex({"data.name":"text","data.identify":"text","datas_identify":"text"})
然后直接进行检索:
$ db.datas.find({ $text: {$search: "bbb"}})
/* 1 */
{
"_id" : ObjectId("621b7bbff00df89221ebebd6"),
"datas_identify" : "eryajf",
"data" : [
{
"name" : "bbb",
"identify" : "bbb-1",
"create_time" : "2021-01-01"
}
]
}
$ db.datas.find({ $text: {$search: "aaa"}})
/* 1 */
{
"_id" : ObjectId("621b7bbff00df89221ebebde"),
"datas_identify" : "liql",
"data" : [
{
"name" : "aaa",
"identify" : "aaa-1",
"create_time" : "2029-01-01"
}
]
}
/* 2 */
{
"_id" : ObjectId("621b7bbff00df89221ebebd5"),
"datas_identify" : "eryajf",
"data" : [
{
"name" : "aaa",
"identify" : "aaa-1",
"create_time" : "2020-01-01"
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
这是在明确知道数组内字段的情况下的方案,在一些实际应用场景中,一个数组内的字段有可能是不固定的,这种时候就没办法对指定字段进行索引了。这个时候就需要用到全文索引了。
# 全文索引
建立一个通配符全文索引的方法是:
$ db.datas.createIndex({"$**":"text"})
全文索引创建完毕之后,我们可以对整个集合进行检索。
测试效果如下:
$ db.datas.find({ $text: { $search: "aaa" } })
/* 1 */
{
"_id" : ObjectId("621b7bbff00df89221ebebde"),
"datas_identify" : "liql",
"data" : [
{
"name" : "aaa",
"identify" : "aaa-1",
"create_time" : "2029-01-01"
}
]
}
/* 2 */
{
"_id" : ObjectId("621b7bbff00df89221ebebd5"),
"datas_identify" : "eryajf",
"data" : [
{
"name" : "aaa",
"identify" : "aaa-1",
"create_time" : "2020-01-01"
}
]
}
# ============ #
$ db.datas.find({ $text: { $search: "2022" } })
/* 1 */
{
"_id" : ObjectId("621b7bbff00df89221ebebd7"),
"datas_identify" : "eryajf",
"data" : [
{
"name" : "ccc",
"identify" : "ccc-1",
"create_time" : "2022-01-01"
}
]
}
# ============ #
$ db.datas.find({ $text: { $search: "2024" } })
/* 1 */
{
"_id" : ObjectId("621b7bbff00df89221ebebda"),
"datas_identify" : "liql",
"data" : [
{
"name" : "fff",
"identify" : "fff-1",
"create_time" : "2024-01-01"
}
]
}
/* 2 */
{
"_id" : ObjectId("621b7bbff00df89221ebebd9"),
"datas_identify" : "eryajf",
"data" : [
{
"name" : "eee",
"identify" : "eee-1",
"create_time" : "2024-01-01"
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
# 其他补充
基于全文索引的搜索,有一些需要注意的点,这里做一下记录。
- 如果查询中有通配符,使用如下方式转义
$ db.datas.find({ $text: { $search: "\"10.6.6.66\"" } }) - 多条件逻辑或
$ db.datas.find({ $text: { $search: "2024 bbb" } }) - 多条件逻辑与
$ db.datas.find({ $text: { $search: '"2024" "liql"' } }) - 如果想要排除某个结果,则用
-查询$ db.datas.find({ $text: { $search: '"2024" -liql' } }) /* 1 */ { "_id" : ObjectId("621b7bbff00df89221ebebd9"), "datas_identify" : "eryajf", "data" : [ { "name" : "eee", "identify" : "eee-1", "create_time" : "2024-01-01" } ] }1
2
3
4
5
6
7
8
9
10
11
12
13 - golang检索时的代码
type Data struct { DatasIdentify string `json:"datas_identify"` Data []struct { Name string `json:"name"` Identify string `json:"identify"` CreateTime string `json:"create_time"` } `json:"data"` } func FindTest() { filters := bson.D{} filter := bson.E{Key: "datas_identify", Value: "eryajf"} searchFilter := bson.E{Key: "$text", Value: bson.M{"$search": "2022"}} filters = append(filters, filter, searchFilter) datas, err := ListData(filters, options.FindOptions{}) if err != nil { fmt.Printf("get data failed: %v\n", err) } for _, v := range datas { fmt.Println(v) } } // ListData 获取数据列表 func ListData(filter bson.D, options options.FindOptions) ([]*Data, error) { table := DB.Collection("datas") cus, err := table.Find(ctx, filter, &options) if err != nil { fmt.Printf("find data failed: %v\n", err) } defer func(cus *mongo.Cursor, ctx context.Context) { err := cus.Close(ctx) if err != nil { return } }(cus, ctx) list := make([]*Data, 0) for cus.Next(ctx) { data := new(Data) err := cus.Decode(&data) if err != nil { fmt.Printf("decode data failed: %v\n", err) } list = append(list, data) } return list, nil }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
以上就是MongoDB中索引的一些实践,一些内容需要结合实际场景进行使用。
# 最后
以上,便是我个人对于CMDB平台建设的全部思考,但愿这对您是有所帮助的。
只有真正身处其中的人才能体会负责一个平台建设的苦辣酸甜,当平台落地建成之后,这种价值与影响是长久且深远的,祝福每一位,在平台建设之路上顺遂平坦!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK