

一次Java堆外内存排查经历
source link: http://huyan.couplecoders.tech/2023/07/13/%E5%AE%9E%E9%99%85%E6%A1%88%E4%BE%8B/2023-07-13-%E4%B8%80%E6%AC%A1Java%E5%A0%86%E5%A4%96%E5%86%85%E5%AD%98%E6%8E%92%E6%9F%A5%E7%BB%8F%E5%8E%86/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

一次Java堆外内存排查经历
线上有一个服务, 功能比较简单:
- 维护一个map. 包含2亿条数据. 数据更新频率很高. 但是很少移除.
- 对外提供接口, 接口职责: 查询n次map. 对结果进行一些计算(计算逻辑与本文无关,不提)后返回.
服务的简化代码如下:
public class Demo {
/*
缓存数据结构
*/
static class Data {
int id;
public Data(int id) {
this.id = id;
}
// other fields
}
// 缓存数据
private Map<Integer, Data> cache = new HashMap<>(100000000);
// 对外接口. 查询缓存后计算返回.
public List<Data> compute(List<Integer> keys) {
List<Data> res = new ArrayList<>();
for (Integer key : keys) {
res.add(this.cache.get(key));
}
// 计算逻辑, 这里忽略掉.
return res;
}
public static void main(String[] args) {
Demo demo = new Demo();
// 填充缓存
for (int i = 0; i < 100000000; i++) {
demo.cache.put(i, new Data(i));
}
// 对外接口使用, 线上是RPC接口,这里模拟调用即可. 100次.
ThreadLocalRandom r = ThreadLocalRandom.current();
for (int i = 0; i < 100; i++) {
// 每次请求800个随机ID.
List<Integer> keys = new ArrayList<>();
for (int j = 0; j < 800; j++) {
keys.add(r.nextInt());
}
List<Data> result = demo.compute(keys);
// 使用接口的结果.
}
}
}
接口QPS较高, 大概单机2w+.
遇到问题:
随着map中维护条目数据量增加. 在业务高峰期, 频繁触发GC. CPU load很高,影响对外服务稳定性.
使用堆外缓存
前面提到, map中数据, 很少移除. 因此参与GC的意义不大. 白白浪费CPU时间.
GC时, 扫描全部堆(大概140G). 发现其中100G+都无法释放,只能处理20G左右. CPU: 好玩是吧?
因此考虑将缓存移动到堆外. 仍旧能以不错的性能提供缓存功能, 同时不参与gc. 让JVM每次gc的压力变小.
经过简单的调研, 觉得确实有搞头.
优点是直接在 heap区内读写,速度快
缺点是缓存的数据量非常有限
同时缓存时间受 GC影响
数据过多会导致GC开销增大,从而影响应用程序性能
读写比堆内相对要慢
优点是堆外空间不受GC影响
缓存数据量较大(G以上级别)时, 且仍有较高的性能
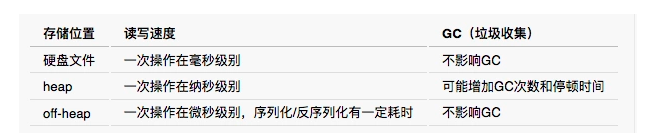
- 缓存介质性能(估算)
主流堆外缓存:
OHCache:支持缓存驱逐和过期(Cassandra/HugeGraph使用的缓存库)
ChronicleMap:支持Hash结构,性能好,不支持缓存驱逐
MapDB:支持Tree结构,可顺序扫描,不支持缓存驱逐
Ehcache3:BigMemory收费
选择了网上资料最多的OHC框架来实现堆外缓存.
OHC的基础原理以及使用案例这里不再赘述. 给出官方文档以及一个不错的入门示例:
经过简单的修改, 我们使用OHC作为堆外缓存实现的代码, 变成了:
public class DemoOHC {
/*
缓存数据结构
*/
static class Data {
int id;
public Data(int id) {
this.id = id;
}
// other fields
}
static class IntSerializer implements CacheSerializer<Integer> {
@Override
public void serialize(Integer integer, ByteBuffer byteBuffer) {
byteBuffer.putInt(integer);
}
@Override
public Integer deserialize(ByteBuffer byteBuffer) {
return byteBuffer.getInt();
}
@Override
public int serializedSize(Integer integer) {
return 4;
}
}
static class DataSerializer implements CacheSerializer<Data> {
@Override
public void serialize(Data value, ByteBuffer buf) {
buf.putInt(value.id);
}
@Override
public Data deserialize(ByteBuffer buf) {
return new Data(buf.getInt());
}
@Override
public int serializedSize(Data value) {
return 4;
}
}
// 缓存数据
private final OHCache<Integer, Data> cache = OHCacheBuilder.<Integer, Data>newBuilder()
.keySerializer(new IntSerializer())
.valueSerializer(new DataSerializer())
.capacity(85 * 1024 * 1024 * 1024L) // byte
.eviction(Eviction.LRU)
.throwOOME(true)
.build();
// 对外接口. 查询缓存后计算返回.
public List<Data> compute(List<Integer> keys) {
List<Data> res = new ArrayList<>();
for (Integer key : keys) {
res.add(this.cache.get(key));
}
// 计算逻辑, 这里忽略掉.
return res;
}
public static void main(String[] args) {
DemoOHC demo = new DemoOHC();
// 填充缓存
for (int i = 0; i < 100000000; i++) {
demo.cache.put(i, new Data(i));
}
// 对外接口使用, 线上是RPC接口,这里模拟调用即可. 100次.
ThreadLocalRandom r = ThreadLocalRandom.current();
for (int i = 0; i < 100; i++) {
// 每次请求800个随机ID.
List<Integer> keys = new ArrayList<>();
for (int j = 0; j < 800; j++) {
keys.add(r.nextInt());
}
List<Data> result = demo.compute(keys);
// 使用接口的结果.
}
}
}
直接在灰度环境开始运行~. 起初一切良好. 我以20G的JVM堆,100G堆外内存配置. 成功运行了服务. (之前以120G的JVM运行, GC特别严重.)
但是很快问题出现了. 在接入线上小流量之后, 机器内存占用持续升高. 如下图:
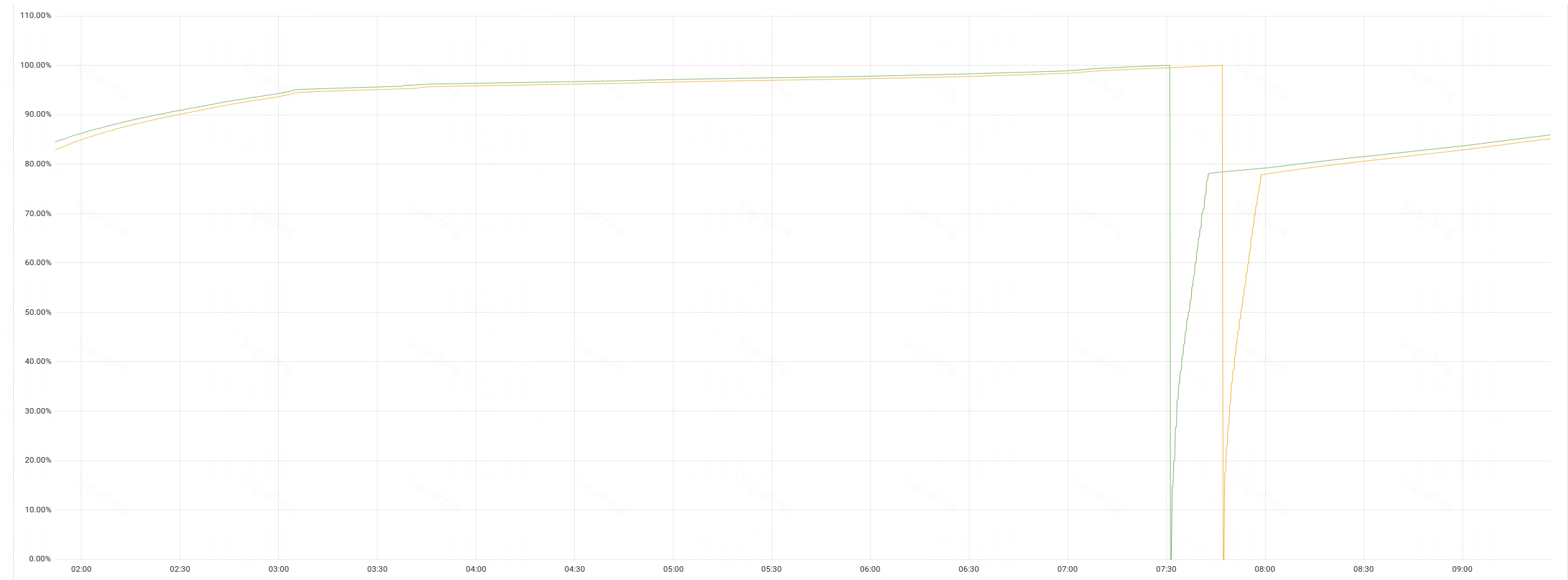
在服务启动, 加载数据期间, 内存占用快速上升, 之后的几个小时内, 内存占用缓慢上升,直到到达 物理内存上线, 程序OOM进行重启.
排查内存泄漏
物理内存共150G, 程序申请了20G JVM堆, 以及100G的堆外缓存. 理论上至少还有20+G的空闲, 但是机器内存爆掉了. 且从top命令结果来看, 确实是该进程占用内存达到了150G.
友情提示: 在排查过程中, 避免JDK13+ZGC的组合. ZGC会导致观测到的内存占用翻了三倍(堆占用). 虽然不影响实际内存占用, 但是会严重的扰乱排查过程.
排查过程中, 我被折磨许久后, 临时切换至G1GC, 豁然开朗.
参考: https://www.jianshu.com/p/7ace41894c41
第一个排查思路就是: 产生了堆外内存泄漏.
JVM内存占用
首先, 确认下JVM堆的配置,以及占用是否正常.
使用命令 jhsdb jmap --heap --pid pid 查看 JVM占用. 结果如下:
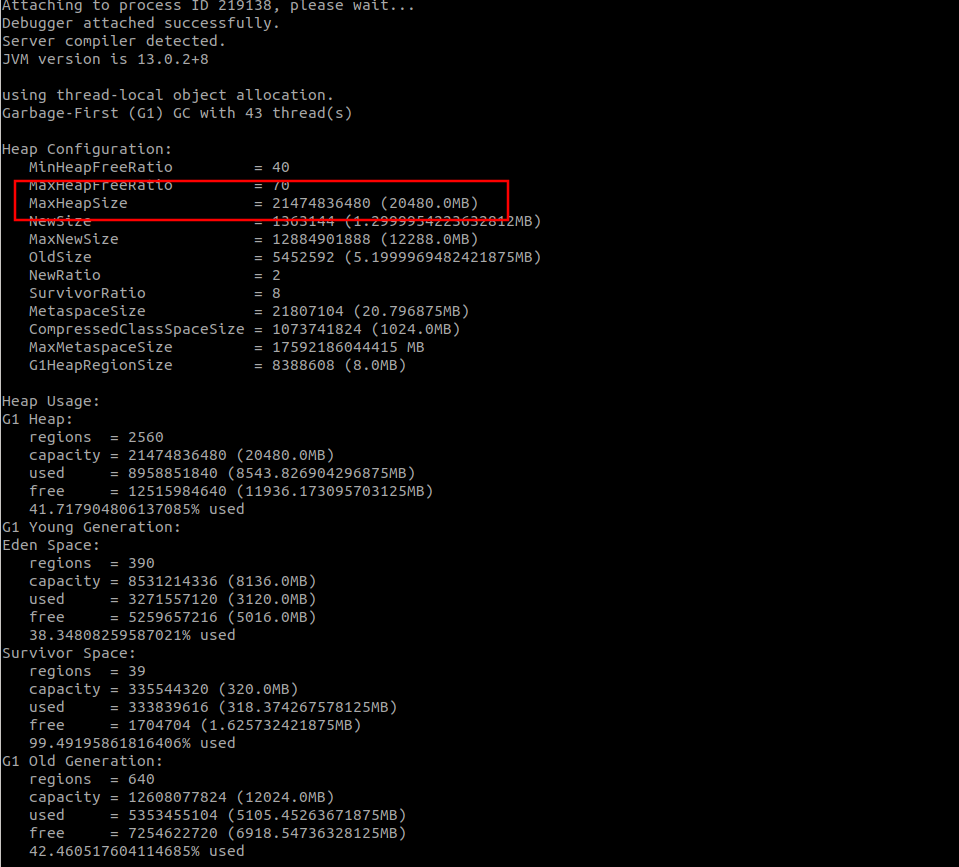
可以看到其中 MaxHeapSize=20480.0MB. 也就是说. 我们的JVM堆确实是占用了20G.
从JVM提供的查看(堆内内存、Code区域或者使用unsafe.allocateMemory和DirectByteBuffer申请的堆外内存)工具来看.
在项目中添加-XX:NativeMemoryTracking=detailJVM 参数重启项目,使用命令jcmd pid VM.native_memory detail 查看到的内存分布如下:
其中JVM相关的部分:
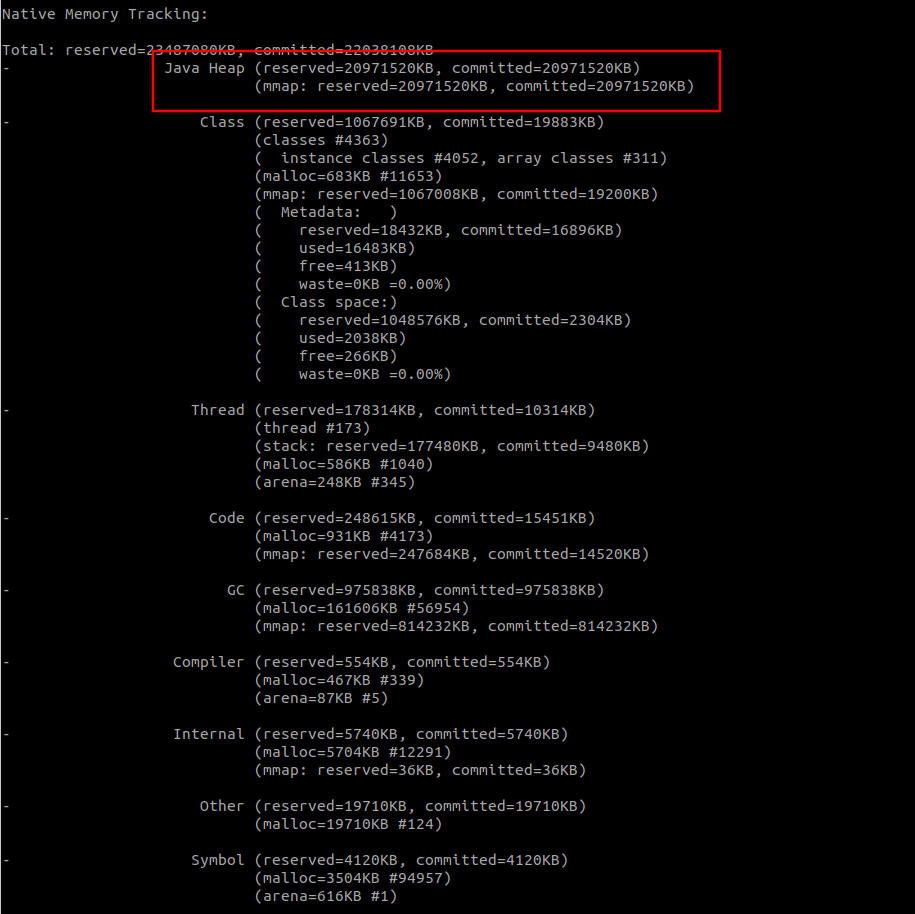
可以看到Java Heap 也是使用了20G. class thread 等其他部分, 占用量很少.
该命令, 还可以帮助我们查看部分堆外内存的占用, 主要是通过JDK提供的接口来申请的堆外内存. 包括使用unsafe.allocateMemory和DirectByteBuffer申请的堆外内存.
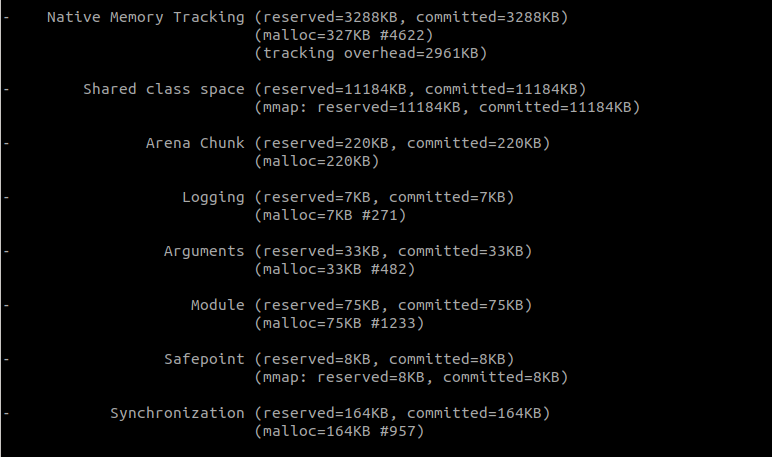
可以看到堆外内存占用量很少. 因为:
- 我们使用的OHC, 申请堆外内存,并不是通过这两个接口, 因此不在监控内.
- “可能发生的内存泄漏”, 也不是使用这两个接口申请的.
OHC缓存占用
堆外内存并没有特别好的观测方法, 我们使用定时打印OHC缓存统计信息, 来判断OHC缓存占用.
OHCacheStats{hitCount=1503972, missCount=23014, evictionCount=0, expireCount=0, size=167057308, capacity=91268055040, free=10803907716, rehashCount=1024, put(add/replace/fail)=167057308/0/0, removeCount=0, segmentSizes(#/min/max/avg)=128/1300746/1308479/1305135.22, totalAllocated=-1, lruCompactions=0}
根据上面的统计信息, 我们可以看到, 这次测试中, 我们给了85G的堆外内存容量, 当前只使用了75G左右. 远远没有达到100G. 更何况150G的物理内存.
物理内存占用
我们使用pmap -x pid | sort -k 3 -n -r 命令, 查看该进程占用的所有内存:
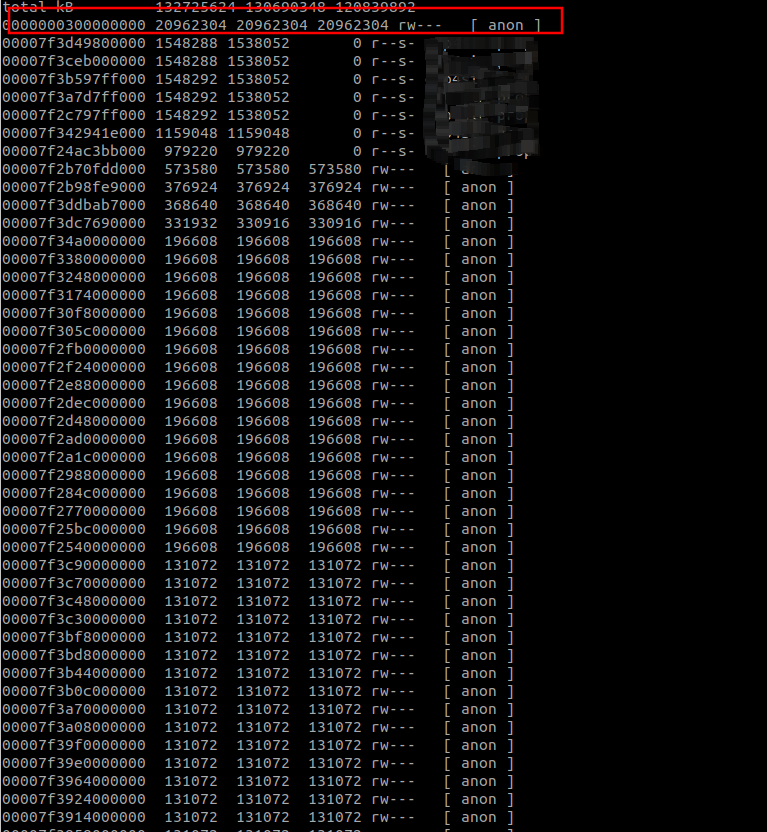
最上面是一整块内存, 是JVM占用的20G. 除此之外有部分是缓存对象. 也没有找到明显的, 可疑的内存占用.
至此, 得到的结论是:
- 150G物理内存, 确实是被该进程占用了.
- JVM堆占用了20G. 通过OHCCache自带的统计来看, OHCache 使用量远远不足100G.
- 其他堆外内存, 没有有效观测手段.
因为是引入堆外内存后出现的问题, 因此首先怀疑OHC导致的, 主要有两个方向:
- OHC 存储我们的缓存之外,还有一些额外的堆外内存占用. 且没有统计到内存占用量中.
- OHC 包有bug. 尤其是发生 put 时, 没有释放掉老的对象的内存.
OHC 额外内存占用
我使用的是OHCCache的OHCacheLinkedImpl实现. 查看源码后发现, 在put方法org.caffinitas.ohc.linked.OHCacheLinkedImpl#putInternal的实现中, 计算写入当前k=v需要的内存大小时, 使用了org.caffinitas.ohc.linked.Util#allocLen 方法. 实现如下:
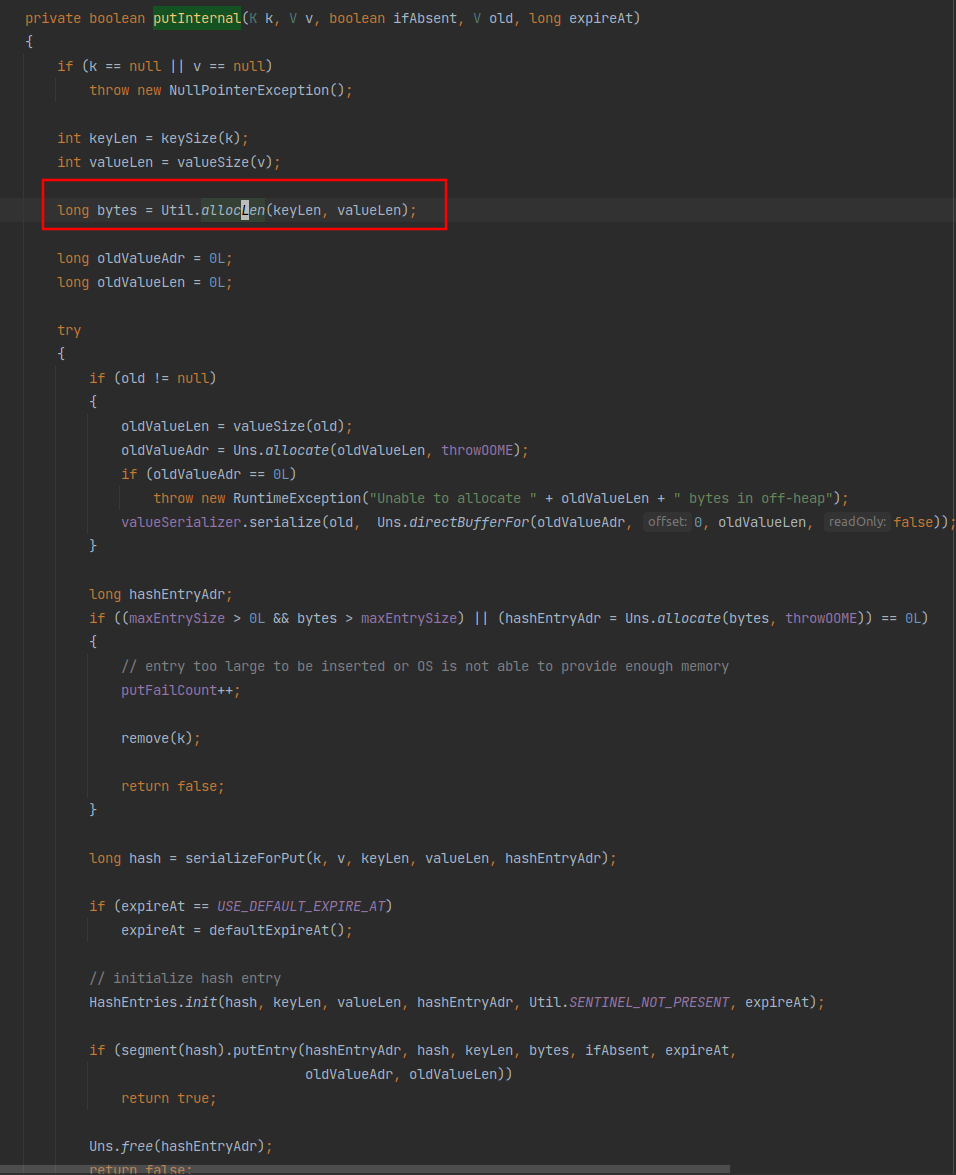
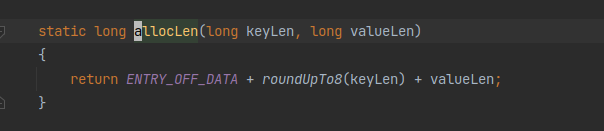
已经提前计算了存储需要的额外内存占用, 主要是:
- 对key进行8位补齐.
- 64位的额外信息存储.
因此, OHC使用的所有堆外内存, 应该都是在内存统计信息中的. 也就是说, OHC没有占用更多的堆外内存了.
OHC put未释放旧内存
首先, 怀疑这个问题就显得我很蠢, 而且我在这个问题上花费了一下午时间….
首先, 这是OHC 最基本的能力, 不应该会有bug. 尤其是在应用如此广泛的情况下.
其次, 我简化代码, 单元测试. 在本地启动程序, 调用Cache.put().
- 缓存中不存在, 大量新增.
- 缓存中存在, 大量替换.
这两种情况下, 堆外内存的占用, 都是比较稳定的.
病急乱投医
排查陷入僵局, 我开始在网上搜索, 试错. 甚至在StackOverFlow提了一个问题, 可惜没有人回答我.
元空间内存泄漏
Java8之后, 元空间的默认大小时机器物理内存大小,理论上存在内存泄漏可能性. 元空间内存泄漏排查案例 这篇文章讲的挺好, 可惜经过验证, 不符合我的情况.
glibc
在网上看到很多内存泄漏的文章, 提到使用pmap查看内存区域时, 有大量64M内存块, 导致内存泄漏.
文章指出造成应用程序大量申请64M大内存块的原因是由Glibc的一个版本升级引起的,通过export MALLOC_ARENA_MAX=4可以解决VSZ占用过高的问题。虽然这也是一个问题,但却不是我们想要的,因为我们增长的是物理内存,而不是虚拟内存。
不过不死心的我, 还是尝试了export MALLOC_ARENA_MAX=4, 限制使用的内存池数量, 之后启动进程, 问题依旧~.
网上有很多文章, 推荐使用gdb来查看内存区域中的内容. 不过大多看到的结果不具有实际意义, 因此我没有尝试.
jeprof
jeprof是jemalloc提供的一个内存优化的工具,jemalloc是facebook开源的内存管理工具,类似ptmalloc和tcmalloc,在多线程场景具有较好的性能。
默认情况下编译jemalloc后并没有jeprof工具,需要在编译时添加–enable-prof参数,然后在编译目录的bin目录中就能找到jeprof程序。
开启prof功能的jemalloc根据环境变量MALLOC_CONF和mallctl接口操作prof功能。
在机器上安装好jemalloc后, 我们很轻松地通过设置环境变量来强制JVM使用它(而不是glibc的malloc):
export LD_PRELD=/usr/local/lib/libjemalloc.so
我们还让jemalloc在每分配1GB内存后将分析结果写入磁盘,并且记录堆栈跟踪. 参考 jeprof。
export MALLOC_CONF=prof:true,lg_prof_interval:30,lg_prof_sample:17
我们随后通过常规的方法启动了应用,并开始进行测试。现在jemalloc应该会生成名为jeprof*.heap的性能快照文件。在确认泄漏发生后,我们使用reproof生成了一份内存报告:
jeprof –show_bytes –gif /path/to/jvm/bin/java jeprof*.heap > /tmp/app-profiling.gif
该报告如下:

从报告中看, 没有任何可疑的内存申请操作.
不过从另外一种方式, 发现了一些端倪:
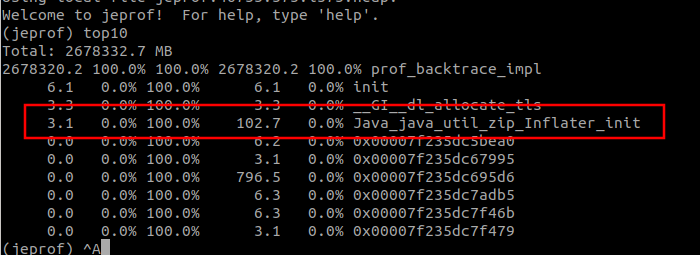
这个Java_java_util_zip_Inflater_init, 在我们浏览内存泄漏文章时, 经常遇到. 这些文章都指向了Java的压缩流, GZIPInputStream. 因此我们分析代码, 发现我们的项目中确实没有使用到. 无论时在rpc的通信协议, 还是OHC缓存的序列化与反序列化, 我们都没有使用任何压缩功能. 且该方法调用的内存申请, 其实在总的占比中很少. 因此放过这条线索.
在我们安装了jemalloc并强制JVM应用它之后, 我们花了几个小时分析他的内存申请,没有找到任何可疑的地方. 但是我们发现, 内存增长的速度极大的放缓了.
同时我们了解到, glibc标配的ptmalloc在处理高并发的情况下, 内存碎片管理的不够好.
这两个因素, 与我们相当符合:
- 高并发. 我们单机接口2w+ qps, 每次接口调用会进行1600+次的cache查询.
- 我们的缓存很少会移除, 但是更新频率极高. 也就是说, OHC需要大量的释放旧值,替换新值.
因此, 我们用jemalloc替换原装的ptmalloc, 且关闭掉jeprof. 灰度了一台机器, 接收部分流量. 与直接使用OHC+ptmalloc的机器进行内存占用对比, 如下图:
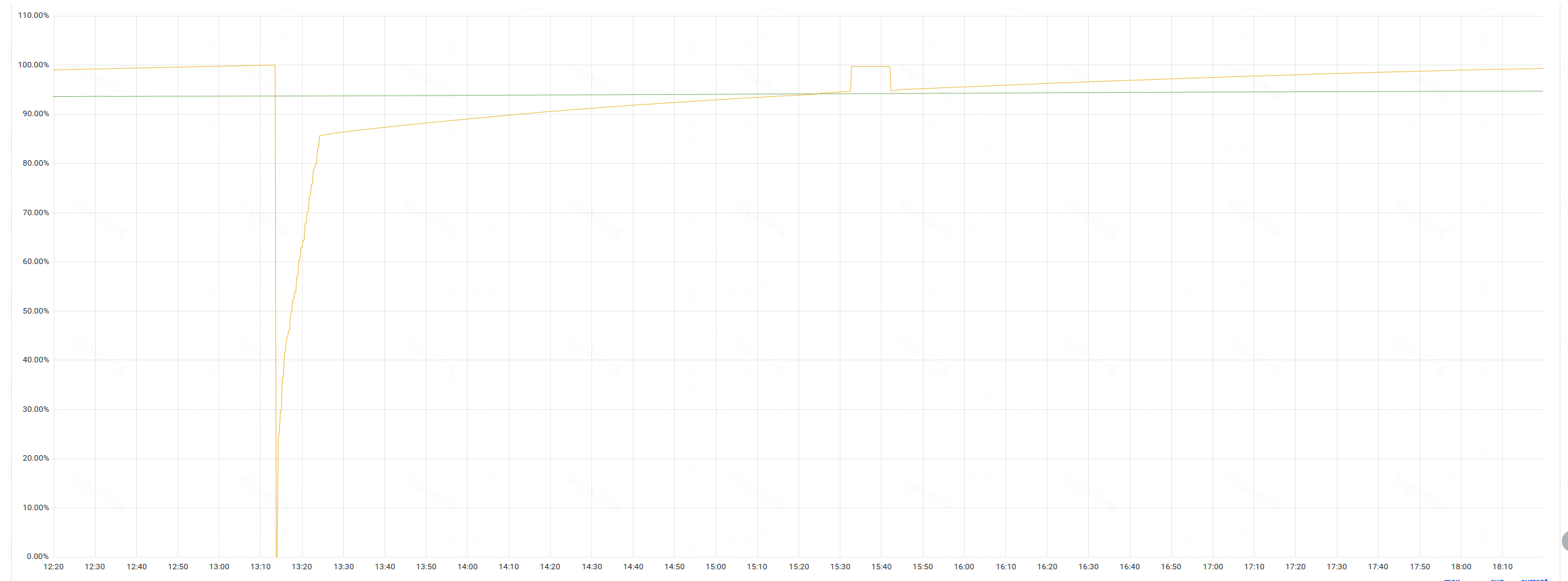
其中: 黄色线条=OHC+ptmalloc, 绿色线条=OHC+jemalloc.
可以看到, 在6个小时中, ptmalloc的机器, 在一次OOM之后,内存又上涨到了99%,即将OOM重启. 而jemalloc的机器, 内存仅仅从93.5%->94.6%. 这个内存上涨是符合预期的, 因为我们的缓存也会实时增加一部分.
观察了两天, 线上问题解决. 符合预期正常运行.
因此,暂定以下结论:
- 问题: 使用OHC管理100G左右堆外内存(更新频率较高,缓存条目较多,单个条目不大),占用内存远高于100G, 且不止于150G.
- 解决方案: 使用
jemalloc替换linux默认的ptmalloc. 问题得到解决. - 猜测原因: 大量更新堆外缓存,导致内存碎片化很严重. OHC确实调用了释放内存的接口. 但是由于
ptmalloc的原因, 这些内存没有被真正的释放掉,归还给操作系统. 持续占用.
持续研究中~:
- 如何量化的评估, 内存碎片率多高? 多严重?
- 如何证明在内存碎片率高于一定值的情况下, OHC释放了内存, 但是内存没有归还操作系统, 反而一直被进程占用?
- 多种内存分配器的实现原理与优劣势.
最后,欢迎关注我的个人公众号【 呼延十 】,会不定期更新很多后端工程师的学习笔记。
也欢迎直接公众号私信或者邮箱联系我,一定知无不言,言无不尽。

以上皆为个人所思所得,如有错误欢迎评论区指正。
欢迎转载,烦请署名并保留原文链接。
联系邮箱:[email protected]
更多学习笔记见个人博客或关注微信公众号 <呼延十 >——>呼延十
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK