

数据仓库 - chaplinthink
source link: https://www.cnblogs.com/bigdata1024/p/17517495.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

数据仓库
- 给一张城市和交易额表,一张城市对应省份表, 取出 省份 总 交易额大于 500 的 省份 的名字
select max(tmp.province_name) from (select bt.city_num, bt.gmv, pt.province_num, pt.province_name from business_table bt left join province_table pt on bt.city_num = pt.city_num) tmp GROUP BY (tmp.province_num) HAVING sum(tmp.gmv) > 500
- 基于上面1问题, 得出 省份 总 交易额 [0,500 ] , [500,1000 ] , [1000,+oo ] 在以下三个区间的 省份 的 数量
select count(case when tmp1.pro_gmv >=0 and tmp1.pro_gmv <500 then tmp1.pro_name else NULL END ) as gmv_0_500,count(case when tmp1.pro_gmv >=500 and tmp1.pro_gmv <1000 then tmp1.pro_name else NULL END ) as gmv_500_1000,count(case when tmp1.pro_gmv >=1000 then tmp1.pro_name else NULL END ) as gmv_1000_from (select max(tmp.province_name) as pro_name , sum(gmv) as pro_gmv from (select bt.city_num, bt.gmv, pt.province_num, pt.province_name from business_table bt left join province_table pt on bt.city_num = pt.city_num) tmp group by tmp.province_num) tmp1
- 还是基于刚才, 按从小到大的顺序得出每个城市的累计交易额,可以用窗口
-- group by select city_num, sum(gmv) as c_gmv from business_table bt group by city_num order by c_gmv -- windowselect bt.city_num, bt.c_gmv from (select DISTINCT city_num, sum(gmv) over (PARTITION by city_num) as c_gmv from business_table) bt order by bt.c_gmv
指标的价值
海盗指标法(AARRR海盗模型)
它反映了增长是系统性地贯穿于用户生命周期各个阶段的:用户拉新(Acquisition)、用户激活(Activation)、用户留存(Retention)、商业变现(Revenue)、用户推荐(Referral)
指标如何做到精准
选指标常用方法是指标分级方法和OSM模型。
-
指标分级方法
T1 公司战略层面指标
T2 业务策略层面指标
T3 业务执行层面指标 -
OSM模型
O 业务目标
S 业务策略
M 业务度量
维度建模的模式:
- 星型模型: 以事实表为中心,所有的维度表直接连在事实表上
- 雪花模式:雪花模式的维度表可以拥有其他的维度表,这种表不易维护,一般不推荐使用
- 星座模型: 基于多张事实表,而且共享维度信息,即事实表之间可以共享某些维度表
维度建模步骤:
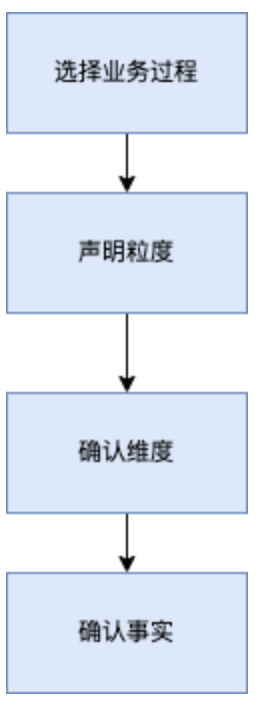
事实表种类:
- 事物事实表: 表中的一行对应空间或时间上某点的度量事件
- 周期快照事实表: 单个周期内数据, 每行都带有时间值字段,代表周期
- 累计快照事实表: 由多个周期数据组成,每行汇总了过程开始到结束之间的度量
- 无事实的事实表: 有少量的没有数字化的值但是还很有价值的字段,无事实的事实表就是为这种数据准备的,利用这种事实表可以分析发生了什么。
- 聚集事实表: 原子粒度的数据进行简单的聚合操作,目的就是为了提高查询性能
- 合并事实表: 属于相同粒度,就可以合并为一个事实表
维度表技术
-
维度表结构
维度表谨记一条原则,包含单一主键列 -
跨表钻取
使不同的查询能够针对两个或更多的事实表进行查询上钻(roll-up):上卷是沿着维的层次向上聚集汇总数据。例如,对产品销售数据,沿着时间维上卷,可以求出所有产品在所有地区每月(或季度或年或全部)的销售额。
下钻(drill-down):下钻是上钻的逆操作,它是沿着维的层次向下,查看更详细的数据。
-
退化维度
退化维度就是将维度退回到事实表中。因为有时维度除了主键没有其他内容,虽然也是合法维度键,但是一般都会退回到事实表中,减少关联次数,提高查询性能 -
多层次维度
多数维度包含不止一个自然层次,如日期维度可以从天的层次到周到月到年的层次。所以在有些情况下,在同一维度中存在不同的层次。 -
维度表空值属性
推荐采用描述性字符串代替空值 -
日历日期维度
在日期维度表中,主键的设置不要使用顺序生成的id来表示,可以使用更有意义的数据表示,比如将年月日合并起来表示,即YYYYMMDD,或者更加详细的精度。
业务数据 -- Sqoop
日志数据 -- Flume
其他数据 -- 通用第三方接口
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK