

AIGC音频合成知识入门
source link: https://www.woshipm.com/ai/5857397.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

AIGC音频合成知识入门
随着信息技术的发展,AI能帮助我们做的内容越来越多。本篇文章,作者以AI音频合成为主,分析音频合成的流程,以及需要考虑的几个方面,帮助音频合成零基础的伙伴,快速掌握音频合成。

今年席卷而来的AI风潮刮到了各个模态,音频创作作为重要形态之一,也逐渐涌现出众多产品与模型,但音频合成的基本原理你是否了解呢?一起来看看吧。
组成声音的结构包括音素、音节、音位、语素等,音频生成是对这些基本单位进行预测和组合,通过频谱逼近或波形逼近的合成策略来生成对应的声音波形。
语音合成的本质是通过对于语句结构和关系的学习来预测其声学特征,还原声音波形的过程。语音+音频结合后才得到我们常见的歌曲、朗读等形态。
音频生成目前主要包括:根据文本合成语音(text-to-speech),进行不同语言之间的语音转换,音色克隆(Singing Voice Conversion),根据视觉内容(图像或视频)进行语音描述,以及生成旋律、音乐等。
二、发展历程
音频生成随着计算机技术的发展,逐渐形成了以“文本分析-声学模型-声码器”为基本结构的语音合成方法。
基于对这个结构部分模块的替代或优化,音频生成的关键技术大致经历了拼接合成阶段、参数合成阶段、端到端合成阶段三个时期。
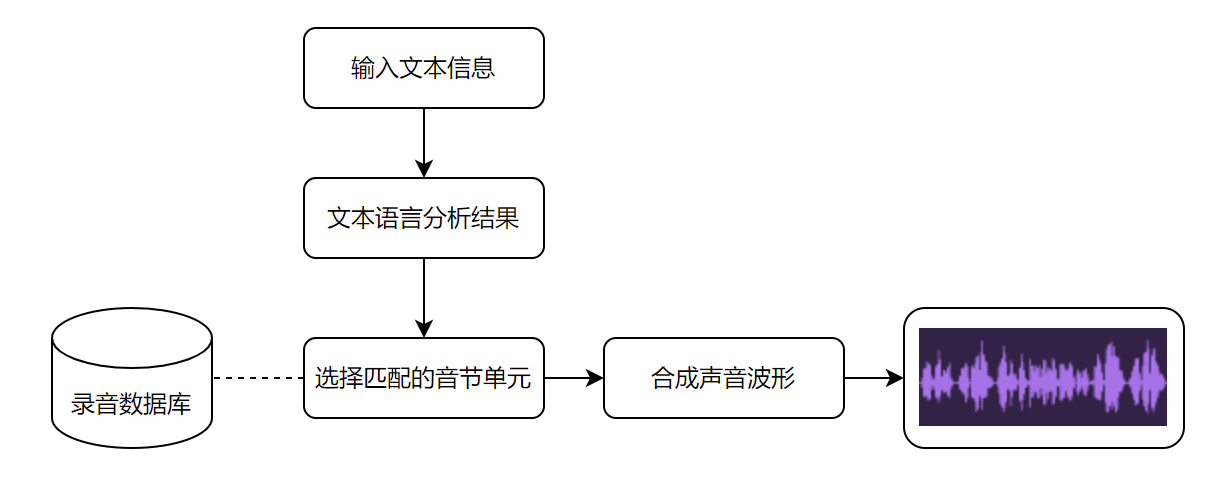
1. 波形拼接语音合成
顾名思义,波形拼接法是通过对语句的音素、音节、单词等进行特征标注和切分之后,在已有的语音数据库中查找基本单位,拼接合成语音。
其背后需要录制大量的音频,尽可能覆盖全所有的音节、音素等,数据库中的录音量(样本)越多,最后合成的音频效果越好。
- 优点:基于真人录制的语音音质较好,听觉上比较真实。
- 缺点:拼接效果依赖于语音库的数据量,需要录制大量的语音才能保证覆盖率;字词的衔接过渡较为生硬,不够自然。
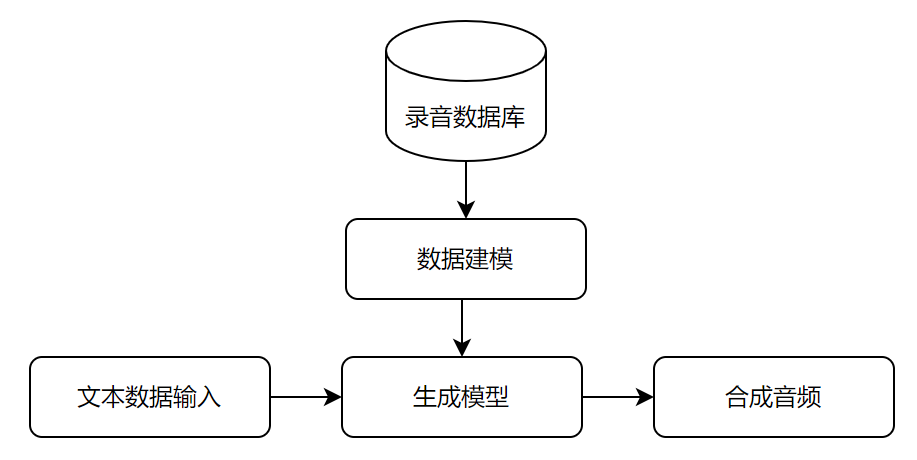
2. 参数语音合成技术
参数合成法是主要是通过数学方法对已有声音数据进行声学特征参数建模,构建文本序列映射到语音特征的映射关系,生成参数合成器。
训练好的模型对输入数据进行分词、断句、韵律分析等,映射出对应的声学特征,再由声学模型(声码器)合成音频。
- 优点:原始录音数据量小;字间协同过渡平滑,自然。
- 缺点:存在音质损失,没有波形拼接的好;机械感强,有杂音。
3. 端到端语音合成技术
端到端语音合成技术是目前最为主流的技术,通过神经网络学习的方法,采用编码器-注意力机制-解码器(Encoder-Attention-Decoder)的声学模型,实现直接输入文本或者注音字符。
中间为黑盒部分,最后输出频谱和声音波形合成音频,简化了复杂的语言分析部分和特征抽取过程。
端到端合成大大降低了对语言学知识的要求,可以实现多种语言的语音合成。通过端到端合成的音频,效果得到的进一步的优化,更加自然,趋近真人发声效果。
目前,语音生成领域应用广泛且效果优秀的产品均基于端到端合成框架实现的,模型性能和应用能力的提升使其逐渐成为主流。
- 优点:对语言学知识要求降低;合成的音频自然,趋近人声,效果好;同参数合成一样所需录音量小。
- 缺点:黑盒模型,合成的音频不能人为调优;复杂合成任务需要较多资源。

当前的开源模型在不断迭代更新,端到端合成目前比较火的有Tacotron2、Transformer-TTS、WavLM等模型。
三、影响应用能力的关键因素
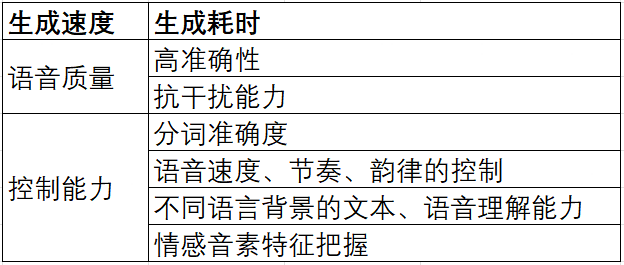
四、输入类型

五、效果指标
1. MOS值
定义:找一些业内专家,对合成的音频效果进行打分,分值在1-5分之间,通过平均得到最后的分数。
这是一个相对主观的评分,没有具体的评分标准。根据个人对音色的喜好,对合成音频内容场景的掌握情况,以及对语音合成的了解程度是强相关的。
虽然mos值是一个比较主观的测试方式,但也有一些可评判的标准。例如在合成的音频中,多音字的读法、当前场景下数字的播报方式、英语的播报方式,以及在韵律方面,词语是否连在一起播报、应该重读的地方是否有重读、停顿的地方是否合理、音色是否符合应用于当前的这个场景。都可以在打分的时候做为得分失分的依据。
2. ABX测评
定义:熟知的AB测试,选择相同的文本以及相同场景下的音色,用不同的模型合成来对比哪个的效果较好,也是人为的主观判断。
但是具有一定的对比性,哪个模型更适合当前的场景,合成的效果更好。
3. 其他指标
围绕合成音频的可懂性、自然度、相似度。以中文为例,还有些指标包括PER(拼音-不包含声调-错误率,越低越好)、PTER(拼音-包含声调-错误率,越低越好)、Sim(与真人声音的相似度,越高越好)等。
六、应用场景
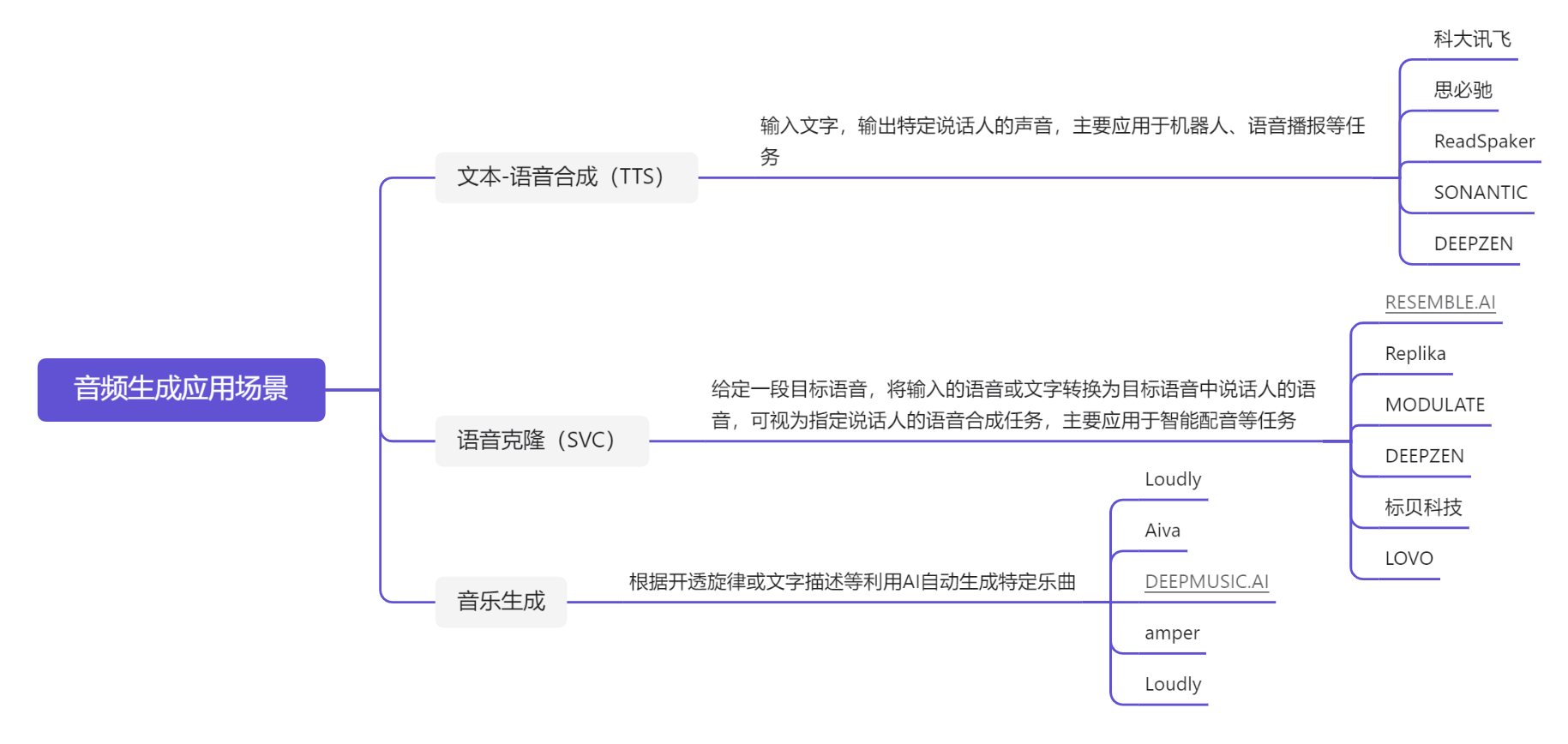
1. 文本-语音合成(TTS)
目前技术发展已经较为成熟,市面上已有较多公司(讯飞、出门问问、思必驰等)推出了商业化产品,主要聚焦的应用场景是AI语音合成

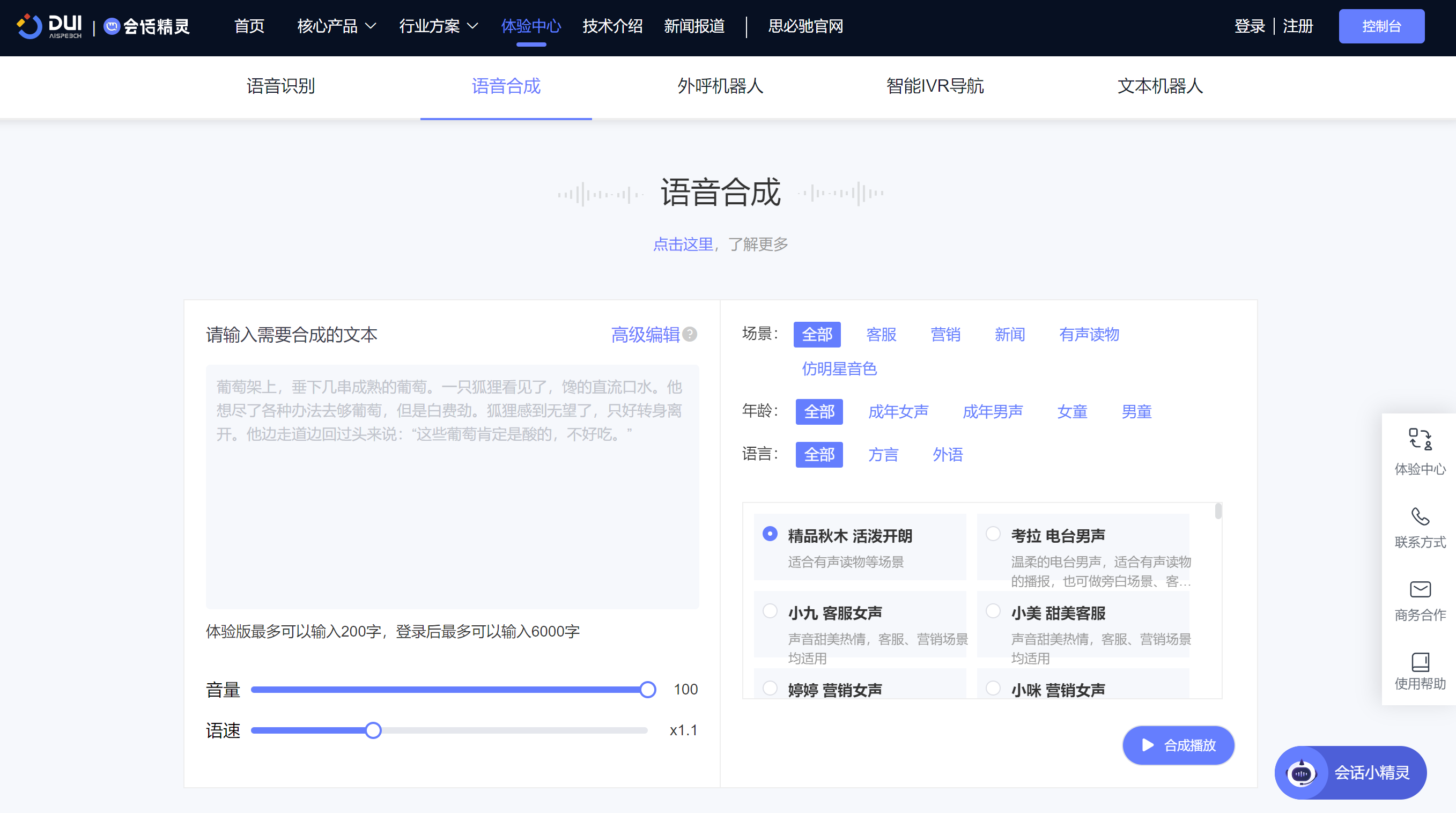
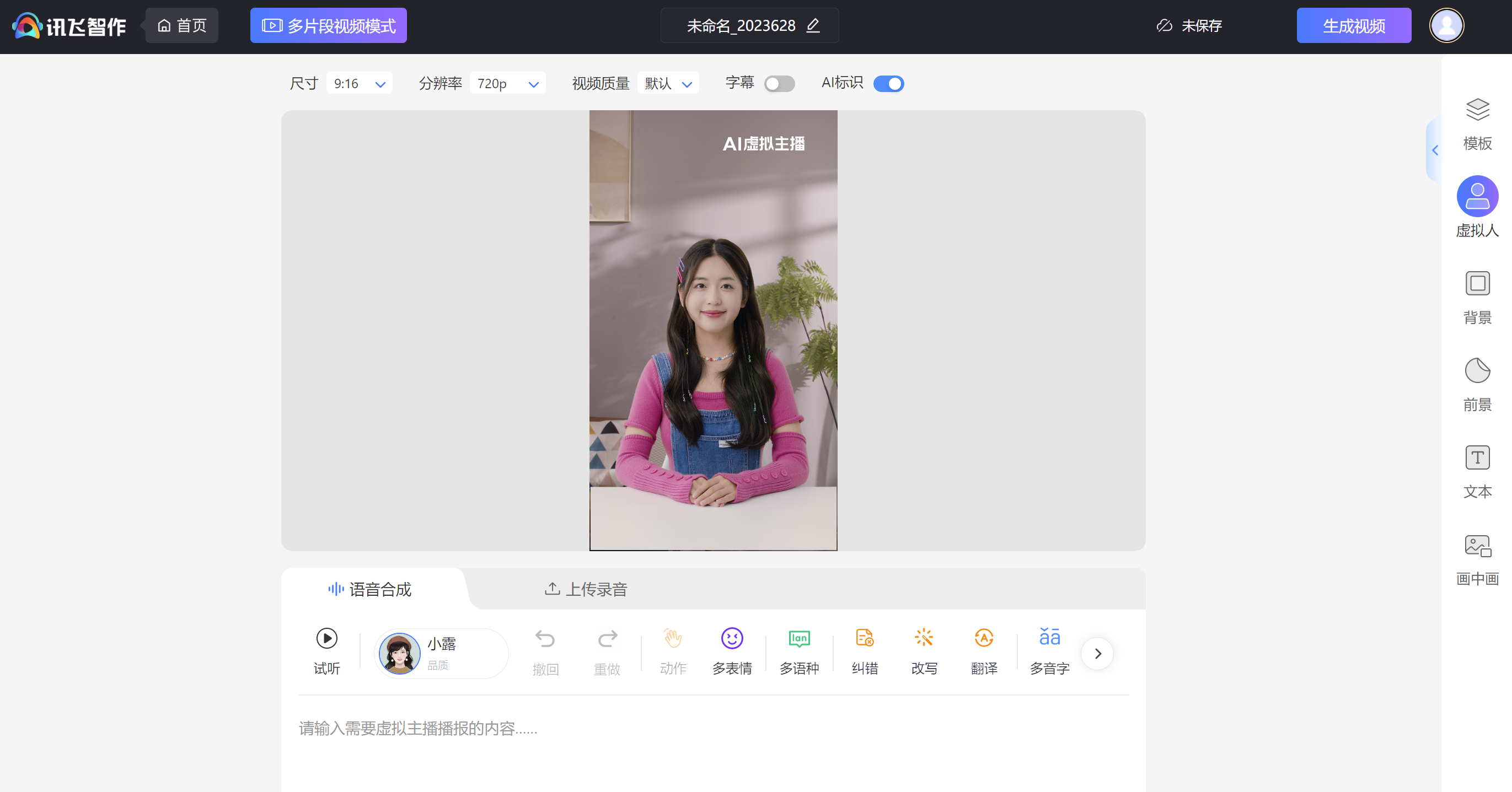
虚拟人主播
2. 音色迁移/语音克隆(SVC)
这段时间爆火的“AI孙燕姿”就是音色克隆的代表之一,只需要一定数量的训练集录音,就可将输入的文本或语音转换为目标模型音色
部分商业化产品目前也在试行推广这一功能。

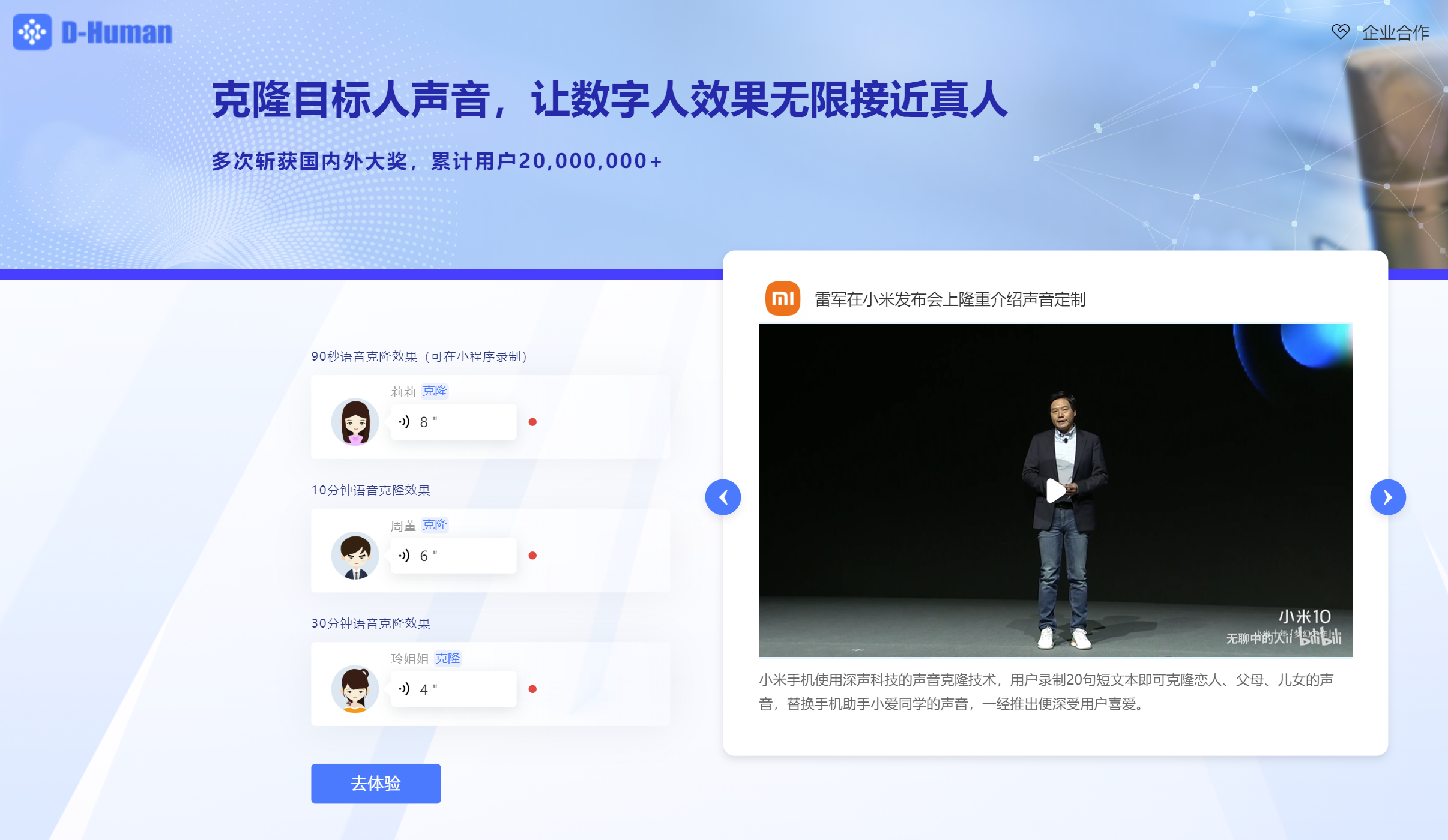
目前也有开源模型支持个人训练,仅需满足硬件限制(6GB以上显存的NVDIA显卡、Windows系统)。
例如比较主流的模型so-vits-svc,部署后可直接通过webui即可进行训练操作。
github仓库地址:so-vits-svc/README_zh_CN.md at 4.1-Stable · svc-develop-team/so-vits-svc · GitHub
至此音频合成的知识入门就告一段落,感兴趣的同学可以尝试语音克隆的模型训练去了解更多,实践出真知~
本文引用数据源:
易观千帆:https://qianfan.analysys.cn/
本文由 @白金之星 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK