

论文学习笔记:增强学习应用于OS调度
source link: https://www.51cto.com/article/759102.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

从小型物联网设备到大型服务器,Linux在各个领域中都得到了广泛应用。计算吞吐量对于使用数百万个线程来模拟人工智能和机器学习模型至关重要,但对于其他机器来说,响应性能可能很关键。
CPU调度是一种确定可以执行的下一个进程的技术。为特定环境使用的CPU调度程序的优化是提高性能和降低成本的重要问题。工作负载和机器的性能很大程度上取决于调度程序的配置。然而,大多数机器考虑的是Linux的通用硬件和软件环境,使用默认调度程序配置。有效的调度对整个Linux服务器具有显著的性能影响,大多数调度研究都专注于减少调度开销或修改优先级操作以支持特定情况下的作业。
1. Linux 中的调度器
目前默认的 Linux 调度器,即完全公平调度器 (CFS) ,使用虚拟运行时间的概念,旨在实现理想和精准的多任务 CPU调度,以便所有任务使用相同的 CPU 时间。相比之下,FreeBSD 操作系统的默认调度器 ULE ,专为对称多处理 (SMP) 环境设计,其中两个或多个处理器使用一个共享内存,并允许多个线程独立执行。它旨在通过独立调整每个任务的交互能力、优先级和片段大小,提高同步多线程 (SMT) 环境的性能。为此,Bouron 将 FreeBSD 的 ULE 调度器移植到 Linux,并将其性能与 CFS 进行了比较。结果,确认在大多数工作负载中两个调度器显示相似的性能,对于具有许多交互式任务的工作负载,ULE 显示出了更好的性能。
Kolivas 认为,用于在特定环境下改善性能的启发式调整参数会降低性能。为了减少这种调度开销,他们实现了一种简单的调度算法 (BFS),该算法消除了复杂优先级计算。BFS 提高了 Linux 桌面的响应性,适用于少于 16 个 CPU 核心的设备,并用作多个 Linux 发行版(包括 PCLinuxOS 2010、Zenwalk 6.4 和 GalliumOS 2.1)的默认调度器。
优化调度器是一个困难的问题,需要在操作系统上具有广泛的专业知识。许多因素会影响调度程序的性能,例如硬件、工作负载和网络,以及用户如何操作系统。然而,理解这些许多因素之间的所有相关性是困难的。即使实现了这样的调度程序算法,调度程序度量也会存在误差。因此,很难确认调度程序性能是否真正得到了改善。
2. 基于ML 的调度参数调优
Lama 提出并开发了 AROMA,一个自动化 Hadoop 参数配置的系统,该平台用于大数据分析,以提高服务质量并降低成本。AROMA 使用支持向量机 (SVM),一种机器学习模型,以优化参数,使云服务能够有效地使用,而无需进行低效的参数调整。
自动优化基于机器学习的 Apache Spark 参数,可以提高其性能。Spark 内部有超过 180 个参数,其中有 14 个参数对性能有重大影响,这些参数可以采用决策树模型算法进行优化。在相关论文的性能评估结果中,初始设置的平均性能改善了 36%。
此外,对于 Android 调度器的性能, Learning EAS 是一种针对 Android 智能手机调度器 EAS 的策略梯度强化学习方法。Learning EAS 应用于正在运行任务的特征,并调整 TARGETLOAD 和 schedmigration_cost 以提高调度器性能。在 LG G8 ThinQ 上的评估结果表明,与默认 EAS 相比,Learning EAS 可将功耗降低最多 5.7%,并将性能提高了最多 25.5%。
服务器中很常见的是静态工作负载,例如基因组分析软件、大数据分析系统和人工智能。所读论文旨在通过调整调度策略和参数来提高静态工作负载的性能。在Linux内核中,定义了5个调度策略和14个调度程序参数。通过适当地修改这些策略和参数,可以提高调度程序的性能,以适应硬件环境和工作负载的特征。但是,对于单个优化,需要消耗大量成本,因为必须考虑每个参数之间的关系,并且需要专业的工作负载信息和硬件专业知识。
3.基于RL 的调度参数调优
3.1关于强化学习 RL
强化学习是一种机器学习算法,它建立了一个策略,以确定在当前状态下总补偿值最大的行为。它由环境和代理组成,如下图所示。代理是确定下一个执行操作的主体,通过行动与环境交互,环境则回应状态和奖励。代理不断与环境交互以建立最优策略。
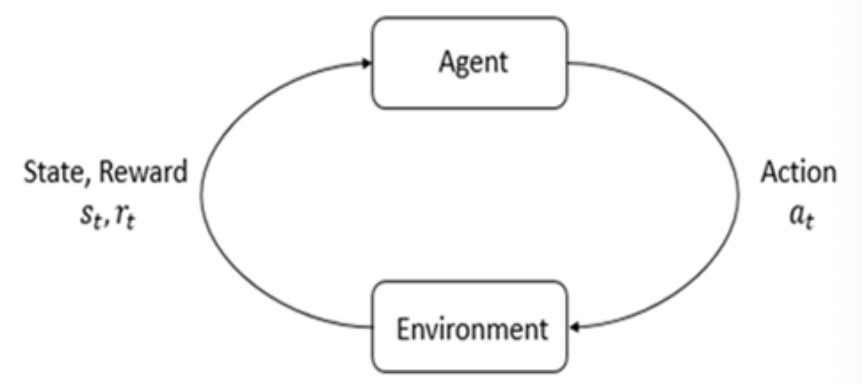
图片
强化学习适用于具有权衡关系的问题。特别是,短期和长期行为的奖励值是明确的时候,RL被用于各种领域,如机器人控制等,例如DOTA 2 就通过深度强化学习进行了良好的训练。
有许多算法用于实现强化学习,这篇论文中采用了Q-learning算法。Q-learning的代理具有一个Q表,记录了可以在每个状态下执行的所有动作的Q值,以解决问题。当代理首次开始学习时,Q表的所有值都被初始化为0。如果每个状态的Q值为0,则代理会随机选择一个操作并更新Q表中的Q值。如果Q值不为0,则代理选择具有最大Q值的操作,以最大化奖励。代理重复执行这些步骤,直到找到最佳策略。
Q-learning是一种无模型强化学习,它使用贝叶斯方程来找到具有最高总奖励的行动。在强化学习中,模型预测环境的状态变化和补偿。无模型强化学习具有易于实现或调整的优点。
3.2 强化学习的工具
OpenAI Gym为强化学习提供了一个名为Env的集成环境接口。Env提供以下功能:
Render(self):此函数在环境内呈现一个帧,并将其显示为GUI。在本研究中,由于没有需要GUI,因此未使用它。
Reset(self):此函数将环境重置为其初始状态。此功能通常在每个学习阶段结束时应用,以进行下一步学习。
Step(self, action):此函数逐步执行一个动作,并返回以下三个变量。
- 观测(object):该值是一个环境特定的对象,表示对环境的观测。
- 奖励(flfloat):该值表示通过上一次行动获得的补偿金额。强化学习的最终目标是最大化总奖励值的总和。
- 完成(boolean):这是一个标志,用于决定是重置环境还是结束学习。
OpenAI提供了各种环境的接口,论文中的实现基于OpenAI Gym。
3.3 Linux中的调度策略与内核调度参数
在Linux内核中,当前定义了五个调度策略:NORMAL(CFS)、FIFO、RR、BATCH、IDLE ,可以使用Linux提供的schedtool工具更改这些策略,而无需重新启动服务器。
SCHED_NORMAL(CFS) 这是Linux内核的默认调度策略。CFS的目的是最大化整体CPU利用率,并为所有任务提供公平的CPU资源。CFS基于每个CPU运行队列,这些任务按虚拟运行时间的顺序运行,并通过红黑树排序。
SCHED_FIFO 这是一个固定优先级调度策略,每个任务以1到99的优先级值执行,并且是按高优先级顺序抢占并执行CPU的策略。
SCHED_RR 这基本上与SCHED_FIFO的操作相同,但每个任务都有一个时间量子值,这是执行的最长时间。当时间量子过期时,任务以轮询方式切换到下一个任务。
SCHED_BATCH 此策略适用于批处理作业。通过避免被其他任务抢占,我们可以运行一个任务更长时间,比其他策略更好地利用硬件缓存;但是,这对于交互式任务效果不佳。
SCHED_IDLE 此策略以非交互方式运行,类似于SCHED_BATCH。但是,与SCHED_BATCH不同,当其他进程处于空闲状态时,可以执行SCHED_IDLE。
Linux内核提供了14个调度器参数进行优化。该论文对其中9个参数进行了优化,并排除了不影响性能的五个参数。下表显示了可以更改的参数值范围和Linux内核的默认值。它们可以使用Linux提供的sysctl命令在不重新启动机器的情况下更改。
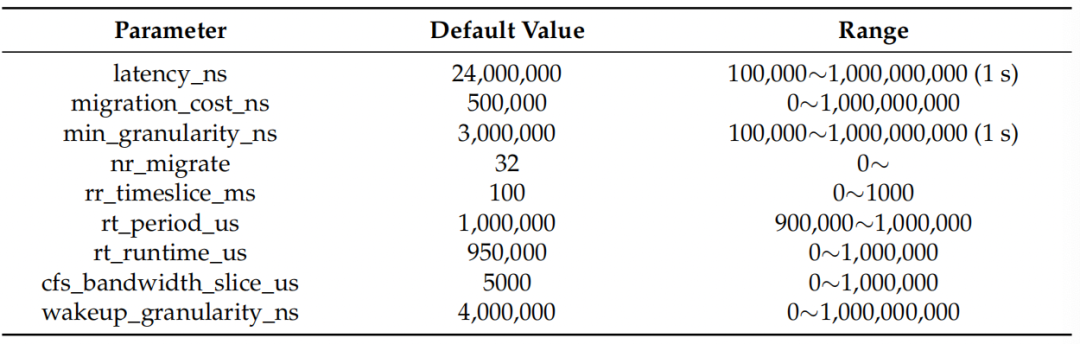
图片
每个参数的含义如下。
sched_latency_ns: 针对CPU绑定任务的目标抢占延迟。增加此参数会增加CPU绑定任务的时间。
sched_migration_cost_ns: 这是在迁移决策中被认为是热缓存的最后一次执行后的时间。热任务不太可能被迁移到另一个CPU,因此增加此变量会减少任务迁移。如果CPU空闲时间高于预期而有可运行的进程,则建议减小此值。如果任务经常在CPU或节点之间反弹,则可能更好地增加它。
sched_min_granularity_ns: CPU绑定任务的最小抢占粒度。此参数与sched_latency_ns密切相关。
sched_nr_migrate: 这控制有多少个任务可跨处理器进行负载平衡。由于负载平衡使用禁用中断的运行队列(softirq)迭代,因此可能会对实时任务产生irq延迟惩罚。因此,增加此值可能会给大型SCHED_OTHER线程带来性能提升,但以实时任务的irq延迟为代价。
sched_rr_timeslice_ms: 此参数可以调整SCHED_RR策略中的时间。
sched_rt_runtime_us: 这是在schedrtperiodus期间分配给实时任务的时间量子。将该值设置为* - *将禁用RT带宽强制执行。默认情况下,RT任务每秒可以消耗CPU资源的95%,因此留给SCHED_OTHER任务5%,或0.05秒。
sched_rt_period_us: 这是测量实时任务带宽执行的周期。
sched_cfs_bandwidth_slice_us: 在使用CFS带宽控制时,此参数控制从任务的控制组带宽池向运行队列转移的运行时间(带宽)的数量。较小的值允许全局带宽在任务之间以精细的方式共享,而较大的值会减少转移开销。
sched_wakeup_granularity_ns wakeup: 这是唤醒抢占的粒度。增加此变量会减少唤醒抢占,减少计算绑定任务的干扰。降低它可以提高对延迟关键任务的唤醒延迟和吞吐量,特别是当短周期负载组件必须与CPU绑定组件竞争时。
3.4 基于RL的调度器参数调整——STUN
STUN并没有用最广泛用于强化学习的深DQN,因为它消耗大量计算能力和内存,如果仅使用CPU而没有GPU,则需要太长时间进行学习。事实上,它无法在合理的时间内搜索内核调度程序的最优参数。Q学习算法比深度学习轻,消耗更少的内存。因此,STUN采用了Q学习算法,这是在Linux内核中实现STUN的一种更好选择。
下显示了STUN的结构。STUN由环境模块和代理模块组成。环境模块定义了内核参数优化的环境,代理模块定义了Q学习算法并执行代理。
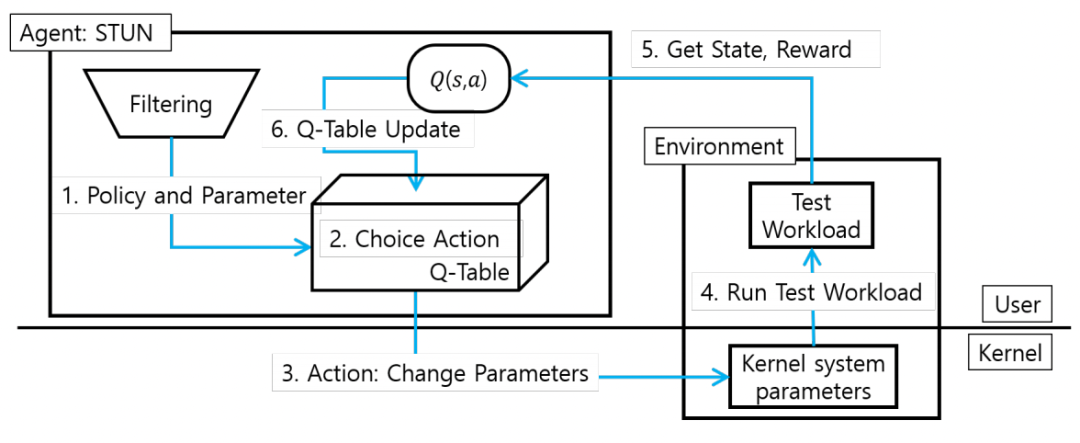
图片
在环境模块中定义的reset和step函数如下。
Reset(self, f = True) 此函数初始化要优化的参数。重置用于防止在学习过程中对特定参数值进行过度奖励。它随机初始化值,最多可学习次数的一半,其余值为表现最佳的值。
Step(self, action): STUN在更改参数值的情况下进行测试工作负载后,返回状态、奖励和完成。每个变量的含义如下。
Action: 这是一个值,确定每个参数的增加或减少。当优化n个参数时,它有n + 1个值从0到n。STUN通过添加或减去预定义值α来更改优化值。
State: 这是用于指示要学习的参数的值的元素。每个参数分为50个,范围可以修改,并且每个状态的值为0到49,表示为(s1,s2...sn)。
Reward: 作为测试工作负载的结果,用于确定是否比先前状态下获得更好的性能。
Done: 这是用于提高效率的学习结束的元素。“完成”标志初始化为true。如果测试工作负载的结果小于默认性能的20%,则返回false。如果连续出现一定数量的false值,则该执行结束。
代理模块定义Q表,该表记录在每个状态下执行某个动作时的动作值。STUN使用Q学习模型和值函数Q(st,at)来更新Q表的值。从值函数获得的值是未来可以获得的预期值,而不是判断当前价值的好坏,与奖励值不同。Q-学习算法每次执行操作时都会更新Q表中状态的预期值,然后选择具有最大预期值的操作。更新Q值的公式如下。
在上面的公式中,st和at分别表示当前状态和动作;Rt+1是在当前状态下执行的奖励值;max aQt(st+1,a)是在未来假设最有利的动作时得到的预期值。在这里,γ是折扣率,反映了当前奖励的价值高于未来奖励的价值。由于未来奖励的价值低于当前奖励,因此通过将其乘以0到1之间的值γ进行反映。
在代理模块中,学习迭代的数量由代理的事件执行次数(N)和步骤函数执行次数(T)确定。通过在单个事件中多次执行步骤函数,改变和学习参数值多达T次。因此,代理最多有N×T个学习迭代。
即使参数值根据调度程序策略或工作负载发生变化,也不是所有参数都会影响性能。过滤过程通过最小化性能改进的不必要的训练来缩短训练时间,并减少内存使用以更有效地执行优化。在Q-learning算法中使用所有五个调度程序策略和九个参数会浪费大量内存并增加学习时间。因此,需要找到一个显著影响性能的参数。为了实现有效学习,STUN通过过滤过程选择优化的调度程序策略和参数。
STUN将单个参数值按照最小值、最大值和默认值依次更改为每个策略,并记录测试工作负载中的性能变化。此时,其他参数被固定为默认值。过滤过程删除不影响应用程序整体性能的参数。为了确定参数,过滤过程使用20%的阈值作为测量误差。由于根据系统情况可能存在10-15%的误差范围,因此我们决定20%的性能差异是有意义的,并测试参数的最佳值。
在整个过滤过程中,已知这些策略和参数之间的关系,因此只使用最影响性能的参数作为学习变量。因此,过滤过程可以缩短学习时间并减少内存使用,从而更有效地实现优化。
奖励是指工作负载性能是否在改善的值。通过细分和应用奖励,STUN可以更有效地更新Q表,并缩短学习时间。
STUN奖励函数中的奖励和惩罚规则的一些想法如下:
- 对于性能的重大改进给予高奖励
- 如果性能显著下降,则给予惩罚
- 基于以前的性能给予奖励
为了表示算法的规则,默认值是作为性能标准使用的变量。这是在不更改参数的情况下在Linux默认设置下的测试工作负载结果。请注意,结果表示测试工作负载的性能。与过滤过程一样,根据20%以上和20%以下的结果奖励不同,以检查性能是否受到重大影响。从default_bench提高20%以上的结果设置为upper,低于20%的结果设置为under。如果结果优于upper,则奖励为200,是一个大奖励;如果低于under,则惩罚为−50。当性能在20%的范围内变化时,如果性能高于以前的结果,则给予100的值;否则,返回0的值。算法1是获得奖励的算法表示。
算法1: 奖励算法
upper : 20% greater than de f ault_bench
under : 20% less than de f ault_bench
if result_o f _testworkload > upper then
reward = 200
else if result_o f _testworkload < under then
reward = −50
else if result_o f testworkload > lastresult then
reward = 100
else
reward = 0
end4. 基于RL的OS调度调优的评估方法
没有评估体系和评估指标的AI 都是在耍流氓,该论文评估了以下几点:
基于学习迭代次数的STUN性能。通过改变决定强化学习中总迭代次数的因素,即episode count N和Max_T的值来分析结果。
微基准下的性能表现。为了确认STUN的详细性能改进,选择了微基准,即hackbench,并将其在经过优化的STUN调度程序参数下与在默认调度程序环境下的性能进行比较。作为评估Linux内核调度程序性能的基准,它创建进程通过套接字或管道进行通信,并测量每个对之间发送和接收数据所需的时间。对于运行hackbench的选项,给定了目标机器的核心数,并将核心数乘以40个任务应用为测量执行时间的进程。
真实工作负载下的性能表现。为了评估STUN对真实工作负载的性能影响,运行了一个使用Haar Cascades的人脸检测应用程序,并比较了在默认和经过优化的设置下应用程序的执行时间和每秒帧数之间的差异。人脸检测应用程序使用OpenCV提供的基于机器学习的对象检测算法之一,它从视频文件的帧中查找人的面部和眼睛。将默认应用程序修改为高度并行的多线程应用程序,以利用许多底层核心。
基于CPU核心数量的改进。为了确认CPU核心数是否影响STUN的性能,比较了在4核、44核和120核机器上优化Sysbench的性能改进率。Sysbench是一个基于LuaJIT的多线程基准测试工具集。虽然它主要用于基准测试数据库,但也用于创建任意复杂的工作负载。在这个评估中,生成了CPU核心数× 10个线程,并将执行的总事件数作为结果。
为验证在实际工作负载下的性能,在44核机器上使用STUN优化了人脸检测程序,并分析了视频的人脸识别时间和默认和优化参数值下的每秒帧数。STUN获取的最佳参数值如下:
- 调度程序策略:Normal;
- kernel.sched_rt_runtime_us = 1,000,000;
- kernel.sched_min_granularity_ns = 680,100,000。
应用最佳值后的人脸检测程序的结果, 总执行时间从58.998秒降至48.198秒,下降了18.3%,每秒帧数从16.95增加到20.748,增加了22.4%。
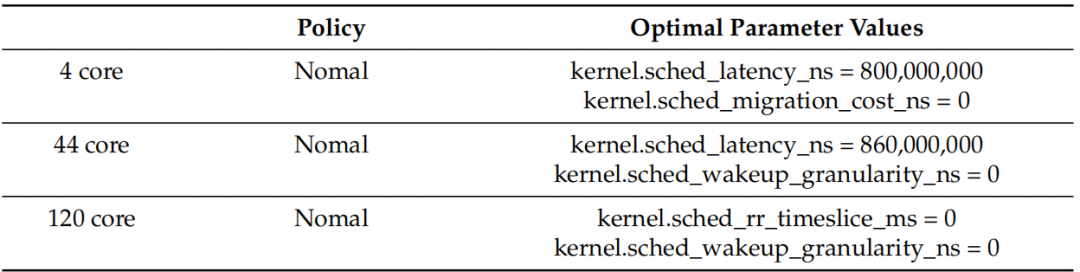
调度程序的性能影响在很大程度上取决于核心数量,这归因于调度程序的功能。因此,该论文比较了在4核、44核和120核机器上通过STUN对Sysbench的性能改进。Sysbench线程选项设置为每台机器CPU核心数的10倍。此外,策略和参数设置为通过过滤过程获得的最佳值。表3显示了通过STUN为每个核心数优化Sysbench的调度程序策略和参数值。
CPU调度程序是影响系统性能的重要因素。该论文提出了STUN,这是一种使用强化学习优化Linux内核调度程序参数的优化框架。使用STUN可以在不需要人为干预的情况下增强各种调度环境。
STUN具有有效和快速优化的特点。首先,通过滤波过程选择的参数显著影响性能,从而实现有效优化。此外,将奖励算法细分,以便强化学习中的代理可以有效地学习。未来可以采用另一种强化学习算法,例如策略梯度,以获得更精确的优化参数值和更并发的参数。此外,可以将STUN的逻辑与Linux内核集成,以创建自适应调度程序。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK