

详解数据库中的索引和视图 - 华为云开发者联盟
source link: https://www.cnblogs.com/huaweiyun/p/17509128.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

摘要:索引就是数据表中数据和相应的存储位置的列表,利用索引可以提高在表或视图中的查找数据的速度。
本文分享自华为云社区《数据库开发指南(六)索引和视图的使用技巧、方法与综合应用》,作者: bluetata 。
1.1 什么是索引
索引就是数据表中数据和相应的存储位置的列表,利用索引可以提高在表或视图中的查找数据的速度。它类似于书籍的索引,可以帮助快速定位和检索数据。在数据库中,索引是对一个或多个列的值进行排序和存储的结构,它们包含指向实际数据位置的指针。
1.2 索引分类
数据库中索引主要分为两类:聚集索引和非聚集索引。SQL Server 还提供了唯一索引、索引视图、全文索引、XML 索引等等。聚集索引和非聚集索引是数据库引擎中索引的基本类型,是理解其他类型索引的基础。
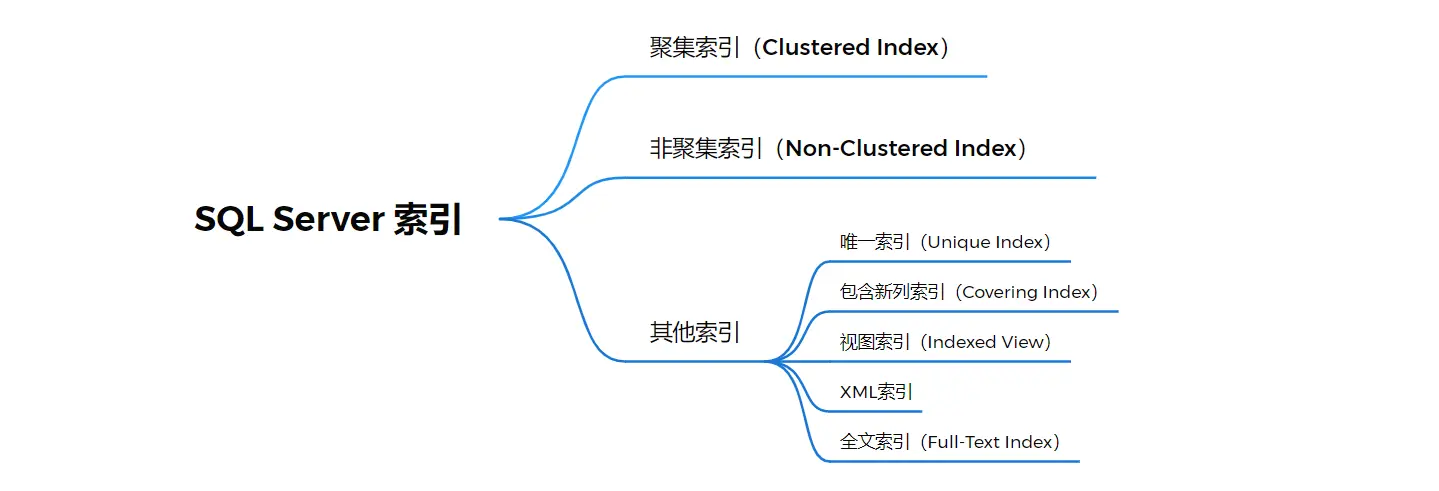
1.2.1 聚集索引
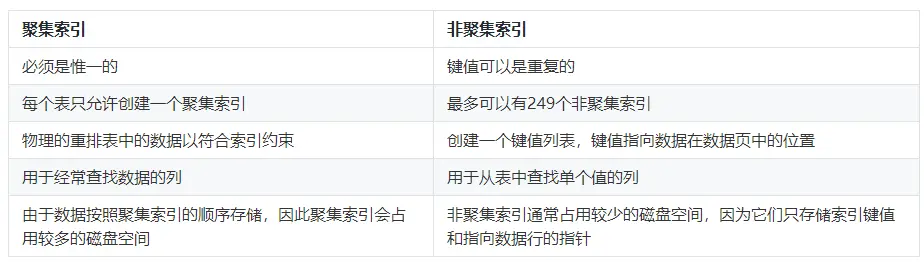
聚集索引是值表中数据行的物理存储顺序和索引的存储顺序完全相同。聚集索引根据索引顺序物理地重新排列了用户插入到表中的数据,因此,每个表只能创建一个聚集索引。聚集索引经常创建在表中经常被搜索到的列或按顺序访问的列上。在默认情况下,主键约束自动创建聚集索引。
1.2.2 非聚集索引
非聚集索引不改变表中数据列的物理存储位置,数据与索引分开存储,通过索引指向的地址与表中的数据发生关系。
非聚集索引没有改变表中物理行的位置,索引可以在以下情况下使用非聚集索引:
- 如果某个字段的数据唯一性比较高
- 如果查询所得到的数据量比较少
1.2.3 聚集索引和非聚集索引的区别
这里用一个表格简单的总结一下聚集索引和非聚集索引的区别:
1.2.4 其他类型索引
除了以上索引,还有以下类型索引:
- 唯一索引:如果希望索引键都不同,可以创建唯一索引。聚集索引和非聚集索引都可以是唯一索引。
- 包含新列索引:索引列的最大数量是16个,索引列的字节总数的最高值是900。如果当多个列的字节总数大于900,切又想在这些劣种都包含索引是,可以使用包含新列索引
- 视图索引:提供视图查询效率,可以视图的索引物理化,也就是说将结果集永久存储在索引中,可以创建视图索引。
- XML索引:是与xml数据关联的索引形式,是XML二进制blob的已拆分持久表示形式
- 全文索引:一种特殊类型的基于标记的功能性功能,用于帮助在字符串中搜索赋值的词
1.3 创建索引
1.3.1 语法
create [unique] [clustered | noclustered]
index index_name
on table_name (column_name ...)
[with fillfactor=x]unique 唯一索引
clustered 聚集索引
noclustered 非聚集索引
fillfactor 填充因子大小,范围在 0-100 直接,表示索引页填满的空间所占的百分比。
1.3.2 创建索引的命名规则最佳实践
在 MSSQL 中,索引的命名规则的最佳实践可以有一些常见的准则,以提高可读性和维护性。这个潜在的要求不仅试用于 SQL Server 数据库,同样在其他数据库例如 MySQL、Oracle 中都同样值得注意。
下面是个人总结的一些命名规则与建议:
- 命名应该具有描述性:索引的名称应该能够清晰地表达其作用和关联的列或表。使用有意义的名称可以使其他开发人员更容易理解索引的用途。
- 包含表名和列名:在索引名称中包含相关表名和列名(长表名可适当缩写,但要确保可以定位到表),可以使索引更具可读性,并且可以避免在不同表之间使用相同名称的索引时的冲突。
- 使用统一的命名约定:为了提高一致性,可以定义一套命名约定,并在整个数据库中使用。例如,可以使用特定的前缀或后缀来标识索引的类型(如 idx_ 表示非聚集索引)。
- 避免过长的名称:索引名称不应该过长,以免在使用索引时引起不便。尽量使用简洁但描述性的名称。
- 避免使用保留关键字和特殊字符:确保索引名称不与 MSSQL 的保留关键字或特殊字符冲突,以避免语法错误。
1.3.3 创建索引示例
-- 普通索引
if (exists (select * from sys.indexes where name = 'idx_stu_name'))
drop index student.idx_stu_name
go
create index idx_stu_name
on
student(name);
-- 联合索引
if (exists (select * from sys.indexes where name = 'idx_uqe_clu_stu_name_age'))
drop index student.idx_uqe_clu_stu_name_age
go
create unique clustered index idx_uqe_clu_stu_name_age
on student(name, age);
if (exists (select * from sys.indexes where name = 'idx_cid'))
drop index student.idx_cid
go
if (exists (select * from sys.indexes where name = 'idx_cid'))
drop index student.idx_cid
go
-- 非聚集索引
create nonclustered index idx_cid
on
student (cid)
with fillFactor = 30; --填充因子
-- 聚集索引
if (exists (select * from sys.indexes where name = 'idx_sex'))
drop index student.idx_sex
go
create clustered index idx_sex
on
student(sex);
-- 聚集索引
if (exists (select * from sys.indexes where name = 'idx_name'))
drop index student.idx_name
go
create unique index idx_name
on
student(name);1.4 适合的创建索引的列
一般情况,可以选择那些对查询性能有积极影响的列进行索引创建,下面进行一定的总结:
列的选择性:选择性是指列中不同值的数量与总行数的比例。如果某列具有较高的选择性,即不同的值较多,那么为该列创建索引可能会有更好的效果。例如,在表示性别的列上创建索引可能没有太大的帮助,因为只有两个可能的值。
查询频率:观察经常用于查询条件的列。如果某个列经常用于搜索、过滤或连接操作,那么为该列创建索引可以提高查询性能。
数据表的大小:对于大型表,创建索引的影响可能更加显著。较小的表可能不需要太多的索引,因为全表扫描的开销相对较小。
数据更新频率:索引的创建和维护也会增加对数据的写操作的开销。如果某个列的数据经常发生变化,那么创建索引可能会带来一定的性能开销。
查询性能优化需求:通过分析查询执行计划,可以确定是否存在潜在的性能瓶颈,并考虑为相关的列创建索引以改善查询性能。
请注意过多的索引也可能会带来维护开销和存储成本,因此需要在权衡索引数量和性能提升之间找到平衡点。定期监控和评估索引的使用情况也是重要的,以确保索引仍然对数据库性能产生积极影响。
1.5 不适合创建索引的列
虽然在某些情况下创建索引可以提高查询性能,但并不是所有列都适合创建索引。以下是一些不适合创建索引的列的情况:
低选择性列:如果某个列的选择性很低,即该列的不同值较少,创建索引可能不会带来明显的性能提升。例如,对于性别这样只有几个可能值的列,创建索引可能不会有太大意义。
经常更新的列:如果某个列的值经常被修改,那么为该列创建索引可能会带来额外的维护成本和性能开销。每次更新操作都需要更新索引,这可能会影响写入性能。在这种情况下,需要仔细评估是否真的需要为该列创建索引。
过于频繁的查询列:某些列可能经常被查询,但它们的选择性较低,即不同的值较少。在这种情况下,尽管查询频率高,但为该列创建索引可能不会带来明显的性能提升,因为索引的使用效果有限。
大文本或大二进制列:对于存储大文本或大二进制数据的列,如长文本字段或图像字段,创建索引的效果通常较差。这是因为索引本身需要占用额外的存储空间,并且对于大型数据的索引操作可能变得非常耗时。
不常用的列:对于很少用于查询的列,创建索引可能没有太大意义。如果一个列很少用于查询条件或连接操作,那么为其创建索引可能只会增加额外的开销而不带来实际的性能提升。
需要注意的是,以上列举的情况只是一般性的指导原则,具体是否适合创建索引还取决于具体的数据库结构、查询模式和性能需求。在设计和创建索引时,应根据具体情况进行评估,并进行性能测试和优化以确保索引的有效性。
2.1 什么是视图
视图就是一个虚拟的数据表,该数据表中的数据记录是由一条查询语句的查询结果得到的。
2.2 为什么要使用视图,而不是表(面试可能会被问到)
如果你在面试的时候被问到这个问题,建议从下面这个流程来回答一下面试官。
首先介绍一下表的作用(比如表是直接存储结构化数据,可以扩展增删改之类的),之后在介绍一下视图是什么,之后从两个切入点来讲解视图的好处以及必要性,这两个切入点是:复用性和安全性,这里来简单总结一下:
- 简化查询,提高复用性
想象一下,一个人员宽表,里面有几百个字段,但是你每次只需要用到这个表中的姓名、性别、年龄这三个字段,那么你可以创建一个视图来直接使用,或者你这个人员表经常和另外一个履历表 join 组合在一起,而只取了其中的部分字段,并且频繁使用这几个字段。那么无疑创建视图是一个好做法。当然这种情况也可以说明使用视图能够简化查询。 - 提高安全性
- 通过视图,可以限制用户对敏感数据的直接访问。视图可以控制用户可以看到和操作的数据的范围,提供更好的安全性和隐私保护。这里还拿刚才我讲的姓名、性别、年龄三个字段,假如年龄是一个比较敏感的字段,那么对某些数据库用户只能查询姓名和性别的话,那么就可以设置一个视图分配给这个用户。
- 另外就是如果你要更新视图的时候,也只能更新视图所见的字段,用户对视图不可以随意的更改和删除,可以一定程度的保证数据的安全性。
讲解完上述的两个大的关键点后,也可以适当自行发挥,比如视图你可以调整表字段的显示顺序,或者字段名字等等。这些也是优点。可以适当进行讲解。
2.3 创建视图
创建视图的时候,对命名视图大家一般也有默认的规则,一般情况可以使用 v_ 或 view_ + 表名(表缩写)的形式。
例如:v_student
--创建视图
if (exists (select * from sys.objects where name = 'v_student'))
drop view v_student
go
create view v_student
as
select id, name, age, sex from student;2.4 创建视图准则
创建视图需要考虑一下准则:
- 视图名称必须遵循标识符的规则,该名称不得与该架构的任何表的名称相同。
- 你可以对其他视图创建视图。允许嵌套视图,但嵌套不得超过32层。视图最多可以有1024个字段。
- 不能将规则和 default 定义于视图相关联。
- 视图的查询不能包含 compute 子句、compute by 子句或 into 关键字。
- 定义视图的查询不能包含 order by 子句,除非在 select 语句的选择列表中还有 top 子句。
下列情况必须指定视图中每列的名称:
- 有列顺序需求(在某些情况下,您可能希望定义视图的结果集中列的顺序,并且这与基础表中的顺序不同。)
- 视图中的任何列都是从算术表达式、内置函数或常量派生而来
- 视图中有两列或多列具有相同名称(通常由于视图定义包含联接,因此来自两个或多个不同的列具有相同的名称)
- 有指定列别名的需求。注意无论是否重命名,视图列都需继承原列的数据类型
2.5 修改视图
修改视图和修改表有点类似,可以直接使用 alter 关键字进行修改,示例如下:
alter view v_student
as
select id, name, sex from student;
alter view v_student(编号, 名称, 性别)
as
select id, name, sex from student
go
select * from v_student;
select * from information_schema.views;2.6 加密视图
如果你对某一个视图有保护查询逻辑、防止修改或者查询加密的需求的时候,可以使用加密视图操作。
在 SQL Server 中 使用with encryption后,可以在创建视图时对其定义的 SQL 查询进行加密。也就是说 MSSQL 会对该视图的定义中的查询语句进行加密。这意味着其他人无法直接查看或分析该视图的查询逻辑。压根就看不到这个视图内部结构了。
-- 加密视图
if (exists (select * from sys.objects where name = 'v_student_info'))
drop view v_student_info
go
create view v_student_info
with encryption --加密
as
select id, name, age from student
go
--view_definition is null
select * from information_schema.views
where table_name like 'v_student';如何解密被加密的视图,或者修改已经被加密的视图:
一般情况一个视图被加密后,你需要修改它,那么大致有3个方法:
- 重新创建视图(先删除已加密的视图,然后使用新的查询逻辑重新创建视图。)。
- 创建新视图(创建一个新的,视图名称不同,之后调用这个新的)。
- 暴力解密之后修改(一般需要借助第三方工具或辅助,该方式个人不推荐)
2.7 视图能否被更新 update (面试可能会被问到)
视图可以被更新吗?什么情况下可以被更新? 如果面试官问了这两个问题,那么他还算友好的提醒了你,如果直接问了一句话“视图可以被更新吗?”,那么我感觉有被挖坑的嫌疑。
视图可以被更新,但不是所有的情况都可以。
视图更新必须遵循以下规则:
- 当视图的字段是通过字段表达式(Field Expression)或常数(Constant)计算得出的结果时,对该视图执行 INSERT 和 UPDATE 操作是不允许的,但可以执行 DELETE 操作。
- 若视图的字段是来自库函数,则此视图不允许更新;
- 若视图的定义中有 GROUP BY 子句或聚集函数时,则此视图不允许更新;
- 若视图的定义中有 DISTINCT 任选项,则此视图不允许更新;
- 若视图的定义中有嵌套查询,并且嵌套查询的 FROM 子句中涉及的表也是导出该视图的基表,则此视图不允许更新;
- 若视图是由两个以上的基表导出的,此视图不允许更新(源表单一才可以被更新);
- 一个不允许更新的视图上定义的视图也不允许更新;
- 由一个基表定义的视图,只含有基表的主键或候补键,并且视图中没有用表达式或函数定义的属性,才允许更新。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK