

10年首次登顶!CVPR 2023大奖揭晓:上海AI实验室/武大/商汤破纪录夺魁,西工大斩获最...
source link: https://www.36kr.com/p/2311902960184834
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

10年首次登顶!CVPR 2023大奖揭晓:上海AI实验室/武大/商汤破纪录夺魁,西工大斩获最佳学生论文
CVPR开奖了!
作为AI领域最有学术影响力的顶级会议之一,国际计算机视觉与模式识别会议(CVPR)今年的颁奖依然是万众瞩目。
今年共有5篇论文获奖。2篇最佳论文,1篇最佳学生论文,另外最佳学生论文提名和最佳论文提名也各1篇。
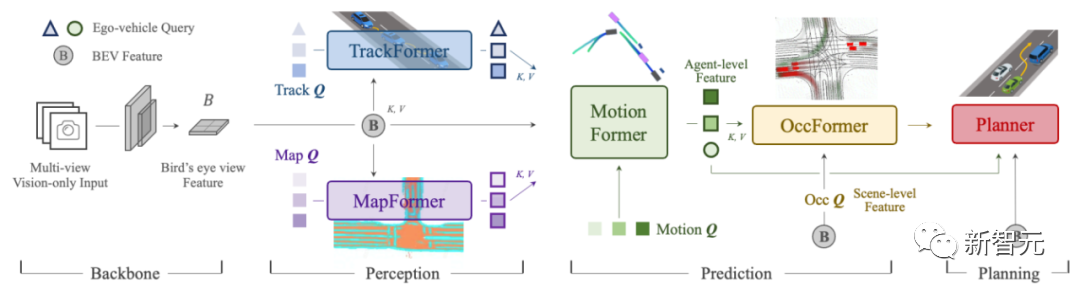
其中,上海AI实验室、武汉大学、商汤联手提出的Planning-oriented Autonomous Driving(以路径规划为导向的自动驾驶)一举夺得CVPR 2023最佳论文头冠。

论文首次提出感知决策一体化的自动驾驶通用大模型「UniAD」,开创了以全局任务为目标的自动驾驶大模型架构先河,为自动驾驶技术与产业的发展提出了新的方向。
据悉,这也是近10年来计算机视觉三大顶级会议中(CVPR、ICCV、ECCV),第一篇以中国学术机构作为第一单位的最佳论文。
与此同时,来自西北工业大学的团队也摘取了CVPR 2023的最佳学生论文。
而去年由谷歌推出,并风靡AI圈的扩散模型Dreambooth,则获得了本届最佳学生论文提名。
最佳论文
CVPR 2023共计评选出2篇最佳论文。
第一篇最佳论文颁给上海AI实验室、武汉大学、商汤科技团队的Planning-oriented Autonomous Driving。
获奖理由:
该文章提出一个端到端的感知决策一体框架,融合了多任务联合学习的新范式,使得进行更有效的信息交换,协调感知预测决策,以进一步提升路径规划能力。

论文地址:https://arxiv.org/pdf/2212.10156.pdf
这是CVPR历史上第一篇以自动驾驶为主题的最佳论文。

论文中,研究人员首次将感知、预测和规划等3大类主任务、6小类子任务(目标检测、目标跟踪、场景建图、轨迹预测、栅格预测和路径规划)整合到统一的基于Transformer的端到端网络框架下,实现了全栈关键任务驾驶通用模型。
在nuScenes真实场景数据集下,UniAD的所有任务均刷新SOTA,尤其是预测和规划效果远超之前的最佳方案。
其中,多目标跟踪准确率超越SOTA 20%,车道线预测准确率提升30%,预测运动位移和规划的误差则分别降低了38%和28%。
UniAD的价值就在于,能更好地协助进行行车规划,实现「多任务」和「高性能」,确保车辆行驶的可靠和安全。
另一篇最佳论文颁给AI2的CV研究团队Prior的「Visual Programming: Compositional visual reasoning without training」。
获奖理由:
解决了自然语言教学中的组成视觉推理任务,为视觉推理和神经符号研究提供了新的方向。

论文,研究人员中提出了VISPROG,一种根据自然语言指令解决复杂和组合视觉任务的方法。
只需要给出几个自然语言指令的示例和所需的高级程序,VISPROG使用GPT-3中的上下文学习为任何新指令生成一个程序,然后在输入图像上执行该程序以获得预测结果。

论文地址:https://arxiv.org/pdf/2211.11559.pdf
VISPROG还将中间的输出总结为可解释的视觉原理。
研究人员在一些任务上演示了VISPROG,这些任务需要组成一组不同的模块,用于图像理解和操作、知识检索以及算术和逻辑运算。

最佳学生论文
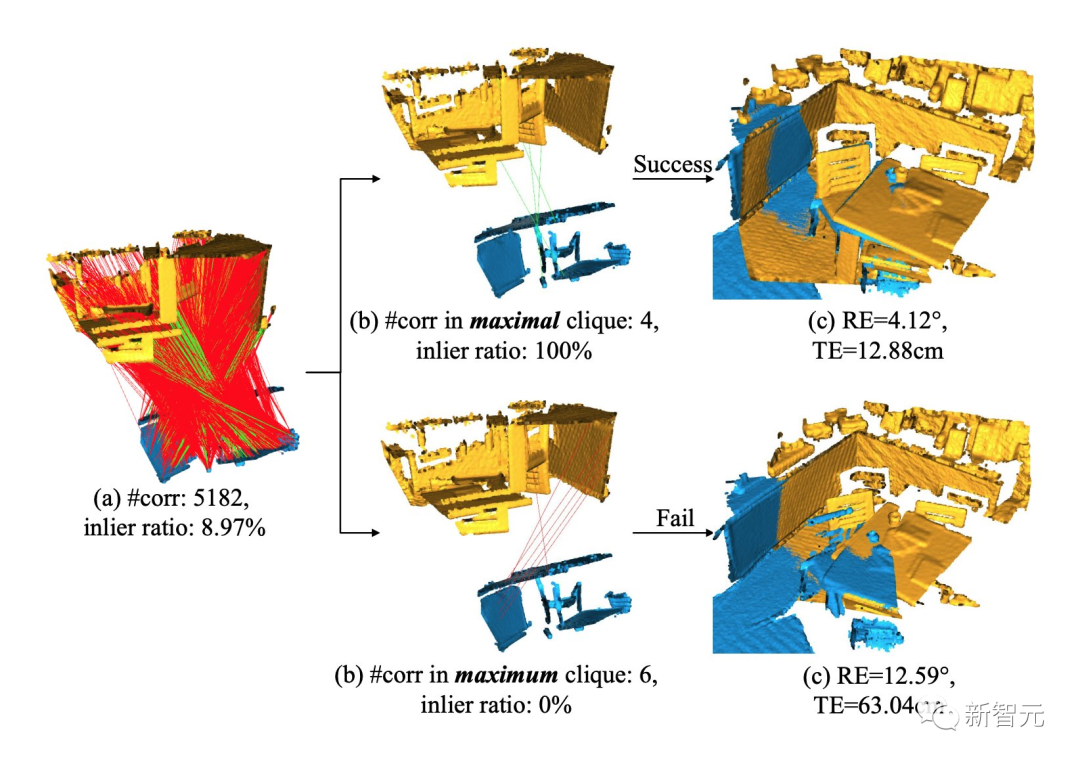
今年的「最佳学生论文」颁给了西北工业大学的「3D Registration with Maximal Cliques」。
获奖理由:
提出了一种解决点云配准基本问题的方法,该方法利用来自噪声点对应的兼容性图中的最大团约束。

3D点云配准(3D point cloud registration)是计算机视觉领域的一个基本问题,目的是寻找最优的点云对齐姿态。
这篇论文提出了一种基于最大团(maximal clique,MAC)的3D配准方法。

论文的核心思想就是放松先前的最大团约束,挖掘图中更多的局部共识信息,以准确地生成姿态假设:
1)构建相容图来呈现初始对应关系之间的亲和关系;
2)在图中搜索最大团,每个团代表一个一致性集合。然后执行节点引导的团选择,其中每个节点对应于具有最大图权重的最大团。
3)通过奇异值分解算法计算所选团的变换假设,并选择最佳假设进行配准。

论文地址:https://arxiv.org/pdf/2305.10854.pdf
在U3M、3DMatch、3DLoMatch和KITTI数据集上进行的大量实验表明,MAC能够有效提高配准准确性,优于现有的各种主流方法,并且提升了深度学习方法的性能性能。
MAC与深度学习相结合,在3D Match/3DLoMatch上实现了95.7%/78.9%d SOTA配准召回率。
最佳论文提名
「最佳论文提名」颁给来自谷歌和康奈尔大学的「DynIBaR: Neural Dynamic Image-Based Rendering」。
获奖理由:
对于具有复杂物体运动和不受控制的摄像机轨迹的长视频,在时空新颖视图合成方面向前迈出了重要一步。

现场,只有2位获奖者上台领奖。引台下观众大笑的是,没到现场3位童鞋,他们便拉了一条横幅代替。

以往,对于具有复杂物体运动和不受控制的摄像机轨迹的长视频,基于动态神经辐射场(即动态NeRF)的方法会产生模糊或不准确的渲染结果。
进而,限制了其在现实中的使用。
谷歌和康奈尔大学提出新的方法DynIBaR,通过采用基于volumetric的图像渲染框架,在场景运动感知的方式下,通过聚合附近视角的特征来合成新视角。

论文地址:https://arxiv.org/pdf/2211.11082.pdf
该系统保留了之前方法的优点,能够模拟复杂场景和视角相关效果,同时能够从具有复杂场景动态和自由摄像机轨迹的长视频中合成逼真的新视角。
在动态场景数据集上,DynIBaR在比现有方法上取得了显著的改进。

最佳学生论文提名
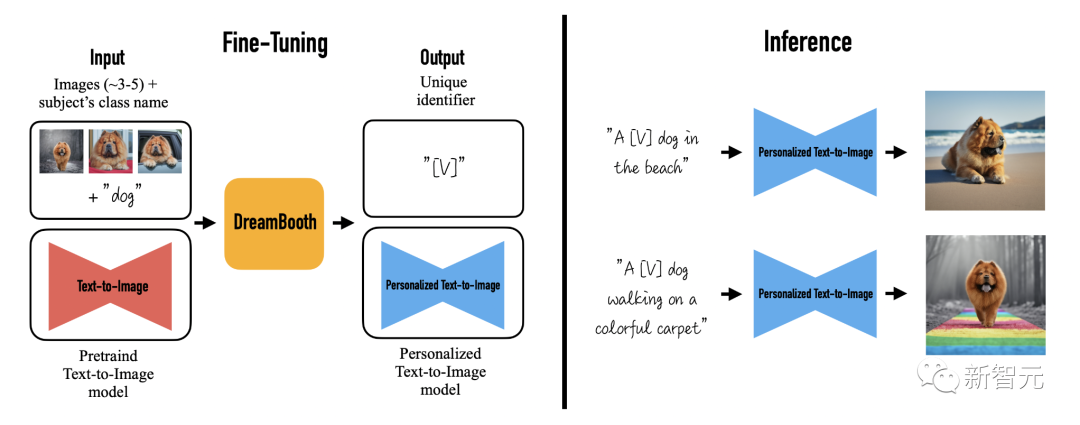
今年的「最佳学生论文提名」颁给了谷歌和波士顿大学的Dreambooth。
获奖理由:
显示了如何在文本条件下的图像生成扩散模型进行微调,以在新的背景、视角和艺术风格下仅使用少数图像样本生成目标对象,具有令人印象深刻的生成能力。

Dreambooth强大之处在于,只需要你上传3-5张指定的物体照片,再描述下想要生成的背景、动作或者表情,便能让指定物体「闪现」你想要的场景。

具体来讲,该研究将给定主题的图像植入模型的输出域,以便可以使用唯一标识符对其进行合成。
为此,研究人员提出了一种用稀有token标识符表示给定主题的方法,并微调了一个预训练、基于扩散的T2I框架,该框架分两步运行:
从文本生成低分辨率图像,然后应用超分辨率(SR)扩散模型。

论文地址:https://arxiv.org/pdf/2208.12242.pdf
虽然Dreambooth是在Imagen基础上做的调整,但这一全新方法也适用其他的扩散模型。
Longuet-Higgins奖
Longuet-Higgins奖会颁发给经受了时间考验的一篇10年前的CVPR论文。
该奖以理论化学家和认知科学家H. Christopher Longuet-Higgins命名。
这届Longuet-Higgins奖颁发给了「Online Object Tracking: A Benchmark」。


青年研究员奖
青年研究员奖奖会颁发给在获得博士学位后7年内,对计算机视觉做出杰出研究贡献的一位或两位研究人员。
本届的青年研究员奖颁发给了Christoph Feichtenhofer和Judy Hoffman。


黄煦涛(Thomas S. Huang )纪念奖
黄煦涛(Thomas S. Huang )纪念奖会颁发给在研究、教学领域被公认为楷模的研究者。
最后的黄煦涛(Thomas S. Huang )纪念奖,颁给了Alyosha Efros。

这个奖项从2020年开始设立,是为了纪念已故的黄煦涛教授,一位在CV和图像处理领域做出大量贡献的先驱学者。
该奖项每年颁发给博士毕业后至少7年、最好是处于职业生涯中期的研究人员(博士毕业不能超过25年)。

谷歌90+论文霸榜,CVPR 2023接收率新高
2月份,CVPR 2023曾公布了放榜率。

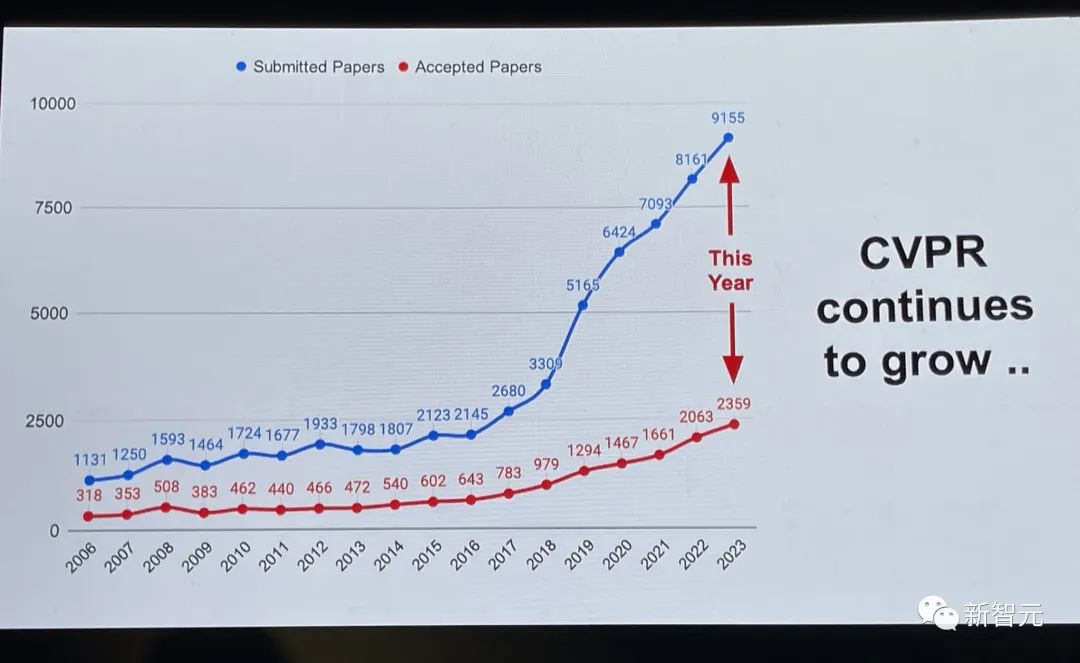
今年,CVPR论文接受和录用通通创下历史新高。
CVPR收到了创纪录的9155份论文(比CVPR2022增加了12%),并录用了2360篇论文,接收率为25.78%。
另外,今年参会人数也创自疫情以来历史最高。大约8300多人参会,其中线下人数近7000。
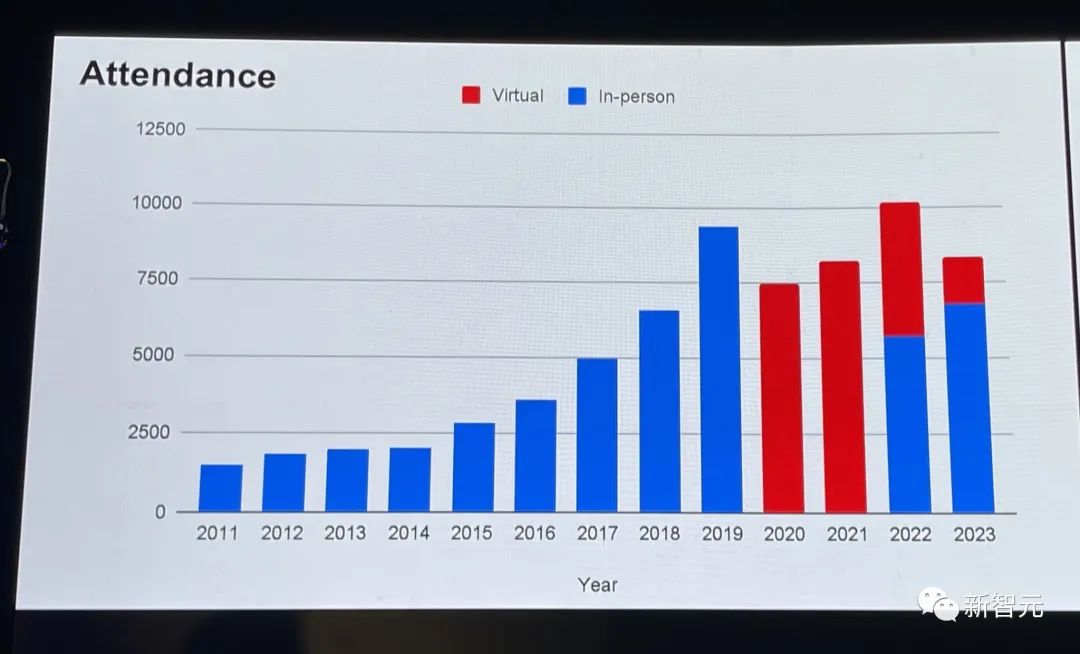
前段时间,CVPR曾公布12篇入围本届最佳论文候选名单(Award Candidate),包括谷歌、上海AI实验室、斯坦福大学、康奈尔大学等在内的世界顶尖企业及机构的研究。
最佳论文等奖项如何脱颖而出,大会介绍了其中的流程:
区域主席提名31篇最佳论文
高级区域主席选出12篇候选论文
程序主席组成委员会,并进行最终讨论

CVPR至尊地位,已经成为业界万众瞩目的一颗星。
根据Google Scholar,过去5年被引用最多的出版物中,CVPR位列第4。

值得一提的是,今年谷歌在众多机构被接收的论文拔得头筹,大约有90篇论文。
就国内来看,中国机构获奖论文许久未见如此盛况。
在本届CVPR上,上海AI实验室以一篇最佳论文、一篇最佳论文候选、12篇入选「Highlight」名单的成绩,颇受瞩目。
另外,商汤、武汉大学、西北工业大学同样在本届CV顶会大放异彩。
CVPR 2050长什么样?
在获奖论文颁奖结束后,来自华盛顿大学的Yejin Choi教授畅想了一下,CVPR 2050可能是什么盛况?
(当然,前提是AGI还未实现,智械危机还未成真)

在那时,或许CVPR 2050的颁奖大会是在元宇宙中举行的。

又或者,我们那时已经成功移民火星,所以举办了第一届CVPR火星大会。

那时,或许整个CVPR都会在AI的掌握之中,由ChatGPT写论文,ChatGPT审论文,最后再由ChatGPT rebuttal。
扩散模型会生成演讲幻灯片,NeRF来负责演讲,最后由ChatGPT完成总结。

那时,最流行的学术话题还是few-shot prompting、指令微调、NeRF、Diffusion、Transformers吗?亦或是自动驾驶/清洁/通水管/带娃?
那时,大语言模型还会是时代的先锋吗?Scaling laws或许已经失效了。
而到2050年,我们很可能还没有实现LeCun所言的「狗级」人工智能,AGI依然远在5到10年之外,组合性原则依然未被解决。

GPT 5/6/7或许已经达到了全知全能。

AGI可能在没有具身的情况下实现吗?RLHF真的能让LLM和真实对齐吗?Transformers真的能掌握组合性原则吗?

这些问题,都得留给未来解答了。
参考资料:
https://twitter.com/CVPR/status/1671545306838626306
本文来自微信公众号“新智元”(ID:AI_era),作者:新智元,36氪经授权发布。
该文观点仅代表作者本人,36氪平台仅提供信息存储空间服务。
Recommend
-
32
翻译 | 林椿眄 编辑 | 阿司匹林 出品 | 人工智能头条(公众号ID:AI_Thinker)
-
15
“安永企业家”中国区大奖揭晓 十位企业家当选 2020-12-19 13:56 12月18日,第十五届“安永企业家奖2020中国”获...
-
8
历经三个月的激烈角逐,2020数英奖最终诞生出了30件
-
14
中国电子信息博览会大奖揭晓 海信电视U7G-PRO获金奖 2021-04-10 12:1...
-
12
《东京动画节2022》年度大奖揭晓 EVA与咒术回战登顶 国际...
-
4
西工大遭美国国安局网络攻击/ UCLA推出「马斯克的法律」课程/ 传iPhone将取消SIM卡槽… 今日更多新鲜事在此 ...
-
4
解密!为了攻击西工大,美国国安局竟动用54台跳板机和代理服务器 作者:新智元 2022-09-05 17:34:40 今年4月,西北工业大学的信息系统发现遭受网络攻击。今天,幕后黑手终于挖出来了,没想到竟是美国国家安全局。
-
8
西工大遭美国国安局网络攻击、小米第一款车售价超30万元、免费开源虚拟机VirtualBox 6.1.38发布 | T资讯 原创 作者:路遥 2022-09-06 07:48:49
-
4
用全域安全防范美国NSA对西工大的网络侵略犯 精选 原创 上周在51CTO写的一篇文章《
-
1
西工大自研扑翼式无人机破世界纪录!单次飞行超154分钟 2022-12-12 15:48 出处/作者:快科技 整合编辑:佚名 0
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK