

How to Overcome GPT Token Limit?
source link: https://uxplanet.org/how-to-overcome-gpt-token-limit-721c30a18d55
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

How to Overcome GPT Token Limit?
Over the past few months, everyone has been talking about Large Language Models (LLMs) and how they can be used to improve products and life in general.
OpenAI, with ChatGPT, has shifted our perspective on models from «Oh, it’s too complicated» to «How can we apply this to our situation?».

Image from https://fireflies.ai/blog/what-is-gpt-3
Businesses and professionals are inventing more and more interesting use scenarios every day to improve our lives: increasing productivity, reducing costs.
ChatGPT is trained on a vast part of the internet and can answer almost any question, from coding to complex science.
I believe the first question that comes to any professional’s mind when they see such a convenient system is — how can we do the same thing in our product / life?
How can we make it so that the capabilities of ChatGPT use not just the entire internet, but also your knowledge accumulated over many years? For instance, all the documentation about your product, or an entire book / lengthy article that you want to learn?
Problem.
The first thing that comes to mind when you have such a need is to load everything into the context. And this is partly a good solution. The GPT model will be able to respond according to your context and will do it very well, but… the context window won’t allow you to do this.
The context window is the amount of information the model takes in and its response to you. The sum of received and created information is the context that the model can operate with.
Unfortunately, the context window of the model is only 4 thousand tokens (speaking about ChatGPT), or, if you have access to GPT-4, it’s 8 thousand tokens. But even if you take the latest GPT-3.5-Turbo model with 16 thousand tokens, it is still not enough to load, for example, an entire book or an entire section of your website, right?
So, what to do in this case, where to find a solution that will allow us to overcome this limit?
Vectors come to our aid.
Vector Indexes.
To avoid burdening you with technical details, I’ll start discussing this with a specific example.
Imagine that you have 100 documents containing information of 100 thousand tokens (70–80 thousand characters). And you want the model to be able to use this information to answer questions.
To do this, the first thing we need to do is cut all these documents into pieces, say, 2000 characters each.
In our case, we got 40 pieces, which we need to transform into vectors.
You probably have a lot of questions right away, but I promise that once I finish, everything will become clear to you.
After we’ve turned the 40 pieces into vectors, we can start working with them and use them to answer questions.
Each time a user asks a question to our system, we will transform his question into a vector as well, and then, using cosine distance, find the vectors of our document pieces closest to the question vector. It will search for the most suitable vectors where information on the topic is likely to be contained.
And then, the last step, we use the vectors of these pieces — we transform them from a vector into text. Then, we add them to the GPT context and ask the question that the user asked again. And GPT responds.
In other words, vector search is essentially a tool that allows you to add only relevant information from all the data you have loaded to the model’s context.
It’s probably not so easy to understand if you’ve never worked with vector bases and have no mathematical background. I will attach a conceptual diagram of how this works here to make it clearer:
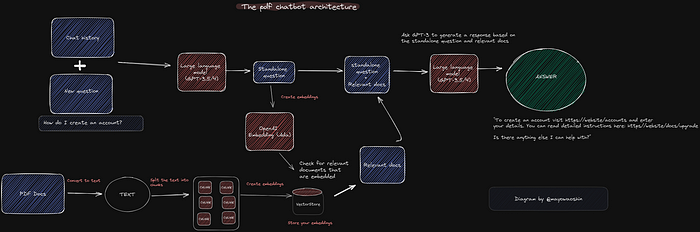
Image from https://github.com/mayooear/gpt4-pdf-chatbot-langchain/tree/feat/vectordbqa
It’s easier than it looks and incredibly effective.
Setting up.
I’m not a fan of articles that only provide high-level explanations without concrete usage examples, so let’s write the code together that allows you to do this and immediately apply what I’m talking about.
You have to start with the fact that vectors are data that needs to be stored somewhere. In the example, I will be showing it based on the Pinecone database. It’s a paid service (there is a free plan), but it seemed to me the simplest one to start with quickly.
Therefore, you need to register there and get access to the API key.
Let’s import the libraries.
We need OpenAI in this context to transform your documents into vectors.
Next we initialise pinecone, openai, nympy and create an index.
import openai
import os
import pinecone
import nympy as np
openai.api_key = ""
pinecone.init(api_key="", environment="")
# Choose an index name
index_name = " "
pinecone.create_index(name = "index_name", dimension=1536, metric="cosine", pod_type="p1")
# Connect to the index
index = pinecone.Index(index_name=index_name)
Upload your documents. Any format you like. And add code that can cut your document into chunks.
def split_document(document, chunk_size=2000):
chunks = []
for i in range(0, len(document), chunk_size):
chunks.append(document[i:i+chunk_size])
return chunks
When the documents are ready, then let’s do 3 actions: add meta-information about them, convert them into vector and load them into index.
For vector conversion we will use OpenAI’s Ada model, because it is incredibly cheap and efficient for such tasks.
MODEL = "text-embedding-ada-002"
def upsert_documents(documents, metadata, index):
# Creating embeddings for each document and preparing for upsert
upsert_items = []
for i, chunk in enumerate(chunks):
res = openai.Embedding.create(
input=[chunk],
engine=MODEL
)
embedding = [record['embedding'] for record in res['data']]
# Include the original document text in the metadata
document_metadata = metadata.copy()
document_metadata['original_text'] = document
upsert_items.append((f"{metadata['file_name']}-{i}", embedding[0], document_metadata))
# Upsert to Pinecone
index.upsert(upsert_items)
def read_document(file_path):
with open(file_path, 'r') as file:
document_content = file.read()
return document_content
# Example usage
file_path = 'path/to/document.txt'
document = read_document(file_path)
metadata = {"file_name": "your_file_name"}
So, there’s just a little bit left to get the cherished result.
The next task is to take the user’s question, convert it to a vector and search for the closest documents to that question.
## Converting question to vector
def get_query_embedding(query):
res = openai.Embedding.create(
input=[query],
engine=MODEL
)
query_embedding = [record['embedding'] for record in res['data']]
return query_embedding[0]
## Find top_k similar vectors to question vector
def query_index(query, top_k, index):
# Convert the query into an embedding
query_embedding = get_query_embedding(query)
# Query the index
results = index.query(queries=[query_embedding], top_k=top_k, include_metadata=True)
# Extract original_text from metadata for each match
original_texts = [match.metadata['original_text'] for match in results.results[0].matches]
return original_texts
Almost there.
Next we need to transfer this text to GPT and ask the question again.
def prepare_gpt_context(query, chunks, question):
# Create a single context string from the chunks, the query and the question
context = '\n'.join(chunks)
context += '\n\n' + query
context += '\n\n' + question
return context
def generate_response(context):
response = openai.ChatCompletion.create(
engine="gpt-3.5-turbo",
prompt=context,
max_tokens=1024, # Adjust based on your requirements
)
return response.choices[0].text.strip()
Now let’s get it all together and get it running!
## Upload a document
document = 'your_document_path'
metadata = {"file_name": "your_file_name"}
## Split document to chunks and upsert embeddings
document_chunks = split_document(document)
create_embeddings_and_upsert(document_chunks, metadata, index)
## Get answer on your question
question = "Your question here"
chunks = query_index(query, top_k=3, index=index)
context = prepare_gpt_context(query, chunks, question)
response = generate_response(context)
print(response)
Okay, ready!
Congratulations, now you know how to overcome the contextual window limit in GPT.
Important Detail.
The code I provided above is a complex way to implement this process. I did it just so you could understand how it works internally. The more you understand what’s going on inside, the easier it is to work with.
In fact, there are very simple ways to do the same thing in 5–10 lines of code, which will work even better.
Suppose in LangChain — the code I wrote above (which works even better), looks like this:
## Load a document
from langchain.document_loaders import TextLoader
loader = TextLoader('../../modules/state_of_the_union.txt')
## Create Index
from langchain.indexes import VectorstoreIndexCreator
index = VectorstoreIndexCreator().from_loaders([loader])
## Query index
query = "What did the president say about Ketanji Brown Jackson"
index.query(query)
Looks simpler, doesn’t it?
If you’re interested, I highly recommend reading and looking at these repositories:
Conclusions.
There are plenty of interesting examples of using LLM models together with vector storage. One of the founders of OpenAI said: «Prediction is compression».
How you compress data and how you deliver it to your model is a key parameter for the success of your future use cases.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK