

现代硬件算法[3]: 指令级并行
source link: https://no5-aaron-wu.github.io/2023/06/12/HPC-3-AMH-ILP/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

现代硬件算法[3]: 指令级并行
指令级并行
当程序员听到并行(parallelism)这个词时,他们主要想到的是多核并行(multi-core parallelism),即将计算过程明确地拆分为协同工作的半独立的线程(threads),以此解决常见问题。
这种并行主要是为了减少延迟(latency)和实现可扩展性(scalability),而不是为了提高效率(efficiency)。你可以用并行算法解决十倍大的问题,但它需要至少十倍的计算资源。尽管并行硬件越来越丰富,并行算法设计也越来越重要,但目前,我们先只考虑单个CPU内核的情况。
还有其他类型的并行,已经存在于CPU内核中,可以免费(不需要额外计算资源)使用。
指令流水线
要执行任何指令,处理器首先需要做大量的准备工作,包括:
-
从内存获取(fetch)机器代码块;
-
对其进行解码(decode)并分割成指令;
-
执行(execute)这些指令,其中可能涉及一些访存(memory)操作;
-
将结果写(write)回寄存器。
整个操作序列很长。即使是像将两个寄存器中的值相加这样简单的操作,也需要15-20个CPU周期。为了隐藏这种延迟,现代CPU使用了流水线(pipelining):在指令通过第一阶段后,立即开始处理下一条指令,而无需等待前一条指令完全完成。
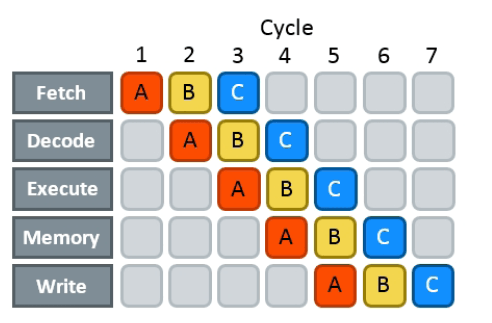
流水线并不能减少实际的延迟,但在功能上使其看起来像是只由执行和访存阶段组成。你仍然需要花费这15-20个周期,但你只需要在要执行的指令序列的最后做一次。
考虑到这一点,硬件制造商更喜欢使用每条指令的周期数(cycles per instruction,CPI),而不是像“平均指令延迟”这样的指标作为CPU设计的主要性能指标。对算法设计而言,只考虑有用的指令也是一个很好的指标。
一个完美的流水线处理器的CPI应该无限接近于1,但是我们可以通过复制流水线的每个阶段来使流水线变得“更宽”(即增加一条流水线),从而一次可以处理多条指令,那么CPI实际上可能会更低。因为缓存和大部分ALU可以共享,所以增加一条流水线会比添加完全独立的内核更便宜。这样的架构能够在每个时钟周期执行一条以上的指令,被称为超标量(superscalar),大多数现代CPU都支持超标量。
只有当指令流包含一组可以单独处理的逻辑上独立的运算时,才能利用超标量处理。指令并不总是以最合适的顺序到达,因此,在可能的情况下,现代CPU可以乱序(out of order)地执行指令,以提高整体利用率并最大限度地减少流水线停滞。至于乱序执行具体是如何工作的,是一个更加深入的主题,目前你可以简单地假设CPU维持一个缓冲区给未来一段距离内将要执行的挂起指令,在其所依赖操作数的值完成计算,并且有可用的执行单元时,立即执行这些指令。
考虑一下我们的教育系统是如何运作的:
- 内容是向整个学生群体而不是个人教授的,因为同时向所有人广播相同的内容更高效。
- 招收的学生被分成由不同老师领导的班级;作业和其他课程资料在班级之间共享。
- 每年都会给新生教授同样的课程,这样老师们就可以一直工作。
这些创新大大提高了整个系统的吞吐量(throughput),尽管延迟(latency)(学生毕业的周期)保持不变(可能会增加一点,因为个性化的精准辅导更高效)。
你可以找到许多与现代CPU类似的东西:
- CPU使用SIMD并行在不同数据精度(16、32或64个字节)的块上执行相同的操作。
- 有多个执行单元可以同时处理这些指令,同时共享其他CPU单元(通常为2-4个执行单元)。
- 指令以流水线方式处理(节省的周期数可以类比为幼儿园到博士之间的年数)。
除此之外,其他几个方面也很相似:
-
执行路径随着时间的推移变得越来越不同,并且需要不同的执行单元(有人读大学,有人读大专)。
-
某些指令可能由于各种原因而被搁置(留级)。
-
有些指令被预测执行(提前执行),但随后被丢弃(跳级但翻车)。
-
一些指令可以分为几个不同的微操作,这些操作可以独立执行。
对拥有流水线和超标量的处理器进行编程有其自身的挑战,我们将在本章中对此进行阐述。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK