

华为、特斯拉带头,车企卷入「大模型」军备竞赛
source link: https://www.geekpark.net/news/320677
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

华为、特斯拉带头,车企卷入「大模型」军备竞赛

智能驾驶,还未出现类似 ChatGPT 的「涌现」能力。
自动驾驶的进程,因为大模型又起波澜。
近几年,自动驾驶近年发展迅猛,硬件预埋软件持续迭代的风潮下,车载算力急剧增长快速普及,但软件端功能进化滞后于算力。人们似乎开始接受要经过很长时间才能发展到自动驾驶。
但 ChatGPT 的出现带给自动驾驶行业很大启示。
ChatGPT 作为大语言模型的代表,通过对海量多模态数据的大规模自监督学习,借助「预训练+微调」的方式,让 AI 可以完成各种复杂自然语言任务,甚至通过了图灵测试——自动驾驶,被认为是下一个可能实现突破的领域。
北京智源人工智能研究院院长黄铁军甚至预测,三年之内可以实现高级别自动驾驶。
目前,在产业界很多公司都在「大模型上车」上进行探索。一部分自建大模型,商汤发布的日日新大模型,毫末智行发布了自动驾驶生成式大模型 DriveGPT——雪湖·海若;另一部分公司走联合路线,比如小鹏汽车联合阿里的大模型建立自动驾驶智算中心、斑马智行接入阿里大模型等。
「大模型上车」目前重点进展:
数据标注——特斯拉等公司,通过大模型优化数据标注,降低了人工标注比例和成本;
仿真优化——提升虚拟训练环境的真实性,优化虚拟训练数据;
优化感知——利用大模型能力,优化多个环节的小模型,提高感知效果;
端到端——利用生成式预训练大模型技术,让自动驾驶模拟类似人脑驾驶的能力。
大模型会如何影响智能驾驶?现在有哪些公司和团队,已经开始实践「大模型上车」了?它真的能让无人驾驶更快到来吗?
小模型 VS 大模型
智能驾驶行业,经历了一个模型「从小到大」的过程。
目前已量产的智能驾驶,绝大多数采用的是模块化架构。简而言之,模块化是将智能驾驶系统拆分为多个典型任务,并由专门的 AI 模型或模块处理。
现阶段的自动驾驶模型框架主要由感知、规划决策和执行三个部分组成。感知模块就像是人的眼睛和耳朵,负责对外部环境进行感知;控制模块就像人的双手和双脚,负责最终的加减速、转向等操作;而决策规划模块就像人的大脑,基于接收到的感知等信息进行行为决策和轨迹生成。
在此架构下,每个大模块可能包含多个小模型的组合。如感知模块可能包含分类、追踪和定位等不同 AI 模型,各司其职。
不过,随着软硬件升级与逐步深入,自动驾驶对于计算能力和海量数据处理能力的需求暴增,传统各个小模型「堆叠」的方案,已经无法满足城市自动驾驶的需求。比如,「堆叠」造成信息失真以及算力浪费,而每个小模型的技术「天花板」也会导致整体解决方案受限。
举个简单例子,小模型就像一个小孩,他非常擅长看图和听故事,可以快速地找到图片中的物品或者听懂一段故事的意思。但是,如果这个故事太长或者太复杂,他可能就会听不懂或者忘记了。
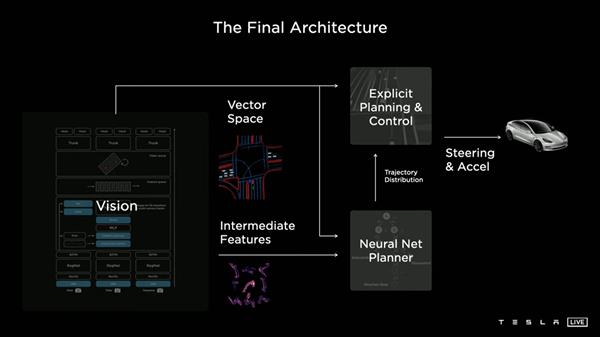
特斯拉自动驾驶技术架构 | 特斯拉
这个时候,大模型开始进入业界视野。
2021 年 8 月,特斯拉的 AI 高级总监 Andrej Karpathy,在特斯拉 AI DAY 上展示了一项新技术——基于 Transformer 的 BEV(鸟瞰视角) 感知方案。相当于车辆正上方 10-20 米有一个直升机俯视车辆与周围环境,这是大模型技术首次应用于自动驾驶领域,也是特斯拉实现纯视觉智能驾驶方案的关键。
华为、百度 Apollo、蔚小理、毫末智行、商汤等一众厂商,甚至像地平线这样的芯片公司,也都在 BEV+Transformer 上有所布局。例如华为的 ADS 1.0,据称已实现基于 Transformer 的 BEV 架构,而最新发布的 ADS 2.0 进一步升级了 GOD 网络,类似于特斯拉的占用网络算法。
而大模型则可以比喻成一个大人,他非常聪明,可以同时处理许多信息,包括看图片、听故事和听音乐等。他可以处理很长的故事或音乐,同时处理多个任务。不过,他需要更多时间和精力学习和处理这些信息。
值得注意的是,Transformer 不等于大模型。它是模型的底座,大模型的架构可以基于 Transformer。
大模型时代的数据和算法
在特斯拉使用 Transformer 之后,大模型早已经不限于智能驾驶感知领域。
目前,智能驾驶已从仅使用模型进行图像感知,使用规则算法的方式,转变为感知、融合、预测全面使用模型。
其中,这是大模型在智能驾驶领域最先落地的几个场景。
自动标注是大模型最直接的应用之一,可以大大降低数据标注成本。海量高效的数据标注是算法模型的基础。随着智能驾驶的发展,激光雷达 3D 点云信息和摄像头采集的 2D 图像信息增加,道路场景更丰富,自动驾驶的数据标注类型和数量不断增加。
然而,数据挖掘难度大,数据标注成本高。所以,智能驾驶厂商通过自动标注优化系统效率。例如,特斯拉从 2018 年以来不断发展自动标注技术,从 2D 人工标注转为 4D 空间自动标注。随着自动标注技术的成熟,特斯拉的人工标注团队规模不断缩小。2021 年该团队超过 1000 人,2022 年裁员超过 200 人。
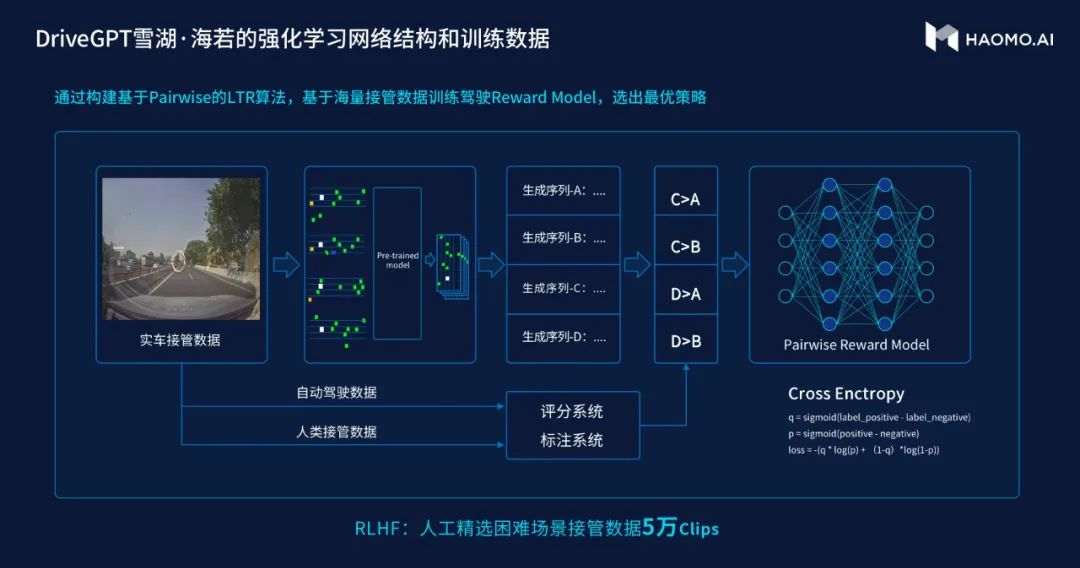
毫末智行发布的自动驾驶生成式大模型 DriveGPT——雪湖·海若 | 毫末智行
小鹏汽车和毫末智行也相继推出自动标注工具。据毫末智行 CEO 顾维灏表示,目前获取车道线、交通参与者和红绿灯信息,人工标注成本约每张图 5 元,而毫末 DriveGPT 的成本仅 0.5 元。
除此之外,自动驾驶需要大量的数据支持,数据积累将长期内是自动驾驶的核心竞争点。目前,数据来源主要有真实数据、虚拟仿真和影子模式。
除真实数据外,仿真场景是弥补训练大模型数据不足的重要方式。虚拟仿真通过 AI 生成道路场景、车辆和行人等信息,对模型进行训练。可用于对行车采集的 corner case 进行反复模拟和训练,弥补现实场景采集信息不足的问题。
目前仿真场景主要由游戏引擎生成,基于现实世界数据保证仿真场景与真实场景的相似度,依靠交通要素的重新组合提高泛化能力。理论上,优质仿真可替代实车数据收集,降低算法搭建成本并提高迭代速率,但逼真的仿真环境构建和许多长尾场景的复现难度大。
大模型有望推动仿真场景大幅提升泛化能力,帮助主机厂提升仿真场景数据的应用比例,从而提高自动驾驶模型的迭代速度、缩短开发周期。
比如特斯拉基于虚幻 4 引擎渲染的仿真环境,测试自动驾驶系统在极端情况和复杂环境中的效果。毫末智行选择与阿里和德清政府合作,将真实交通流导入仿真引擎,用于路口场景的调试和验证。
优化小模型
除了数据层面,在模块化的算法部署模式下,感知算法和规控算法可通过大模型的加强实现感知精度和规控效果的提高。例如,大模型作为车端算法的「老师」,通过「蒸馏 (教授)」帮助小模型实现优异的性能。所谓「蒸馏」,就像老师教学生,将大模型或多个模型集学到的知识迁移到另一个轻量级的模型上。
比如百度将文心大模型的能力与自动驾驶感知技术结合,提升车载端侧模型的感知能力百度利用半监督方法,充分利用 2D 和 3D 数据训练一个感知大模型。通过在多个环节对小模型进行蒸馏,提高小模型的性能,同时通过自动标注为小模型定制化训练。大模型可以增强远距离视觉 3D 感知能力、提高多模态感知模型的感知效果。
端到端一体化端到端的感知决策一体化算法被认为是自动驾驶算法终局,预测、规划、决策都在这个模型里。所谓「端到端」并不是自动驾驶领域独有的说法,本身是深度学习的一个概念,英文为「End-to-End(E2E)」,简单说就是一个 AI 模型,只要输入原始数据就可以输出最终结果,与 ChatGPT 类似。
在智能驾驶领域,端到端并不是新概念,1988 年面世的 ALVINN 自动驾驶试验车基于端到端架构,在大学校园实现最高 70km/h 的自主行驶。目前,许多厂商研发端到端智能驾驶技术,除特斯拉外,还有英伟达和 comma.ai 等。
这一驾驶方案更接近真实人类驾驶,只需要一个人来开车,从眼睛看到双手转方向盘、脚踩刹车或制动板,整个过程一气呵成,关键因素是人类的大脑中枢神经系统,端到端大模型的作用类似于人类的大脑中枢神经系统。
毫末 DriveGPT 底层模型,同样采用 GPT 这种生成式预训练大模型技术,首先通过引入大规模驾驶数据进行预训练,然后使用奖励模型 (Reward Model) 与 RLHF(人类反馈强化学习) 技术对人驾数据进行强化学习,对自动驾驶认知决策模型进行持续优化。
端到端自动驾驶,只是实现自动驾驶的最理想技术方案,带有研究者的理想主义情感。目前,端到端大模型还存在许多痛点,最大的痛点是可解释性差。
从 PPT 到落地
然而,大模型和智能驾驶的融合并非一蹴而就。
理想汽车创始人、董事长兼 CEO 李想认为,大模型和智能驾驶可以分为三个阶段:
- 第一阶段是赋能,也就是智能辅助驾驶,赋能驾驶员,让驾驶更安全、便捷。这个阶段需要进行人机共驾的过程来训练大模型;
- 第二阶段是半机器人。随着越来越多的人使用辅助驾驶,智能驾驶会形成半机器人。它可以解决酒驾、疲劳驾驶等问题,相当于垂直领域的专家,可以看作是真正免费的司机;
- 第三阶段是 AGI(通用人工智能)。行为学习和认知学习会二合为一,大脑和小脑同时具备,机器可以独立获取信息,形成自主迭代。虽然无法预测这个阶段何时到来,但我们对此充满期待。

大模型发展时间线 | 网络
不过,大型模型在智能驾驶领域面临着众多挑战:
多模态数据
主要体现在多模态数据、训练和部署等几个方面。比如,自动驾驶所需传感器数据包括激光雷达、毫米波雷达、超声波雷达,以及高清摄像头、IMU、GPS 以及 V2X 等。这些数据来自不同的坐标系,带有不同的触发时间戳,以及要考虑到硬件损坏等问题时;同时,需要大量的场景数据,比如交通标志线、交通流、行为模型等等。
算力+芯片难题
从部署方面看,大模型需要高规格的硬件配置,包含高性能计算能力、大容量内存和低时延等特点。但车载设备的硬件条件相对有限,无法提供足够的计算资源支撑大模型运行。
具体来说,大型模型需要超过 10 亿级的 GPU 计算能力,例如在自然语言处理领域的 GPT-3 模型就需要数万亿次浮点运算(Tops)的计算能力。这要求芯片的算力至少要在万级 Tops 以上才能够胜任大型模型的计算任务。但是,在车载部署场景下,芯片的算力往往只有数百 Tops 左右,远远达不到大型模型的要求。
同时,大型模型需要大量的内存来存储模型参数和中间状态。例如,在自然语言处理领域的 GPT-3 模型中,需要使用 350GB 的内存来存储模型参数。但是,在车载部署场景下,芯片的内存容量通常只有几十 GB。
此外,大型模型的部署还需要考虑时延的问题。例如,在自动驾驶场景下,需要对海量数据进行实时处理和分析,因此需要保证模型的推理速度和响应时间。但是,在车载部署场景下,要求模型的推理时延要控制在 10ms 级别。
总的来说,大型模型在智能驾驶领域仍是一个初级探索阶段,需要进行算法优化和硬件进一步改进才能真正落地应用。但它给业界带来的期望也很大——有望在未来让自动驾驶成为真正的「老司机」。
一个邀请:
目前正在、或者计划将大模型与汽车行业进行结合的团队或个人,不论是否已有产品落地,欢迎联系本文作者 周永亮(Wechat:zhouxizi77),咱们一起聊聊「大模型上车」!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK