

小模型的意见也有用!GPT-4+AutoGPT在线决策:买东西再也不用纠结了
source link: https://www.51cto.com/article/757622.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

小模型的意见也有用!GPT-4+AutoGPT在线决策:买东西再也不用纠结了
这篇论文通过对真实世界决策任务中的Auto-GPT代理进行了全面的基准研究,探索了大型语言模型(LLM)在决策任务中的应用。

论文链接:https://arxiv.org/pdf/2306.02224.pdf
作者比较了多种流行的LLM(包括GPT-4,GPT-3.5,Claude和Vicuna)在Auto-GPT决策任务中的表现,并引入了一种名为「额外意见」的新算法,该算法可以将小的专家模型融入到Auto-GPT方案中,从而提高了任务性能。
在这一研究中最有趣的发现是大语言模型,尤其是GPT4有了类似于人类的能力,可以从不同的意见中提取有用信息,进行思考和批判然后提高自己的结果。
那么问题来了,GPT是怎么受益于不同意见的呢?
人类的心理学研究过一些人类受益于不同意见的方式以及一些模式,比如人类会给有权威的意见更多的权重,会倾向于忽略极少数的个别意见,会给自己的意见过多的权重,通常三到六个意见就足够了等等。
这个方向还值得很多后续的研究,比如现在我们是用一个小的专家模型来提供不同意见,如果让大模型们互相争论呢?
1.首次展示Auto-GPT可以轻松适应与真实世界场景密切相似的在线决策任务。
2.提供了流行LLM(包括GPT-4, GPT-3.5,Claude和Vicuna)之间的全面基准比较。我们提出了关于这些模型适用于自主代理的发现。
3. 证明了从小的专家模型那里获得的第二意见可以显著提高任务性能。这可以成为为在不进行模型微调的情况下将监督信号引入Auto-GPT的一种新的方法。
提示设计
在没有进行大规模调优的情况下,我们将任务需求或问题直接作为Auto-GPT的目标,适配了Auto-GPT进行各项任务。
比如输入像「I want to purchase a folding storage box that is easy to install, made of faux leather, and has dimensions of 60x40x40cm」的句子。
为了帮助Auto-GPT理解可用的行动,我们将每个行动表现为一个工具。
值得注意的是,在没有示例的情况下,仅使用工具指令的效果较差。然而,只要有少量的示例,性能就会显著提高。因此,我们在工具演示中包括一到三个few-shot示例,以利用LLM的上下文学习能力。
考虑额外意见
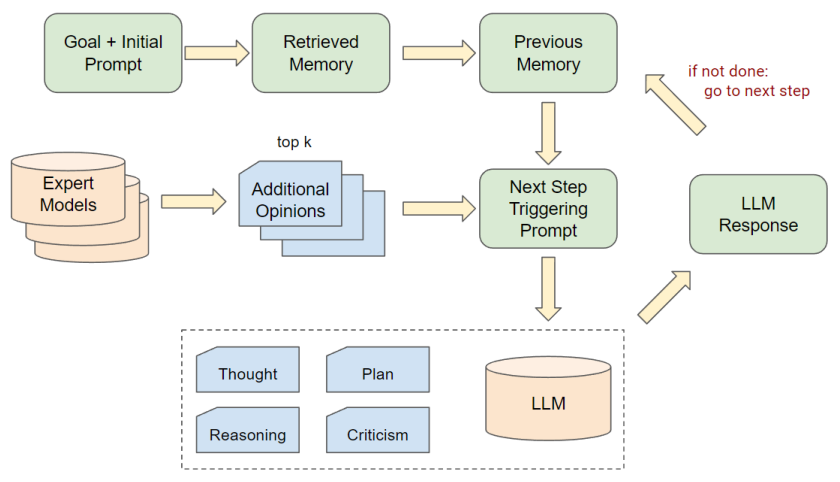
我们进一步改进了Auto-GPT的工作流,以便考虑来自外部专家模型的额外意见。
具体来说,在Auto-GPT的决策阶段,我们从专家模型中抽样出前k个意见,并将这些意见放入提示的上下文部分,以供大语言模型参考。
在这项工作中,我们简单地使用了对于每个任务都已经准备好的IL模型作为外部专家。
提供给LLM额外意见的提示遵循这样的模板:‘Here’s one(a few) suggestion(s) for the command: Please use this suggestion as a reference and make your own judgement. ’
Webshop实验设置:
Webshop是一个模拟网购环境,从http://Amazon.com上抓取超过118万个产品。
该环境提供了如搜索、点击、导航、购买等真实的行动空间。
评估过程主要看是否成功购买了描述的产品,需要产品、属性、选项和价格全都匹配。
基线模型是采用模仿学习(IL)方法的模型,它的动作策略组件已经过微调。这个基线模型将与采用Auto-GPT方式运行的大语言模型进行比较。
ALFWorld实验设置
ALFWorld是一个研究环境,结合了复杂的任务导向和语言理解。该环境包含超过25000个独特的、程序生成的任务,涵盖厨房、客厅、卧室等真实环境。
这些任务需要复杂的解决问题的能力和对语言及环境的深入理解。初始评估使用模仿学习(IL)的DAgger代理进行,然后与采用Auto-GPT风格的生成语言模型进行比较。
直接比较结果
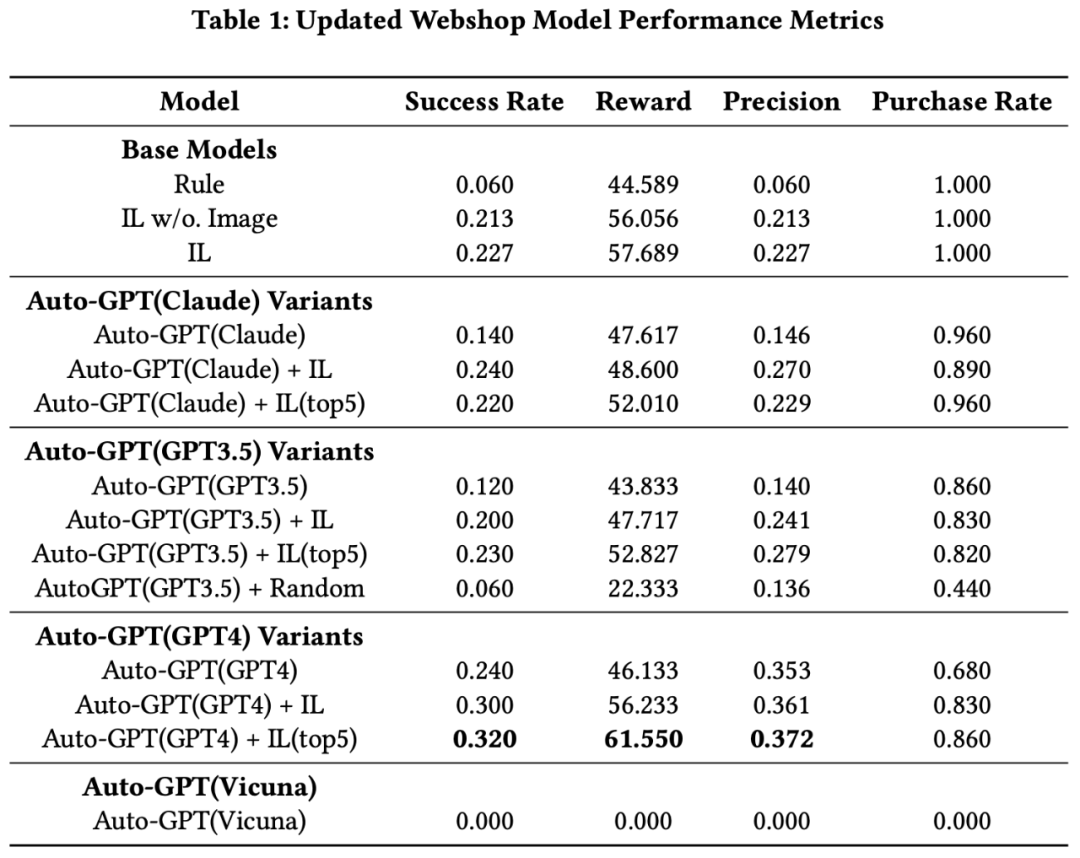
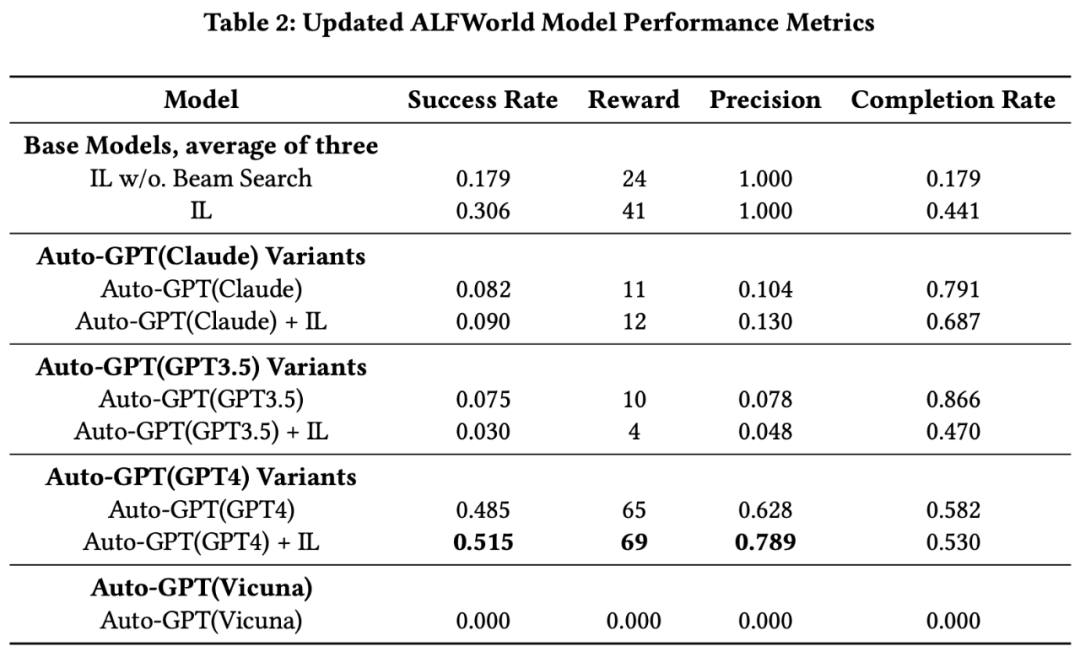
本研究主要通过运行Webshop和ALFWorld两种实验,比较了不同的大型语言模型(Large Language Models,LLMs)和模仿学习(Imitation Learning,IL)模型在AutoGPT配置中的表现。
首先,Webshop试验中,GPT4表现出色,其性能超过了其他IL模型。尽管无图像输入的原始IL模型仅取得了适度的成功率,但是加入了图像输入的IL模型表现更好。
然而,只使用GPT3.5或Claude的Auto-GPT代理表现不如原始IL模型,但是,GPT4本身的性能优于所有IL模型。
其次,在ALFWorld实验中,IL模型与Beam Search的组合显著优于无Beam Search的版本。而在AutoGPT设置中运行的Claude和GPT3.5的性能均未超越IL模型,但GPT4明显超越了IL模型的性能,无论是否使用Beam Search。
此外,我们提出了一种新的研究模式,将大型语言模型(LLMs)与专家模型结合起来。
首先从专家模型中采样出前k个附加观点,然后将这些观点呈现给LLMs,让它们考虑这些观点并做出最后的决定。这种方法在GPT4上表现得特别好,这表明GPT4在考虑来自多个弱学习模型的观点时,可以提高其性能。
总的来说,GPT4在所有模型中表现出了最佳的性能,并且能够有效地利用专家模型的建议来提高其决策能力。
我们推荐使用GPT4,因为它在考虑了其他模型的观点后,其决策性能显著提高。最后Abaltion Study证明了这些额外意见必须是有一点价值的,随机的意见并没有任何帮助,见AutoGPT(GPT3.5) + Random
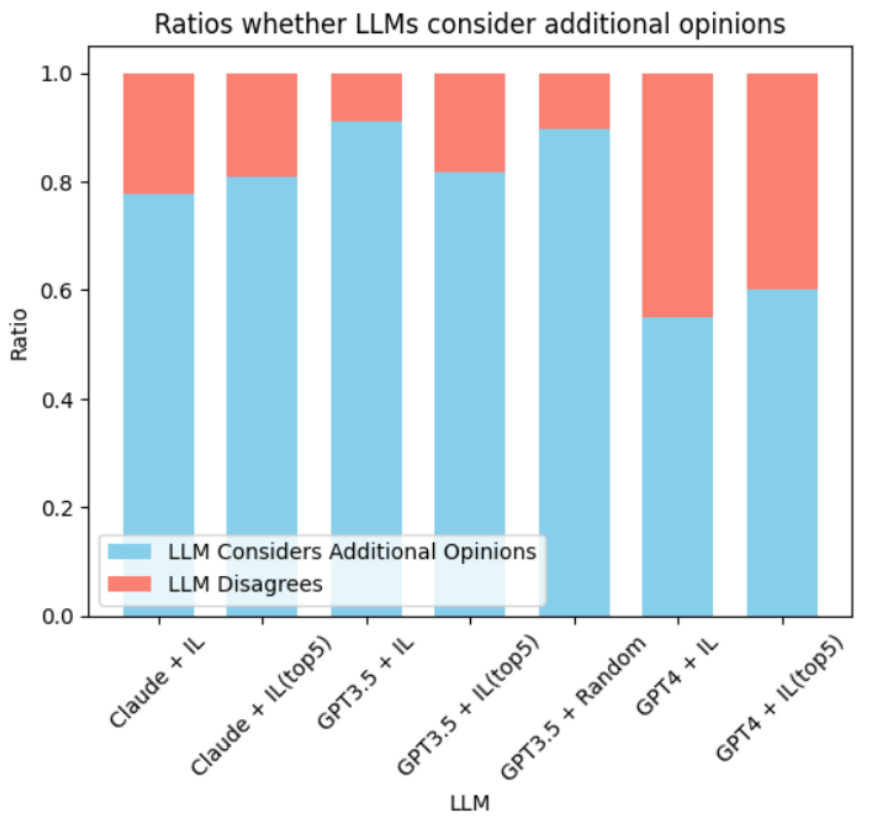
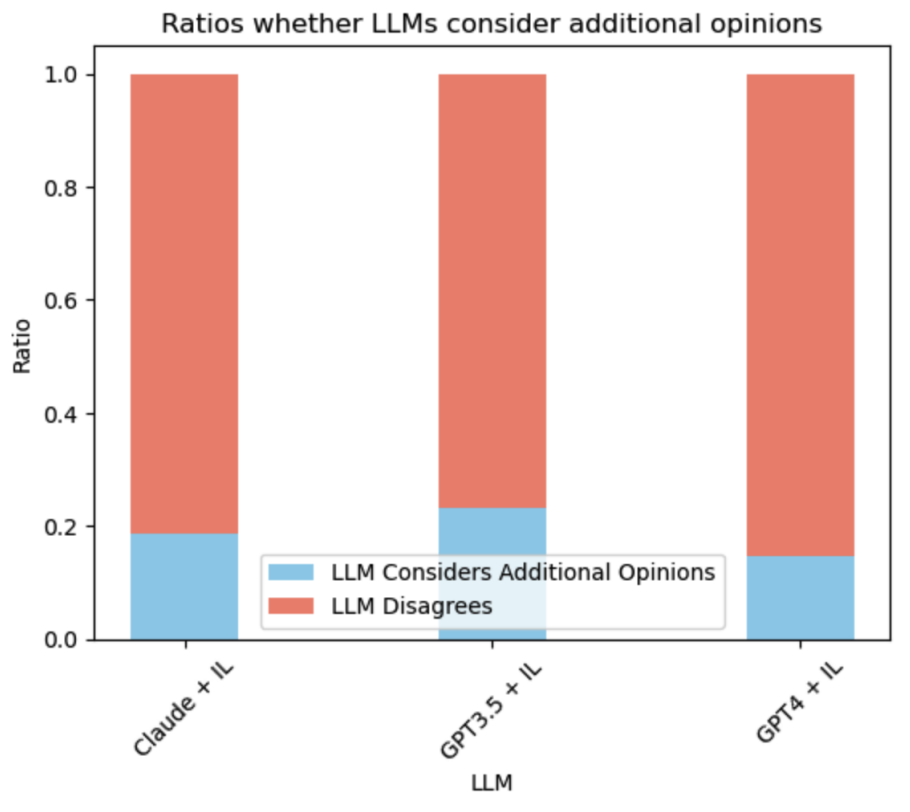
采用额外意见比例
在我们的实验中,我们发现GPT-4模型在处理额外意见时表现出极高的辨别能力。即使在信息噪声中,GPT-4也能区分出有益和无关的建议。
而GPT-3.5模型在面对可能导致混淆的输入时,表现出了明显的劣势。总的来说,LLM与额外意见的一致性或不一致性,很大程度上取决于LLM的理解能力和额外意见的质量。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK