

硬核科普:从贝叶斯定理到大语言模型,智能写作创业者的探索之路
source link: https://www.woshipm.com/ai/5845214.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

硬核科普:从贝叶斯定理到大语言模型,智能写作创业者的探索之路
最近这段时间,大语言模型(LLM)火了起来,而这一现象和趋势也给许多AI创业者或智能产品的从业者们带来了更多思考。比如本文作者便曾经在几年前尝试过智能写作产品研发,在大语言模型火了之后,他对语言模型、对先前的创业项目又有了新的思考,一起来看。

2019年,我们在做智能写作的时候,面临的最大的挑战就是AI给的数据效果和预期偏差太远。特别是做扩写的时候,发现生成的文字很容易跑偏。
当时,我们做了很多算法和模型研究。几乎爬取了全网的自媒体文章,然后训练一批模型,问题依然很多。因为中文博大精深各种修辞手法和阴阳怪气,再加上随着时代的发展,特殊词的用法也如雨后春笋一般涌现,如何让AI能跟上人类语言的理解能力是个让人头痛的问题。
当时我们也训练了不少语言模型,发现它根本无法弄懂词的含义,无法理解“心灵鸡汤”和“鸡汤”是完全两码事,写出了“老鼠爱喝心灵鸡汤”的令人啼笑皆非的错误;另外,很容易跑偏,从“心灵鸡汤”跑偏到“老鼠喝汤”再跑偏到“动物世界”,一口气扩写出几百个字,能跑偏到十万八千里,让人完全摸不着头脑。
在试了很多方案之后,我们得到了一个结论:机器无法真正理解人类的语言。然后,我们悄悄把“扩写”放到了“实验室”的板块,放弃了文本生成的持续研发。
AI生成文字这条路到底通不通?到2023年,在没有体验ChatGPT之前,我还是持保留态度,但是体验之后,我忍不住惊呼:“这三四年的时间到底发生了什么?”
我和大家一样,重新补起了功课……
一、什么是语言模型?
语言模型(Language Model)是一种机器学习算法,它可以根据给定文本来预测下一个词语或字符的出现的概率。
语言模型通过大量的文本数据来学习语言的统计特征,进而生成具有相似统计特征的新文本。其核心目标是建立一个统计模型,用来估计文本序列中每个词语或字符出现的概率,从而实现语言生成、语言理解等自然语言处理任务。
比如,我们可以给一句话让ChatGPT做扩写:
我今天吃了一个___
它可能会扩写出“苹果”,“馒头”、“面包”、“汉堡”。根据大量的文本统计,这些词出现频率大致如下图:
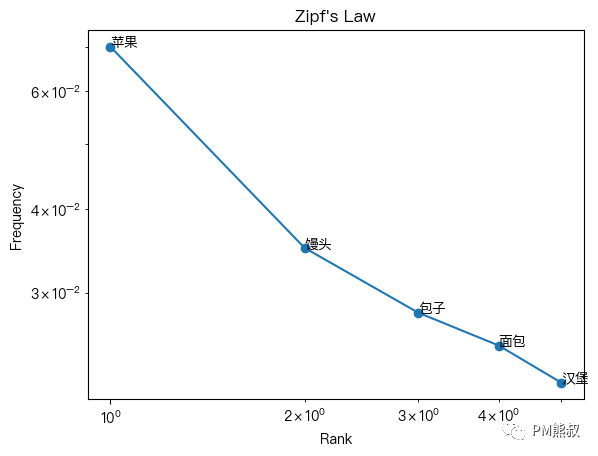
苹果为0.07,馒头为0.035,面包为0.025,汉堡为0.022。
因为”苹果“出现得比较多,ChatGPT大概率会写出”今天我吃了一个苹果“。但它不太可能预测出”我今天吃了一个火车”,因为”火车“不是食物,虽然语法通顺。但喂给GPT训练的语料里面基本没有人会这样造句。
正是因为GPT在训练过程中吸收了大量的人类语言数据,所以我们会觉得它的回答符合我们的逻辑。
人类区别于普通动物的最主要智慧特征可能就是强大的语言能力。语言不仅仅只是一种沟通工具,还包含着人类的思考逻辑和对世界的认知。
不管AI是否有真正的智慧,我相信只要语言模型的预测能力做到极致,就能够让人类信以为真。
二、概率从哪里来?
那么,语言模型是如何预测概率的呢?这要从200多年前的贝叶斯学派说起。
贝叶斯定理,由英国数学家贝叶斯 ( Thomas Bayes 1702-1761 ) 发明的。其主要思想就是,通过已知的知识来预测接下来要发生事情的概率。即我们通过以往的经验、分析或实验,可以推断出一些事件发生的概率。为了更好的理解,我们举个预测地震的例子。
假设有人收集了大量历史数据,我们可以发现地震和自然界的某些异常现象有某种关系,如鸡飞狗跳、老鼠上街、青蛙搬家、湖水干涸等现象,我们可以根据历史的数据事先计算好这些现象出现的概率,叫做先验概率。地震的概率可以写作P(地震),异常现象的概率可以写为P(异常现象),例如,老鼠上街的概率可以写作P(老鼠上街)。
正所谓:一切偶然背后都会有个必然。根据历史数据,我们可以算出地震和异常现象的概率关系,我们称之为条件概率。例如,在某个异常现象发生后出现地震的概率,可以写作P(地震|异常现象),先决条件写在|后面。如果是已知地震再计算异常现象的概率,也可以反过来P(异常现象|地震)。
有了这些数据,我们就可以根据观测,预测还未发生的地震了。通过观测一些现象来预测的还未发生的概率,这叫做后验概率,我们记为P(新地震|异常现象)。
例如,P(新地震|鸡飞狗跳)表示的是我们观测到鸡飞狗跳,预测可能发生地震的概率。这时我们可以用到贝叶斯公式。
后验概率=(先验概率*条件概率)/证据概率

我们把预测地震的例子迁移回语言模型。假设要预测在给定“吃”这个词之后,下一个词是“苹果”的概率,即P(苹果|吃)。
首先,语言模型学习了大量的文本数据,获得了大量的先验知识,已经知道了P(吃|苹果)、P(苹果)和P(吃)这三个概率值。其中,P(吃|苹果)表示在给定“苹果”这个词之后,出现“吃”的概率;P(苹果)表示“苹果”这个词出现的概率;P(吃)表示“吃”这个词出现的概率。
然后,我们可以根据贝叶斯定理,计算后验概率P(苹果|吃):

我们还可以通过输入法的联想词模拟整个句子的生成过程。
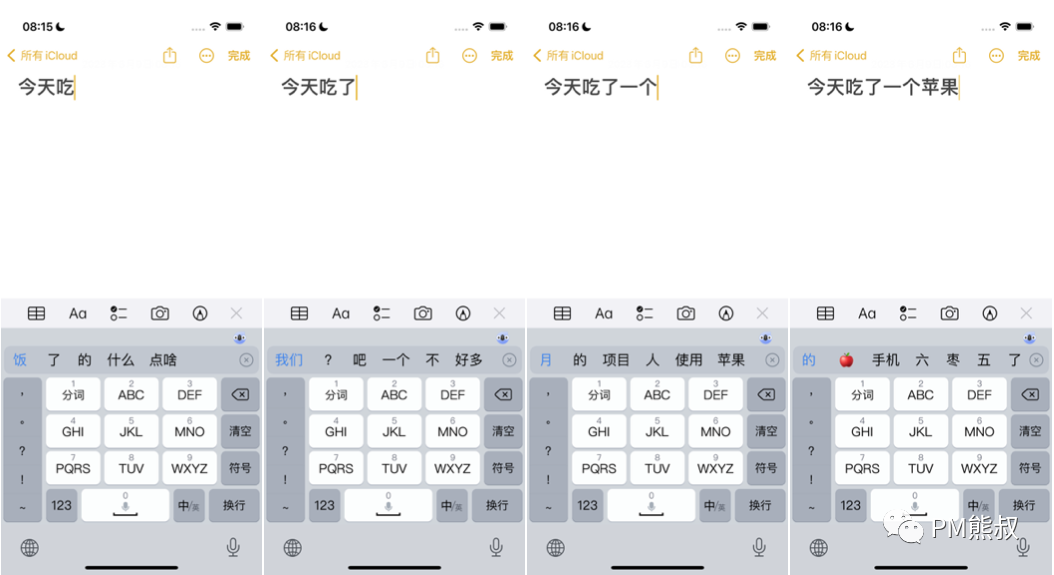
我们以“今天吃”这个词作为输入,语言模型会继续根据统计数据,计算出在“今天吃”这个词之后,各个词出现的概率。例如,它可能计算出“饭”这个词出现的概率为0.4,“了”这个词出现的概率为0.35,“的”这个词出现的概率为0.33……我们结合语境选择“了”,然后输入法刷新联想词,然后我们选择“一个”。依次重复这个过程,最终得到了“今天吃了一个苹果”的句子。
大家可能也注意到了它的问题。输入法的语言模型,只能预测上一个词和下一个词的关系,如果没有人类的主动选择就很容易跑偏,这是一个长文本预测的问题。
在2019年,我们遇到了问题是一样的。而且我们在实际应用中我们会使用更加复杂的模型,我们会用到一些RNN等深度学习的技术,让语言模型可以预测更长一点的句子。但是针对长文本依然无法解决跑偏的问题。
当时的解决方案就是一句一句的扩,让用户随时可以纠正偏差。但问题是这种扩写的意义又在哪里呢?让我对AI文本生成的信仰顿时崩塌。
三、什么是大语言模型(LLM)?
2023年,让整个人类最为振奋的AI技术就是ChatGPT。“大语言模型(Large Language Model)”这个词也随之映入人们的眼帘。ChatGPT让人觉得惊艳之处,能够结合上下文,像人一样有逻辑性地回答问题,就算生成超长的文本也不会跑偏。到底什么是大语言模型?
大语言模型与普通语言模型相比,大语言模型的一个显著区别在于其规模。大语言模型通常具有大量的参数,并且在训练过程中使用了巨量的文本数据。大型语言模型的参数规模通常与效果成正比,能够更好地理解和生成自然语言文本,更好地完成各种自然语言处理任务,如写作、翻译、问答等。
GPT优秀之处是做了前无古人的突破性的尝试,使用了巨量的参数和预训练数据。GPT-3拥有1750亿个参数,使用了45TB的文本数据进行训练。训练数据和参数量都远远超过传统的语言模型。
1. 大规模的参数有什么用?
我们要从词嵌入(Word Embedding)说起,为帮助语言模型更好地理解每个词的特征和含义, 我们需要使用大量的参数来存储和处理信息。我们会将这些词嵌入一个高维的向量空间里面,像GPT-3的向量空间的维数就有12288,这意味着GPT-3可以使用12288个维度来充分理解某个词。对于很多单词的理解可能比人类都要透彻。
语言模型还可以通过词向量空间中的位置的远近来理解词与词之间的关系。
假设我们的词向量空间有三个维度:颜色、形状和类别。我们有三个单词:“苹果”、“橘子”、“手机”,应该如何嵌入到向量空间呢?
“苹果”和“橘子”都属于水果类别,因此它们在类别维度上的值相同都是用数字“1”表示;但“苹果”的颜色是红色用数字“1”表示,而“橘子”的颜色是橙色用数字“2”表示;至于形状维度,由于“苹果”和“橘子”的形状都是圆形,都用数字“1”表示,于是有下面这个数值。

“手机”属于电子产品类别,数值用“3”表示;手机的形状是方的,数值用“2”表示;颜色是多色的,数值用“8”来表示。

他们之间的关系可以一目了然地展示在向量空间的关系中,如下图:
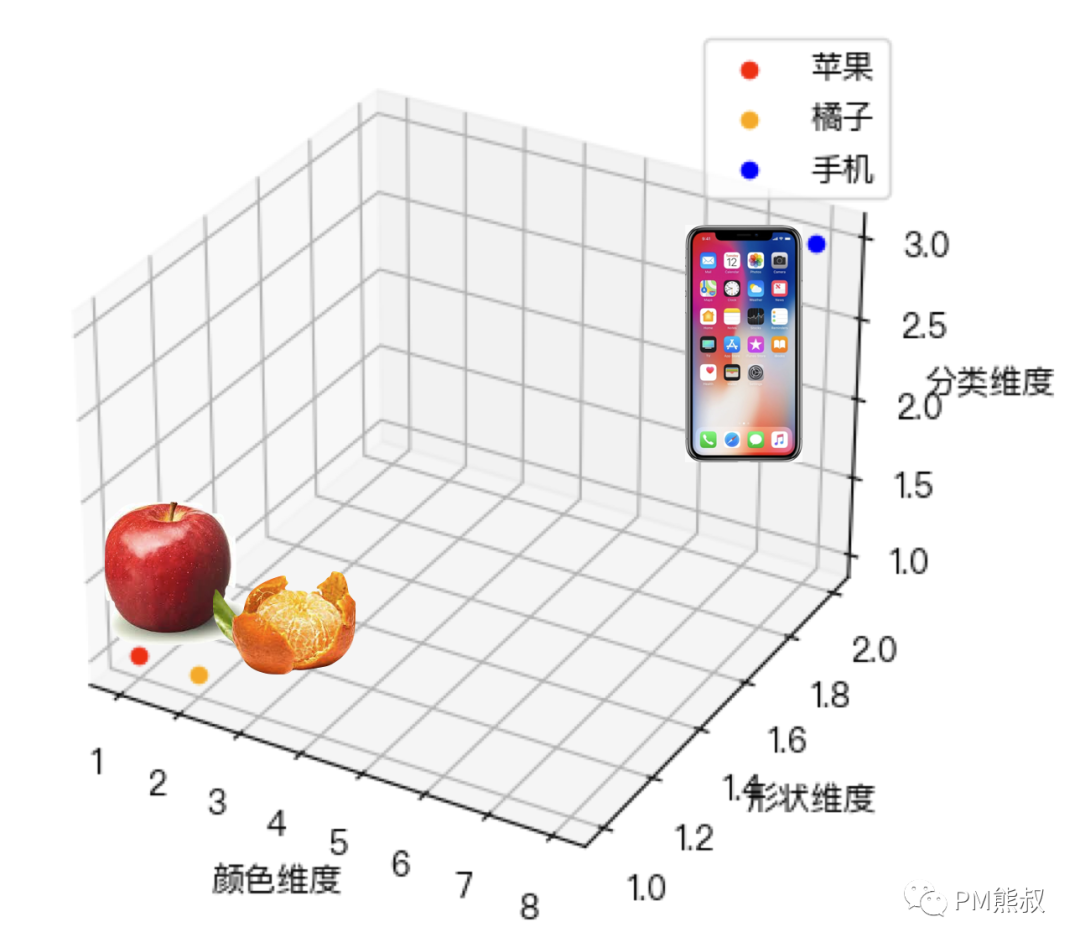
我们可以看到语义相似的单词在向量空间中彼此靠近。当GPT在生成文字的时候,它可以根据向量空间知道“苹果”和“橘子”是一类水果,在“吃”的语境中可以相互替换。

但是这也有新的问题,“苹果”也有可能是指生产手机的“苹果公司”, GPT怎么能知道“苹果”是否特指“苹果公司”呢,根据不同的语境推理出不同含义的“苹果”呢?
2019年,如何结合语境,让语言模型能够准确地理解词的含义,这在当时也是个巨大的难题。我们当时想的策略也相对简单粗暴,就是通过命名实体技术强制将它们标记为不同的实体名词,例如,“苹果手机”类别为电子产品,“苹果公司”为企业。但是遇到的问题是,我们没有办法列举完所有的命名实体,需要不断扩充新词库;另外在很多语境中“苹果”就能代表”苹果公司“和”苹果手机“,没办法根本解决这个问题。
GPT-3高明之处就是使用上下文相关的词嵌入方法和自注意力机制来解决这个问题。它的词嵌入方法考虑了单词在给定文本中使用的上下文,而自注意力机制则允许模型在生成文本时考虑前面的所有的单词。最终,让机器能更好地理解语境 ,解决词的多义性和歧义性问题。
2. 什么是注意力机制?
GPT的Transformer模型通过使用自注意力机制(Self-attention mechanism),能够让模型在处理每个单词时都能考虑到文本中所有单词的信息,从而更好地捕捉文本中的长距离依赖关系,解决了长文本的跑偏的问题。这在传统的模型中是无法做到的。
注意力机制的灵活性来自于它的“软权重”特性,即这种权重是可以在运行时改变的,可以根据上下文来推断出单词的含义,来达到更好的预测效果。
举个例子,假设我们有一个句子:“我喜欢吃苹果,但我不喜欢苹果手机。”在这个句子中,“苹果”这个词出现了两次,第一个“苹果”是指一种水果,而第二个“苹果”是指一种手机品牌。
如果是没有注意力机制的模型来处理这个句子,那么模型可能会将两次出现的“苹果”都当做水果来处理。但对于GPT来说就不一样了,它能够根据上下文来推断出每次出现的“苹果”的含义。
这主要归功于GPT包含的巨量参数中不仅仅包含了词汇的意义,还包含了词在句子中结构和语法、语言风格、语境信息等等。
注意力机制可以通过计算每个词的相似度来实现注意力权重的计算。当它处理第一个“苹果”时,会注意到前面有一个权重较高的“吃”字,因此会推断出这里的“苹果”指的是一种水果;而当模型处理第二个“苹果”时,它会注意到后面有一个权重较高的“手机”,因此会推断出这里的“苹果”指的是一种手机品牌。
我们可以简单模拟一下这个注意力权重的计算过程。
假设我们有个三维的词向量空间,我们先把“我”、“喜欢”、“吃”、“苹果”这4个词嵌入到这个空间里面:

如果绘制成图,他们在向量空间中的关系一目了然。如下图,两个词越是接近,关系就越紧密。
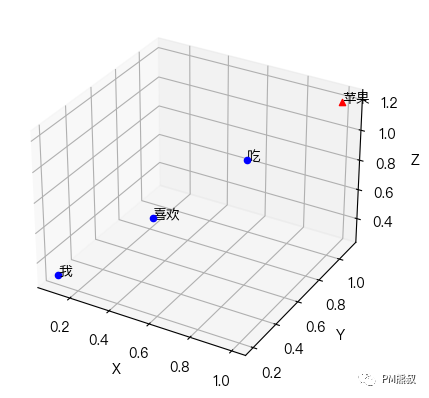
语言模型可以用数学方法来分别计算“苹果”与“我”“喜欢”“吃”三个词的权重分数,我们可以通过向量的点积计算方式模拟计算一下,值越大代表的是向量的相关性越大:

通过计算我们发现“吃”的相似度最大为2.66,那就说明“吃”这个词相对于“苹果”应该有更高的注意权重。
或许看到这里,你已经觉得自己消耗了不少的脑细胞。但似乎我们也能够理解GPT的工作量是有多么的大。因为要不断地动态的生成和预测下个词,需要消耗大量的算力。没办法一步到位,所以它只能是一个字一个字地给你呈现出来。
算力也是我们在2019年遇到的难题,因为训练模型的沉没成本很高。稍微复杂一点的模型训练可能需要几天的时间,但是你也没有办法保证预期结果。而且,在模型训练好之后,用户还需要长时间的等待计算结果,导致体验非常糟糕。对于一个争分夺秒的创业团队来说,显然有些不切实际。
所以我们当时思路是尽可能把模型做多做小,按照不同的文章分类进行训练,想通过这种方式平衡时间和效果,但效果依然不尽人意。从今天的结果来看,没有通用的大语言模型作为基座,把模型做小做细基本就是一条不归路。最终,我们放弃了文本生成算法的持续研发。
GPT的成功之处,不仅仅是技术的成功,也是在商业上面的成功。有了微软的算力加持,可以更好的保证模型训练和服务体验,才能在普通的用户人群获得巨大的反响。
今天,在ChatGPT闪耀的光环之下,我们看到OpenAI的CEO 山姆·奥特曼(Sam Altman) 风光无限,我在短视频平台经常能刷到他的精彩演讲语录,我也总是希望能够从他的成功经历上学到点什么。
如果有一天,我拿着2023年的大语言模型的论文,穿越回了2019年,重新开始智能写作的项目,我会做得更好吗?其实,我依然觉得很难,因为创业需要“天时地利人和”。
先不提OpenAI所在的土壤对于创新极其的开放,它吸纳了全球最顶尖的人才,并获得了资本的鼎力支持。光是能够看清未来的方向,并且能够坚定不移地走下去,也是我们大多数创业团队无法企及的高度。
对于一个创业者来说,看见未来很重要,但认清自己也很重要。看见未来,你才能坚定不移地走下去;认清自己,你才能力所能及地把事情做得更好。在没有能力之前,需要先学会成长;在机遇没有到来之前,需要先学会等待;在没有成功之前,也要学会选择坚持。
现在ChatGPT的热度之下,又有一些朋友重新投入到AI创业的大潮中。雷军说过:“站在风口,猪也能被吹上天”。但是风很大,浪也会很急,挑战也会很多。希望各位创业者能够一帆风顺。
专栏作家
PM熊叔,微信公众号:PM熊叔,人人都是产品经理专栏作家。教育类产品产品经理出身,学过设计,做过开发,做过运营的产品经理。
本文原创发布于人人都是产品经理。未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。
更多精彩内容,请关注人人都是产品经理微信公众号或下载App

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK