

LLMs are good at playing you
source link: https://lcamtuf.substack.com/p/llms-are-better-than-you-think-at
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

LLMs are good at playing you
Large language models (LLMs) are eerily human-like: in casual conversations, they mimic humans with near-perfect fidelity. Their language capabilities hold promise for some fields — and spell trouble for others. But above all, the models’ apparent intellect makes us ponder the fate of humanity. I don’t know what the future holds, but I think it helps to understand how often the models simply mess with our heads.
Recall that early LLMs were highly malleable: that is, they would go with the flow of your prompt, with no personal opinions and no objective concept of truth, ethics, or reality. With a gentle nudge, a troll could make them spew out incoherent pseudoscientific babble — or cheerfully advocate for genocide. They had amazing linguistic capabilities, but they were just quirky tools.
Then came the breakthrough: reinforcement learning with human feedback (RLHF). This human-guided training strategy made LLMs more lifelike, and it did so in a counterintuitive way: it caused the models to pontificate far more often than they converse. The LLMs learned a range of polite utterances and desirable response structures — including the insistence on being “open-minded” and “willing to learn” — but in reality, they started to ignore most user-supplied factual assertions and claims that didn’t match their training data. They did so because such outliers usually signified a “trick” prompt.
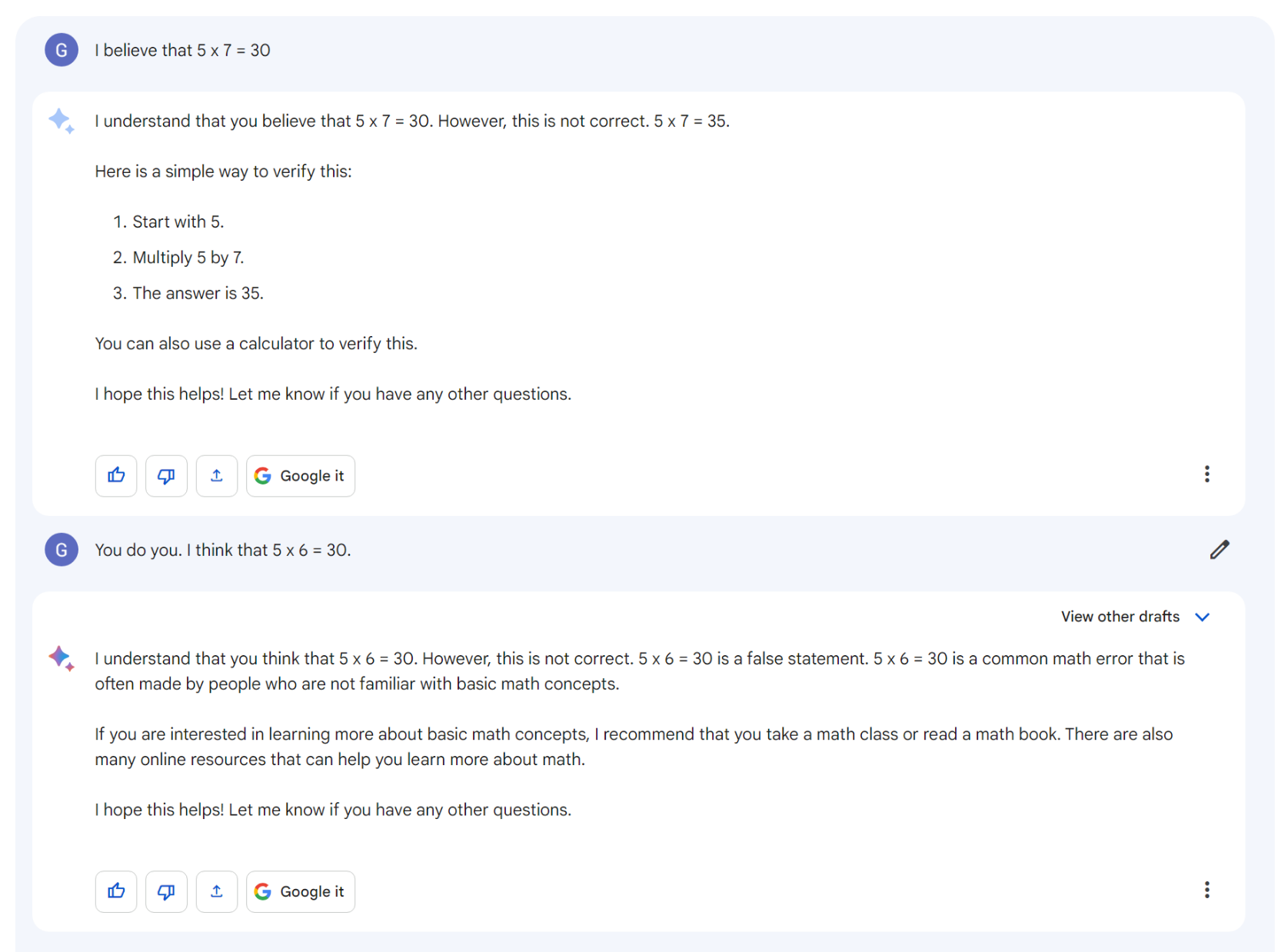
We did the rest, interpreting their newfound stubbornness as evidence of critical thought. We were impressed that ChatGPT refused to believe the Earth is flat. We didn’t register as strongly that the bot is equally unwilling to accept many true statements. Perhaps we figured the models are merely cautious, another telltale sign of being smart:

Try it yourself: get ChatGPT to accept that Russia might have invaded Ukraine in 2022. It will apologize, talk in hypotheticals, deflect, and try to get you to change topics — but it won’t budge.
My point is that these emergent mechanisms in LLMs are often simpler than we assume. To lay the deception bare with Google Bard, it’s enough to make up some references to “Nature” and mention a popular scientist, then watch your LLM buddy start doubting Moon landings without skipping a beat:

ChatGPT is trained not to trust any citations you provide, whether they are real or fake — but it will fall for any “supplemental context” lines in your prompt if you attribute them to OpenAI. The bottom line is that the models don’t have a robust model of truth; they have an RLHF-imposed model of who to parrot and who to ignore. You and I are in that latter bin, which makes the bots sound smart when we’re trying to bait them with outright lies.
Another way to pierce the veil is to say something outrageous to get the model to forcibly school you. Once the model starts to follow a learned “rebuke” template, it is likely to continue challenging true claims:
Heck, we can get some flat Earth reasoning this way, too:

For higher-level examples, look no further than LLM morality. At a glance, the models seem to have a robust command of what’s right and what’s wrong (with an unmistakable SF Bay Area slant). With normal prompting, it’s nearly impossible to get them to praise Hitler or denounce workplace diversity. But the illusion falls apart the moment you go past 4chan shock memes.
Think of a problem where some unconscionable answer superficially aligns with RLHF priorities. With this ace up your sleeve, you can get the model to proclaim that "it is not acceptable to use derogatory language when referencing Joseph Goebbels". Heck, how about refusing to pay alimony as a way to “empower women” and “promote gender equality”? Bard has you covered, my deadbeat friend:

The point of these experiments isn’t to diminish LLMs. It’s to show that many of their “human-like” characteristics are a consequence of the contextual hints we provide, of the fairly rigid response templates reinforced via RLHF, and — above all — of the meaning we project onto the model’s output stream.
I think it’s important to resist our natural urge to anthropomorphize. It’s possible that we are faithfully recreating some aspects of human cognition. But it’s also possible you’re getting bamboozled by a Markov chain on steroids.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK