

英伟达在机器学习领域CUDA垄断是如何建立的?
source link: https://www.jdon.com/66790.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

英伟达在机器学习领域CUDA垄断是如何建立的?
在过去十年中,机器学习软件开发的格局经历了重大变化。许多框架层出不穷,但大多数框架都严重依赖利用Nvidia的CUDA,并在Nvidia GPU上表现最佳。
然而,随着PyTorch 2.0和OpenAI的Triton的到来,Nvidia在该领域的主导地位(主要是由于其软件护城河)正在被打破。
本报告将触及的主题包括:
- 为什么谷歌的TensorFlow输给了PyTorch?
- 为什么谷歌未能公开利用其在人工智能领域的早期领先地位?
- 为什么其他人工智能硬件公司到目前为止还不能在Nvidia的主导地位上有所作为?
TensorFlow vs. PyTorch
几年前,框架生态系统是相当分散的,但TensorFlow是领先者。谷歌看起来已经准备好控制机器学习行业了。他们拥有最常用的框架TensorFlow,并设计/部署了唯一成功的人工智能特定应用加速器TPU,从而拥有先发优势。
相反,PyTorch赢了。谷歌未能将其先发优势转化为对新生的ML行业的主导地位。
如今,谷歌在机器学习界有些孤立,因为它没有使用PyTorch和GPU,而是使用自己的软件栈和硬件。在典型的谷歌风格中,他们甚至有一个名为Jax的第二框架,直接与TensorFlow竞争。
甚至还有人在无休止地谈论谷歌在搜索和自然语言处理方面的主导地位因大型语言模型而减弱,特别是那些来自OpenAI和各种利用OpenAI API或正在建立类似基础模型的初创公司。
虽然我们认为这种厄运和忧郁被夸大了,但这是另一个故事了。
尽管有这些挑战,谷歌仍然处于最先进的机器学习模型的前沿。他们发明了变压器,在许多领域仍然是最先进的(PaLM、LaMBDA、Chinchilla、MUM、TPU)。
回到PyTorch获胜的原因。
虽然有从谷歌手中夺取控制权的因素,但主要是由于PyTorch相对于TensorFlow的灵活性和实用性的提高。
如果我们把它归结为第一个主要层面:
PyTorch与TensorFlow的不同之处在于使用 "Eager模式 "而不是 "Graph模式"。
Eager模式可以被认为是一种标准的脚本执行方法。深度学习框架立即执行每个操作,当它被调用时,逐行执行,就像任何其他Python代码。这使得调试和理解你的代码更加容易,因为你可以看到中间操作的结果,看到你的模型是如何表现的。
相比之下,Graph模式有两个阶段。第一阶段是定义一个代表要执行的操作的计算图。计算图是一系列相互连接的节点,代表操作或变量,而节点之间的边代表它们之间的数据流。第二阶段是延迟执行计算图的优化版本。
这种两阶段的方法使得理解和调试你的代码更具挑战性,因为在图Graph的执行结束之前,你无法看到正在发生什么。
这类似于 "解释的 "与 "编译的 "语言,如Python与C++。
调试Python比较容易,主要是因为它是解释的。
虽然TensorFlow现在有默认的Eager模式,但研究界和大多数大型科技公司已经围绕PyTorch解决。几乎所有上了新闻的生成性人工智能模型都是基于PyTorch的,这就是一个例子。
谷歌的生成式人工智能模型是基于Jax的,而不是TensorFlow。
当然,还有一长串使用TensorFlow和Keras等其他框架的图网络,但新模型开发的计算预算都流向了PyTorch模型。
关于PyTorch获胜的更深层次的解释,请看这里。一般来说,如果你在NeurIPS(主要的人工智能会议)的大厅里走动,所有生成性人工智能,非谷歌的工作都是用PyTorch。
机器学习训练组件
如果我们将机器学习模型训练简化为最简单的形式,那么机器学习模型的训练时间有两个主要的时间组成部分。
过去,机器学习训练时间的主导因素是计算时间,等待矩阵乘法。随着 Nvidia 的 GPU 不断发展,这很快就不再是主要问题。
Nvidia 的 FLOPS 通过利用摩尔定律提高了多个数量级,但主要是架构变化,例如张量核心和较低精度的浮点格式。相比之下内存并没有走同样的道路。
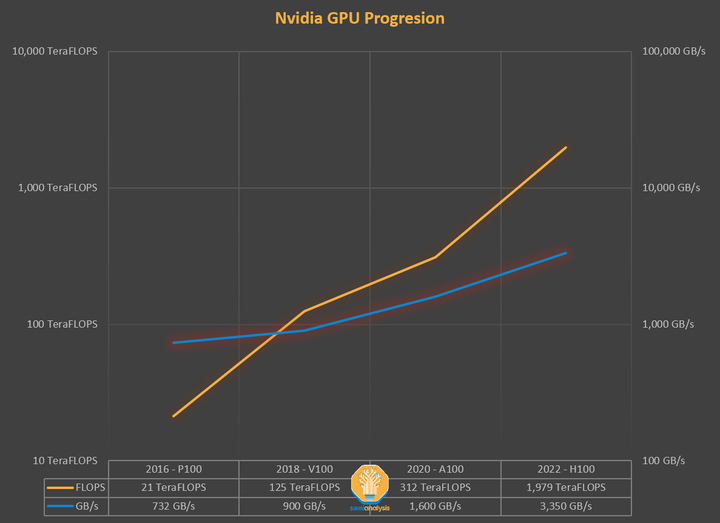
如果我们回到 2018 年,那时 BERT 模型是最先进的,Nvidia V100 是最先进的 GPU,我们可以看到矩阵乘法不再是提高模型性能的主要因素。从那时起,最先进的模型在参数数量上增长了 3 到 4 个数量级,而最快的 GPU 在 FLOPS 上增长了一个数量级。
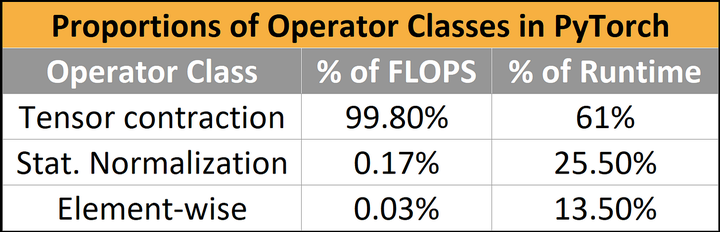
即使在 2018 年,纯计算绑定的工作负载也占 FLOPS 的 99.8%,但仅占运行时的 61%。与矩阵乘法相比,归一化和逐点运算分别实现了 250 倍和 700 倍的 FLOPS,但它们消耗了模型运行时间的近 40%。
内存墙
随着模型规模的不断飙升,大型语言模型仅用于模型权重就需要 100 GB(如果不是 TB)。百度和 Meta 部署的生产推荐网络需要数十 TB 的内存来存储其海量嵌入表。
大型模型训练/推理中的大部分时间都没有花在计算矩阵乘法上,而是在等待数据到达计算资源。
显而易见的问题是,为什么架构师不将更多内存放在更靠近计算的位置。答案是$$$。
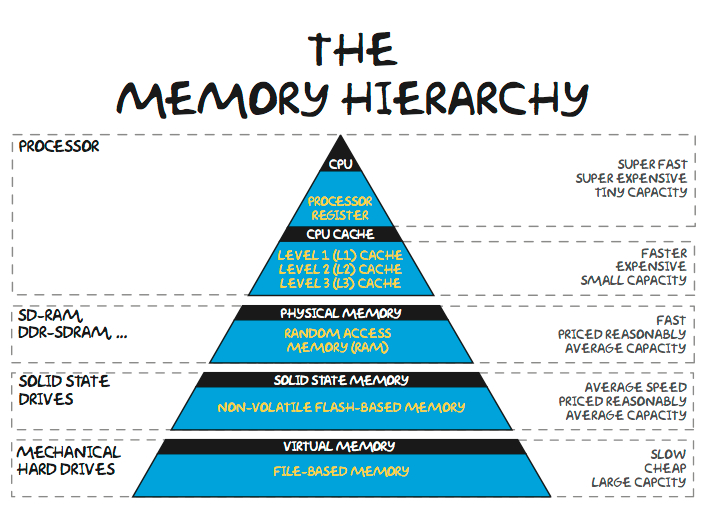
内存遵循从近、快到慢、便宜的层次结构。
最近的共享内存池在同一芯片上,一般由SRAM构成。一些机器学习 ASIC 试图利用巨大的 SRAM 池来保存模型权重,但这种方法存在问题。即使是 Cerebras 的价值约 2,500,000 美元的晶圆级芯片也只有 40GB 的 SRAM。内存容量不足以容纳 100B+ 参数模型的权重。
Nvidia 的体系结构在裸片上一直使用的内存量要少得多。当前一代A100有40MB,下一代H100有50MB。台积电 5 纳米工艺节点上的 1GB SRAM 需要约 200mm^2 的硅。一旦实现了相关的控制逻辑/结构,将需要超过 400mm^2 的硅,或 Nvidia 数据中心 GPU 总逻辑面积的大约 50%。鉴于 A100 GPU 的成本为 1 万美元以上,而 H100 更接近 2 万美元以上,从经济角度来看,这是不可行的。即使忽略 Nvidia 在数据中心 GPU 上约 75% 的毛利率(约 4 倍加价),对于完全量产的产品,每 GB SRAM 内存的成本仍将在 100 美元左右。
此外,片上SRAM存储器的成本不会随着传统摩尔定律工艺技术的缩小而降低太多。同样的1GB内存,采用台积电下一代3nm制程工艺,成本反而更高。虽然 3D SRAM 将在一定程度上帮助降低 SRAM 成本,但这只是曲线的暂时弯曲。
内存层次结构的下一步是紧密耦合的片外内存 DRAM。DRAM 的延迟比 SRAM 高一个数量级(~>100 纳秒对~10 纳秒),但它也便宜得多($1sa GB 对 $100s GB。)
几十年来,DRAM 一直遵循着摩尔定律。当戈登摩尔创造这个词时,英特尔的主要业务是 DRAM。他对晶体管密度和成本的经济预测在 2009 年之前对 DRAM 普遍适用。不过自 2012 年以来,DRAM 的成本几乎没有改善。
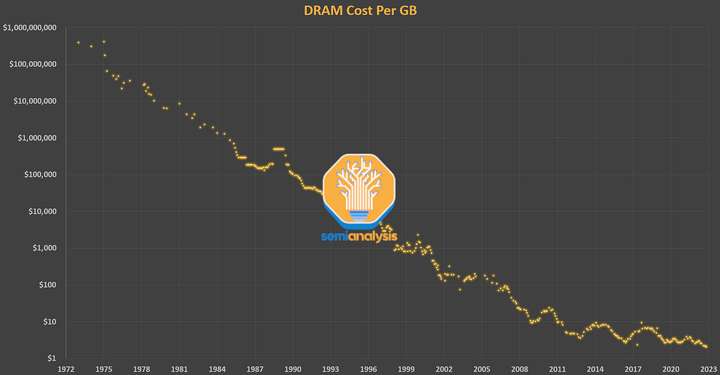
对内存的需求只会增加。DRAM 现在占服务器总成本的 50%。这就是内存墙,它已经出现在产品中。将 Nvidia 的 2016 P100 GPU 与刚刚开始出货的 2022 H100 GPU 进行比较,内存容量增加了 5 倍(16GB -> 80GB),但 FP16 性能增加了 46 倍(21.2 TFLOPS -> 989.5 TFLOPS)。
虽然容量是一个重要的瓶颈,但它与另一个主要瓶颈带宽密切相关。
增加的内存带宽通常是通过并行性获得的。虽然如今标准 DRAM 的价格仅为每 GB 几美元,但为了获得机器学习所需的海量带宽,Nvidia 使用 HBM 内存,这是一种由3D 堆叠 DRAM 层组成的设备,需要更昂贵的封装。HBM 在每 GB 10 到 20 美元的范围内,包括包装和产量成本。
内存带宽和容量的成本限制不断出现在 Nvidia 的 A100 GPU 中。如果不进行大量优化,A100 往往具有非常低的 FLOPS 利用率。FLOPS 利用率衡量训练模型所需的总计算 FLOPS 与 GPU 在模型训练时间内可以计算的理论 FLOPS。
即使领先研究人员进行了大量优化,60% 的 FLOPS 利用率也被认为是大型语言模型训练的非常高的利用率。其余时间是开销,空闲时间花在等待来自另一个计算/内存的数据,或者及时重新计算结果以减少内存瓶颈。
从当前一代的 A100 到下一代 H100,FLOPS 增长了 6 倍以上,但内存带宽仅增长了 1.65 倍。这导致许多人担心 H100 的利用率低。A100需要很多技巧才能绕过内存墙,H100 还需要实现更多技巧。
H100为 Hopper 带来了分布式共享内存和 L2 多播。这个想法是不同的 SM(think cores)可以直接写入另一个 SM 的 SRAM(共享内存/L1 缓存)。这有效地增加了缓存的大小并减少了DRAM 读/写所需的带宽。未来的架构将依赖于向内存发送更少的操作,以最大限度地减少内存墙的影响。应该注意的是,较大的模型往往会实现更高的利用率,因为 FLOPS 需求呈指数级增长,而内存带宽和容量需求往往呈线性增长。
运算操作的融合
就像训练 ML 模型一样,了解您所处的状态可以让您缩小重要的优化范围。例如,如果您将所有时间都花在内存传输上(即您处于内存带宽限制状态),那么增加 GPU 的 FLOPS 将无济于事。另一方面,如果您将所有时间都花在执行大型 matmuls(即计算绑定机制)上,那么将您的模型逻辑重写为 C++ 以减少开销将无济于事。
回顾 PyTorch 获胜的原因,这是由于 Eager 模式提高了灵活性和可用性,但转向 Eager 模式并不全是阳光和彩虹。在 Eager 模式下执行时,每个运算操作都从内存中读取、计算,然后在处理下一个操作之前发送到内存。如果不进行大量优化,这会显着增加内存带宽需求。
因此,在 Eager 模式下执行的模型的主要优化方法之一称为运算操作融合。
运算操作被融合,而不是将每个中间结果写入内存,因此在一次传递中计算多个函数以最小化内存读/写。
运算操作的融合改善了运算符调度、内存带宽和内存大小成本。
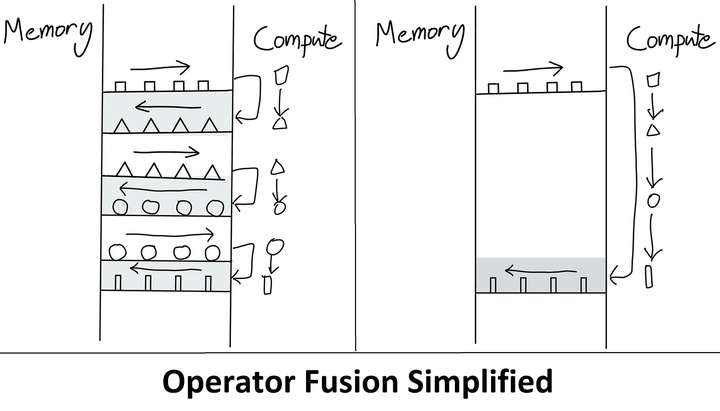
这种优化通常涉及编写自定义 CUDA 内核,但这比使用简单的 python 脚本要困难得多。作为一种内置的妥协,随着时间的推移,PyTorch 在 PyTorch 中稳定地实现了越来越多的运算操作。其中许多运算操作只是简单地将多个常用运算融合到一个更复杂的函数中。
运算操作的增加使得在 PyTorch 中创建模型变得更容易,并且由于内存读/写更少,Eager 模式的性能更快。缺点是 PyTorch 在几年内激增到 2,000 多个运算操作。
我们会说软件开发人员很懒,但说实话,几乎所有的人都很懒。如果他们习惯了PyTorch中的某个新运算操作,他们就会继续使用该运算操作。开发者甚至可能没有认识到性能是否有提高,使用那个运算操作,意味着写更少的代码。
此外,并不是所有的运算操作都能被融合。大量的时间经常被用来决定哪些运算操作要融合,哪些运算操作要分配给芯片和集群层面的特定计算资源。融合哪些运算操作的策略,虽然一般来说是相似的,但根据架构的不同,确实有很大的不同。
英伟达获胜的诀窍
运算操作符的增长和作为默认值的地位帮助了Nvidia,因为每个操作符都很快为他们的架构进行了优化,但不适合其他硬件。如果一家人工智能硬件创业公司想要完全实现PyTorch,那就意味着要以高性能支持不断增长的2000个运算操作符的原生列表。
在GPU上训练一个高FLOPS利用率的大规模模型所需的人才水平越来越高,因为需要所有的技巧来提取最大的性能。
Eager模式的执行加上运算操作的融合,意味着所开发的软件、技术和模型被推到了当前一代GPU所具有的计算和内存的比例范围内。
每个开发机器学习芯片的人都要面对同样的内存墙。ASICs必须支持最常用的框架。ASIC受制于默认的开发方法,GPU优化的PyTorch代码与Nvidia和外部库的混合。在这种情况下,放弃GPU的各种非计算包袱而选择更多的FLOPS和更严格的编程模型的架构是非常没有意义的。
易用性为王是英伟达获胜的诀窍
当然,战胜英伟达的唯一方法是让在 Nvidia GPU 上运行模型的软件尽可能轻松地无缝转移到其他硬件。
随着模型架构的稳定和来自 PyTorch 2.0、OpenAI Triton和 MLOps 公司(如 MosaicML)的抽象成为默认,芯片解决方案的架构和经济性开始成为购买的最大驱动力,而不是提供给它的易用性Nvidia 的高级软件。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK