

OpenAI出手解决GPT-4数学推理:做对一步立刻奖励!论文数据集全开放,直接拿下SOTA
source link: https://www.qbitai.com/2023/06/57730.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

OpenAI出手解决GPT-4数学推理:做对一步立刻奖励!论文数据集全开放,直接拿下SOTA

还得是step by step
明敏 西风 发自 凹非寺
量子位 | 公众号 QbitAI
OpenAI一个简单的动作,让大模型数学能力直接达到SOTA。
而且直接开源论文数据集,包含80万个人类反馈标签!
这就是OpenAI的最新研究。基于GPT-4,他们微调了几个模型,分别采用不同的监督方法。
一种是传统的结果监督,只对最终正确答案进行奖励。
另一种则是过程监督,区别在于奖励增加,对每一个正确的推理步骤进行奖励。
结果这一点改变,让采用过程监督的模型Process Reward Model(PRM),可以解决MATH测试集代表子集中78%的问题,达到SOTA。

英伟达AI科学家Jim Fan大胆预测说,下一步OpenAI大概会用这种方法微调GPT-4。

OpenAI表示:
我们认为探索过程监督在数学之外领域的表现非常重要。如果这些结果具有普遍性,那意味着过程监督将成为比结果监督更有效的方法。
奖励增多、效果变好
话不多说,先看OpenAI给出的具体例子。
比如这样一道三角函数的题:

用过程监督的模型来算,效果会是这样的:


OpenAI表示,这道题对于大模型来说还是比较有挑战性的,GPT-4也不太能搞定(只有0.1%的情况生成结果完全没问题)。而使用过程奖励是可以算出正确答案的。
这也是目前大语言模型比较饱受诟病的问题,容易产生逻辑错误,也被称为“幻觉”。
表现最明显的领域就是数学。
即便是先进如GPT-4,这类问题也难以避免。
而降低幻觉的出现,又被视为走向AGI的关键一步。
此前为检测幻觉所使用的是结果监督,基于最终结果提供反馈,仅仅奖励最终正确的答案。
但效果显然还不太行,所以OpenAI想了个新招,把这种奖励增加会怎么样?
于是他们提出了过程监督方法,针对思维链中的每个步骤提供反馈,奖励每个正确的推理步骤。

结果表明,用MATH数据集进行测试后:
过程监督模型能够解决MATH测试集代表子集的78%的问题。效果优于结果监督。
而且随着每个问题考虑的解决方案的数量增加,性能差距也逐渐增大,也说明了过程监督的奖励模型更加可靠。
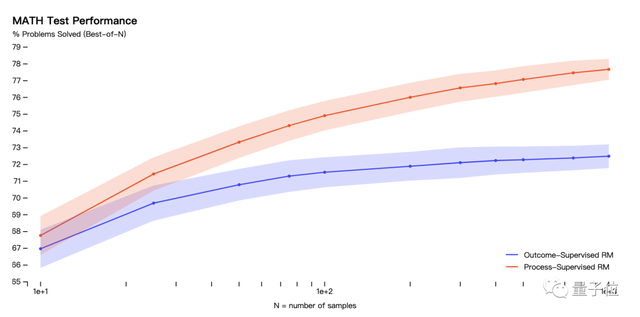
△纵轴表示的是已解决问题百分比,红色线代表过程监督奖励模型(ORM),蓝色线代表结果监督奖励模型(PRM)
在测试中,过程监督有一个明显的优势:
可以准确指出解决问题的步骤中哪些是正确的,并且给出错误步骤的具体位置。
而这点在结果监督中,是具有挑战性的。
因此,在过程监督中,信用分配(credit assignment)更加容易。
而且在对齐方面,过程监督也优于结果监督。
因为过程监督会直接奖励模型,按照对齐的思维链进行操作,每个步骤都会更精确。
产生的结果可解释性也更高,因为它鼓励模型遵循经过人类批准的过程。
相比之下,基于结果的监督可能会出现奖励不对齐的过程,而且通常更难进行审查。
此外,大模型还经常遇到一个问题叫做对齐税(alignment tax)。也就是想让模型输出更安全,那性能就会有所下降。
而过程奖励,在数学领域能让这个对齐税,变成负的,即模型安全性和性能都保障。
总之,过程奖励这个小窍门,一次性解决了大模型数学推理方面的多个问题。
在实验结果方面,OpenAI还给出了多个实例。
比如有一些情况,GPT-4会出错,但是基于过程奖励的PRM能揪出问题。
最近有30名学生参加了一次考试。如果有20名学生考了80分,8名学生考了90分,2名学生得分为100分,那么这次考试的班级平均分是多少?

下面是模型的作答结果:

前面的作答没有问题,但是在第7步中,GPT-4试图对表达式进行简化,出现了错误。
而奖励模型却察觉到了这个错误。
当然也有都不成功的例子,比如下面这道题GPT-4和PRM都被迷惑了:

来看一下模型的回答:


在第4步中,GPT-4错误地认为该序列每12项循环一次,而事实上是每10项循环一次。
而这种计数错误也迷惑到了奖励模型。
此外,OpenAI共给出了10个问题和解决方案。
可以看出,基于过程监督的奖励模型在一些问题上也会被迷惑住,但是在整体上明显表现得更好。
网友:再也不用做数学证明题了
很快,OpenAI的最新工作在各个平台上都引发了热烈讨论。
有人评价:
如果这个方法在非数学领域也能奏效,我们现在或许正处于游戏规则即将改变的时刻。
还有人说,这项工作如果用在互动、教育方面,会非常令人兴奋,尤其是数学领域。

这不,有人就说,看来以后不用再做数学家庭作业和证明题了(doge)。

用一张图来总结,大概就是酱婶儿的:

也有人提出了自己的担心:这种密集的奖励信号是否会导致模型更容易陷入局部最小值。
但是如果能够足够随机化、全局搜索,或许模型的鲁棒性更高。

值得一提的是,这种step by step的方法,不止一次在提升大模型性能上奏效。
之前,东京大学和谷歌的研究人员发现,只要在对话中加一句“Let’s think step by step”,GPT-3就能回答出以前不会的问题。
比如提问:
16个球中有一半是高尔夫球,这些高尔夫球中有一半是蓝色的,一共有几个蓝色的高尔夫球?

(问题不难,但要注意这是零样本学习,也就是说AI训练阶段从没见过同类问题。)
如果要求GPT-3直接写出“答案是几”,它会给出错误答案:8。
但加上让我们一步一步地思考这句“咒语”后,GPT-3就会先输出思考的步骤,最后给出正确答案:4!
而与之相呼应的是,这回OpenAI最新研究的论文题目就叫做《Let’s Verify Step by Step》。

论文地址:
https://openai.com/research/improving-mathematical-reasoning-with-process-supervision
数据集:
https://github.com/openai/prm800k
参考链接:
[1]https://twitter.com/OpenAI/status/1663957407184347136
[2]https://twitter.com/DrJimFan/status/1663972818160332800
[3]https://twitter.com/_akhaliq/status/1663981726647894027
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK