

分布式缓存综合指南
source link: https://www.jdon.com/66571.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

分布式缓存综合指南
一个重要的网站需要一个网络服务器来接收请求和一个数据库来写入或读取数据。但是,如果每秒收到数百万个请求,这种简单的设置只有在优化数据库或更改整体数据库策略后才能扩展。那是对的吗?数据库最终达到了活动连接数的限制,并且难以管理并发请求。
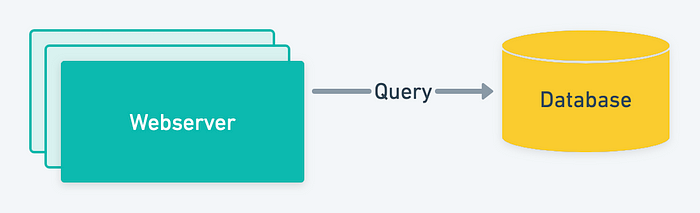
在寻求提高系统的可伸缩性时要考虑的一种解决方案是缓存。缓存是一种广泛使用的技术,可以在许多不同的领域找到,包括 Web 应用程序、数据库、媒体流、电子商务、游戏、云计算和移动应用程序。
在深入研究缓存之前,首先必须了解它相对于单独使用传统数据库的优势。缓存可以提供单独的数据库可能无法提供的几个好处:
- 速度:缓存可以通过将经常访问的数据存储在内存中来显着提高应用程序的速度,访问速度比存储在磁盘上的数据快得多。
- 可扩展性:缓存可以通过将负载分布到多个可以处理许多请求的缓存服务器来帮助扩展应用程序。
- 减轻数据库的负载:缓存可以通过将频繁访问的数据存储在内存中来减轻负载,从而减少对数据库的请求次数。
- 提高可用性:缓存可以通过在数据库变得不可用时提供经常访问的数据的备份来帮助提高应用程序的可用性。
- 成本:缓存可以通过减少对数据库的请求数量来降低成本,这有助于减少对昂贵的数据库资源(如 CPU、内存和存储)的需求。
- 数据一致性:缓存可以通过存储最新的数据并确保数据始终是最新的来提高一致性。
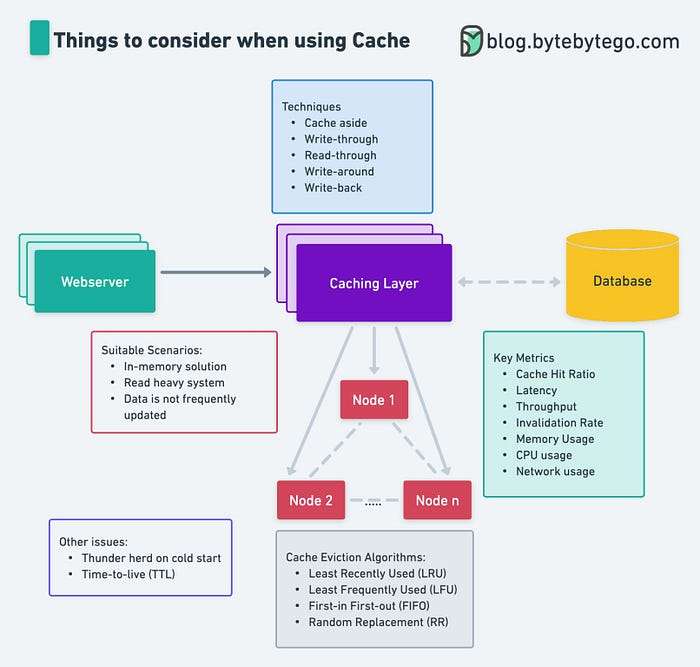
缓存策略
让我们看看可用的缓存解决方案并确定哪一个最符合我们的要求。在大规模应用程序中缓存可能是一项具有挑战性的任务。以下是一些可用于在大规模应用程序中进行缓存的策略:
- 内存缓存:内存缓存将缓存数据存储在内存中,从而加快访问速度。此策略有助于处理大量读取操作的大规模应用程序。
- 缓存分片:缓存分片是一种将大缓存分成较小分区的技术,这些分区可以存储在不同的服务器上。这有助于分配负载并降低单点故障的风险。每个分片负责由特定键访问的数据的特定子集。
- 分布式缓存:分布式缓存允许您跨多个服务器缓存数据,这有助于减少任何一台服务器上的负载并提高系统的整体性能。分布式缓存系统可以进一步分为复制缓存和分区缓存。复制缓存将数据的副本存储在多个服务器上,而分区缓存将数据分成更小的块并将它们存储在不同的服务器上。
- 内容分发网络 (CDN):CDN 是分布在全球的服务器。他们可以根据地理位置缓存和交付用户内容。
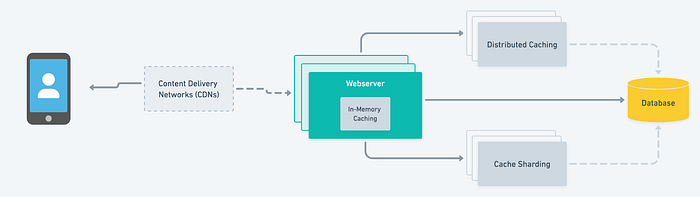
在谈到缓存时,一定要注意策略的选择将取决于应用程序的独特需求和要求。测试各种场景并确定最适合特定用例的方案是有益的。对于数据一致性不是主要问题的大规模应用程序,混合方法(例如将内存缓存与分布式缓存或缓存分片相结合)也可能是必需的。总的来说,缓存策略应该根据应用程序的特定需求进行调整。
本文将重点介绍分布式缓存,但所讨论的概念也可以应用于其他领域。
分布式缓存
分布式缓存是一种允许您跨多个服务器而不是单个服务器缓存数据的技术。这可以减少任何服务器上的负载并提高系统的整体性能。
几个关键组件组成了分布式缓存系统:
- 缓存节点是存储和管理缓存数据的服务器。它们可以配置为集群或网格,并相互通信以保持缓存数据的一致性。
- 缓存客户端是与缓存节点交互以读取和写入数据的应用程序或服务。
- 负载均衡器:该组件在缓存节点之间分配负载。它可以配置为使用各种算法,例如循环法、最少连接数或 IP 散列。
这些组件提供高可用性、可伸缩性和系统性能。
一位智者说:
计算机科学中只有两件难事:缓存失效和命名事物。 ——菲尔·卡尔顿
缓存失效策略
缓存失效是从缓存中删除陈旧或过时数据的过程。这是缓存的一个重要方面,因为它确保缓存中的数据是最新的并且与源数据一致。
现在我们了解了缓存失效的重要性,让我们关注此过程中使用的一个关键指标:生存时间 (TTL)。每个缓存项都分配有时间戳和 TTL 值。一旦 TTL 到期,相应的项目将自动从缓存中删除。
我们如何从缓存中删除该项目?可以使用几种缓存逐出策略来提高系统的性能,包括:
- 先进先出(FIFO):当需要添加新条目时,此策略会删除缓存中最旧的条目。
- Least Recently Used (LRU):该策略删除缓存中时间最长但未被访问的条目。
- 最近使用 (MRU):此策略删除最近访问的条目。
- Least Frequently Used (LFU):此策略删除访问次数最少的条目。
- Random Replacement (RR):该策略随机选择一个条目在需要添加新条目时删除。它适用于难以预测将来可能重新访问哪些数据的应用程序。
您还可以使用以下基本且广泛接受的技术来处理来自应用程序的缓存失效:
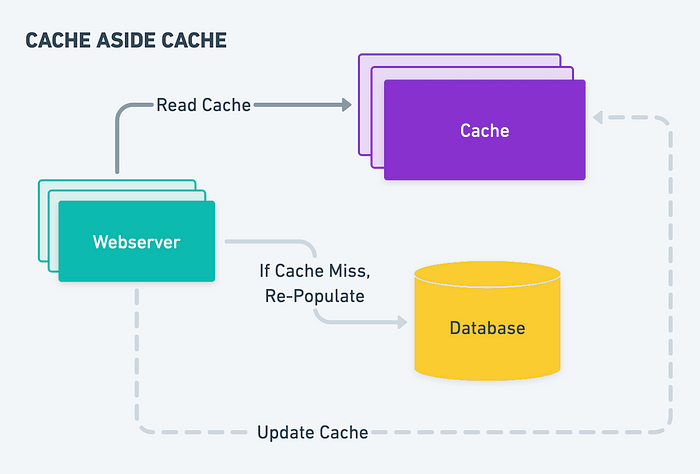
缓存端缓存
该策略涉及在访问源数据(例如数据库)之前检查请求数据的缓存。如果在缓存中找不到数据,则从源数据中检索数据并将其存储在缓存中以备将来使用。
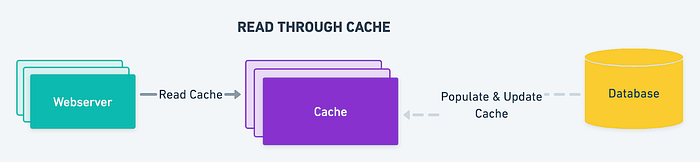
直读缓存
在read-through cache中,当执行了一个读操作,并且没有在cache中找到数据时;缓存将自动从后备存储中获取数据并将其存储在缓存中,然后再将其返回给请求者。这可以通过减少后备存储所需的读取操作数来提高读取性能。在缓存端,应用程序从数据库中检索数据并将其存储在缓存中。相比之下,库或缓存提供程序通常处理通读缓存策略,即从数据库中获取数据并填充缓存的逻辑。
read-through 缓存策略非常适用于频繁请求相同数据,读负载大的场景。然而,这种策略的一个缺点是第一次请求数据时,它总是会导致缓存未命中,从而导致将数据加载到缓存的额外惩罚。开发人员可以通过手动预加载缓存来解决这个问题,也称为“预热”缓存。与cache-aside一样,数据也有可能在缓存和数据库之间变得不一致,所以写策略的选择是必不可少的。
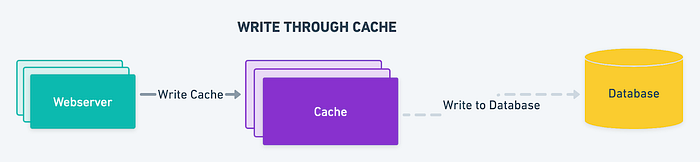
直写缓存
在直写缓存中,当执行写操作时,数据会同时写入缓存和后备存储。这确保了两者之间的数据始终一致,但由于对后备存储的额外写入操作,可能会导致写入性能降低。
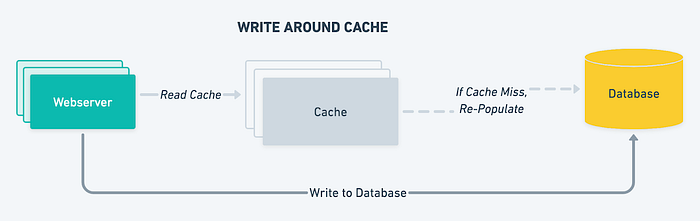
绕写高速缓存
在 write-around 缓存中,写入操作绕过缓存并直接写入后备存储。这可以提高写入性能,但会导致缓存无法与最新数据保持同步。
回写/后写缓存
在回写缓存中,写操作被写入缓存并标记为“脏”。数据最终会写回后备存储,但这可以在以后完成,并且可以与其他脏缓存条目一起完成。这可以提高写入性能,但是如果缓存丢失(例如由于电源故障),任何脏缓存条目都将丢失。
基于推送的失效:该技术使用推送通知系统在源数据中的数据更改时通知缓存节点。这种技术可用于分布式缓存的情况,其中数据在不同的缓存节点之间进行分区。
基于轮询的失效:在这种技术中,缓存节点定期检查源数据的变化并使陈旧数据失效。
优化分布式缓存
应该注意的是,分布式缓存的实现是一个复杂的过程,需要大量的专业知识才能正确维护它。有一些策略可用于优化分布式缓存:
- 数据分区:将数据分成更小的分区并将它们分布在多台服务器上可以帮助减少任何一台服务器上的负载并提高系统的整体性能。
- 一致性:数据一致性在分布式缓存系统中至关重要。可以使用数据复制和基于仲裁的协议等技术来实现一致性。
- 负载平衡:分布式缓存系统必须能够处理多个请求的负载。负载均衡可用于将负载分布到多个服务器上,这有助于提高系统的整体性能。
- 失效:分布式缓存系统需要有一种方法来使陈旧或过时的数据失效。这可以通过为每个缓存条目设置生存时间 (TTL) 值或使用分布式缓存失效协议(如基于失效的协议)来实现。
- 容错:分布式缓存系统必须能够在不丢失数据的情况下处理服务器故障。
- 监控和管理:监控和管理分布式缓存系统对于检测和解决问题至关重要。
监控的关键指标
性能不佳的缓存会减慢数据检索速度,从而对应用程序的性能产生负面影响,因为缓存中存储了大量基本数据。为确保最佳性能,定期评估缓存的使用模式并根据需要及时升级或维护系统至关重要。这将确保缓存按预期运行并且应用程序继续良好运行。
在监视和测量分布式缓存系统的性能时,您应该考虑几个关键指标:
- 缓存命中率:缓存命中与缓存请求的比率。高缓存命中率表明缓存有效工作,而低缓存命中率可能表明缓存没有被有效使用。
- 延迟:缓存完成请求所需的时间。较低的延迟表示更好的性能。
- 吞吐量:缓存每秒可以处理的请求数。高吞吐量表示更好的性能。
- 内存使用量:缓存使用的内存量。高内存使用率可能表示缓存已满或需要更有效地使用。
- 数据一致性:不同缓存节点间数据的一致性。高一致性表示更好的性能。
- 失效率:缓存中发生失效的速率。高无效率可能表示驱逐策略有问题或应用程序请求无效过于频繁。
- 错误率:与缓存交互时发生的错误率。高错误率可能表示缓存或应用程序有问题。
- 复制率:跨节点复制数据的速率。高复制率可能表示数据频繁更改或复制间隔太低。
请记住,最重要的指标可能因用例而异;例如,对于实时应用程序,延迟将比无效率更关键,等等。
安全挑战
确保分布式缓存系统的安全性可能是一项具有挑战性的任务;以下是一些可用于增强安全性的策略:
- 身份验证:要求对缓存的访问进行身份验证有助于防止对缓存的未授权访问。这可以使用用户名和密码身份验证或令牌等技术来实现。
- 加密:加密缓存中存储的数据有助于防止未经授权的访问。这可以使用 AES 或 SSL/TLS 等加密算法在缓存节点之间进行通信来实现。
- 授权:根据用户角色或权限授权对缓存的访问有助于防止对缓存的未授权访问。这可以使用基于角色的访问控制或令牌等技术来实现。
- 网络安全:确保缓存节点之间的通信安全至关重要。这可以使用防火墙和 VPN 或安全协议(如 SSL/TLS)来实现。
- 数据验证:在将数据存储到缓存中之前对数据进行验证,以避免存储恶意数据。
- 审核:跟踪访问缓存的用户及其操作可以帮助检测和防止未经授权的访问。
- 监控:定期监控缓存是否存在可疑活动,例如异常流量模式或登录尝试失败,有助于检测和防止未经授权的访问。
- 定期更新软件:定期更新缓存系统的软件可以帮助修复任何已知的漏洞并增强系统的安全性。
值得注意的是,安全是一个持续的过程,必须持续监控和更新安全措施以跟上新的威胁和漏洞。
处理错误
另一个考虑因素是,虽然设置缓存很重要,但正确处理错误以确保积极的用户体验和最佳应用程序使用也同样重要。在分布式缓存系统中处理错误可能具有挑战性;以下是一些可用于处理错误的策略:
- 故障检测:检测分布式缓存系统中的故障是必不可少的。这可以使用缓存节点之间的乒乓或心跳消息来实现。
- 自动故障转移:自动故障转移是一种允许缓存在发生故障时自动切换到备份缓存节点的机制。这可以确保高可用性并最大限度地减少停机时间。
- 冗余:冗余是一种允许缓存跨多个缓存节点存储数据的多个副本的机制。这有助于确保发生故障时的数据可用性。
- 错误记录:在缓存中记录错误有助于识别和诊断问题。这可以使用集中式日志系统或向监控系统发送错误通知来实现。
- 错误处理:错误处理是一种允许缓存优雅地处理错误的机制。这可以通过重试、返回错误消息或将请求重定向到备份缓存节点来实现。
- 监控:定期监控缓存中的错误有助于检测和预防问题。这可以通过使用 Prometheus 等监控工具或在发生错误时发出通知的警报系统来实现。
- 恢复:恢复是一种允许缓存从故障中恢复的机制。这可以使用复制或数据备份和恢复等技术来实现。
总之,在分布式缓存系统中处理错误可能具有挑战性。尽管如此,故障检测、自动故障转移、冗余、错误记录、错误处理、监控和恢复等技术仍有助于确保高可用性并最大限度地减少停机时间。
流行的可用解决方案
市场上有几种现成的分布式缓存系统解决方案。一些受欢迎的包括:
- Memcached:Memcached 是一种简单、快速且广泛使用的缓存解决方案。它最适合需要简单键值缓存和支持数据逐出策略(例如 LRU)的用例。
- Redis:Redis 是比 Memcached 更高级的缓存解决方案。它支持字符串、散列、列表、集合和排序集合等数据结构,还支持持久性、复制和 Lua 脚本等高级功能。它最适合需要更高级数据结构和支持数据逐出策略(例如 LRU、LFU 和随机逐出)的用例。
- Hazelcast:Hazelcast是一种分布式缓存解决方案,支持LRU、LFU、随机驱逐等数据驱逐策略。它还支持映射、队列和主题等分布式数据结构。它最适合需要支持分布式数据结构和支持数据逐出策略的用例。
- Couchbase:Couchbase 是一种分布式缓存解决方案,支持面向文档的 NoSQL 数据库。它最适合需要缓存、面向文档的 NoSQL 数据库以及支持数据逐出策略(例如 LRU 和生存时间 (TTL))的用例。
- Amazon Elasticache 和 Google Cloud Memorystore是完全托管的缓存服务;它们最适合需要完全托管缓存服务、自动故障转移、数据复制以及内置监控和警报功能的用例。
值得注意的是,最好的解决方案将取决于应用程序的具体需求和要求,尝试不同的解决方案并查看哪一个最适合您的用例总是好的。
结论
在本次对话中,我们讨论了缓存,这是一种通过将频繁访问的数据存储在内存中来提高系统性能和可扩展性的技术。我们介绍了不同的缓存策略,例如生存时间 (TTL)、直写式、回写式、缓存分片和分布式缓存。我们还讨论了在分布式缓存系统中处理错误、确保分布式缓存的安全性、不同缓存策略的应用以及缓存对数据库的好处。
最后,我们讨论了缓存失效,它从缓存中删除陈旧或过时的数据。我们讨论了缓存失效的不同技术,例如生存时间 (TTL)、直写、回写、基于推送的失效和基于轮询的失效。值得注意的是,失效技术的选择将取决于具体要求和用例,例如数据一致性级别、系统规模和网络通信。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK