

OpenAI的子词标记化神器--tiktoken 以及 .NET 支持库SharpToken
source link: https://www.cnblogs.com/shanyou/p/17348030.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

OpenAI的子词标记化神器--tiktoken 以及 .NET 支持库SharpToken
经过 Tokenize 之后,一串文本就变成了一串整数组成的向量。OpenAI 的 Tiktoken 是 更高级的 Tokenizer , 编码效率更高、支持更大的词汇表、计算性能也更高。 OpenAI在其官方GitHub上公开了一个开源Python库:tiktoken,这个库主要是用力做字节编码对的。 字节编码对(Byte Pair Encoder,BPE)是一种子词处理的方法。其主要的目的是为了压缩文本数据。主要是将数据中最常连续出现的字节(bytes)替换成数据中没有出现的字节的方法。该算法首先由Philip Gage在1994年提出。
下图是tiktoken中公开的OpenAI所有大模型所使用的词表。
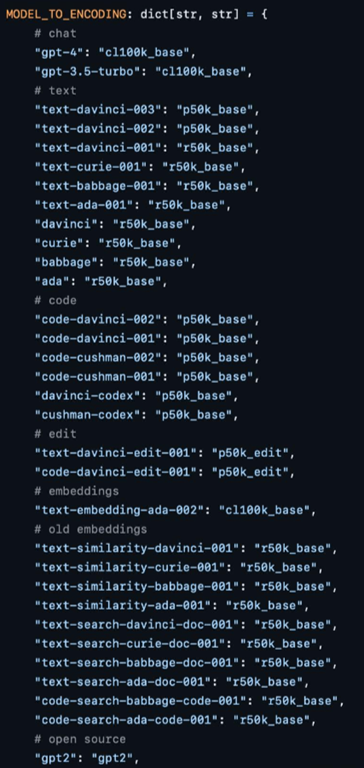
可以看到,ChatGPT和GPT-4所使用的是同一个,名为“cl100k_base”的词表。而text-davinci-003和text-davinci-002所使用的是名为”p50k_base“的词表。

OpenAI 官方开源了Python版本, .NET社区 移植了https://github.com/dmitry-brazhenko/SharpToken, 它提供了使用基于 GPT 的编码对令牌进行编码和解码的功能。此库是为 .NET 6 和 .NET Standard 2.1 构建的,使其与各种框架兼容。
下面是一个示例函数,用于对传递到 gpt-3.5-turbo-0381 或gpt-4-314 的消息的tokens进行计数。请注意,从消息中计算tokens的确切方式可能会因模型而异。将函数中的计数视为一个估计值:
public int CountMessagesTokens(string Model ,string Messages)
{
int tokensPerMessage;
if (Model.StartsWith("gpt-3.5-turbo"))
{
tokensPerMessage = 5;
}
else if (Model.StartsWith("gpt-4"))
{
tokensPerMessage = 4;
}
else
{
tokensPerMessage = 5;
}
var encoding = GptEncoding.GetEncoding("cl100k_base");
int totalTokens = 0;
foreach (var msg in Messages)
{
totalTokens += tokensPerMessage;
totalTokens += encoding.Encode(msg.Content).Count;
}
totalTokens += 3;
return totalTokens;
}
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK