

模仿 Jeff Dean 神总结,前谷歌工程师分享「 LLM 开发秘籍」:每个开发者都应知道的数...
source link: https://www.woshipm.com/ai/5833181.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

模仿 Jeff Dean 神总结,前谷歌工程师分享「 LLM 开发秘籍」:每个开发者都应知道的数字!
一位网友受 Jeff Dean 的启发,整理了一份 LLM 开发秘籍。这份秘籍向工程开发者们解释一些数字的重要性以及该如何利用数字的方法。接下来,让我们跟随作者一起了解吧!

最近,一位网友整理了一份「每个 LLM 开发者都应该知道的数字」,同时解释了这些数字为何重要,以及我们应该如何利用它们。
他在谷歌的时候,就有一份由传奇工程师 Jeff Dean 整理的文件,叫做「每个工程师都应该知道的数字」。

Jeff Dean:「每个工程师都应该知道的数字」
而对于 LLM(Large Language Model)开发者来说,有一组类似的用于粗略估算的数字也是非常有用的。

40-90%:在提示中添加「简明扼要」之后节省的成本
要知道,你是按照 LLM 在输出时用掉的 token 来付费的。
这意味着,让模型简明扼要(be concise)地进行表述,可以省下很多钱。
与此同时,这个理念还可以扩展到更多地方。
比如,你本来想用 GPT- 4 生成 10 个备选方案,现在也许可以先要求它提供 5 个,就可以留下另一半的钱了。
1.3:每个词的平均 token 数
LLM 是以 token 为单位进行操作的。
而token是单词或单词的子部分,比如「eating」可能被分解成两个 token「 eat 」和「 ing 」。
一般来说,750 个英文单词将产生大约 1000 个 token 。
对于英语以外的语言,每个词的 token 会有所增加,具体数量取决于它们在LLM的嵌入语料库中的通用性。

考虑到 LLM 的使用成本很高,因此和价格相关的数字就变得尤为重要了。
~50:GPT-4 与GPT-3.5 Turbo 的成本比
使用 GPT-3.5 – Turbo 大约比 GPT- 4 便宜 50 倍。说「大约」是因为 GPT-4 对提示和生成的收费方式不同。
所以在实际应用时,最好确认一下 GPT-3.5 – Turbo 是不是就足够完成你的需求。
例如,对于概括总结这样的任务,GPT-3.5-Turbo 绰绰有余。


5:使用 GPT-3.5-Turbo 与 OpenAI 嵌入进行文本生成的成本比
这意味着在向量存储系统中查找某个内容比使用用LLM生成要便宜得多。
具体来说,在神经信息检索系统中查找,比向 GPT-3.5-Turbo 提问要少花约 5 倍的费用。与 GPT-4 相比,成本差距更是高达 250 倍!
10:OpenAI 嵌入与自我托管嵌入的成本比
注意:这个数字对负载和嵌入的批大小非常敏感,因此请将其视为近似值。
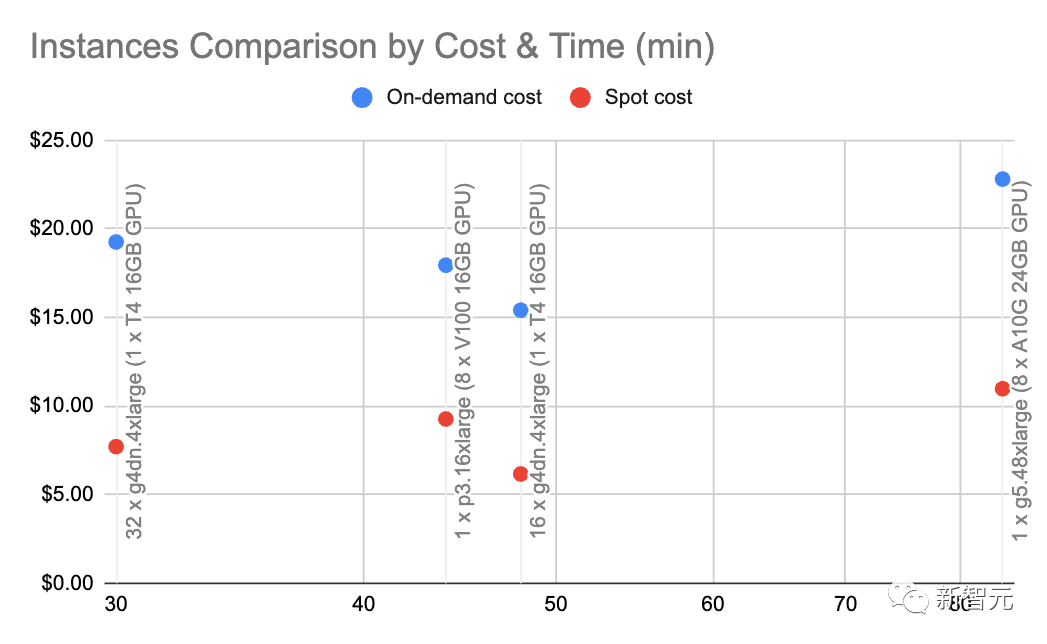
通过 g4dn.4xlarge(按需价格:1.20 美元/小时),我们可以利用用 HuggingFace 的 SentenceTransformers(与 OpenAI 的嵌入相当)以每秒约 9000 个 token 的速度进行嵌入。
在这种速度和节点类型下进行一些基本的计算,表明自我托管的嵌入可以便宜 10 倍。
6:OpenAI 基础模型与微调模型查询的成本比
在 OpenAI 上,微调模型的成本是基础模型的 6 倍。
这也意味着,相比微调定制模型,调整基础模型的提示更具成本效益。
1:自我托管基础模型与微调模型查询的成本比
如果你自己托管模型,那么微调模型和基础模型的成本几乎相同:这两种模型的参数数量是一样的。
三、训练和微调
~100 万美元:在 1.4 万亿个 token 上训练 130 亿参数模型的成本

论文地址:https://arxiv.org/pdf/2302.13971.pdf
LLaMa 的论文中提到,他们花了 21 天的时间,使用了 2048 个 A100 80GB GPU,才训练出了 LLaMa 模型。
假设我们在 Red Pajama 训练集上训练自己的模型,假设一切正常,没有任何崩溃,并且第一次就成功,就会得到上述的数字。
此外,这个过程还涉及到 2048 个 GPU 之间的协调。
大多数公司,并没有条件做到这些。
不过,最关键的信息是:我们有可能训练出自己的 LLM,只是这个过程并不便宜。
并且每次运行,都需要好几天时间。
相比之下,使用预训练模型,会便宜得多。
0.001:微调与从头开始训练的成本费率
这个数字有点笼统,总的来说,微调的成本可以忽略不计。
例如,你可以用大约 7 美元的价格,微调一个 6B 参数的模型。
即使按照 OpenAI 对其最昂贵的微调模型 Davinci 的费率,每 1000 个 token 也只要花费 3 美分。
这意味着,如果要微调莎士比亚的全部作品(大约 100 万个单词),只需要花费四五十美元。
不过,微调是一回事,从头开始训练,就是另一回事了…
四、GPU 显存
如果您正在自托管模型,了解 GPU 显存就非常重要,因为 LLM 正在将 GPU 的显存推向极限。
以下统计信息专门用于推理。如果要进行训练或微调,就需要相当多的显存。
V100:16GB,A10G:24GB,A100:40/80GB:GPU 显存容量
了解不同类型的GPU的显存量是很重要的,因为这将限制你的LLM可以拥有的参数量。
一般来说,我们喜欢使用A10G,因为它们在AWS上的按需价格是每小时1.5到2美元,并且用有24G的GPU显存,而每个A100的价格约为5美元/小时。
2x 参数量:LLM 的典型 GPU 显存要求
举个例子,当你拥有一个 70 亿参数的模型时,就需要大约 14GB 的 GPU 显存。
这是因为大多数情况下,每个参数需要一个 16 位浮点数(或 2 个字节)。
通常不需要超过 16 位精度,但大多数时候,当精度达到 8 位时,分辨率就开始降低(在某些情况下,这也可以接受)。
当然,也有一些项目改善了这种情况。比如 llama.cpp 就通过在 6GB GPU 上量化到4位( 8 位也可以),跑通了 130 亿参数的模型,但这并不常见。
~1GB:嵌入模型的典型 GPU 显存要求
每当你嵌入语句(聚类、语义搜索和分类任务经常要做的事)时,你就需要一个像语句转换器这样的嵌入模型。OpenAI也有自己的商用嵌入模型。
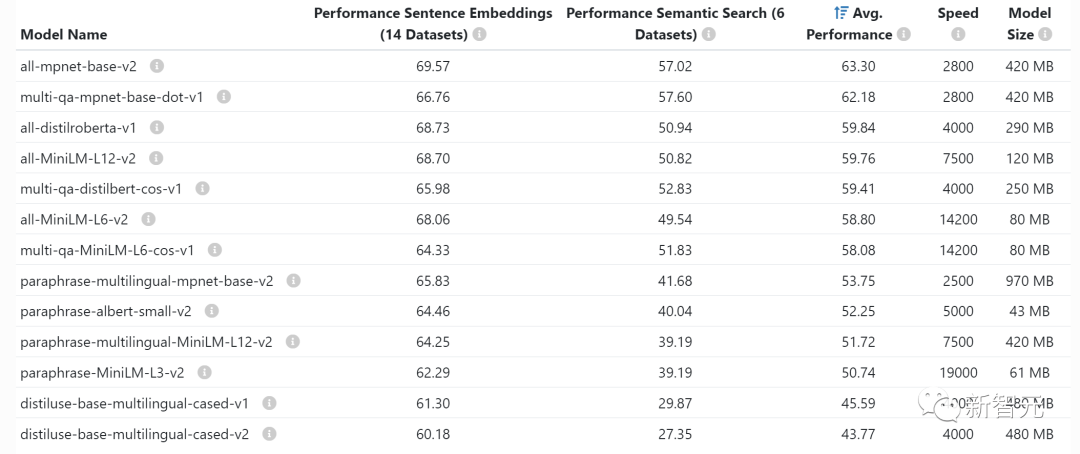
通常不必担心 GPU 上的显存嵌入占用多少,它们相当小,甚至可以在同一 GPU 上嵌入 LLM 。
10x:通过批处理 LLM 请求,提高吞吐量
通过 GPU 运行 LLM 查询的延迟非常高:吞吐量为每秒 0.2 个查询的话,延迟可能需要 5 秒。
有趣的是,如果你运行两个任务,延迟可能只需要 5.2 秒。
这意味着,如果能将 25 个查询捆绑在一起,则需要大约 10 秒的延迟,而吞吐量已提高到每秒 2.5 个查询。
不过,请接着往下看。
~1 MB:130 亿参数模型输出 1 个 token 所需的 GPU 显存
你所需要的显存与你想生成的最大 token 数量直接成正比。
比如,生成最多 512 个 token(大约 380 个单词)的输出,就需要 512MB 的显存。
你可能会说,这没什么大不了的——我有 24GB 的显存,512MB 算什么?然而,如果你想运行更大的 batch,这个数值就会开始累加了。
比如,如果你想做 16 个 batch,显存就会直接增加到 8GB 。
作者:新智元;编辑:好困 Aeneas
来源公众号:新智元(ID:AI_era),“智能+”中国主平台,致力于推动中国从“互联网+”迈向“智能+”。
本文由人人都是产品经理合作媒体 @新智元 授权发布,未经许可,禁止转载。
题图来自 Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK