

图数据库 NebulaGraph 的内存管理实践之 Memory Tracker - NebulaGraph
source link: https://www.cnblogs.com/nebulagraph/p/17409672.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

图数据库 NebulaGraph 的内存管理实践之 Memory Tracker
数据库的内存管理是数据库内核设计中的重要模块,内存的可度量、可管控是数据库稳定性的重要保障。同样的,内存管理对图数据库 NebulaGraph 也至关重要。
图数据库的多度关联查询特性,往往使图数据库执行层对内存的需求量巨大。本文主要介绍 NebulaGraph v3.4 版本中引入的新特性 Memory Tracker,希望通过 Memory Tracker 模块的引入,实现细粒度的内存使用量管控,降低 graphd 和 storaged 发生被系统 OOM kill 的风险,提升 NebulaGraph 图数据库的内核稳定性。
注:为了同代码保持对应,本文部分用词直接使用了英文,e.g. reserve 内存 quota。
在进行 Memory Tracker 的介绍之前,这里先介绍下相关的背景知识:可用内存。
进程可用内存
在这里,我们简单介绍下各个模式下,系统是如何判断可用内存的。
物理机模式
数据库内核会读取系统目录 /proc/meminfo,来确定当前环境的实际内存和剩余内存,Memory Tracker 将“实际物理内存”作为“进程可以使用的最大内存”;
容器/cgroup 模式
在 nebula-graphd.conf 文件中有一个配置项 FLAG_containerized 用来判断是否数据库跑在容器上。将 FLAG_containerized(默认为 false)设置为 true 之后,内核会读取相关 cgroup path 下的文件,确定当前进程可以使用多少内存;cgroup 有 v1、v2 两个版本,这里以 v2 为例;
| FLAG | 默认值 | 解释 |
|---|---|---|
| FLAG_cgroup_v2_memory_max_path | /sys/fs/cgroup/memory.max | 通过读取路径确定最大内存使用量 |
| FLAG_cgroup_v2_memory_current_path | /sys/fs/cgroup/memory.current | 通过读取路径确定当前内存使用量 |
举个例子,在单台机器上分别控制 graphd 和 storaged 的内存额度。你可以通过以下步骤:
step1:设置 FLAG_containerized=true;
step2:创建 /sys/fs/cgroup/graphd/,/sys/fs/cgroup/storaged/,并配置各自目录下的 memory.max;
step3:在 etc/nebula-graphd.conf,etc/nebula-storaged.conf 添加相关配置
--containerized=true
--cgroup_v2_controllers=/sys/fs/cgroup/graphd/cgroup.controllers
--cgroup_v2_memory_stat_path=/sys/fs/cgroup/graphd/memory.stat
--cgroup_v2_memory_max_path=/sys/fs/cgroup/graphd/memory.max
--cgroup_v2_memory_current_path=/sys/fs/cgroup/graphd/memory.current
Memory Tracker 可用内存
在获取“进程可用内存”以后,系统需要将其换算成 Memory Tracker 可 track 的内存,“进程可用内存”与“Memory Tracker 可用内存”有一个换算公式;
memtracker_limit = ( total - FLAGS_memory_tracker_untracked_reserved_memory_mb ) * FLAGS_memory_tracker_limit_ratio
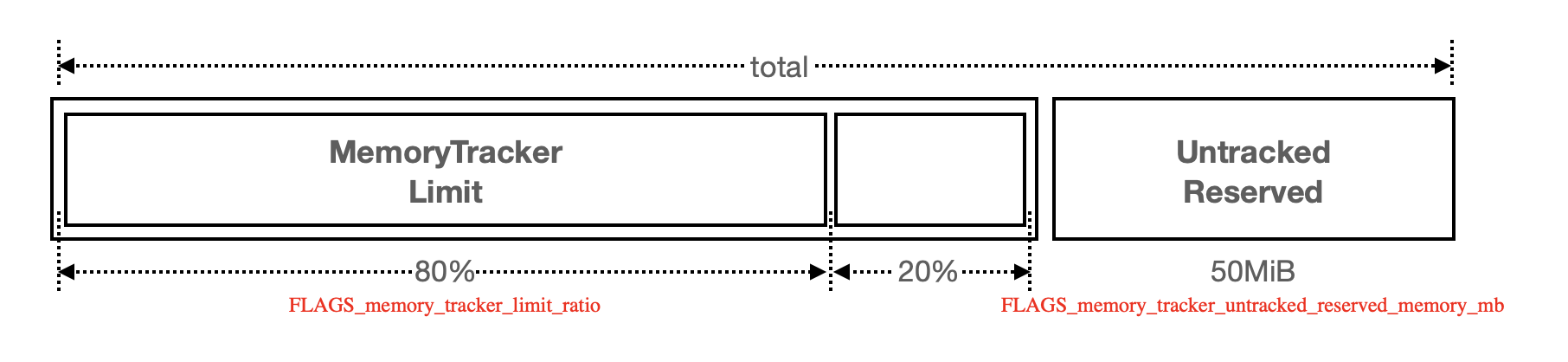
| FLAG | 默认值 | 解释 | 支持动态改 |
|---|---|---|---|
| memory_tracker_untracked_reserved_memory_mb | 50 M | Memory Tracker 会管理通过 new/delete 申请的内存,但进程除了通过此种方式申请内存外,还可能存在其他方式占用的内存;比如通过调用底层的 malloc/free 申请,这些内存通过此 flag 控制,在计算时会扣除此部分未被 track 的内存。 | Yes |
| memory_tracker_limit_ratio | 0.8 | 指定 Memory Tracker 可以使用的内存比例,在一些场景,我们可能需要调小来防止 OOM。 | Yes |
这里来详细展开说下 memory_tracker_limit_ratio 的使用:
- 在混合部署环境中,存在多个 graphd 或 storaged 混合部署是需要调小。比如 graphd 只占用 50% 内存,则需在 nebula-graphd.conf 中将其手动改成 0.5;
- 取值范围:
memory_tracker_limit_ratio除了(0,1]取值范围外,还额外定义了两个特殊值:2:通过数据库内核感知当前系统运行环境的可用内存,动态调整可用内存。由于此种方式非实时,有一定的概率会感知不精准;3:limit 将被设成一个极大值,起到关闭 Memory Tracker 的效果;
Memory Tracker 的设计与实现方案
下面,讲下 Memory Tracker 的设计与实现。整体的 Memory Tracker 设计,包含 Global new/delete operator、MemoryStats、system malloc、Limiter 等几个子模块。这个部分着重介绍下 Global new/delete operator 和 MemoryStats 模块。
Global new/delete operator
Memory Tracker 通过 overload 全局 new/delete operator,接管内存的申请和释放,从而做到在进行真正的内存分配之前,进行内存额度分配的管理。这个过程分解为两个步骤:
- 第一步:通过 MemoryStats 进行内存申请的汇报;
- 第二步:调用 jemalloc 发生真正的内存分配行为;
jemalloc:Memory Tracker 不改变底层的 malloc 机制,仍然使用 jemalloc 进行内存的申请和释放;
MemoryStats
全局的内存使用情况统计,通过 GlobalMemoryStats 和 ThreadMemoryStats 分别对全局内存和线程内部内存进行管理;
ThreadMemoryStats
thread_local 变量,执行引擎线程在各自的 ThreadMemoryStats 中维护线程的 MemoryStats,包括“内存 Reservation 信息”和“是否允许抛异常的 throwOnMemoryExceeded”;
- Reservation
每个线程 reserve 了 1 MB 的内存 quota,从而避免频繁地向 GlobalMemoryStats 索要额度。不管是申请还是返还时,ThreadMemoryStats 都会以一个较大的内存块作为与全局交换的单位。
alloc:在本地 reserved 1 MB 内存用完了,才问全局要下一个 1 MB。通过此种方式来尽可能降低向全局 quota 申请内存的频率;
dealloc:返还的内存先加到线程的 reserved 中,当 reserve quota 超过 1 MB 时,还掉 1 MB,剩下的自己留着;
// Memory stats for each thread.
struct ThreadMemoryStats {
ThreadMemoryStats();
~ThreadMemoryStats();
// reserved bytes size in current thread
int64_t reserved;
bool throwOnMemoryExceeded{false};
};
- throwOnMemoryExceeded
线程在遇到超过内存额度时,是否 throw 异常。只有在设置 throwOnMemoryExceeded 为 true 时,才会 throw std::bad_alloc。需要关闭 throw std::bad_alloc 场景见 Catch std::bac_alloc 章节。
GlobalMemoryStats
全局内存额度,维护了 limit 和 used 变量。
-
limit:通过运行环境和配置信息,换算得到 Memory Tracker 可管理的最大内存。limit 同 Limiter 模块的作用,详细内存换算见上文“Memory Tracker 可用内存”章节;
-
used:原子变量,汇总所有线程汇报上来的已使用内存(包括线程 reserved 的部分)。如果 used + try_to_alloc > limit,且在
throwOnMemoryExceeded为 true 时,则会抛异常std::bac_alloc。
Catch std::bac_alloc
由于 Memory Tracker overload new/delete 会影响所有线程,包括三方线程。此时,throw bad_alloc 在一些第三方线程可能出现非预期行为。为了杜绝此类问题发生,我们采用在代码路径上主动开启内存检测,选择在算子、RPC 等模块主动开启内存检测;
算子的内存检测
在 graph/storage 的各个算子中,添加 try...catch (在当前线程进行计算/分配内存) 和 thenError (通过 folly::Executor 异步提交的计算任务),感知 Memory Tracker 抛出 std::bac_alloc。数据库再通过 Status 返回错误码,使查询失败;
在进行一些内存调试时,可通过打开 nebula-graphd.conf 文件中的 FLAGS_memory_tracker_detail_log 配置项,并调小 memory_tracker_detail_log_interval_ms 观察查询前后的内存使用情况;
folly::future 异步执行
thenValue([this](StorageRpcResponse<GetNeighborsResponse>&& resp) {
memory::MemoryCheckGuard guard;
// memory tracker turned on code scope
return handleResponse(resp);
})
.thenError(folly::tag_t<std::bad_alloc>{},
[](const std::bad_alloc&) {
// handle memory exceed
})
同步执行
memory::MemoryCheckGuard guard; \
try {
// ...
} catch (std::bad_alloc & e) { \
// handle memory exceed
}
RPC 的内存检测
RPC 主要解决 Request/Response 对象的序列化/反序列化的内存额度控制问题,由于 storaged reponse 返回的数据均封装在 DataSet 数据结构中,所以问题转化为:DataSet 的序列化、反序列化过程中的内存检测。
序列化:DataSet 的对象构造在 NebulaGraph 算子返回结果逻辑中,默认情况下,已经开启内存检测;
反序列化:通过 MemoryCheckGuard 显式开启,在 StorageClientBase::getResponse's onError 可捕获异常;
为了便于分辨哪个模块发生问题,NebulaGraph 中还添加了相关错误码,分别表示 graphd 和 storaged 发生 memory exceeded 异常:
E_GRAPH_MEMORY_EXCEEDED = -2600, // Graph memory exceeded
E_STORAGE_MEMORY_EXCEEDED = -3600, // Storage memory exceeded
谢谢你读完本文 (///▽///)
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK