

Using vector math functions on Arm
source link: https://community.arm.com/arm-community-blogs/b/tools-software-ides-blog/posts/using-vector-math-functions-on-arm
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Using vector math functions on Arm

Performance of a broad range of workloads, including many benchmarks such as SPEC, rely on the efficient implementation of elementary math routines. These routines can leverage performance by vectorization and efficient use of SIMD pipelines.
A recent blog post describes how to increase performance of weather prediction models on Neoverse V1 using SVE subroutines provided in Arm Compiler for Linux (ACfL) and Arm Performance Libraries (Arm PL).
Arm optimized scalar and vector math routines implementation is available publicly as open-source software in ARM-software/optimized-routines. These implementations are conveniently licensed to allow users to include them directly in other projects, if needed. In addition, we also release these as pre-compiled binaries, called Libamath, as part of both Arm PL and ACfL.
While ACfL is able to generate calls to vector math routines through auto-vectorisation (see https://developer.arm.com/documentation/101458/latest/ for more details using the "-fsimdmath" compiler option), other compilers may not allow that to happen on AArch64 yet. However linking your project to Arm PL or building it with ACfL with auto-vectorisation disabled still gives you access to the vector math symbols. Libamath is shipped with ACfL, but as a separate library, therefore your project can be linked to libamath by adding -lamath.
In this post, we highlight the scale of performance increases possible, detail the accuracy requirements, and explain in detail how to use these functions directly in your own code.
Accuracy and Performance
Libamath routines have maximum errors inferior to 4 ULPs and only support the default rounding mode (round-to-nearest, ties to even). Therefore switching from libm to libamath results in a small accuracy loss on a range of routines, similar to other vectorized implementations of these functions.
The expected performance gain on a Neoverse V1 system is shown on the following 2 graphs for single and double-precision routines.
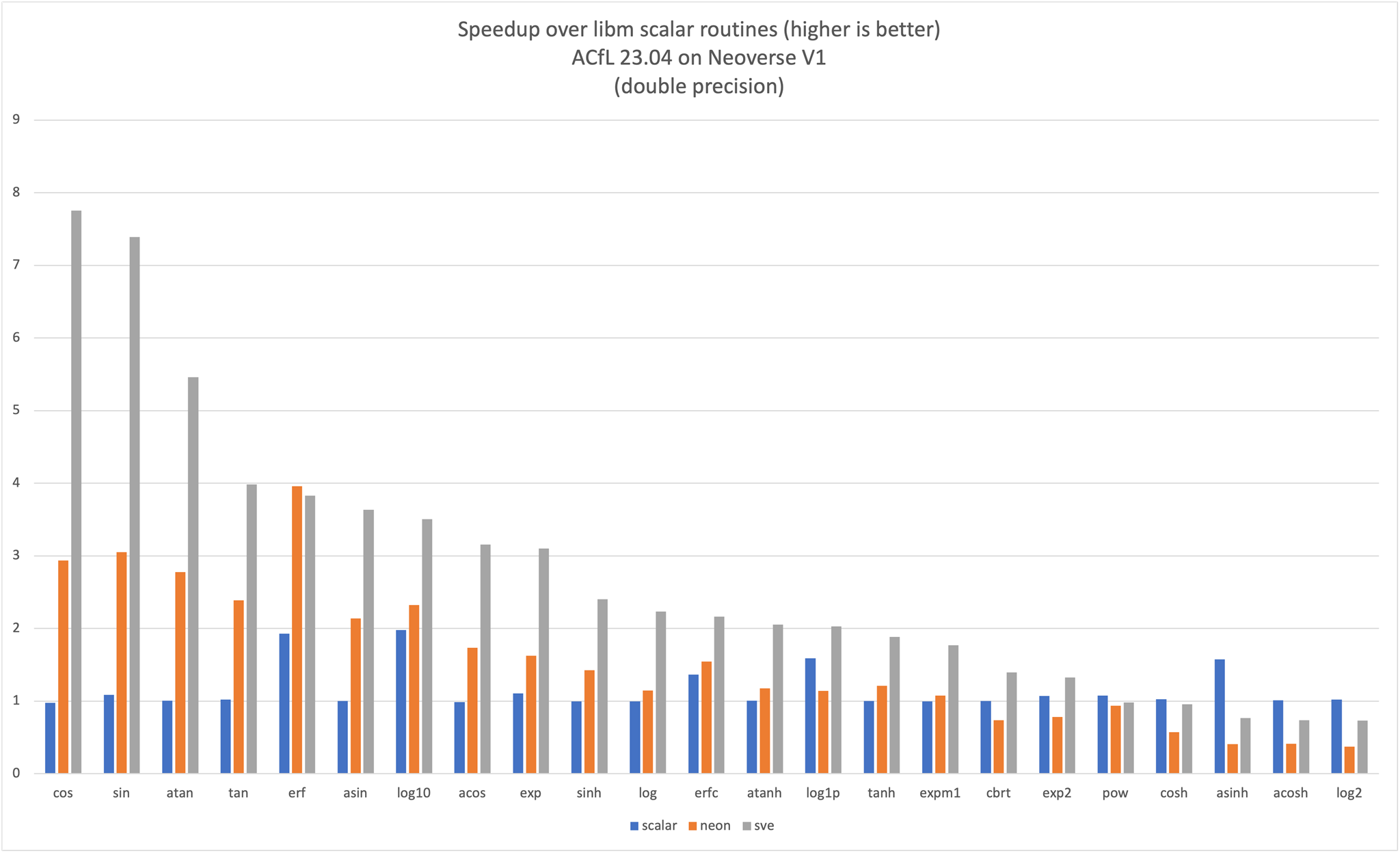
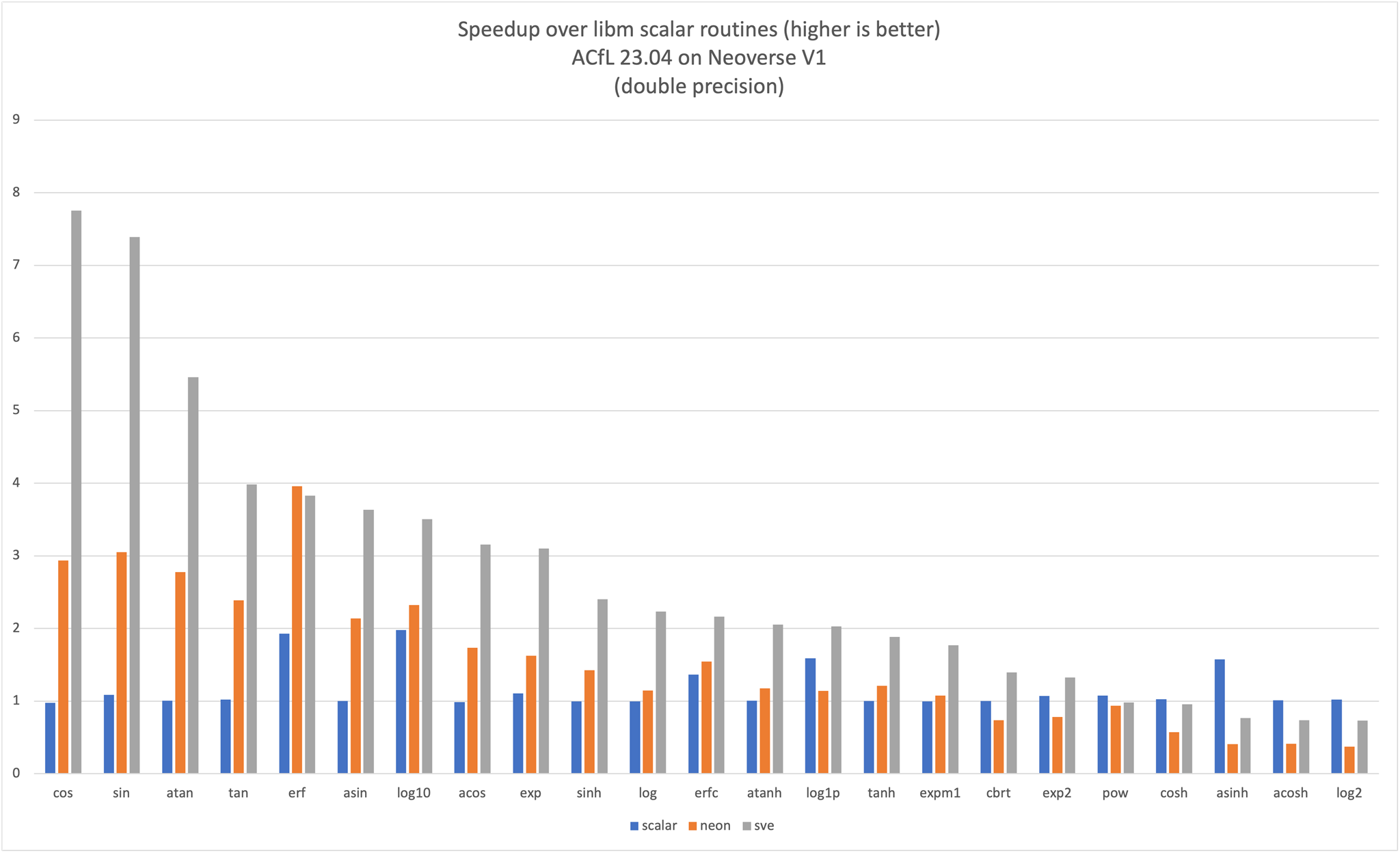
Naming and Calling Conventions
Libamath scalar routines match names used in libm, for example, single and double-precision exponential are called respectively expf and exp.
Each vector routine is exposed under the vector ABI name. The vector name mangling defined in AArch64's vector function ABI matches that of glibc's vector ABI (section 2.6).
For instance, the symbols used for the scalar, Neon, and SVE variants of single-precision exponential read as expf, _ZGVnN4v_expf and _ZGVsMxv_expf, respectively.
Vector ABI
In the vector ABI, the vector function name is mangled as the concatenation of the following items:
'_ZGV' <isa> <mask> <vlen> <signature> '_' <original_name>
where
-
<original_name>: name of scalar libm function -
<isa>: 'n' for Neon, 's' for SVE <mask>: 'M' for masked/predicated version, 'N' for unmasked. Only masked routines are defined for SVE, and only unmasked for Neon.<vlen>: integer number representing vector length expressed as number of lanes. For Neon<vlen>='2'in double-precision and<vlen>='4'in single-precision. For SVE,<vlen>='x'.<signature>: 'v' for 1 input floating point or integer argument, 'vv' for 2. More details in AArch64's vector function ABI.
Examples
From the latest release, 23.04, Arm Performance Libraries provides documentation and an example program to show how a user may call vector routines directly from their programs, without relying on auto-vectorization. The following snippet illustrates how to call Neon double precision sincos, SVE single-precision pow and SVE double-precision erf.
Declarations of all scalar and vector routines are provided in the header file amath.h.
#include <amath.h>
int main(void) {
// Neon cos and sin (using sincos)
float64x2_t vx = (float64x2_t){0.0, 0.5};
double vc[2], vs[2];
_ZGVnN2vl8l8_sincos(vx, vs, vc);
// SVE math routines
#if defined(__ARM_FEATURE_SVE)
// single precision pow
svbool_t pg32 = svptrue_b32();
svfloat32_t svx = svdup_n_f32(2.0f);
svfloat32_t svy = svdup_n_f32(3.0f);
svfloat32_t svz = _ZGVsMxvv_powf(svx, svy, pg32);
// double precision error function
svbool_t pg64 = svptrue_b64();
svfloat64_t svw = svdup_n_f64(20.0);
svfloat64_t sve = _ZGVsMxv_erf(svw, svptrue_b64());
#endif
}Conclusion
When using Arm Compiler for Linux, libamath offers the potential to leverage performance on these applications by relying on auto-vectorisation via the compiler. This offers Arm-optimised Neon and SVE variants of all math.h routines. Our "Optimized Routines" open-source repository gives access to the latest optimisations for the more widely used routines. These vectorized algorithms are already used to accelerate elementary math on Arm in a range of applications like computational physics, machine learning and networking. When using either of these methods the user also has the option to call directly into these vector routines from their code using the interfaces described above.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK