

数据分析缺失值处理(Missing Values)——删除法、填充法、插值法 - VipSoft
source link: https://www.cnblogs.com/vipsoft/p/17399188.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

数据分析缺失值处理(Missing Values)——删除法、填充法、插值法
缺失值指数据集中某些变量的值有缺少的情况,缺失值也被称为NA(not available)值。在pandas里使用浮点值NaN(Not a Number)表示浮点数和非浮点数中的缺失值,用NaT表示时间序列中的缺失值,此外python内置的None值也会被当作是缺失值。需要注意的是,有些缺失值也会以其他形式出现,比如说用NULL,0或无穷大(inf)表示。
pip install d2l -i https://pypi.tuna.tsinghua.edu.cn/simple
import os
import pandas as pd
# 添加 测试数据
os.makedirs(os.path.join('.', 'data'), exist_ok=True)
data_file = os.path.join('.', 'data', 'house_tiny.csv')
with open(data_file, 'w') as f:
f.write('NumRooms,Alley,Test,Price\n')
f.write('NA,Pave,NA,127500\n')
f.write('2,D,A,106000\n')
f.write('4,NA,NA,178100\n')
f.write('NA,NA,B,14000\n')
# 读取 csv 数据
data = pd.read_csv(data_file)
print("\nCSV data => \n", data)
print("-" * 60)
# 检测缺失值
res_null = pd.isnull(data)
print("\nres_null => \n", res_null)
print("\nres_null.sum() => \n", res_null.sum())
# 通过位置索引iloc,将 data 分成 inputs、 outputs
inputs, outputs = data.iloc[:, 0:3], data.iloc[:, 3]
print("-" * 60)
简单,但是容易造成数据的大量丢失
1、删除全为空值的行或列
data=data.dropna(axis=0,how='all') # 只删除【全行】为缺失值的行数据
data=data.dropna(axis=1,how='all') # 只删除【全列】为缺失值的列数据
2、删除含有空值的行或列
data=data.dropna(axis=0,how='any') # 只要【行】中有缺失值的,删除该【行】数据
data=data.dropna(axis=1,how='any') # 只要【列】中有缺失值的,删除该列数据
axis : {0或'index',1或'columns'},默认0
确定是否删除包含缺失值的行或列。
0或’index’:删除包含缺失值的行。
1或“列”:删除包含缺失值的列。
从0.23.0版开始不推荐使用:将元组或列表传递到多个轴上。只允许一个轴。
how : {'any','all'},默认为'any'
当我们有至少一个NA或全部NA时,确定是否从DataFrame中删除行或列。
'any':如果存在任何NA值,则删除该行或列。
'all':如果所有值均为NA,则删除该行或列。
thresh : int,可选
需要许多非NA值。
subset :类数组,可选
要考虑的其他轴上的标签,例如,如果要删除行,这些标签将是要包括的列的列表。
inplace : bool,默认为False
如果为True,则对数据源进行生效
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(5, 3), index=list('abcde'), columns=['one', 'two', 'three']) # 随机产生5行3列的数据
print(df)
df.iloc[1, :] = np.nan # 将指定数据定义为缺失
df.iloc[1:-1, 2] = np.nan
print("-" * 60)
print(df)
print("-" * 60)
print(df.dropna(axis=0))
import os
import pandas as pd
"""
删除法:
简单,但是容易造成数据的大量丢失
how = "any" 只要有缺失值就删除
how = "all" 只删除全行为缺失值的行
axis = 1 丢弃有缺失值的列(一般不会这么做,这样会删掉一个特征), 默认值为:0
"""
# 添加 测试数据
data_file = os.path.join('.', 'data', 'house_tiny.csv')
"""
输入:
NumRooms Alley Test Price
0 NaN Pave NaN 127500.0
1 2.0 D NaN 106000.0
2 4.0 NaN NaN 178100.0
3 NaN NaN NaN NaN
输出:
NumRooms Alley Test Price
0 NaN Pave NaN 127500.0
1 2.0 D NaN 106000.0
2 4.0 NaN NaN 178100.0
"""
print("-" * 60)
with open(data_file, 'w') as f:
f.write('NumRooms,Alley,Test,Price\n')
f.write('NA,Pave,NA,127500\n')
f.write('2,D,NA,106000\n')
f.write('4,NA,NA,178100\n')
f.write('NA,NA,NA,NA\n')
data = pd.read_csv(data_file)
print("\nCSV data => \n", data)
data.dropna(how="all", axis=0, inplace=True)
print("删除之后的结果,只删除全行为缺失值的行数据: \n", data)
"""
输入:
NumRooms Alley Test Price
0 NaN Pave NaN 127500.0
1 2.0 D NaN 106000.0
2 4.0 NaN NaN 178100.0
3 NaN NaN NaN NaN
输出:
NumRooms Alley Price
0 NaN Pave 127500.0
1 2.0 D 106000.0
2 4.0 NaN 178100.0
3 NaN NaN NaN
"""
print("-" * 60)
data.dropna(how="all", axis=1, inplace=True)
print("删除之后的结果,只删除全列为缺失值的列数据: \n", data)
"""
输入:
NumRooms Alley Test Price
0 NaN Pave A 127500.0
1 2.0 D E 106000.0
2 4.0 NaN NaN 178100.0
3 NaN NaN B NaN
输出:
NumRooms Alley Test Price
1 2.0 D E 106000.0
"""
with open(data_file, 'w') as f:
f.write('NumRooms,Alley,Test,Price\n')
f.write('NA,Pave,A,127500\n')
f.write('2,D,E,106000\n')
f.write('4,NA,NA,178100\n')
f.write('NA,NA,B,NA\n')
data = pd.read_csv(data_file)
print("\nCSV data => \n", data)
print("-" * 60)
data.dropna(how="any", axis=0, inplace=True)
print("删除之后的结果,只要【行】中有缺失值的,删除该【行】数据: \n", data)
"""
输入:
NumRooms Alley Test Price
0 NaN Pave A 127500
1 2.0 D E 106000
2 4.0 NaN C 178100
3 NaN NaN B 14000
输出:
Test Price
0 A 127500
1 E 106000
2 C 178100
3 B 14000
"""
with open(data_file, 'w') as f:
f.write('NumRooms,Alley,Test,Price\n')
f.write('NA,Pave,A,127500\n')
f.write('2,D,E,106000\n')
f.write('4,NA,C,178100\n')
f.write('NA,NA,B,14000\n')
data = pd.read_csv(data_file)
print("\nCSV data => \n", data)
print("-" * 60)
data.dropna(how="any", axis=1, inplace=True)
print("删除之后的结果,只要【列】中有缺失值的,删除该列数据: \n", data)
"""
输入:
NumRooms Alley Test Price
0 NaN Pave A 127500
1 2.0 D E 106000
2 4.0 C NaN 178100
3 NaN NaN B 14000
输出:
NumRooms Alley Test Price
0 NaN Pave A 127500
1 2.0 D E 106000
"""
with open(data_file, 'w') as f:
f.write('NumRooms,Alley,Test,Price\n')
f.write('NA,Pave,A,127500\n')
f.write('2,D,E,106000\n')
f.write('4,C,NA,178100\n')
f.write('NA,NA,B,14000\n')
data = pd.read_csv(data_file)
print("\nCSV data => \n", data)
print("-" * 60)
dt = data.dropna(subset=["Alley", "Test"])
print("删除之后的结果,删除 'Alley', 'Test': 有空值的行。\n", dt)
只要不影响数据分布或者对结果影响不是很大的情况
数值型 ——可以使用均值、众数、中位数来填充,也可以使用这一列的上下邻居数据来填充
类别数据(非数值型) ——可以使用众数来填充,也可以使用这一列的上下邻居数据来填充
使用众数来填充非数值型数据
fillna():使用指定的方法填充NA/NaN值。
返回值:DataFrame 缺少值的对象已填充。不改变原序列值。
参数解释
- value :scalar(标量), dict, Series, 或DataFrame
用于填充孔的值(例如0),或者是dict / Series / DataFrame的值,
该值指定用于每个索引(对于Series)或列(对于DataFrame)使用哪个值。
不在dict / Series / DataFrame中的值将不被填充。该值不能是列表(list)。 - method : {‘backfill’,‘bfill’,‘pad’,‘ffill’,None},默认为None
填充重新索引的系列填充板/填充中的holes的方法:
将最后一个有效观察向前传播到下一个有效回填/填充:
使用下一个有效观察来填充间隙。 - axis : {0或’index’,1或’columns’}
填充缺失值所沿的轴。
inplace : bool,默认为False
如果为True,则就地填充。
注意:这将修改此对象上的任何其他视图
(例如,DataFrame中列的无副本切片)。 - limit : int,默认值None
如果指定了method,
则这是要向前/向后填充的连续NaN值的最大数量。
换句话说,如果存在连续的NaN数量大于此数量的缺口,
它将仅被部分填充。如果未指定method,
则这是将填写NaN的整个轴上的最大条目数
如果不为None,则必须大于0。 - downcast : dict,默认为None
item-> dtype的字典,如果可能的话,将向下转换,
或者是字符串“infer”,
它将尝试向下转换为适当的相等类型
(例如,如果可能,则从float64到int64)。
import os
import pandas as pd
# 添加 测试数据
data_file = os.path.join('.', 'data', 'house_tiny.csv')
with open(data_file, 'w') as f:
f.write('NumRooms,Alley,Test,Price\n')
f.write('NA,Pave,NA,127500\n')
f.write('2,D,NA,106000\n')
f.write('4,NA,NA,178100\n')
f.write('NA,NA,NA,NA\n')
data = pd.read_csv(data_file)
print("\nCSV data => \n", data)
print("-" * 60)
# 处理缺失值,替换法 - 用当前列的平均值,填充 NaN
# 通过位置索引iloc,将 data 分成 inputs、 outputs
inputs, outputs = data.iloc[:, 0:4], data.iloc[:, 3]
a = inputs.fillna(inputs.mean())
print("\ninputs.fillna => \n", a)
b = inputs.fillna(inputs.mean(), limit=1)
print("\ninputs.fillna => \n", b)
最常用的插值函数就是interp1d,按照字面意思理解就是插值一个一维函数。其必不可少的输入参数,就是将要被插值的函数的自变量和因变量,输出为被插值后的函数
而所谓插值,要求只能在特定的两个值之间插入,而对于超出定义域范围的值,是无法插入的
在无声明的情况下,插值方法默认是线性插值linear,如有其他需求,可变更kind参数来实现,可选插值方法如下:
- 样条插值:其0、1、2、3阶插值参数分别为zero、slinear、quadratic、cubic
- 返回单点:next和previous用于返回上一个或下一个值
- 最邻近插值:nearest采取向下取整;nearest-up采用向上取整。
import numpy as np
import matplotlib.pyplot as plt
import scipy.interpolate as si
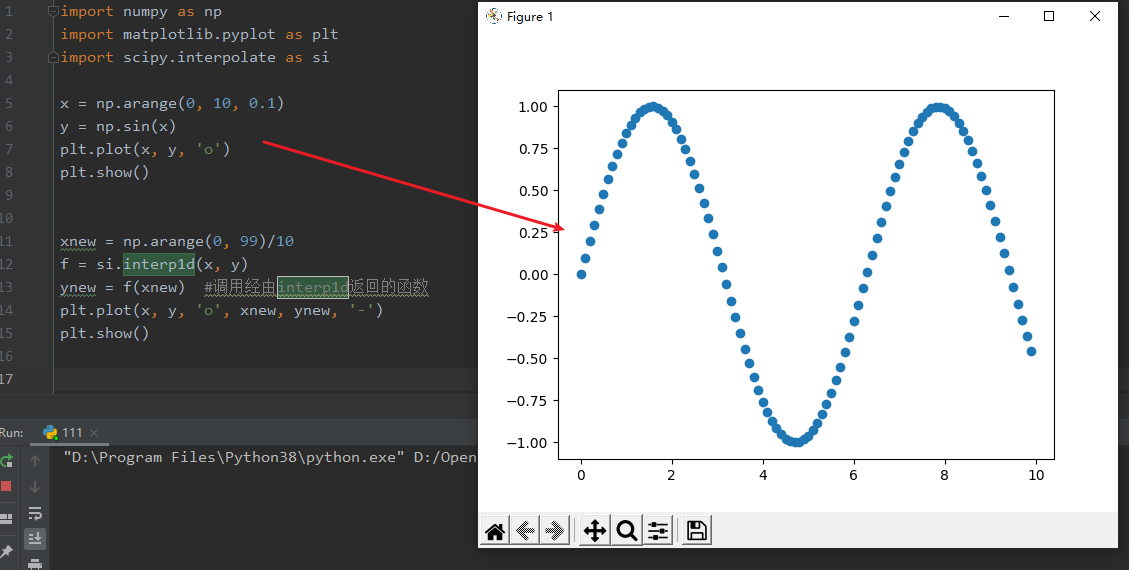
x = np.arange(0, 10, 0.1)
y = np.sin(x)
plt.plot(x, y, 'o')
plt.show()
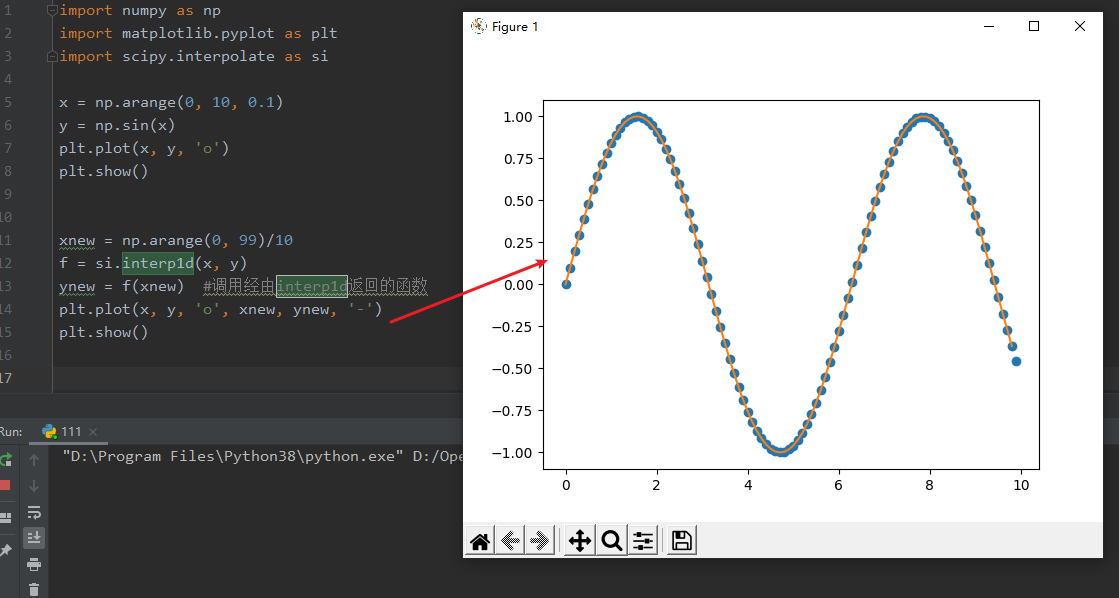
xnew = np.arange(0, 99)/10
f = si.interp1d(x, y)
ynew = f(xnew) #调用经由interp1d返回的函数
plt.plot(x, y, 'o', xnew, ynew, '-')
plt.show()
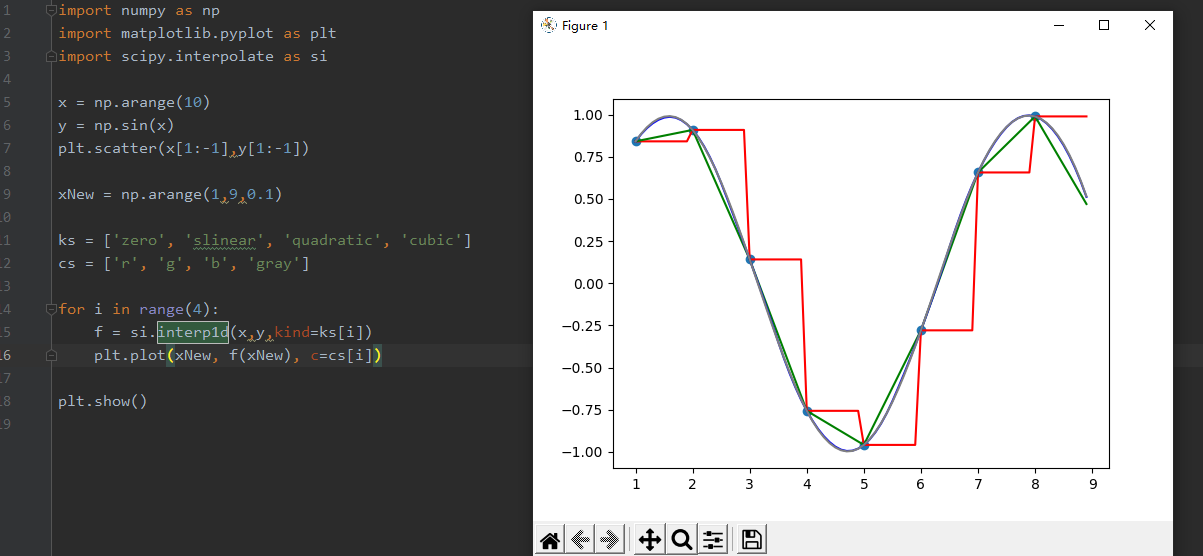
import numpy as np
import matplotlib.pyplot as plt
import scipy.interpolate as si
x = np.arange(10)
y = np.sin(x)
plt.scatter(x[1:-1],y[1:-1])
xNew = np.arange(1,9,0.1)
ks = ['zero', 'slinear', 'quadratic', 'cubic']
cs = ['r', 'g', 'b', 'gray']
for i in range(4):
f = si.interp1d(x,y,kind=ks[i])
plt.plot(xNew, f(xNew), c=cs[i])
plt.show()
下图中,红、绿、蓝、灰分别代表0到3次插值,可见,尽管只有10个点,但分段的二次函数已经描绘出了三角函数的形状,其插值效果还是不错的。
import numpy as np
from scipy.interpolate import interp1d
from scipy.interpolate import lagrange
# 插值法
# 线性插值 ——你和线性关系进行插值
# 多项式插值 ——拟合多项式进行插值
# 拉格朗日多项式插值、牛顿多项式插值
# 样条插值 ——拟合曲线进行插值
# 对于线型关系,线型插值,表现良好,多项式插值,与样条插值也表现良好
# 对于非线型关系,线型插值,表现不好,多项式插值,与样条插值表现良好
# 推荐如果想要使用插值方式,使用拉格朗日插值和样条插值
x = np.array([1, 2, 3, 4, 5, 8, 9])
y = np.array([3, 5, 7, 9, 11, 17, 19])
z = np.array([2, 8, 18, 32, 50 ,128, 162])
# 线型插值
linear_1 = interp1d(x=x, y=y, kind="linear")
linear_2 = interp1d(x=x, y=z, kind="linear")
linear_3 = interp1d(x=x, y=y, kind="cubic")
print("线性插值: \n", linear_1([6, 7])) # [13. 15.] 注意不是1是第一个索引
# print("线性插值: \n", linear_1([5, 6])) # [11. 13.]
print("线性插值: \n", linear_2([6, 7])) # [76. 102]
print("线性插值: \n", linear_3([6, 7])) # [76. 102]
# 拉格朗日插值
la_1 = lagrange(x=x, w=y)
la_2 = lagrange(x=x, w=y)
print("拉格朗日: \n", la_1) # [13, 15]
print("拉格朗日: \n", la_2) # [72, 98]
转换为张量格式
import os
import pandas as pd
import numpy as np
import paddle
data_file = os.path.join('.', 'data', 'house_tiny.csv')
with open(data_file, 'w') as f:
f.write('NumRooms,Alley,Test,Price\n')
f.write('NA,Pave,NA,127500\n')
f.write('2,D,NA,106000\n')
f.write('4,NA,NA,178100\n')
f.write('NA,NA,NA,NA\n')
data = pd.read_csv(data_file)
# 对于非NaN类型的数据——先将非NaN类型的数据转化为np.nan
data.replace("*", np.nan, inplace=True)
print("data: \n", data)
print(type(np.nan))
inputs, outputs = data.iloc[:, 0:4], data.iloc[:, 3]
print("-" * 60)
# 把离散的类别信息转化为 one-hot 编码形式
inputs = pd.get_dummies(inputs, dummy_na=True)
print("\none-hot => \n", inputs)
# 转换为张量格式
x, y = paddle.to_tensor(inputs.values), paddle.to_tensor(outputs.values)
print("\n to_tensor => \n", x, y)
Recommend
-
26
数据科学就是关于数据的。它是任何数据科学或机器学习项目的关键。在大多数情况下,当我们从不同的资源收集数据或从某处下载数据时,几乎有95%的可能性我们的数据中包含缺失的值。我们不能对包含缺失值的数据进行分析或训练机器学习模型。...
-
12
在机器学习中建模的时候,往往面临两个困难,一是选择哪个模型,二是怎样处理数据。处于数据包括数据获取、数据清洗和数据分析。其实对于不同的场景和不同的数据,选择的模型也是不一样的,本文简单聊一聊在数据缺失的时候该怎样选择合适的模型。
-
8
在机器学习数据预处理阶段经常需要对数据进行缺失值处理。关于缺失值的处理并没有想象中的那么简单。以下为一些经验分享。 数据缺失类型 完全随机丢失(MCAR,Missing Completely at Random):某个变量是否缺失与它自...
-
4
在数据处理中,Pandas会将无法解析的数据或者缺失的数据使用NaN来表示。虽然所有的数据都有了相应的表示,但是NaN很明显是无法进行数学运算的。 本文将会讲解Pandas对于NaN数据的处理方法。 NaN的例子 上面讲到了缺失的数据会被表现为Na...
-
4
作者:韦斯·麦金尼(Wes McKinney) 译者:徐敬一 来源:大数据DT(ID:hzdashuju) 导读:在进行数据分析和建模的过程中,大量的时间花在数据准备上:加载、清理、转换和重新...
-
4
说说hdfs是如何处理块副本多余和缺失的 - hncscwc的个人空间 - OSCHINA - 中文开源技术交流社区 年度开源项目评选特别策划之“视频号...
-
3
Table of Contents核心知识点 一、检测空值: isnull() notnull() df.isnull() 与 df.notnull() :用于检测dataframe 或者 series
-
8
NLP问答任务 相似度和规则匹配,都是早期的方法,现在主流的方法,都是基于生成的方法 结构化数据问答,有两种形式,一种是知识图谱形式、一种是关系型数据库形式。
-
1
常见的对话系统 个人助手 •Apple Siri, Amazon Alexa, Baidu Xiaodu 客户服务•餐厅预定、商品咨询、债务催收 休闲娱乐 •Microsoft XiaoIce,Replika
-
3
数据的预处理是数据分析,或者机器学习训练前的重要步骤。通过数据预处理,可以 提高数据质量,处理数据的缺失值、异常值和重复值等问题,增加数据的准确性和可靠性 整合不同数据,...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK