

云端炼丹,算力白嫖,基于云端GPU(Colab)使用So-vits库制作AI特朗普演唱《国际歌》 - 刘...
source link: https://www.cnblogs.com/v3ucn/p/17405638.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

人工智能AI技术早已深入到人们生活的每一个角落,君不见AI孙燕姿的歌声此起彼伏,不绝于耳,但并不是每个人都拥有一块N卡,没有GPU的日子总是不好过的,但是没关系,山人有妙计,本次我们基于Google的Colab免费云端服务器来搭建深度学习环境,制作AI特朗普,让他高唱《国际歌》。
Colab(全名Colaboratory ),它是Google公司的一款基于云端的基础免费服务器产品,可以在B端,也就是浏览器里面编写和执行Python代码,非常方便,贴心的是,Colab可以给用户分配免费的GPU进行使用,对于没有N卡的朋友来说,这已经远远超出了业界良心的范畴,简直就是在做慈善事业。
配置Colab
Colab是基于Google云盘的产品,我们可以将深度学习的Python脚本、训练好的模型、以及训练集等数据直接存放在云盘中,然后通过Colab执行即可。
首先访问Google云盘:drive.google.com
随后点击新建,选择关联更多应用:
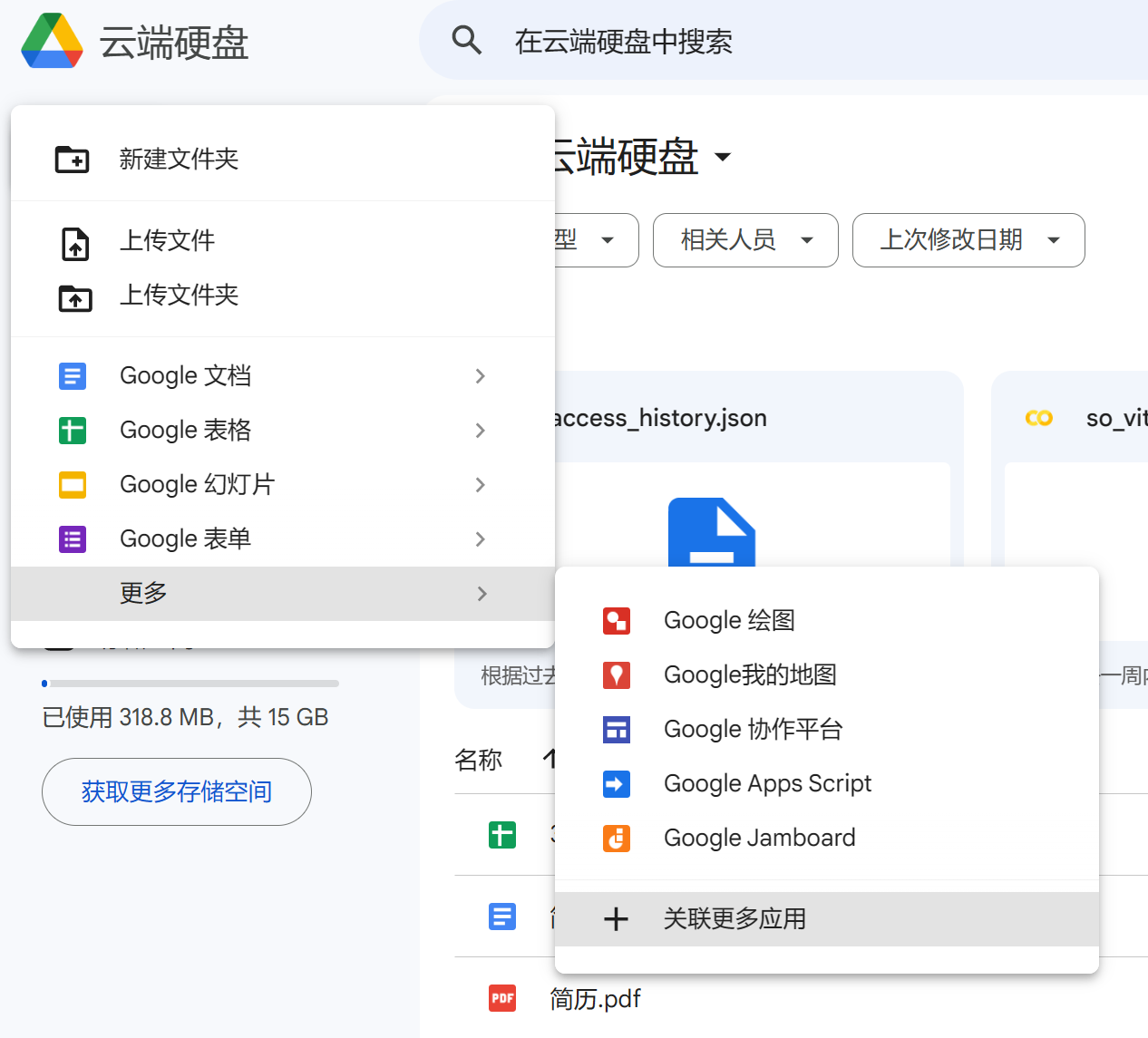
接着安装Colab即可:
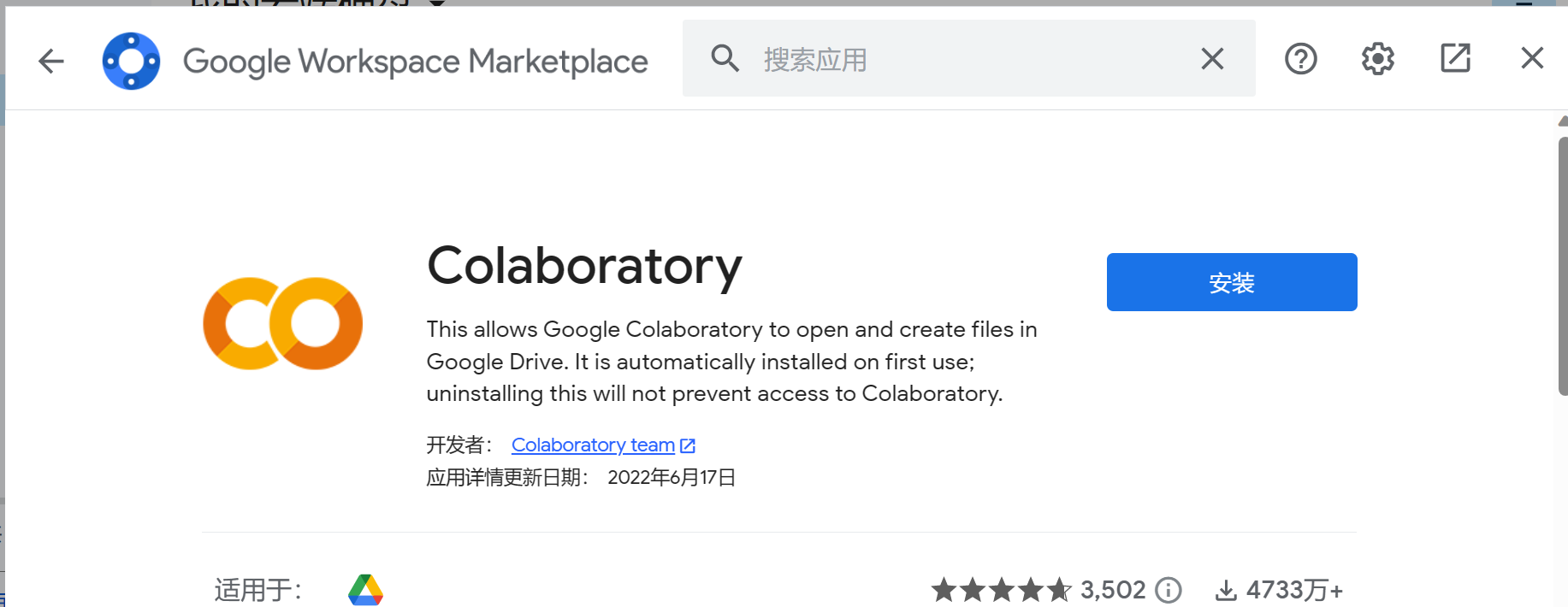
至此,云盘和Colab就关联好了,现在我们可以新建一个脚本文件my_sovits.ipynb文件,键入代码:
hello colab
随后,按快捷键 ctrl + 回车,即可运行代码:

这里需要注意的是,Colab使用的是基于Jupyter Notebook的ipynb格式的Python代码。
Jupyter Notebook是以网页的形式打开,可以在网页页面中直接编写代码和运行代码,代码的运行结果也会直接在代码块下显示。如在编程过程中需要编写说明文档,可在同一个页面中直接编写,便于作及时的说明和解释。
随后设置一下显卡类型:

接着运行命令,查看GPU版本:
!/usr/local/cuda/bin/nvcc --version
!nvidia-smi
程序返回:
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Wed_Sep_21_10:33:58_PDT_2022
Cuda compilation tools, release 11.8, V11.8.89
Build cuda_11.8.r11.8/compiler.31833905_0
Tue May 16 04:49:23 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.85.12 Driver Version: 525.85.12 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 65C P8 13W / 70W | 0MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
这里建议选择Tesla T4的显卡类型,性能更突出。
至此Colab就配置好了。
配置So-vits
下面我们配置so-vits环境,可以通过pip命令安装一些基础依赖:
!pip install pyworld==0.3.2
!pip install numpy==1.23.5
注意jupyter语言是通过叹号来运行命令。
注意,由于不是本地环境,有的时候colab会提醒:
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Collecting numpy==1.23.5
Downloading numpy-1.23.5-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (17.1 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 17.1/17.1 MB 80.1 MB/s eta 0:00:00
Installing collected packages: numpy
Attempting uninstall: numpy
Found existing installation: numpy 1.22.4
Uninstalling numpy-1.22.4:
Successfully uninstalled numpy-1.22.4
Successfully installed numpy-1.23.5
WARNING: The following packages were previously imported in this runtime:
[numpy]
You must restart the runtime in order to use newly installed versions.
此时numpy库需要重启runtime才可以导入操作。
重启runtime后,需要再重新安装一次,直到系统提示依赖已经存在:
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Requirement already satisfied: numpy==1.23.5 in /usr/local/lib/python3.10/dist-packages (1.23.5)
随后,克隆so-vits项目,并且安装项目的依赖:
import os
import glob
!git clone https://github.com/effusiveperiscope/so-vits-svc -b eff-4.0
os.chdir('/content/so-vits-svc')
# install requirements one-at-a-time to ignore exceptions
!cat requirements.txt | xargs -n 1 pip install --extra-index-url https://download.pytorch.org/whl/cu117
!pip install praat-parselmouth
!pip install ipywidgets
!pip install huggingface_hub
!pip install pip==23.0.1 # fix pip version for fairseq install
!pip install fairseq==0.12.2
!jupyter nbextension enable --py widgetsnbextension
existing_files = glob.glob('/content/**/*.*', recursive=True)
!pip install --upgrade protobuf==3.9.2
!pip uninstall -y tensorflow
!pip install tensorflow==2.11.0
安装好依赖之后,定义一些前置工具方法:
os.chdir('/content/so-vits-svc') # force working-directory to so-vits-svc - this line is just for safety and is probably not required
import tarfile
import os
from zipfile import ZipFile
# taken from https://github.com/CookiePPP/cookietts/blob/master/CookieTTS/utils/dataset/extract_unknown.py
def extract(path):
if path.endswith(".zip"):
with ZipFile(path, 'r') as zipObj:
zipObj.extractall(os.path.split(path)[0])
elif path.endswith(".tar.bz2"):
tar = tarfile.open(path, "r:bz2")
tar.extractall(os.path.split(path)[0])
tar.close()
elif path.endswith(".tar.gz"):
tar = tarfile.open(path, "r:gz")
tar.extractall(os.path.split(path)[0])
tar.close()
elif path.endswith(".tar"):
tar = tarfile.open(path, "r:")
tar.extractall(os.path.split(path)[0])
tar.close()
elif path.endswith(".7z"):
import py7zr
archive = py7zr.SevenZipFile(path, mode='r')
archive.extractall(path=os.path.split(path)[0])
archive.close()
else:
raise NotImplementedError(f"{path} extension not implemented.")
# taken from https://github.com/CookiePPP/cookietts/tree/master/CookieTTS/_0_download/scripts
# megatools download urls
win64_url = "https://megatools.megous.com/builds/builds/megatools-1.11.1.20230212-win64.zip"
win32_url = "https://megatools.megous.com/builds/builds/megatools-1.11.1.20230212-win32.zip"
linux_url = "https://megatools.megous.com/builds/builds/megatools-1.11.1.20230212-linux-x86_64.tar.gz"
# download megatools
from sys import platform
import os
import urllib.request
import subprocess
from time import sleep
if platform == "linux" or platform == "linux2":
dl_url = linux_url
elif platform == "darwin":
raise NotImplementedError('MacOS not supported.')
elif platform == "win32":
dl_url = win64_url
else:
raise NotImplementedError ('Unknown Operating System.')
dlname = dl_url.split("/")[-1]
if dlname.endswith(".zip"):
binary_folder = dlname[:-4] # remove .zip
elif dlname.endswith(".tar.gz"):
binary_folder = dlname[:-7] # remove .tar.gz
else:
raise NameError('downloaded megatools has unknown archive file extension!')
if not os.path.exists(binary_folder):
print('"megatools" not found. Downloading...')
if not os.path.exists(dlname):
urllib.request.urlretrieve(dl_url, dlname)
assert os.path.exists(dlname), 'failed to download.'
extract(dlname)
sleep(0.10)
os.unlink(dlname)
print("Done!")
binary_folder = os.path.abspath(binary_folder)
def megadown(download_link, filename='.', verbose=False):
"""Use megatools binary executable to download files and folders from MEGA.nz ."""
filename = ' --path "'+os.path.abspath(filename)+'"' if filename else ""
wd_old = os.getcwd()
os.chdir(binary_folder)
try:
if platform == "linux" or platform == "linux2":
subprocess.call(f'./megatools dl{filename}{" --debug http" if verbose else ""} {download_link}', shell=True)
elif platform == "win32":
subprocess.call(f'megatools.exe dl{filename}{" --debug http" if verbose else ""} {download_link}', shell=True)
except:
os.chdir(wd_old) # don't let user stop download without going back to correct directory first
raise
os.chdir(wd_old)
return filename
import urllib.request
from tqdm import tqdm
import gdown
from os.path import exists
def request_url_with_progress_bar(url, filename):
class DownloadProgressBar(tqdm):
def update_to(self, b=1, bsize=1, tsize=None):
if tsize is not None:
self.total = tsize
self.update(b * bsize - self.n)
def download_url(url, filename):
with DownloadProgressBar(unit='B', unit_scale=True,
miniters=1, desc=url.split('/')[-1]) as t:
filename, headers = urllib.request.urlretrieve(url, filename=filename, reporthook=t.update_to)
print("Downloaded to "+filename)
download_url(url, filename)
def download(urls, dataset='', filenames=None, force_dl=False, username='', password='', auth_needed=False):
assert filenames is None or len(urls) == len(filenames), f"number of urls does not match filenames. Expected {len(filenames)} urls, containing the files listed below.\n{filenames}"
assert not auth_needed or (len(username) and len(password)), f"username and password needed for {dataset} Dataset"
if filenames is None:
filenames = [None,]*len(urls)
for i, (url, filename) in enumerate(zip(urls, filenames)):
print(f"Downloading File from {url}")
#if filename is None:
# filename = url.split("/")[-1]
if filename and (not force_dl) and exists(filename):
print(f"{filename} Already Exists, Skipping.")
continue
if 'drive.google.com' in url:
assert 'https://drive.google.com/uc?id=' in url, 'Google Drive links should follow the format "https://drive.google.com/uc?id=1eQAnaoDBGQZldPVk-nzgYzRbcPSmnpv6".\nWhere id=XXXXXXXXXXXXXXXXX is the Google Drive Share ID.'
gdown.download(url, filename, quiet=False)
elif 'mega.nz' in url:
megadown(url, filename)
else:
#urllib.request.urlretrieve(url, filename=filename) # no progress bar
request_url_with_progress_bar(url, filename) # with progress bar
import huggingface_hub
import os
import shutil
class HFModels:
def __init__(self, repo = "therealvul/so-vits-svc-4.0",
model_dir = "hf_vul_models"):
self.model_repo = huggingface_hub.Repository(local_dir=model_dir,
clone_from=repo, skip_lfs_files=True)
self.repo = repo
self.model_dir = model_dir
self.model_folders = os.listdir(model_dir)
self.model_folders.remove('.git')
self.model_folders.remove('.gitattributes')
def list_models(self):
return self.model_folders
# Downloads model;
# copies config to target_dir and moves model to target_dir
def download_model(self, model_name, target_dir):
if not model_name in self.model_folders:
raise Exception(model_name + " not found")
model_dir = self.model_dir
charpath = os.path.join(model_dir,model_name)
gen_pt = next(x for x in os.listdir(charpath) if x.startswith("G_"))
cfg = next(x for x in os.listdir(charpath) if x.endswith("json"))
try:
clust = next(x for x in os.listdir(charpath) if x.endswith("pt"))
except StopIteration as e:
print("Note - no cluster model for "+model_name)
clust = None
if not os.path.exists(target_dir):
os.makedirs(target_dir, exist_ok=True)
gen_dir = huggingface_hub.hf_hub_download(repo_id = self.repo,
filename = model_name + "/" + gen_pt) # this is a symlink
if clust is not None:
clust_dir = huggingface_hub.hf_hub_download(repo_id = self.repo,
filename = model_name + "/" + clust) # this is a symlink
shutil.move(os.path.realpath(clust_dir), os.path.join(target_dir, clust))
clust_out = os.path.join(target_dir, clust)
else:
clust_out = None
shutil.copy(os.path.join(charpath,cfg),os.path.join(target_dir, cfg))
shutil.move(os.path.realpath(gen_dir), os.path.join(target_dir, gen_pt))
return {"config_path": os.path.join(target_dir,cfg),
"generator_path": os.path.join(target_dir,gen_pt),
"cluster_path": clust_out}
# Example usage
# vul_models = HFModels()
# print(vul_models.list_models())
# print("Applejack (singing)" in vul_models.list_models())
# vul_models.download_model("Applejack (singing)","models/Applejack (singing)")
print("Finished!")
这些方法可以帮助我们下载、解压和加载模型。
音色模型下载和线上推理
接着将特朗普的音色模型和配置文件进行下载,下载地址是:
https://huggingface.co/Nardicality/so-vits-svc-4.0-models/tree/main/Trump18.5k
随后模型文件放到项目的models文件夹,配置文件则放入config文件夹。
接着将需要转换的歌曲上传到和项目平行的目录中。
运行代码:
import os
import glob
import json
import copy
import logging
import io
from ipywidgets import widgets
from pathlib import Path
from IPython.display import Audio, display
os.chdir('/content/so-vits-svc')
import torch
from inference import infer_tool
from inference import slicer
from inference.infer_tool import Svc
import soundfile
import numpy as np
MODELS_DIR = "models"
def get_speakers():
speakers = []
for _,dirs,_ in os.walk(MODELS_DIR):
for folder in dirs:
cur_speaker = {}
# Look for G_****.pth
g = glob.glob(os.path.join(MODELS_DIR,folder,'G_*.pth'))
if not len(g):
print("Skipping "+folder+", no G_*.pth")
continue
cur_speaker["model_path"] = g[0]
cur_speaker["model_folder"] = folder
# Look for *.pt (clustering model)
clst = glob.glob(os.path.join(MODELS_DIR,folder,'*.pt'))
if not len(clst):
print("Note: No clustering model found for "+folder)
cur_speaker["cluster_path"] = ""
else:
cur_speaker["cluster_path"] = clst[0]
# Look for config.json
cfg = glob.glob(os.path.join(MODELS_DIR,folder,'*.json'))
if not len(cfg):
print("Skipping "+folder+", no config json")
continue
cur_speaker["cfg_path"] = cfg[0]
with open(cur_speaker["cfg_path"]) as f:
try:
cfg_json = json.loads(f.read())
except Exception as e:
print("Malformed config json in "+folder)
for name, i in cfg_json["spk"].items():
cur_speaker["name"] = name
cur_speaker["id"] = i
if not name.startswith('.'):
speakers.append(copy.copy(cur_speaker))
return sorted(speakers, key=lambda x:x["name"].lower())
logging.getLogger('numba').setLevel(logging.WARNING)
chunks_dict = infer_tool.read_temp("inference/chunks_temp.json")
existing_files = []
slice_db = -40
wav_format = 'wav'
class InferenceGui():
def __init__(self):
self.speakers = get_speakers()
self.speaker_list = [x["name"] for x in self.speakers]
self.speaker_box = widgets.Dropdown(
options = self.speaker_list
)
display(self.speaker_box)
def convert_cb(btn):
self.convert()
def clean_cb(btn):
self.clean()
self.convert_btn = widgets.Button(description="Convert")
self.convert_btn.on_click(convert_cb)
self.clean_btn = widgets.Button(description="Delete all audio files")
self.clean_btn.on_click(clean_cb)
self.trans_tx = widgets.IntText(value=0, description='Transpose')
self.cluster_ratio_tx = widgets.FloatText(value=0.0,
description='Clustering Ratio')
self.noise_scale_tx = widgets.FloatText(value=0.4,
description='Noise Scale')
self.auto_pitch_ck = widgets.Checkbox(value=False, description=
'Auto pitch f0 (do not use for singing)')
display(self.trans_tx)
display(self.cluster_ratio_tx)
display(self.noise_scale_tx)
display(self.auto_pitch_ck)
display(self.convert_btn)
display(self.clean_btn)
def convert(self):
trans = int(self.trans_tx.value)
speaker = next(x for x in self.speakers if x["name"] ==
self.speaker_box.value)
spkpth2 = os.path.join(os.getcwd(),speaker["model_path"])
print(spkpth2)
print(os.path.exists(spkpth2))
svc_model = Svc(speaker["model_path"], speaker["cfg_path"],
cluster_model_path=speaker["cluster_path"])
input_filepaths = [f for f in glob.glob('/content/**/*.*', recursive=True)
if f not in existing_files and
any(f.endswith(ex) for ex in ['.wav','.flac','.mp3','.ogg','.opus'])]
for name in input_filepaths:
print("Converting "+os.path.split(name)[-1])
infer_tool.format_wav(name)
wav_path = str(Path(name).with_suffix('.wav'))
wav_name = Path(name).stem
chunks = slicer.cut(wav_path, db_thresh=slice_db)
audio_data, audio_sr = slicer.chunks2audio(wav_path, chunks)
audio = []
for (slice_tag, data) in audio_data:
print(f'#=====segment start, '
f'{round(len(data)/audio_sr, 3)}s======')
length = int(np.ceil(len(data) / audio_sr *
svc_model.target_sample))
if slice_tag:
print('jump empty segment')
_audio = np.zeros(length)
else:
# Padding "fix" for noise
pad_len = int(audio_sr * 0.5)
data = np.concatenate([np.zeros([pad_len]),
data, np.zeros([pad_len])])
raw_path = io.BytesIO()
soundfile.write(raw_path, data, audio_sr, format="wav")
raw_path.seek(0)
_cluster_ratio = 0.0
if speaker["cluster_path"] != "":
_cluster_ratio = float(self.cluster_ratio_tx.value)
out_audio, out_sr = svc_model.infer(
speaker["name"], trans, raw_path,
cluster_infer_ratio = _cluster_ratio,
auto_predict_f0 = bool(self.auto_pitch_ck.value),
noice_scale = float(self.noise_scale_tx.value))
_audio = out_audio.cpu().numpy()
pad_len = int(svc_model.target_sample * 0.5)
_audio = _audio[pad_len:-pad_len]
audio.extend(list(infer_tool.pad_array(_audio, length)))
res_path = os.path.join('/content/',
f'{wav_name}_{trans}_key_'
f'{speaker["name"]}.{wav_format}')
soundfile.write(res_path, audio, svc_model.target_sample,
format=wav_format)
display(Audio(res_path, autoplay=True)) # display audio file
pass
def clean(self):
input_filepaths = [f for f in glob.glob('/content/**/*.*', recursive=True)
if f not in existing_files and
any(f.endswith(ex) for ex in ['.wav','.flac','.mp3','.ogg','.opus'])]
for f in input_filepaths:
os.remove(f)
inference_gui = InferenceGui()
此时系统会自动在根目录,也就是content下寻找音乐文件,包含但不限于wav、flac、mp3等等,随后根据下载的模型进行推理,推理之前会自动对文件进行背景音分离以及降噪和切片等操作。
推理结束之后,会自动播放转换后的歌曲。
如果是刚开始使用Colab,默认分配的显存是15G左右,完全可以胜任大多数训练和推理任务,但是如果经常用它挂机运算,能分配到的显卡配置就会渐进式地降低,如果需要长时间并且相对稳定的GPU资源,还是需要付费订阅Colab pro服务,另外Google云盘的免费使用空间也是15G,如果模型下多了,导致云盘空间不足,运行代码也会报错,所以最好定期清理Google云盘,以此保证深度学习任务的正常运行。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK