
0

巨型AI模型背后的分布式训练技术(二)
source link: https://zhuanlan.zhihu.com/p/629443563
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

巨型AI模型背后的分布式训练技术(二)
最近项目需要,又翻了下大模型训练的近期情况。有些新的思考和领悟,记下来梳理思路。
更新一下之前文章的术语,大部分保持不变:Peter PanXin:巨型AI模型背后的分布式训练技术。
Data Parallel(DP):这块没什么变化。
Model Parallel (MP),Pipeline Parallel (PP),Tensor Parallel(TP):感觉PP和TP都可以归在MP门下:
- naive的MP现在已经不谈了,硬件效率太低。所以一般都是说MP的两个子类(个人觉得这么分):PP和TP。
- PP如引文提到,通过切分batch成很多小micro batch,流水线经过多个pipeline stages的GPUs,使得多个GPU能同时工作,较大的提高了GPU利用率。Megatron PP有一些细节创新,比如interleaved PP等进一步缓解PP的bubble问题,同时带来一点额外通信开销,细节可以看Megatron-LM的论文。
- TP在引文中没说,这里简单解释下:就是把某些层的计算用多个GPU并行算,每个GPU算其中一部分。可以类比成传统算法从单线程变成多线程(e.g. mapreduce)的过程。具体不同类型的层(算法)有不同层的并行化算法,下图贴了个MLP的2卡TP切法。TP对于多卡的通信要求比较高,通常不会进行跨server的TP,一般是单server内多GPU的TP。
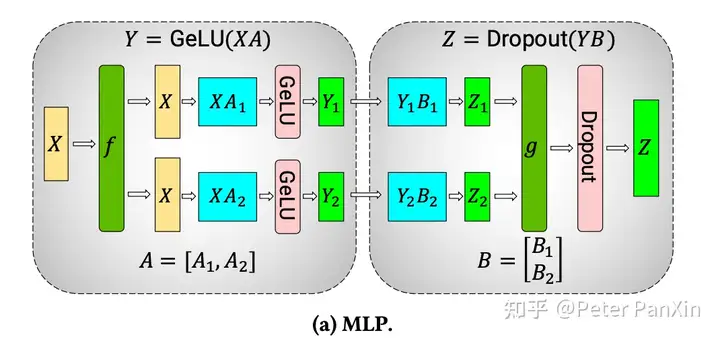
DP,PP,TP有时候会被合起来叫3D-Parallelism,更加酷炫。
Zero / Sharding&Offload:在引文也有讨论过,Zero-1,2,3分别是把optimizer, gradient, parameter切分到多个DP的GPU上,这样每个DP GPU只要存1/n的量,n是DP的GPU数。在需要用是再从各个GPU上gather过来。Offload还可以把GPU的优化器参数offload到CPU的内存上。
其他也没有变化:
- Activation Checkpoint:前向只存一部分中间结果,在反向计算时再重新算没存的那部分,时间换空间。
- Gradient Accumulation:多算几次前向-反向,积累几次的gradient后再optimize,可以再不显著增加空间的情况下提高batch size大小。
DP,TP,PP,Sharding, Offload...关系
难题来了,这么多的分布式优化技术,需要怎么用?
寻找全局最优是个比较复杂的数学建模和优化过程,这里不详细讨论。
定性的记录下大致规律:
- TP的通信量常常最大,每层都需要多次多卡通信,通常只适用机内多卡的nvlink/switch。对于GPU比较充裕的团队,对于较大计算量层,TP可以用算力换时间。
- PP主要适用于模型极大,且算力资源比较充裕的团队。这里其实有个问题:DP和PP怎么选?似乎都可以通过增加资源提高训练吞吐):
- DP的扩展提升通常必然带来batch size的增加,然而batch size未必越大越好,有可能会影响收敛效果,或者降低样本效率等问题。
- PP的扩展不一定带来batch size的增加,依然可以让更多的卡一起计算。但是PP中pipeline stage个数(GPU)增加时,提高batch size也是有好处,甚至必要的。提高batch size可以增加micro batch个数,减少bubble,提高GPU的利用效率。
- 综上,GPU(钱)非常多,模型非常大,可以考虑加入PP。
- Zero的Sharding和Offload优化通常更适用于资源受限,但是又要训练大模型的情况。通过时间换空间。比如把optimizer state, gradient, parameters sharding或者offload到cpu,多少会有一些额外的时间开销,不好通过计算给完全overlap掉。这里没有定量的分析,当模型极大时,gather-scatter会在某个GPU规模后成为比较显著的瓶颈,比如:需要从很多GPU读过来很多shards,才能凑够完整的参数进行计算。
- Zero和TP/PP存在一定重叠的取舍关系。比如,PP/TP使用后,每个GPU的空间压力已经比较小,那么Zero的Sharding和Offload收益也会大打折扣。
- 通常PP和parameter/gradient sharding不太适合搭配。因为PP会产生较多microbatch,导致sharding后需要为每个microbatch做多卡通信
- PP只要不是拆的特别碎,通信量一般比较小,只需要前后stage传递activation就行。而Zero的Sharding和Offload通信会更多一些。
- 易用性问题。PP还有个易用性的问题,使用PP需要考虑不同Pipeline上放哪些层,如何放得均匀,还需要考虑microbatch size等问题,进而还需要修改很多代码。相比之下,Zero用起来相对简单得多。
可以从两个维度来看:GPU/机器的规模,模型的参数量。
| 机器\参数 | <1B | 1~10B | >100B |
|---|---|---|---|
| 单机单GPU | 什么都不用 | Offload | 不建议 |
| 单机多GPU | DP | Sharding+DP | Sharding+Offload+DP |
| 小集群 | DP | Sharding+DP | Sharding+DP |
| 大集群(e.g. >512) | 不建议 | Sharding+DP, maybe PP/TP | DP+TP+PP |
https://cs.stanford.edu/~matei/papers/2021/sc_megatron_lm.pdf
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK